 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
SCALAR: Scientific Citation-based Live Assessment of Long-context Academic Reasoning
Feb 19, 2025Evaluating large language models' (LLMs) long-context understanding capabilities remains challenging. We present SCALAR (Scientific Citation-based Live Assessment of Long-context Academic Reasoning), a novel benchmark that leverages academic papers and their citation networks. SCALAR features automatic generation of high-quality ground truth labels without human annotation, controllable difficulty levels, and a dynamic updating mechanism that prevents data contamination. Using ICLR 2025 papers, we evaluate 8 state-of-the-art LLMs, revealing key insights about their capabilities and limitations in processing long scientific documents across different context lengths and reasoning types. Our benchmark provides a reliable and sustainable way to track progress in long-context understanding as LLM capabilities evolve.
LLM360 K2: Building a 65B 360-Open-Source Large Language Model from Scratch
Jan 16, 2025



We detail the training of the LLM360 K2-65B model, scaling up our 360-degree OPEN SOURCE approach to the largest and most powerful models under project LLM360. While open-source LLMs continue to advance, the answer to "How are the largest LLMs trained?" remains unclear within the community. The implementation details for such high-capacity models are often protected due to business considerations associated with their high cost. This lack of transparency prevents LLM researchers from leveraging valuable insights from prior experience, e.g., "What are the best practices for addressing loss spikes?" The LLM360 K2 project addresses this gap by providing full transparency and access to resources accumulated during the training of LLMs at the largest scale. This report highlights key elements of the K2 project, including our first model, K2 DIAMOND, a 65 billion-parameter LLM that surpasses LLaMA-65B and rivals LLaMA2-70B, while requiring fewer FLOPs and tokens. We detail the implementation steps and present a longitudinal analysis of K2 DIAMOND's capabilities throughout its training process. We also outline ongoing projects such as TXT360, setting the stage for future models in the series. By offering previously unavailable resources, the K2 project also resonates with the 360-degree OPEN SOURCE principles of transparency, reproducibility, and accessibility, which we believe are vital in the era of resource-intensive AI research.
Bi-Mamba: Towards Accurate 1-Bit State Space Models
Nov 18, 2024The typical selective state-space model (SSM) of Mamba addresses several limitations of Transformers, such as quadratic computational complexity with sequence length and significant inference-time memory requirements due to the key-value cache. However, the growing size of Mamba models continues to pose training and deployment challenges and raises environmental concerns due to considerable energy consumption. In this work, we introduce Bi-Mamba, a scalable and powerful 1-bit Mamba architecture designed for more efficient large language models with multiple sizes across 780M, 1.3B, and 2.7B. Bi-Mamba models are trained from scratch on data volume as regular LLM pertaining using an autoregressive distillation loss. Extensive experimental results on language modeling demonstrate that Bi-Mamba achieves performance comparable to its full-precision counterparts (e.g., FP16 or BF16) and much better accuracy than post-training-binarization (PTB) Mamba baselines, while significantly reducing memory footprint and energy consumption compared to the original Mamba model. Our study pioneers a new linear computational complexity LLM framework under low-bit representation and facilitates the future design of specialized hardware tailored for efficient 1-bit Mamba-based LLMs.
FBI-LLM: Scaling Up Fully Binarized LLMs from Scratch via Autoregressive Distillation
Jul 09, 2024



This work presents a Fully BInarized Large Language Model (FBI-LLM), demonstrating for the first time how to train a large-scale binary language model from scratch (not the partial binary or ternary LLM like BitNet b1.58) to match the performance of its full-precision counterparts (e.g., FP16 or BF16) in transformer-based LLMs. It achieves this by employing an autoregressive distillation (AD) loss with maintaining equivalent model dimensions (130M, 1.3B, 7B) and training data volume as regular LLM pretraining, while delivering competitive results in terms of perplexity and task-specific effectiveness. Intriguingly, by analyzing the training trajectory, we find that the pretrained weight is not necessary for training binarized LLMs from scratch. This research encourages a new computational framework and may facilitate the future design of specialized hardware tailored for fully 1-bit LLMs. We make all models, code, and training dataset fully accessible and transparent to support further research (Code: https://github.com/LiqunMa/FBI-LLM. Model: https://huggingface.co/LiqunMa/).
Beyond Size: How Gradients Shape Pruning Decisions in Large Language Models
Nov 08, 2023



Large Language Models (LLMs) with a billion or more parameters are prime targets for network pruning, which aims to reduce a portion of the network weights without compromising performance. Prior approaches such as Weights Magnitude, SparseGPT, and Wanda, either concentrated solely on weights or integrated weights with activations for sparsity. However, they overlooked the informative gradients derived from pretrained large language models. In this paper, we present a novel sparsity-centric pruning method for pretrained LLMs, termed Gradient-based Language Model Pruner (GBLM-Pruner). GBLM-Pruner leverages the first-order term of the Taylor expansion, operating in a training-free manner by harnessing properly normalized gradients from a few calibration samples to determine the importance pruning score, and substantially outperforms competitive counterparts like SparseGPT and Wanda in multiple benchmarks. Intriguing, after incorporating gradients, the unstructured pruning method tends to reveal some structural patterns post-pruning, which mirrors the geometric interdependence inherent in the LLMs' parameter structure. Additionally, GBLM-Pruner functions without any subsequent retraining or weight updates to maintain its simplicity as other counterparts. Extensive evaluations on LLaMA-1 and LLaMA-2 across various language benchmarks and perplexity show that GBLM-Pruner surpasses magnitude pruning, Wanda (weights+activations) and SparseGPT (weights+activations+weight update) by significant margins. Our code and models are available at https://github.com/RocktimJyotiDas/GBLM-Pruner.
SlimPajama-DC: Understanding Data Combinations for LLM Training
Sep 19, 2023



This paper aims to understand the impacts of various data combinations (e.g., web text, wikipedia, github, books) on the training of large language models using SlimPajama. SlimPajama is a rigorously deduplicated, multi-source dataset, which has been refined and further deduplicated to 627B tokens from the extensive 1.2T tokens RedPajama dataset contributed by Together. We've termed our research as SlimPajama-DC, an empirical analysis designed to uncover fundamental characteristics and best practices associated with employing SlimPajama in the training of large language models. During our research with SlimPajama, two pivotal observations emerged: (1) Global deduplication vs. local deduplication. We analyze and discuss how global (across different sources of datasets) and local (within the single source of dataset) deduplications affect the performance of trained models. (2) Proportions of high-quality/highly-deduplicated multi-source datasets in the combination. To study this, we construct six configurations of SlimPajama dataset and train individual ones using 1.3B Cerebras-GPT model with Alibi and SwiGLU. Our best configuration outperforms the 1.3B model trained on RedPajama using the same number of training tokens by a significant margin. All our 1.3B models are trained on Cerebras 16$\times$ CS-2 cluster with a total of 80 PFLOP/s in bf16 mixed precision. We further extend our discoveries (such as increasing data diversity is crucial after global deduplication) on a 7B model with large batch-size training. Our models and the separate SlimPajama-DC datasets are available at: https://huggingface.co/MBZUAI-LLM and https://huggingface.co/datasets/cerebras/SlimPajama-627B.
CSDS: A Fine-Grained Chinese Dataset for Customer Service Dialogue Summarization
Sep 06, 2021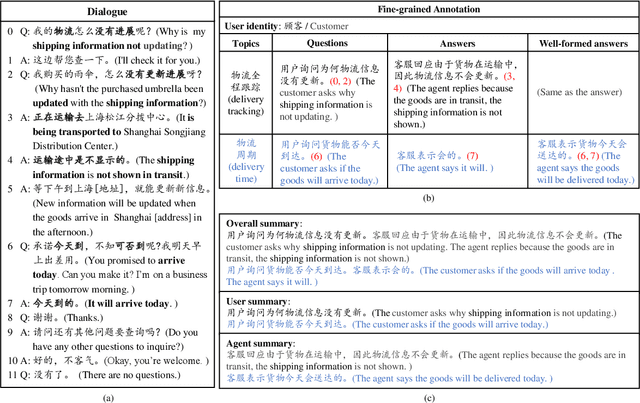
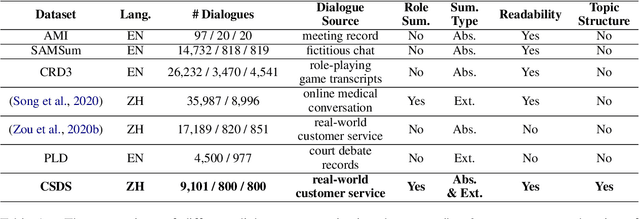
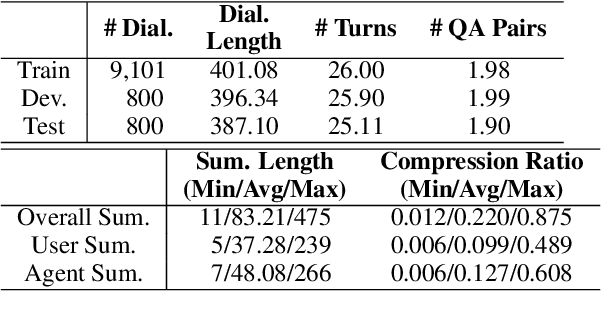
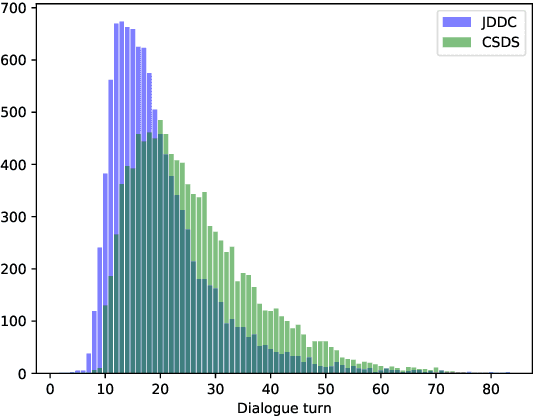
Dialogue summarization has drawn much attention recently. Especially in the customer service domain, agents could use dialogue summaries to help boost their works by quickly knowing customer's issues and service progress. These applications require summaries to contain the perspective of a single speaker and have a clear topic flow structure, while neither are available in existing datasets. Therefore, in this paper, we introduce a novel Chinese dataset for Customer Service Dialogue Summarization (CSDS). CSDS improves the abstractive summaries in two aspects: (1) In addition to the overall summary for the whole dialogue, role-oriented summaries are also provided to acquire different speakers' viewpoints. (2) All the summaries sum up each topic separately, thus containing the topic-level structure of the dialogue. We define tasks in CSDS as generating the overall summary and different role-oriented summaries for a given dialogue. Next, we compare various summarization methods on CSDS, and experiment results show that existing methods are prone to generate redundant and incoherent summaries. Besides, the performance becomes much worse when analyzing the performance on role-oriented summaries and topic structures. We hope that this study could benchmark Chinese dialogue summarization and benefit further studies.
An Empirical Evaluation of Multi-task Learning in Deep Neural Networks for Natural Language Processing
Aug 16, 2019
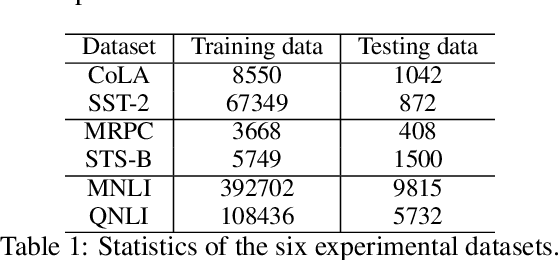
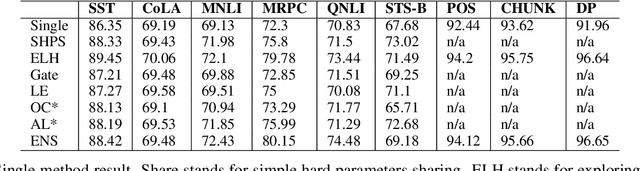
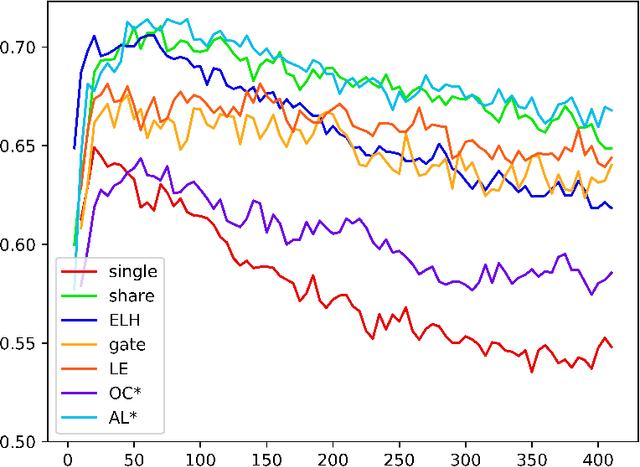
Multi-Task Learning (MTL) aims at boosting the overall performance of each individual task by leveraging useful information contained in multiple related tasks. It has shown great success in natural language processing (NLP). Currently, a number of MLT architectures and learning mechanisms have been proposed for various NLP tasks. However, there is no systematic exploration and comparison of different MLT architectures and learning mechanisms for their strong performance in-depth. In this paper, we conduct a thorough examination of typical MTL methods on a broad range of representative NLP tasks. Our primary goal is to understand the merits and demerits of existing MTL methods in NLP tasks, thus devising new hybrid architectures intended to combine their strengths.