 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSTL: A Comprehensive Benchmark of Spatio-Temporal Predictive Learning
Jun 20, 2023



Spatio-temporal predictive learning is a learning paradigm that enables models to learn spatial and temporal patterns by predicting future frames from given past frames in an unsupervised manner. Despite remarkable progress in recent years, a lack of systematic understanding persists due to the diverse settings, complex implementation, and difficult reproducibility. Without standardization, comparisons can be unfair and insights inconclusive. To address this dilemma, we propose OpenSTL, a comprehensive benchmark for spatio-temporal predictive learning that categorizes prevalent approaches into recurrent-based and recurrent-free models. OpenSTL provides a modular and extensible framework implementing various state-of-the-art methods. We conduct standard evaluations on datasets across various domains, including synthetic moving object trajectory, human motion, driving scenes, traffic flow and weather forecasting. Based on our observations, we provide a detailed analysis of how model architecture and dataset properties affect spatio-temporal predictive learning performance. Surprisingly, we find that recurrent-free models achieve a good balance between efficiency and performance than recurrent models. Thus, we further extend the common MetaFormers to boost recurrent-free spatial-temporal predictive learning. We open-source the code and models at https://github.com/chengtan9907/OpenSTL.
Quantifying the Knowledge in GNNs for Reliable Distillation into MLPs
Jun 09, 2023To bridge the gaps between topology-aware Graph Neural Networks (GNNs) and inference-efficient Multi-Layer Perceptron (MLPs), GLNN proposes to distill knowledge from a well-trained teacher GNN into a student MLP. Despite their great progress, comparatively little work has been done to explore the reliability of different knowledge points (nodes) in GNNs, especially their roles played during distillation. In this paper, we first quantify the knowledge reliability in GNN by measuring the invariance of their information entropy to noise perturbations, from which we observe that different knowledge points (1) show different distillation speeds (temporally); (2) are differentially distributed in the graph (spatially). To achieve reliable distillation, we propose an effective approach, namely Knowledge-inspired Reliable Distillation (KRD), that models the probability of each node being an informative and reliable knowledge point, based on which we sample a set of additional reliable knowledge points as supervision for training student MLPs. Extensive experiments show that KRD improves over the vanilla MLPs by 12.62% and outperforms its corresponding teacher GNNs by 2.16% averaged over 7 datasets and 3 GNN architectures.
Extracting Low-/High- Frequency Knowledge from Graph Neural Networks and Injecting it into MLPs: An Effective GNN-to-MLP Distillation Framework
May 18, 2023Recent years have witnessed the great success of Graph Neural Networks (GNNs) in handling graph-related tasks. However, MLPs remain the primary workhorse for practical industrial applications due to their desirable inference efficiency and scalability. To reduce their gaps, one can directly distill knowledge from a well-designed teacher GNN to a student MLP, which is termed as GNN-to-MLP distillation. However, the process of distillation usually entails a loss of information, and ``which knowledge patterns of GNNs are more likely to be left and distilled into MLPs?" becomes an important question. In this paper, we first factorize the knowledge learned by GNNs into low- and high-frequency components in the spectral domain and then derive their correspondence in the spatial domain. Furthermore, we identified a potential information drowning problem for existing GNN-to-MLP distillation, i.e., the high-frequency knowledge of the pre-trained GNNs may be overwhelmed by the low-frequency knowledge during distillation; we have described in detail what it represents, how it arises, what impact it has, and how to deal with it. In this paper, we propose an efficient Full-Frequency GNN-to-MLP (FF-G2M) distillation framework, which extracts both low-frequency and high-frequency knowledge from GNNs and injects it into MLPs. Extensive experiments show that FF-G2M improves over the vanilla MLPs by 12.6% and outperforms its corresponding teacher GNNs by 2.6% averaged over six graph datasets and three common GNN architectures.
Towards Reasonable Budget Allocation in Untargeted Graph Structure Attacks via Gradient Debias
Mar 29, 2023It has become cognitive inertia to employ cross-entropy loss function in classification related tasks. In the untargeted attacks on graph structure, the gradients derived from the attack objective are the attacker's basis for evaluating a perturbation scheme. Previous methods use negative cross-entropy loss as the attack objective in attacking node-level classification models. However, the suitability of the cross-entropy function for constructing the untargeted attack objective has yet been discussed in previous works. This paper argues about the previous unreasonable attack objective from the perspective of budget allocation. We demonstrate theoretically and empirically that negative cross-entropy tends to produce more significant gradients from nodes with lower confidence in the labeled classes, even if the predicted classes of these nodes have been misled. To free up these inefficient attack budgets, we propose a simple attack model for untargeted attacks on graph structure based on a novel attack objective which generates unweighted gradients on graph structures that are not affected by the node confidence. By conducting experiments in gray-box poisoning attack scenarios, we demonstrate that a reasonable budget allocation can significantly improve the effectiveness of gradient-based edge perturbations without any extra hyper-parameter.
Data-Efficient Protein 3D Geometric Pretraining via Refinement of Diffused Protein Structure Decoy
Feb 05, 2023Learning meaningful protein representation is important for a variety of biological downstream tasks such as structure-based drug design. Having witnessed the success of protein sequence pretraining, pretraining for structural data which is more informative has become a promising research topic. However, there are three major challenges facing protein structure pretraining: insufficient sample diversity, physically unrealistic modeling, and the lack of protein-specific pretext tasks. To try to address these challenges, we present the 3D Geometric Pretraining. In this paper, we propose a unified framework for protein pretraining and a 3D geometric-based, data-efficient, and protein-specific pretext task: RefineDiff (Refine the Diffused Protein Structure Decoy). After pretraining our geometric-aware model with this task on limited data(less than 1% of SOTA models), we obtained informative protein representations that can achieve comparable performance for various downstream tasks.
Explaining Graph Neural Networks via Non-parametric Subgraph Matching
Jan 07, 2023



The great success in graph neural networks (GNNs) provokes the question about explainability: Which fraction of the input graph is the most determinant of the prediction? Particularly, parametric explainers prevail in existing approaches because of their stronger capability to decipher the black-box (i.e., the target GNN). In this paper, based on the observation that graphs typically share some joint motif patterns, we propose a novel non-parametric subgraph matching framework, dubbed MatchExplainer, to explore explanatory subgraphs. It couples the target graph with other counterpart instances and identifies the most crucial joint substructure by minimizing the node corresponding-based distance. Moreover, we note that present graph sampling or node-dropping methods usually suffer from the false positive sampling problem. To ameliorate that issue, we design a new augmentation paradigm named MatchDrop. It takes advantage of MatchExplainer to fix the most informative portion of the graph and merely operates graph augmentations on the rest less informative part. We conduct extensive experiments on both synthetic and real-world datasets and show the effectiveness of our MatchExplainer by outperforming all parametric baselines with significant margins. Additional results also demonstrate that our MatchDrop is a general scheme to be equipped with GNNs for enhanced performance.
A Survey on Protein Representation Learning: Retrospect and Prospect
Dec 31, 2022


Proteins are fundamental biological entities that play a key role in life activities. The amino acid sequences of proteins can be folded into stable 3D structures in the real physicochemical world, forming a special kind of sequence-structure data. With the development of Artificial Intelligence (AI) techniques, Protein Representation Learning (PRL) has recently emerged as a promising research topic for extracting informative knowledge from massive protein sequences or structures. To pave the way for AI researchers with little bioinformatics background, we present a timely and comprehensive review of PRL formulations and existing PRL methods from the perspective of model architectures, pretext tasks, and downstream applications. We first briefly introduce the motivations for protein representation learning and formulate it in a general and unified framework. Next, we divide existing PRL methods into three main categories: sequence-based, structure-based, and sequence-structure co-modeling. Finally, we discuss some technical challenges and potential directions for improving protein representation learning. The latest advances in PRL methods are summarized in a GitHub repository https://github.com/LirongWu/awesome-protein-representation-learning.
Non-equispaced Fourier Neural Solvers for PDEs
Dec 09, 2022Solving partial differential equations is difficult. Recently proposed neural resolution-invariant models, despite their effectiveness and efficiency, usually require equispaced spatial points of data. However, sampling in spatial domain is sometimes inevitably non-equispaced in real-world systems, limiting their applicability. In this paper, we propose a Non-equispaced Fourier PDE Solver (\textsc{NFS}) with adaptive interpolation on resampled equispaced points and a variant of Fourier Neural Operators as its components. Experimental results on complex PDEs demonstrate its advantages in accuracy and efficiency. Compared with the spatially-equispaced benchmark methods, it achieves superior performance with $42.85\%$ improvements on MAE, and is able to handle non-equispaced data with a tiny loss of accuracy. Besides, to our best knowledge, \textsc{NFS} is the first ML-based method with mesh invariant inference ability to successfully model turbulent flows in non-equispaced scenarios, with a minor deviation of the error on unseen spatial points.
Teaching Yourself:Graph Self-Distillation on Neighborhood for Node Classification
Oct 12, 2022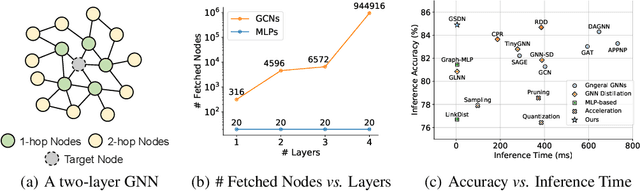
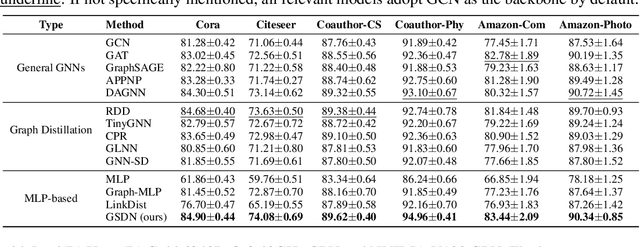
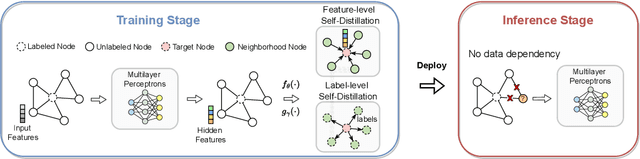

Recent years have witnessed great success in handling graph-related tasks with Graph Neural Networks (GNNs). Despite their great academic success, Multi-Layer Perceptrons (MLPs) remain the primary workhorse for practical industrial applications. One reason for this academic-industrial gap is the neighborhood-fetching latency incurred by data dependency in GNNs, which make it hard to deploy for latency-sensitive applications that require fast inference. Conversely, without involving any feature aggregation, MLPs have no data dependency and infer much faster than GNNs, but their performance is less competitive. Motivated by these complementary strengths and weaknesses, we propose a Graph Self-Distillation on Neighborhood (GSDN) framework to reduce the gap between GNNs and MLPs. Specifically, the GSDN framework is based purely on MLPs, where structural information is only implicitly used as prior to guide knowledge self-distillation between the neighborhood and the target, substituting the explicit neighborhood information propagation as in GNNs. As a result, GSDN enjoys the benefits of graph topology-awareness in training but has no data dependency in inference. Extensive experiments have shown that the performance of vanilla MLPs can be greatly improved with self-distillation, e.g., GSDN improves over stand-alone MLPs by 15.54\% on average and outperforms the state-of-the-art GNNs on six datasets. Regarding inference speed, GSDN infers 75X-89X faster than existing GNNs and 16X-25X faster than other inference acceleration methods.
Automated Graph Self-supervised Learning via Multi-teacher Knowledge Distillation
Oct 05, 2022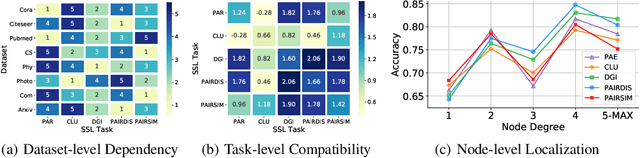
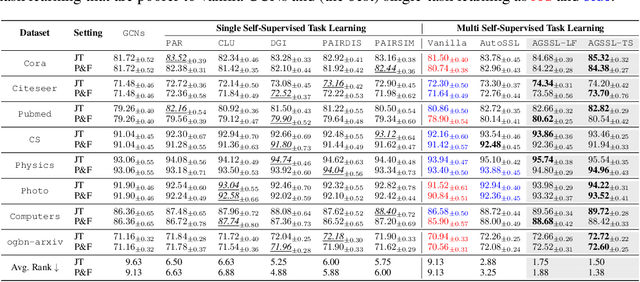

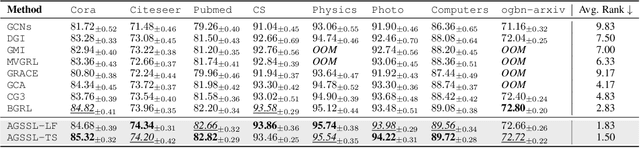
Self-supervised learning on graphs has recently achieved remarkable success in graph representation learning. With hundreds of self-supervised pretext tasks proposed over the past few years, the research community has greatly developed, and the key is no longer to design more powerful but complex pretext tasks, but to make more effective use of those already on hand. This paper studies the problem of how to automatically, adaptively, and dynamically learn instance-level self-supervised learning strategies for each node from a given pool of pretext tasks. In this paper, we propose a novel multi-teacher knowledge distillation framework for Automated Graph Self-Supervised Learning (AGSSL), which consists of two main branches: (i) Knowledge Extraction: training multiple teachers with different pretext tasks, so as to extract different levels of knowledge with different inductive biases; (ii) Knowledge Integration: integrating different levels of knowledge and distilling them into the student model. Without simply treating different teachers as equally important, we provide a provable theoretical guideline for how to integrate the knowledge of different teachers, i.e., the integrated teacher probability should be close to the true Bayesian class-probability. To approach the theoretical optimum in practice, two adaptive knowledge integration strategies are proposed to construct a relatively "good" integrated teacher. Extensive experiments on eight datasets show that AGSSL can benefit from multiple pretext tasks, outperforming the corresponding individual tasks; by combining a few simple but classical pretext tasks, the resulting performance is comparable to other leading counterparts.