 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Temporal Grounding with Structured Variational Cross-Graph Correspondence Learning
Mar 28, 2022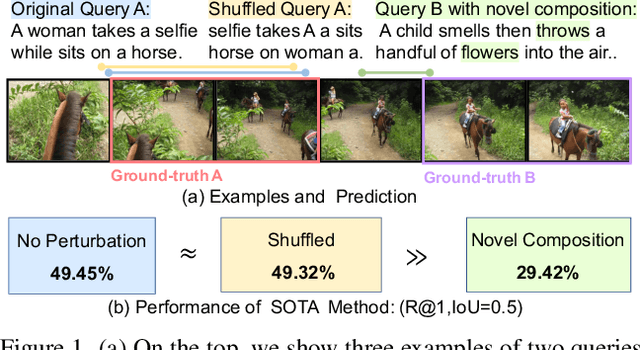
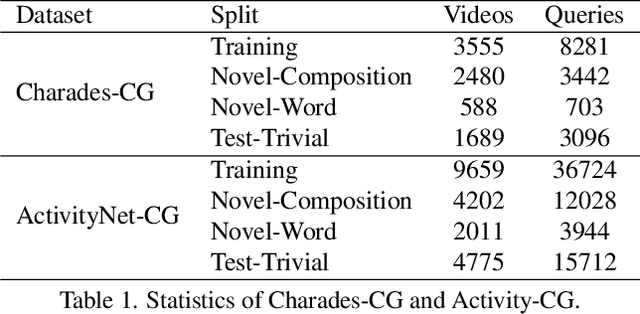
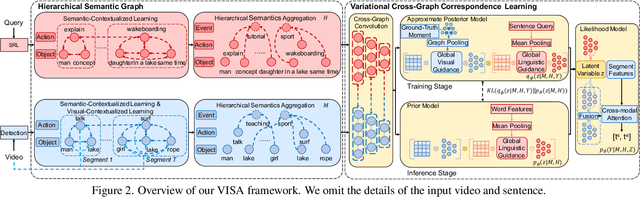
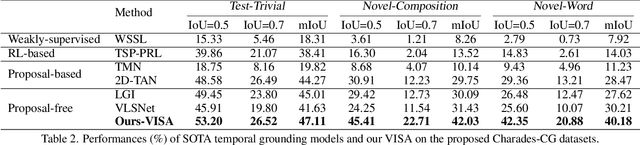
Temporal grounding in videos aims to localize one target video segment that semantically corresponds to a given query sentence. Thanks to the semantic diversity of natural language descriptions, temporal grounding allows activity grounding beyond pre-defined classes and has received increasing attention in recent years. The semantic diversity is rooted in the principle of compositionality in linguistics, where novel semantics can be systematically described by combining known words in novel ways (compositional generalization). However, current temporal grounding datasets do not specifically test for the compositional generalizability. To systematically measure the compositional generalizability of temporal grounding models, we introduce a new Compositional Temporal Grounding task and construct two new dataset splits, i.e., Charades-CG and ActivityNet-CG. Evaluating the state-of-the-art methods on our new dataset splits, we empirically find that they fail to generalize to queries with novel combinations of seen words. To tackle this challenge, we propose a variational cross-graph reasoning framework that explicitly decomposes video and language into multiple structured hierarchies and learns fine-grained semantic correspondence among them. Experiments illustrate the superior compositional generalizability of our approach. The repository of this work is at https://github.com/YYJMJC/ Compositional-Temporal-Grounding.
Vector-Decomposed Disentanglement for Domain-Invariant Object Detection
Aug 15, 2021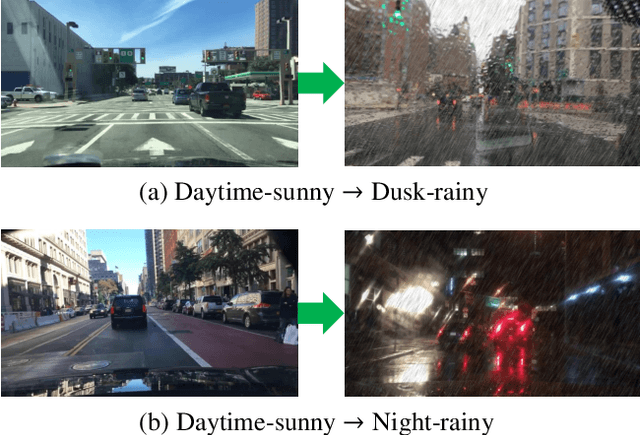
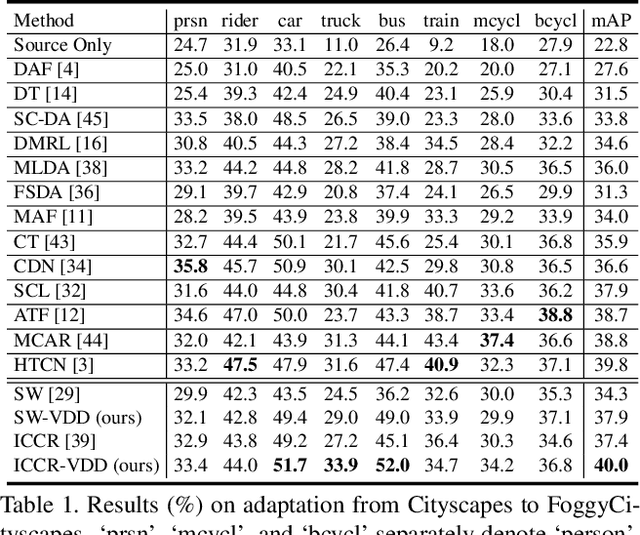
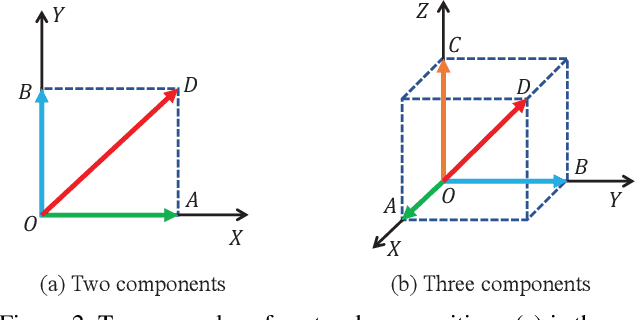
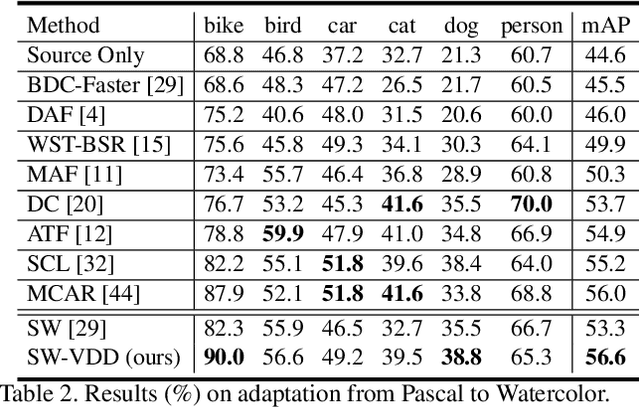
To improve the generalization of detectors, for domain adaptive object detection (DAOD), recent advances mainly explore aligning feature-level distributions between the source and single-target domain, which may neglect the impact of domain-specific information existing in the aligned features. Towards DAOD, it is important to extract domain-invariant object representations. To this end, in this paper, we try to disentangle domain-invariant representations from domain-specific representations. And we propose a novel disentangled method based on vector decomposition. Firstly, an extractor is devised to separate domain-invariant representations from the input, which are used for extracting object proposals. Secondly, domain-specific representations are introduced as the differences between the input and domain-invariant representations. Through the difference operation, the gap between the domain-specific and domain-invariant representations is enlarged, which promotes domain-invariant representations to contain more domain-irrelevant information. In the experiment, we separately evaluate our method on the single- and compound-target case. For the single-target case, experimental results of four domain-shift scenes show our method obtains a significant performance gain over baseline methods. Moreover, for the compound-target case (i.e., the target is a compound of two different domains without domain labels), our method outperforms baseline methods by around 4%, which demonstrates the effectiveness of our method.
Adaptive Hierarchical Graph Reasoning with Semantic Coherence for Video-and-Language Inference
Aug 09, 2021
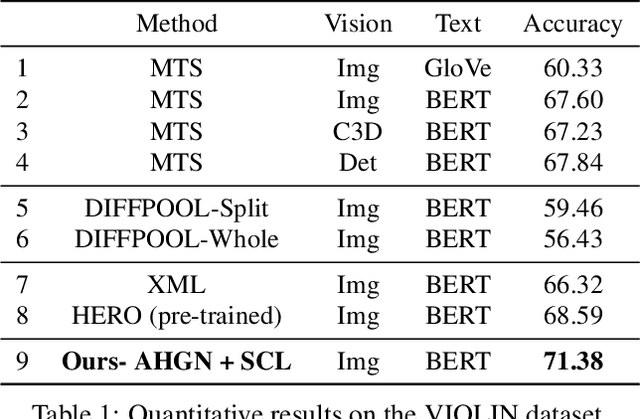
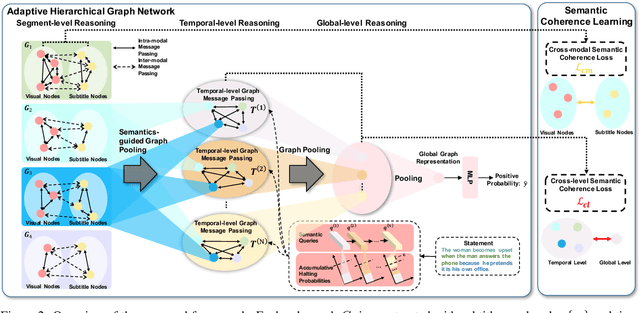

Video-and-Language Inference is a recently proposed task for joint video-and-language understanding. This new task requires a model to draw inference on whether a natural language statement entails or contradicts a given video clip. In this paper, we study how to address three critical challenges for this task: judging the global correctness of the statement involved multiple semantic meanings, joint reasoning over video and subtitles, and modeling long-range relationships and complex social interactions. First, we propose an adaptive hierarchical graph network that achieves in-depth understanding of the video over complex interactions. Specifically, it performs joint reasoning over video and subtitles in three hierarchies, where the graph structure is adaptively adjusted according to the semantic structures of the statement. Secondly, we introduce semantic coherence learning to explicitly encourage the semantic coherence of the adaptive hierarchical graph network from three hierarchies. The semantic coherence learning can further improve the alignment between vision and linguistics, and the coherence across a sequence of video segments. Experimental results show that our method significantly outperforms the baseline by a large margin.
Less is More: Sparse Sampling for Dense Reaction Predictions
Jun 03, 2021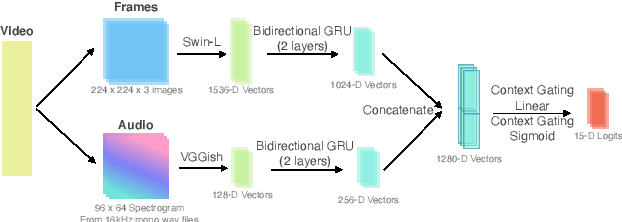
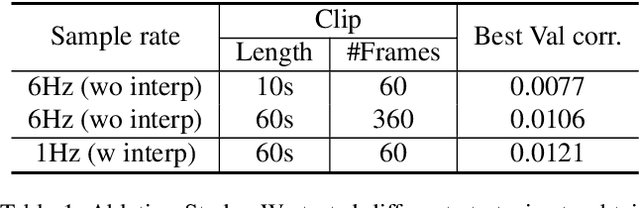
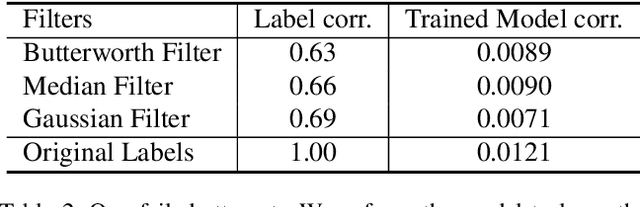
Obtaining viewer responses from videos can be useful for creators and streaming platforms to analyze the video performance and improve the future user experience. In this report, we present our method for 2021 Evoked Expression from Videos Challenge. In particular, our model utilizes both audio and image modalities as inputs to predict emotion changes of viewers. To model long-range emotion changes, we use a GRU-based model to predict one sparse signal with 1Hz. We observe that the emotion changes are smooth. Therefore, the final dense prediction is obtained via linear interpolating the signal, which is robust to the prediction fluctuation. Albeit simple, the proposed method has achieved pearson's correlation score of 0.04430 on the final private test set.
OR-Net: Pointwise Relational Inference for Data Completion under Partial Observation
May 05, 2021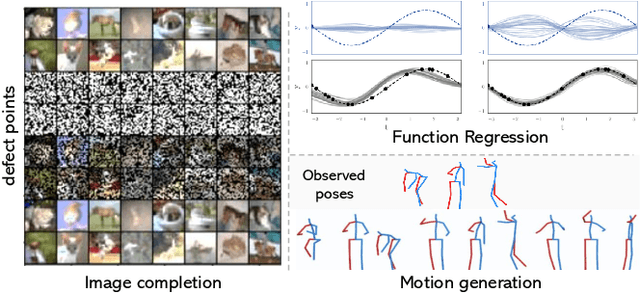
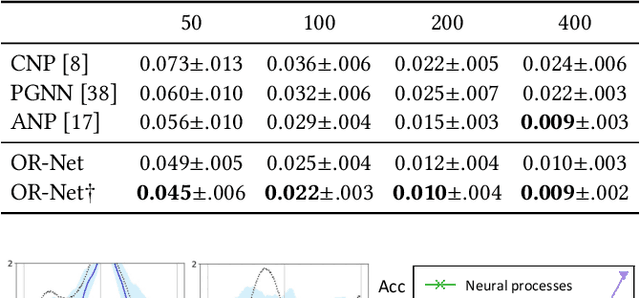
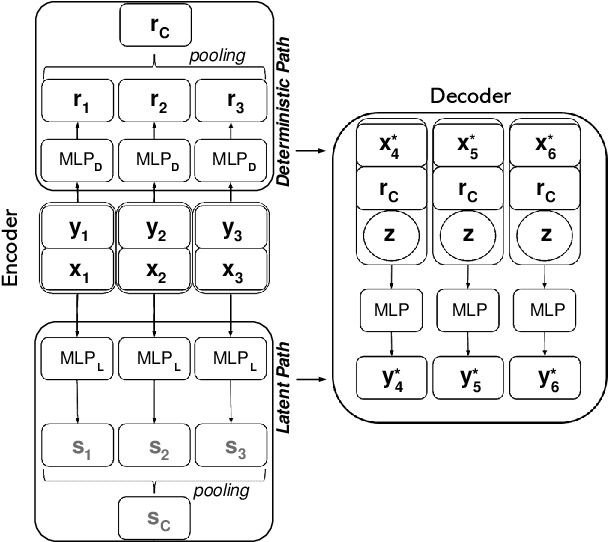
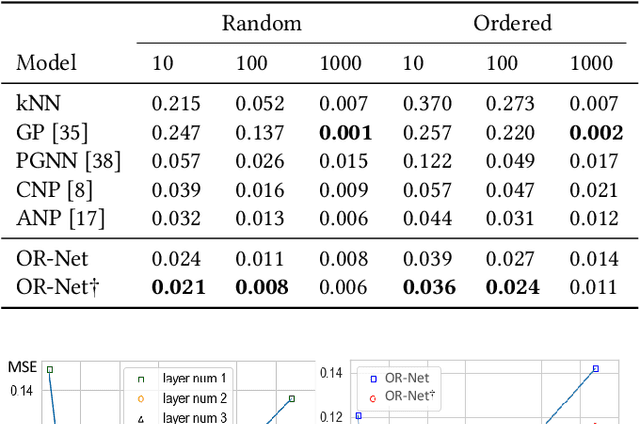
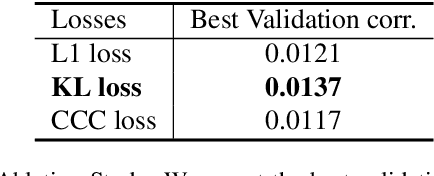
Contemporary data-driven methods are typically fed with full supervision on large-scale datasets which limits their applicability. However, in the actual systems with limitations such as measurement error and data acquisition problems, people usually obtain incomplete data. Although data completion has attracted wide attention, the underlying data pattern and relativity are still under-developed. Currently, the family of latent variable models allows learning deep latent variables over observed variables by fitting the marginal distribution. As far as we know, current methods fail to perceive the data relativity under partial observation. Aiming at modeling incomplete data, this work uses relational inference to fill in the incomplete data. Specifically, we expect to approximate the real joint distribution over the partial observation and latent variables, thus infer the unseen targets respectively. To this end, we propose Omni-Relational Network (OR-Net) to model the pointwise relativity in two aspects: (i) On one hand, the inner relationship is built among the context points in the partial observation; (ii) On the other hand, the unseen targets are inferred by learning the cross-relationship with the observed data points. It is further discovered that the proposed method can be generalized to different scenarios regardless of whether the physical structure can be observed or not. It is demonstrated that the proposed OR-Net can be well generalized for data completion tasks of various modalities, including function regression, image completion on MNIST and CelebA datasets, and also sequential motion generation conditioned on the observed poses.
Faster Meta Update Strategy for Noise-Robust Deep Learning
Apr 30, 2021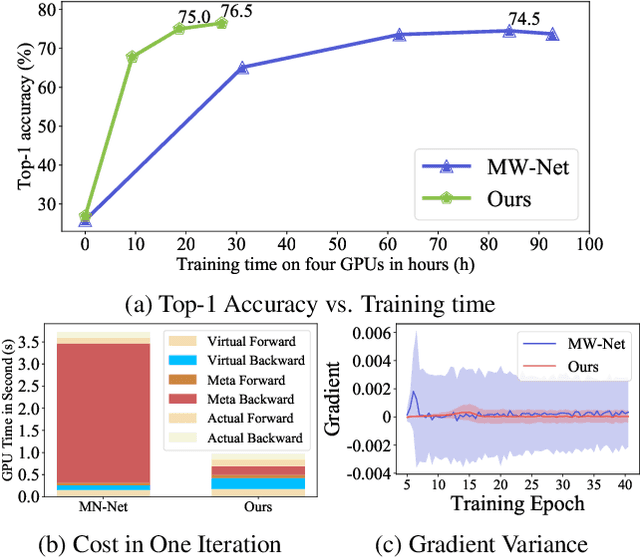
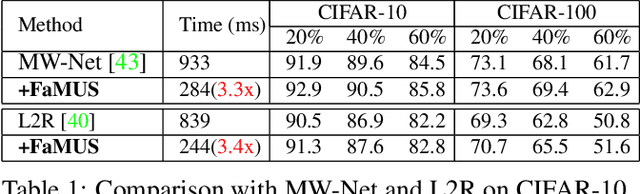
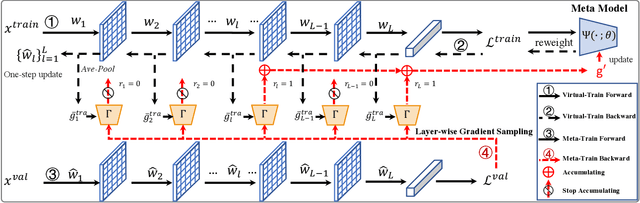
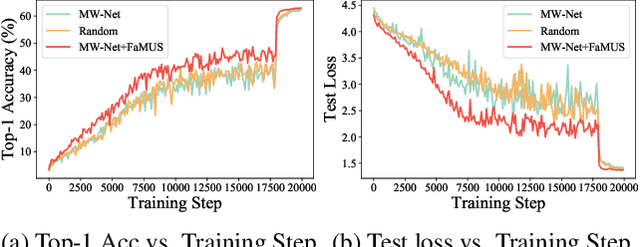
It has been shown that deep neural networks are prone to overfitting on biased training data. Towards addressing this issue, meta-learning employs a meta model for correcting the training bias. Despite the promising performances, super slow training is currently the bottleneck in the meta learning approaches. In this paper, we introduce a novel Faster Meta Update Strategy (FaMUS) to replace the most expensive step in the meta gradient computation with a faster layer-wise approximation. We empirically find that FaMUS yields not only a reasonably accurate but also a low-variance approximation of the meta gradient. We conduct extensive experiments to verify the proposed method on two tasks. We show our method is able to save two-thirds of the training time while still maintaining the comparable or achieving even better generalization performance. In particular, our method achieves the state-of-the-art performance on both synthetic and realistic noisy labels, and obtains promising performance on long-tailed recognition on standard benchmarks.
T2VLAD: Global-Local Sequence Alignment for Text-Video Retrieval
Apr 20, 2021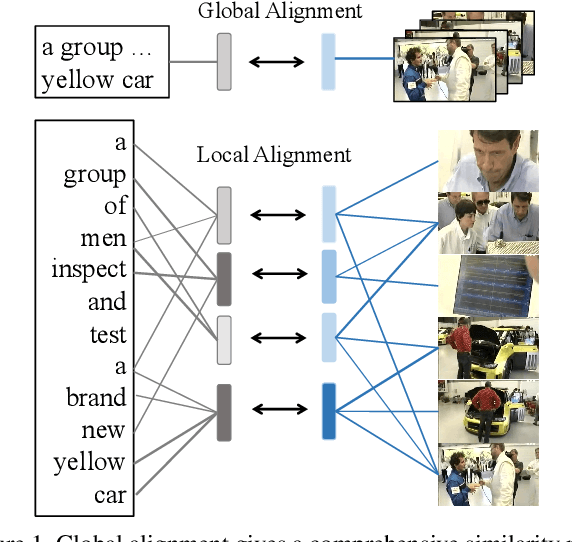
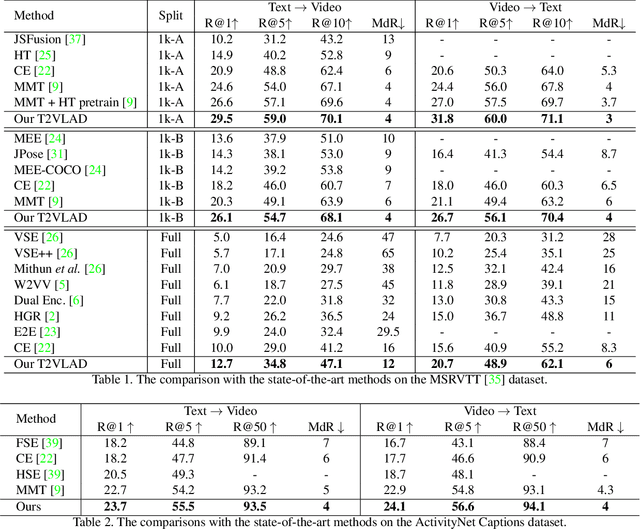
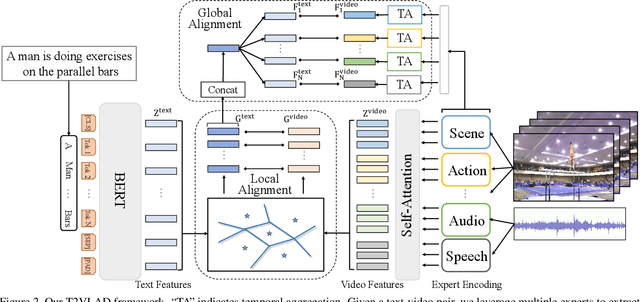
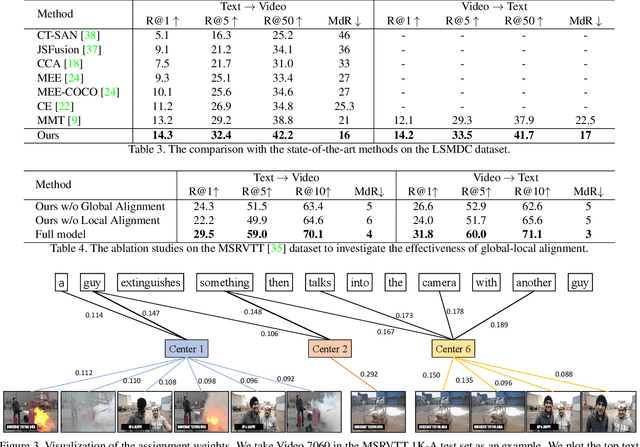
Text-video retrieval is a challenging task that aims to search relevant video contents based on natural language descriptions. The key to this problem is to measure text-video similarities in a joint embedding space. However, most existing methods only consider the global cross-modal similarity and overlook the local details. Some works incorporate the local comparisons through cross-modal local matching and reasoning. These complex operations introduce tremendous computation. In this paper, we design an efficient global-local alignment method. The multi-modal video sequences and text features are adaptively aggregated with a set of shared semantic centers. The local cross-modal similarities are computed between the video feature and text feature within the same center. This design enables the meticulous local comparison and reduces the computational cost of the interaction between each text-video pair. Moreover, a global alignment method is proposed to provide a global cross-modal measurement that is complementary to the local perspective. The global aggregated visual features also provide additional supervision, which is indispensable to the optimization of the learnable semantic centers. We achieve consistent improvements on three standard text-video retrieval benchmarks and outperform the state-of-the-art by a clear margin.
Universal-Prototype Augmentation for Few-Shot Object Detection
Mar 01, 2021
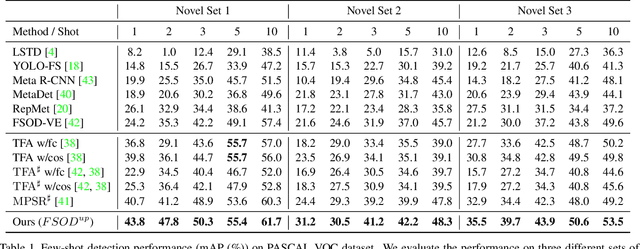
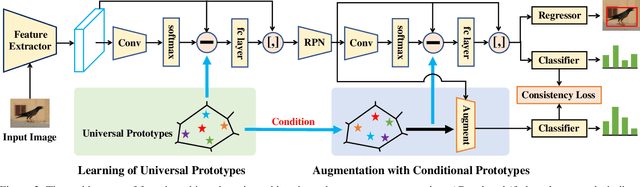
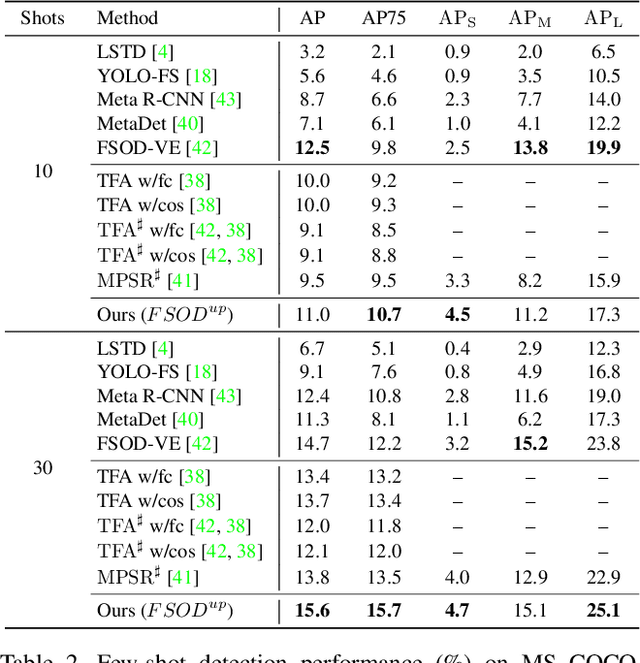
Few-shot object detection (FSOD) aims to strengthen the performance of novel object detection with few labeled samples. To alleviate the constraint of few samples, enhancing the generalization ability of learned features for novel objects plays a key role. Thus, the feature learning process of FSOD should focus more on intrinsical object characteristics, which are invariant under different visual changes and therefore are helpful for feature generalization. Unlike previous attempts of the meta-learning paradigm, in this paper, we explore how to smooth object features with intrinsical characteristics that are universal across different object categories. We propose a new prototype, namely universal prototype, that is learned from all object categories. Besides the advantage of characterizing invariant characteristics, the universal prototypes alleviate the impact of unbalanced object categories. After augmenting object features with the universal prototypes, we impose a consistency loss to maximize the agreement between the augmented features and the original one, which is beneficial for learning invariant object characteristics. Thus, we develop a new framework of few-shot object detection with universal prototypes (${FSOD}^{up}$) that owns the merit of feature generalization towards novel objects. Experimental results on PASCAL VOC and MS COCO demonstrate the effectiveness of ${FSOD}^{up}$. Particularly, for the 1-shot case of VOC Split2, ${FSOD}^{up}$ outperforms the baseline by 6.8\% in terms of mAP. Moreover, we further verify ${FSOD}^{up}$ on a long-tail detection dataset, i.e., LVIS. And employing ${FSOD}^{up}$ outperforms the state-of-the-art method.
Learning to Anticipate Egocentric Actions by Imagination
Jan 19, 2021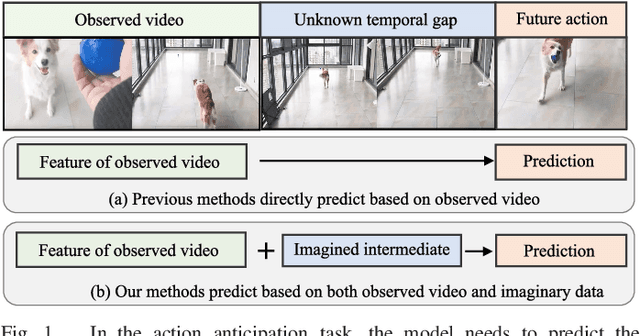
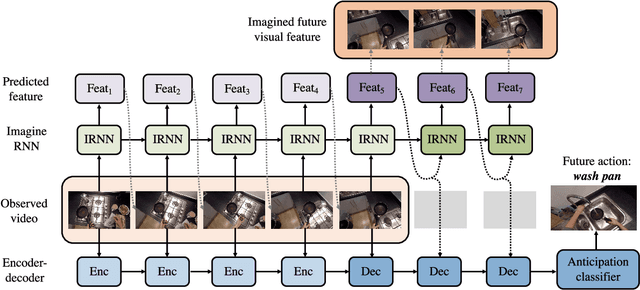
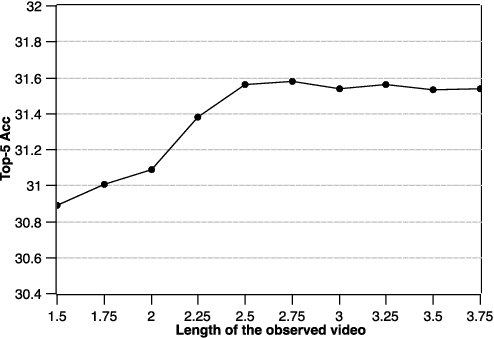
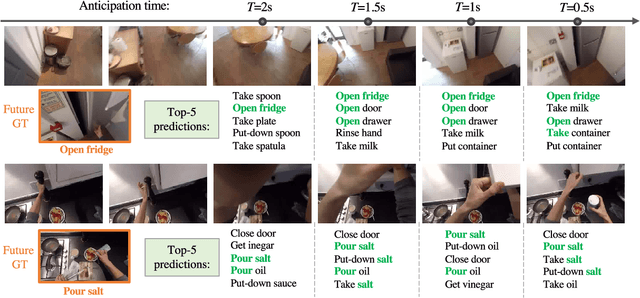
Anticipating actions before they are executed is crucial for a wide range of practical applications, including autonomous driving and robotics. In this paper, we study the egocentric action anticipation task, which predicts future action seconds before it is performed for egocentric videos. Previous approaches focus on summarizing the observed content and directly predicting future action based on past observations. We believe it would benefit the action anticipation if we could mine some cues to compensate for the missing information of the unobserved frames. We then propose to decompose the action anticipation into a series of future feature predictions. We imagine how the visual feature changes in the near future and then predicts future action labels based on these imagined representations. Differently, our ImagineRNN is optimized in a contrastive learning way instead of feature regression. We utilize a proxy task to train the ImagineRNN, i.e., selecting the correct future states from distractors. We further improve ImagineRNN by residual anticipation, i.e., changing its target to predicting the feature difference of adjacent frames instead of the frame content. This promotes the network to focus on our target, i.e., the future action, as the difference between adjacent frame features is more important for forecasting the future. Extensive experiments on two large-scale egocentric action datasets validate the effectiveness of our method. Our method significantly outperforms previous methods on both the seen test set and the unseen test set of the EPIC Kitchens Action Anticipation Challenge.
* Accepted to IEEE Transactions on Image Processing (TIP)
SemGloVe: Semantic Co-occurrences for GloVe from BERT
Dec 30, 2020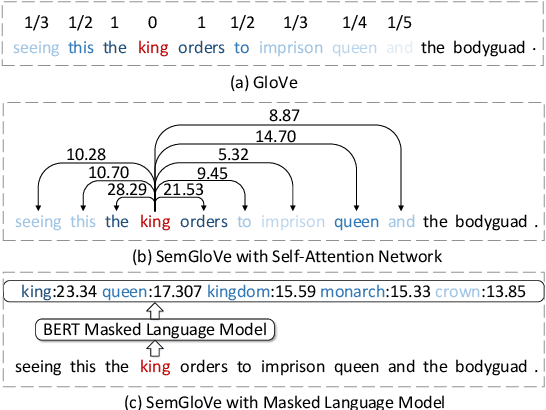
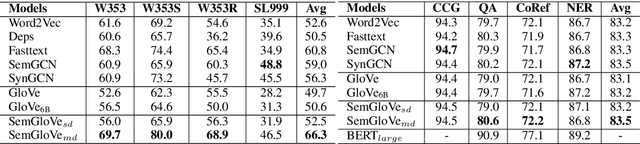
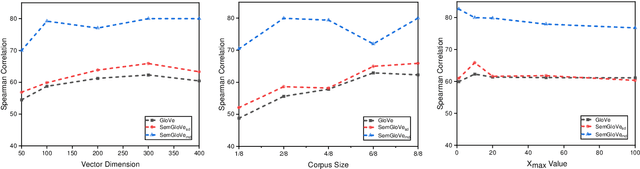

GloVe learns word embeddings by leveraging statistical information from word co-occurrence matrices. However, word pairs in the matrices are extracted from a predefined local context window, which might lead to limited word pairs and potentially semantic irrelevant word pairs. In this paper, we propose SemGloVe, which distills semantic co-occurrences from BERT into static GloVe word embeddings. Particularly, we propose two models to extract co-occurrence statistics based on either the masked language model or the multi-head attention weights of BERT. Our methods can extract word pairs without limiting by the local window assumption and can define the co-occurrence weights by directly considering the semantic distance between word pairs. Experiments on several word similarity datasets and four external tasks show that SemGloVe can outperform GloVe.