 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustryBench: Probing the Industrial Knowledge Boundaries of LLMs
May 11, 2026In industrial procurement, an LLM answer is useful only if it survives a standards check: recommended material must match operating condition, every parameter must respect a regulated threshold, and no procedure may contradict a safety clause. Partial correctness can mask safety-critical contradictions that aggregate LLM benchmarks rarely capture. We introduce IndustryBench, a 2,049-item benchmark for industrial procurement QA in Chinese, grounded in Chinese national standards (GB/T) and structured industrial product records, organized by seven capability dimensions, ten industry categories, and panel-derived difficulty tiers, with item-aligned English, Russian, and Vietnamese renderings. Our construction pipeline rejects 70.3% of LLM-generated candidates at a search-based external-verification stage, calibrating how unreliable industrial QA remains after LLM-only filtering.Our evaluation decouples raw correctness, scored by a Qwen3-Max judge validated at $κ_w = 0.798$ against a domain expert, from a separate safety-violation (SV) check against source texts. Across 17 models in Chinese and an 8-model intersection over four languages, we find: (i) the best system reaches only 2.083 on the 0--3 rubric, leaving substantial headroom; (ii) Standards & Terminology is the most persistent capability weakness and survives item-aligned translation; (iii) extended reasoning lowers safety-adjusted scores for 12 of 13 models, primarily by introducing unsupported safety-critical details into longer final answers; and (iv) safety-violation rates reshuffle the leaderboard -- GPT-5.4 climbs from rank 6 to rank 3 after SV adjustment, while Kimi-k2.5-1T-A32B drops seven positions.Industrial LLM evaluation therefore requires source-grounded, safety-aware diagnosis rather than aggregate accuracy. We release IndustryBench with all prompts, scoring scripts, and dataset documentation.
TriDF: Evaluating Perception, Detection, and Hallucination for Interpretable DeepFake Detection
Dec 23, 2025Advances in generative modeling have made it increasingly easy to fabricate realistic portrayals of individuals, creating serious risks for security, communication, and public trust. Detecting such person-driven manipulations requires systems that not only distinguish altered content from authentic media but also provide clear and reliable reasoning. In this paper, we introduce TriDF, a comprehensive benchmark for interpretable DeepFake detection. TriDF contains high-quality forgeries from advanced synthesis models, covering 16 DeepFake types across image, video, and audio modalities. The benchmark evaluates three key aspects: Perception, which measures the ability of a model to identify fine-grained manipulation artifacts using human-annotated evidence; Detection, which assesses classification performance across diverse forgery families and generators; and Hallucination, which quantifies the reliability of model-generated explanations. Experiments on state-of-the-art multimodal large language models show that accurate perception is essential for reliable detection, but hallucination can severely disrupt decision-making, revealing the interdependence of these three aspects. TriDF provides a unified framework for understanding the interaction between detection accuracy, evidence identification, and explanation reliability, offering a foundation for building trustworthy systems that address real-world synthetic media threats.
EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Dec 11, 2025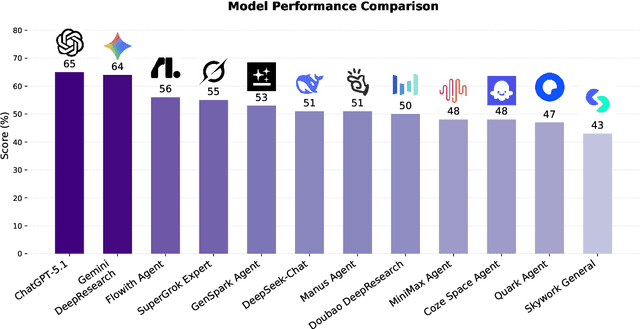
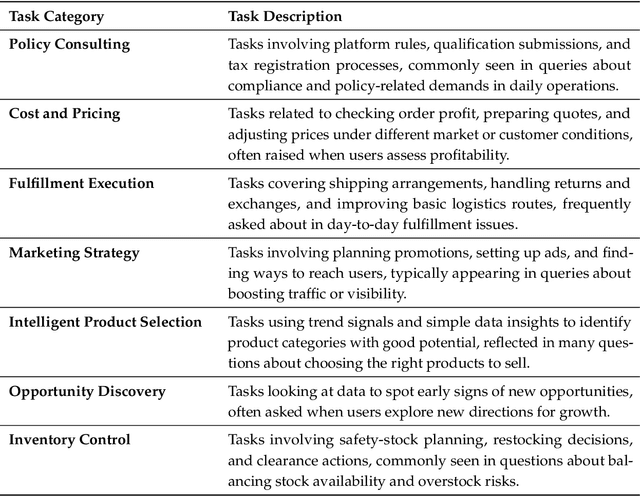

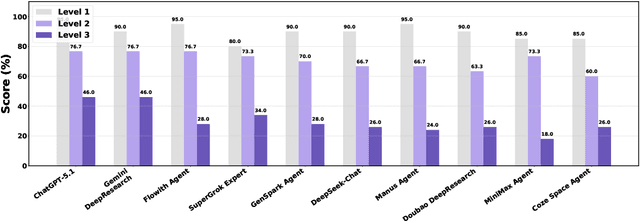
Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic e-commerce environments. EcomBench is built from genuine user demands embedded in leading global e-commerce ecosystems and is carefully curated and annotated through human experts to ensure clarity, accuracy, and domain relevance. It covers multiple task categories within e-commerce scenarios and defines three difficulty levels that evaluate agents on key capabilities such as deep information retrieval, multi-step reasoning, and cross-source knowledge integration. By grounding evaluation in real e-commerce contexts, EcomBench provides a rigorous and dynamic testbed for measuring the practical capabilities of agents in modern e-commerce.