 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHi-Net: Hybrid-fusion Network for Multi-modal MR Image Synthesis
Feb 11, 2020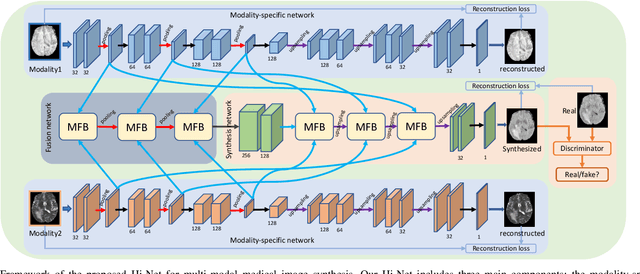
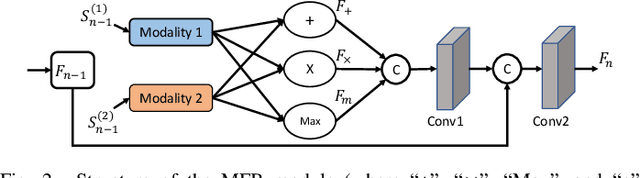
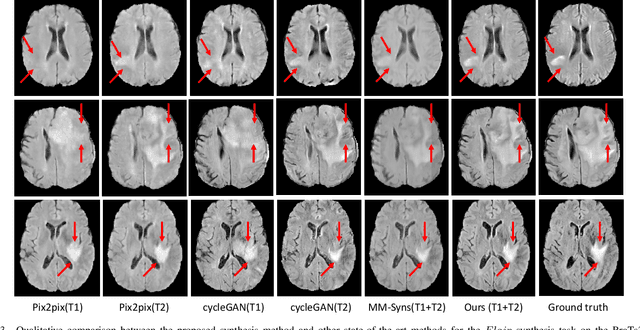
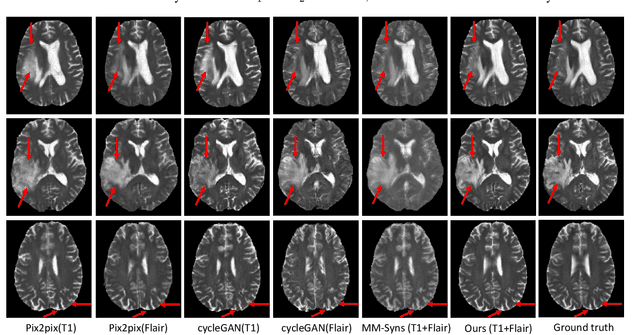
Magnetic resonance imaging (MRI) is a widely used neuroimaging technique that can provide images of different contrasts (i.e., modalities). Fusing this multi-modal data has proven particularly effective for boosting model performance in many tasks. However, due to poor data quality and frequent patient dropout, collecting all modalities for every patient remains a challenge. Medical image synthesis has been proposed as an effective solution to this, where any missing modalities are synthesized from the existing ones. In this paper, we propose a novel Hybrid-fusion Network (Hi-Net) for multi-modal MR image synthesis, which learns a mapping from multi-modal source images (i.e., existing modalities) to target images (i.e., missing modalities). In our Hi-Net, a modality-specific network is utilized to learn representations for each individual modality, and a fusion network is employed to learn the common latent representation of multi-modal data. Then, a multi-modal synthesis network is designed to densely combine the latent representation with hierarchical features from each modality, acting as a generator to synthesize the target images. Moreover, a layer-wise multi-modal fusion strategy is presented to effectively exploit the correlations among multiple modalities, in which a Mixed Fusion Block (MFB) is proposed to adaptively weight different fusion strategies (i.e., element-wise summation, product, and maximization). Extensive experiments demonstrate that the proposed model outperforms other state-of-the-art medical image synthesis methods.
PSC-Net: Learning Part Spatial Co-occurence for Occluded Pedestrian Detection
Jan 25, 2020

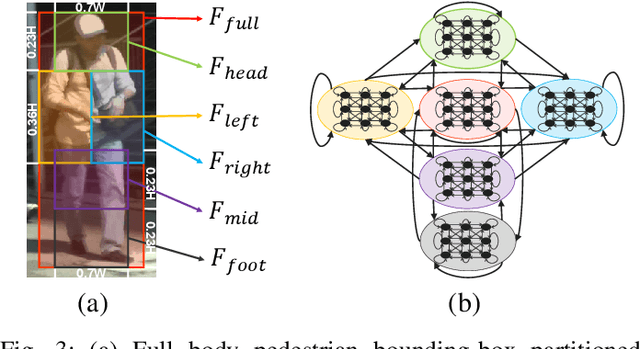
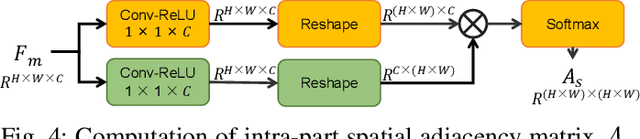
Detecting pedestrians, especially under heavy occlusions, is a challenging computer vision problem with numerous real-world applications. This paper introduces a novel approach, termed as PSC-Net, for occluded pedestrian detection. The proposed PSC-Net contains a dedicated module that is designed to explicitly capture both inter and intra-part co-occurrence information of different pedestrian body parts through a Graph Convolutional Network (GCN). Both inter and intra-part co-occurrence information contribute towards improving the feature representation for handling varying level of occlusions, ranging from partial to severe occlusions. Our PSC-Net exploits the topological structure of pedestrian and does not require part-based annotations or additional visible bounding-box (VBB) information to learn part spatial co-occurence. Comprehensive experiments are performed on two challenging datasets: CityPersons and Caltech datasets. The proposed PSC-Net achieives state-of-the-art detection performance on both. On the heavy occluded (HO) set of CityPerosns test set, our PSC-Net obtains an absolute gain of 3.6% in terms of log-average miss rate over the state-of-the-art with same backbone, input scale and without using additional VBB supervision. Further, PSC-Net improves the state-of-the-art from 37.9 to 34.9 in terms of log-average miss rate on Caltech (\textbf{HO}) test set.
Human-Aware Motion Deblurring
Jan 19, 2020


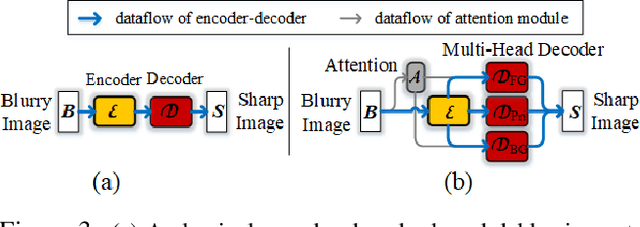
This paper proposes a human-aware deblurring model that disentangles the motion blur between foreground (FG) humans and background (BG). The proposed model is based on a triple-branch encoder-decoder architecture. The first two branches are learned for sharpening FG humans and BG details, respectively; while the third one produces global, harmonious results by comprehensively fusing multi-scale deblurring information from the two domains. The proposed model is further endowed with a supervised, human-aware attention mechanism in an end-to-end fashion. It learns a soft mask that encodes FG human information and explicitly drives the FG/BG decoder-branches to focus on their specific domains. To further benefit the research towards Human-aware Image Deblurring, we introduce a large-scale dataset, named HIDE, which consists of 8,422 blurry and sharp image pairs with 65,784 densely annotated FG human bounding boxes. HIDE is specifically built to span a broad range of scenes, human object sizes, motion patterns, and background complexities. Extensive experiments on public benchmarks and our dataset demonstrate that our model performs favorably against the state-of-the-art motion deblurring methods, especially in capturing semantic details.
See More, Know More: Unsupervised Video Object Segmentation with Co-Attention Siamese Networks
Jan 19, 2020
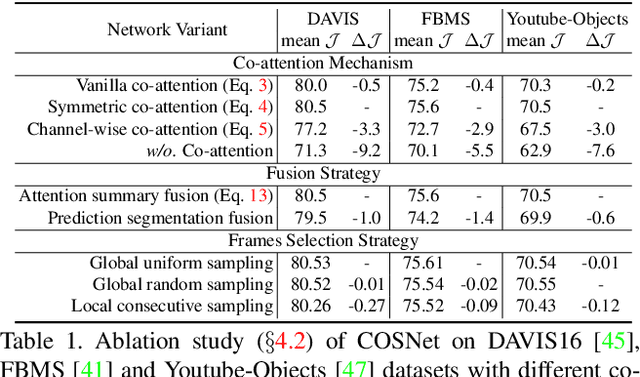
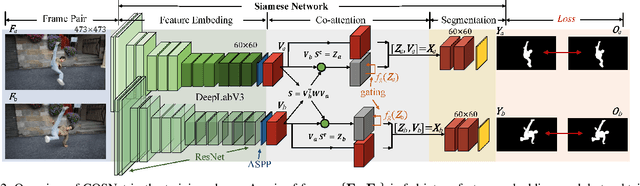
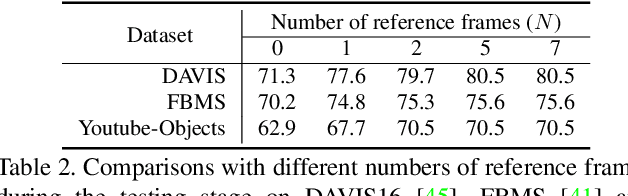
We introduce a novel network, called CO-attention Siamese Network (COSNet), to address the unsupervised video object segmentation task from a holistic view. We emphasize the importance of inherent correlation among video frames and incorporate a global co-attention mechanism to improve further the state-of-the-art deep learning based solutions that primarily focus on learning discriminative foreground representations over appearance and motion in short-term temporal segments. The co-attention layers in our network provide efficient and competent stages for capturing global correlations and scene context by jointly computing and appending co-attention responses into a joint feature space. We train COSNet with pairs of video frames, which naturally augments training data and allows increased learning capacity. During the segmentation stage, the co-attention model encodes useful information by processing multiple reference frames together, which is leveraged to infer the frequently reappearing and salient foreground objects better. We propose a unified and end-to-end trainable framework where different co-attention variants can be derived for mining the rich context within videos. Our extensive experiments over three large benchmarks manifest that COSNet outperforms the current alternatives by a large margin.
* CVPR2019. Weblink: https://github.com/carrierlxk/COSNet
Zero-Shot Video Object Segmentation via Attentive Graph Neural Networks
Jan 19, 2020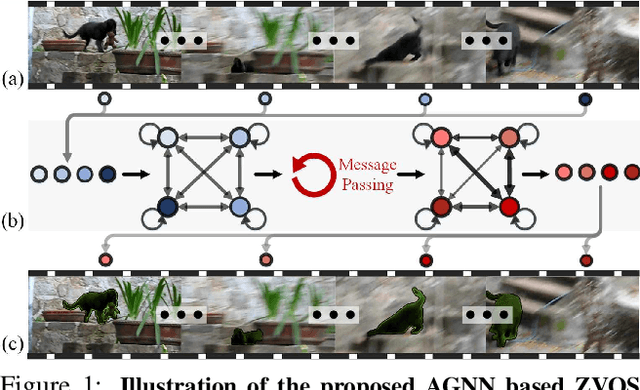

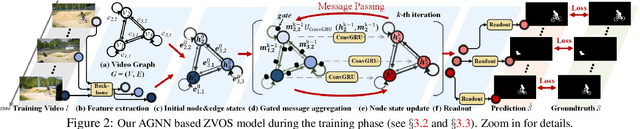
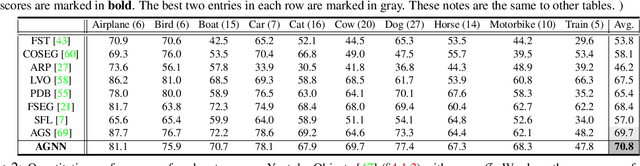
This work proposes a novel attentive graph neural network (AGNN) for zero-shot video object segmentation (ZVOS). The suggested AGNN recasts this task as a process of iterative information fusion over video graphs. Specifically, AGNN builds a fully connected graph to efficiently represent frames as nodes, and relations between arbitrary frame pairs as edges. The underlying pair-wise relations are described by a differentiable attention mechanism. Through parametric message passing, AGNN is able to efficiently capture and mine much richer and higher-order relations between video frames, thus enabling a more complete understanding of video content and more accurate foreground estimation. Experimental results on three video segmentation datasets show that AGNN sets a new state-of-the-art in each case. To further demonstrate the generalizability of our framework, we extend AGNN to an additional task: image object co-segmentation (IOCS). We perform experiments on two famous IOCS datasets and observe again the superiority of our AGNN model. The extensive experiments verify that AGNN is able to learn the underlying semantic/appearance relationships among video frames or related images, and discover the common objects.
* ICCV2019(Oral). Website: https://github.com/carrierlxk/AGNN
Learning Compositional Neural Information Fusion for Human Parsing
Jan 19, 2020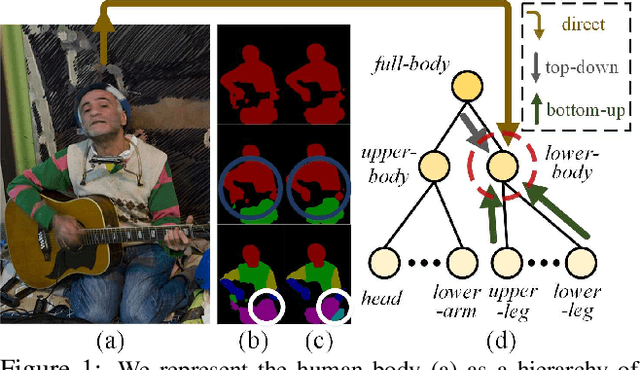
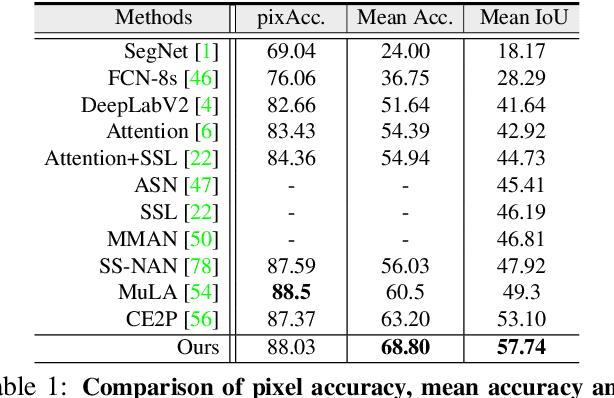
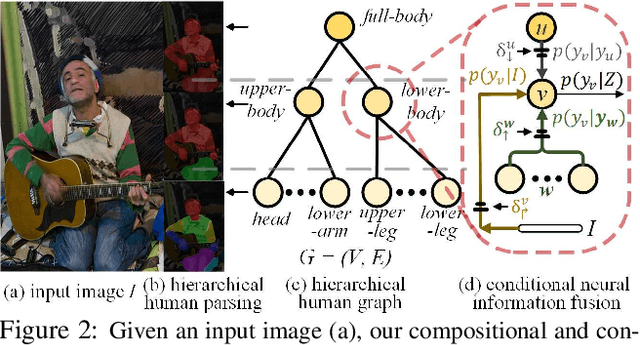
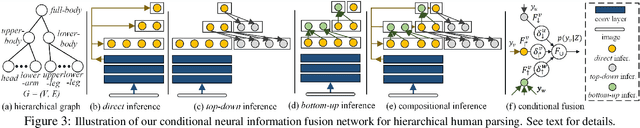
This work proposes to combine neural networks with the compositional hierarchy of human bodies for efficient and complete human parsing. We formulate the approach as a neural information fusion framework. Our model assembles the information from three inference processes over the hierarchy: direct inference (directly predicting each part of a human body using image information), bottom-up inference (assembling knowledge from constituent parts), and top-down inference (leveraging context from parent nodes). The bottom-up and top-down inferences explicitly model the compositional and decompositional relations in human bodies, respectively. In addition, the fusion of multi-source information is conditioned on the inputs, i.e., by estimating and considering the confidence of the sources. The whole model is end-to-end differentiable, explicitly modeling information flows and structures. Our approach is extensively evaluated on four popular datasets, outperforming the state-of-the-arts in all cases, with a fast processing speed of 23fps. Our code and results have been released to help ease future research in this direction.
* ICCV2019. Websie: https://github.com/ZzzjzzZ/CompositionalHumanParsing
NETNet: Neighbor Erasing and Transferring Network for Better Single Shot Object Detection
Jan 18, 2020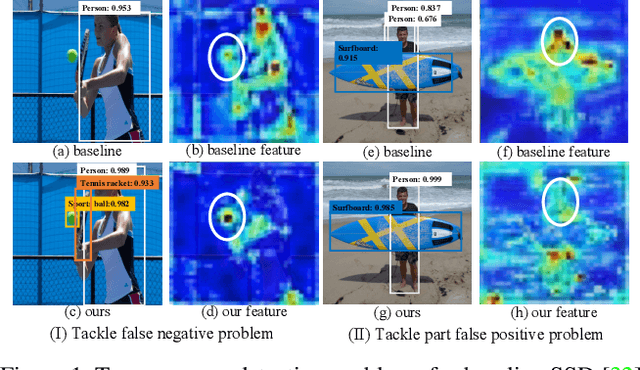
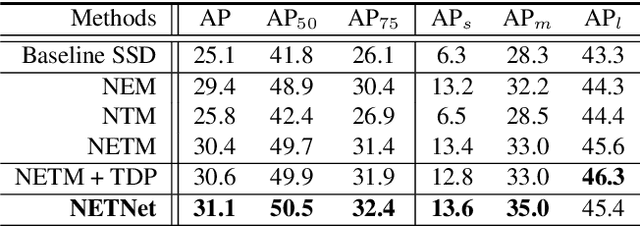
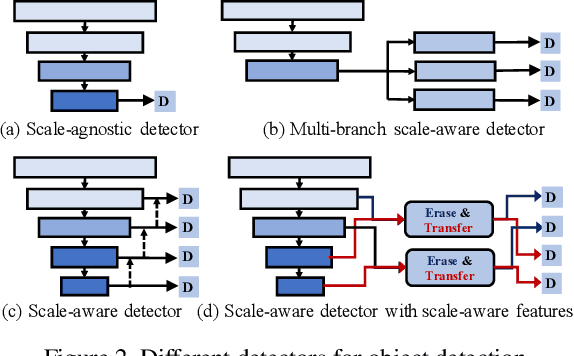
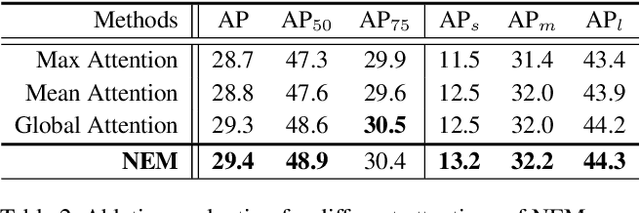
Due to the advantages of real-time detection and improved performance, single-shot detectors have gained great attention recently. To solve the complex scale variations, single-shot detectors make scale-aware predictions based on multiple pyramid layers. However, the features in the pyramid are not scale-aware enough, which limits the detection performance. Two common problems in single-shot detectors caused by object scale variations can be observed: (1) small objects are easily missed; (2) the salient part of a large object is sometimes detected as an object. With this observation, we propose a new Neighbor Erasing and Transferring (NET) mechanism to reconfigure the pyramid features and explore scale-aware features. In NET, a Neighbor Erasing Module (NEM) is designed to erase the salient features of large objects and emphasize the features of small objects in shallow layers. A Neighbor Transferring Module (NTM) is introduced to transfer the erased features and highlight large objects in deep layers. With this mechanism, a single-shot network called NETNet is constructed for scale-aware object detection. In addition, we propose to aggregate nearest neighboring pyramid features to enhance our NET. NETNet achieves 38.5% AP at a speed of 27 FPS and 32.0% AP at a speed of 55 FPS on MS COCO dataset. As a result, NETNet achieves a better trade-off for real-time and accurate object detection.
Deep Learning for Person Re-identification: A Survey and Outlook
Jan 13, 2020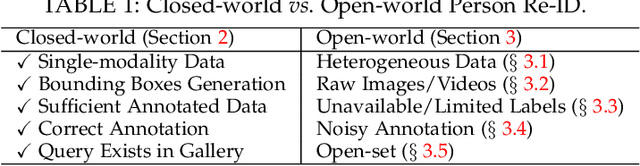

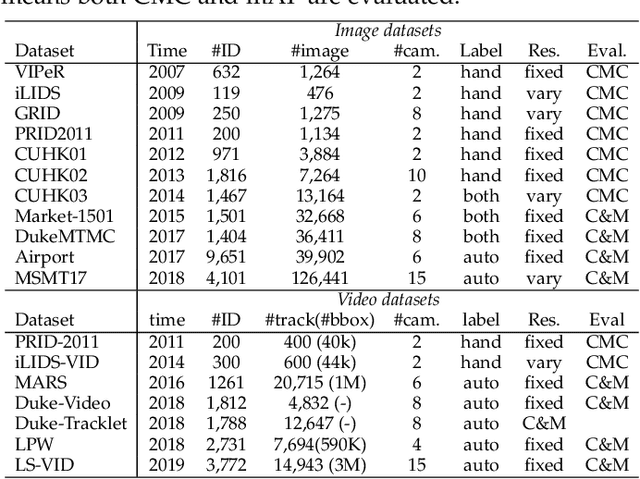
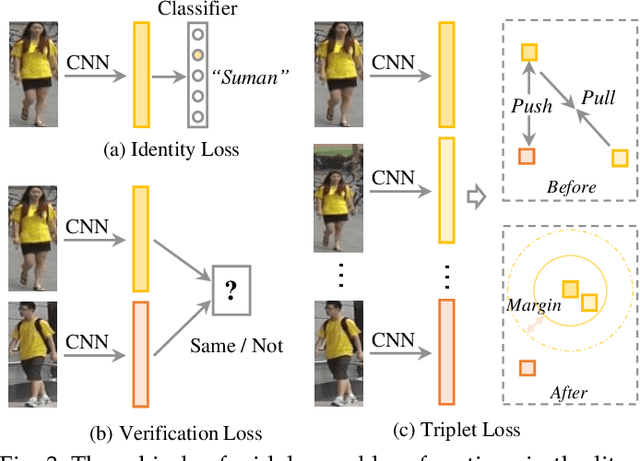
Person re-identification (Re-ID) aims at retrieving a person of interest across multiple non-overlapping cameras. With the advancement of deep neural networks and increasing demand of intelligent video surveillance, it has gained significantly increased interest in the computer vision community. By dissecting the involved components in developing a person Re-ID system, we categorize it into the closed-world and open-world settings. The widely studied closed-world setting is usually applied under various research-oriented assumptions, and has achieved inspiring success using deep learning techniques on a number of datasets. We first conduct a comprehensive overview with in-depth analysis for closed-world person Re-ID from three different perspectives, including deep feature representation learning, deep metric learning and ranking optimization. With the performance saturation under closed-world setting, the research focus for person Re-ID has recently shifted to the open-world setting, facing more challenging issues. This setting is closer to practical applications under specific scenarios. We summarize the open-world Re-ID in terms of five different aspects. By analyzing the advantages of existing methods, we design a powerful AGW baseline, achieving state-of-the-art or at least comparable performance on both single- and cross-modality Re-ID tasks. Meanwhile, we introduce a new evaluation metric (mINP) for person Re-ID, indicating the cost for finding all the correct matches, which provides an additional criteria to evaluate the Re-ID system for real applications. Finally, some important yet under-investigated open issues are discussed.
Fine-grained Recognition: Accounting for Subtle Differences between Similar Classes
Dec 14, 2019
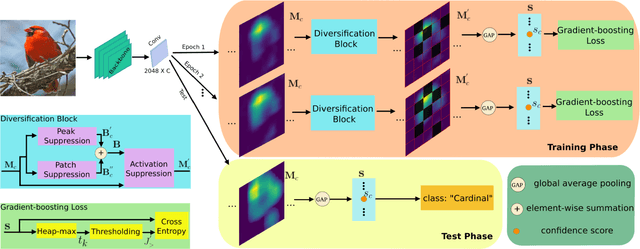
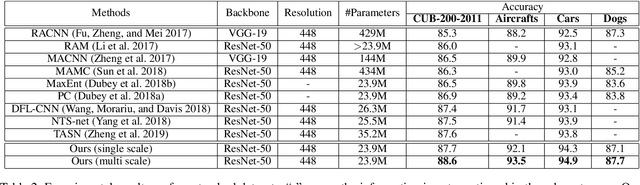
The main requisite for fine-grained recognition task is to focus on subtle discriminative details that make the subordinate classes different from each other. We note that existing methods implicitly address this requirement and leave it to a data-driven pipeline to figure out what makes a subordinate class different from the others. This results in two major limitations: First, the network focuses on the most obvious distinctions between classes and overlooks more subtle inter-class variations. Second, the chance of misclassifying a given sample in any of the negative classes is considered equal, while in fact, confusions generally occur among only the most similar classes. Here, we propose to explicitly force the network to find the subtle differences among closely related classes. In this pursuit, we introduce two key novelties that can be easily plugged into existing end-to-end deep learning pipelines. On one hand, we introduce diversification block which masks the most salient features for an input to force the network to use more subtle cues for its correct classification. Concurrently, we introduce a gradient-boosting loss function that focuses only on the confusing classes for each sample and therefore moves swiftly along the direction on the loss surface that seeks to resolve these ambiguities. The synergy between these two blocks helps the network to learn more effective feature representations. Comprehensive experiments are performed on five challenging datasets. Our approach outperforms existing methods using similar experimental setting on all five datasets.
Towards Partial Supervision for Generic Object Counting in Natural Scenes
Dec 13, 2019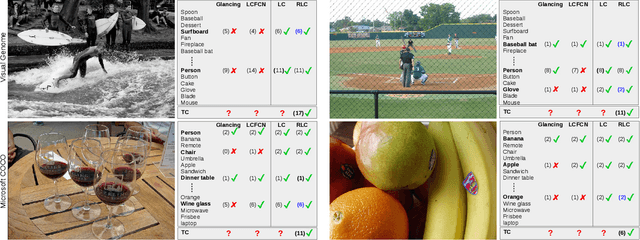

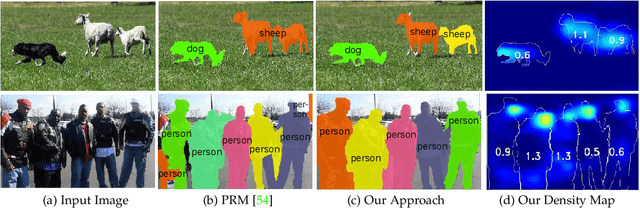
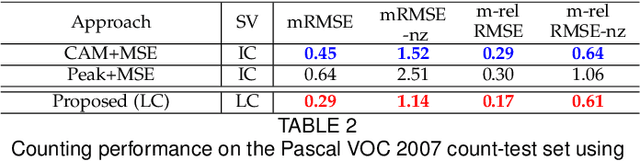
Generic object counting in natural scenes is a challenging computer vision problem. Existing approaches either rely on instance-level supervision or absolute count information to train a generic object counter. We introduce a partially supervised setting that significantly reduces the supervision level required for generic object counting. We propose two novel frameworks, named lower-count (LC) and reduced lower-count (RLC), to enable object counting under this setting. Our frameworks are built on a novel dual-branch architecture that has an image classification and a density branch. Our LC framework reduces the annotation cost due to multiple instances in an image by using only lower-count supervision for all object categories. Our RLC framework further reduces the annotation cost arising from large numbers of object categories in a dataset by only using lower-count supervision for a subset of categories and class-labels for the remaining ones. The RLC framework extends our dual-branch LC framework with a novel weight modulation layer and a category-independent density map prediction. Experiments are performed on COCO, Visual Genome and PASCAL 2007 datasets. Our frameworks perform on par with state-of-the-art approaches using higher levels of supervision. Additionally, we demonstrate the applicability of our LC supervised density map for image-level supervised instance segmentation.