 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLASFNet: A Lightweight Attention-Guided Self-Modulation Feature Fusion Network for Multimodal Object Detection
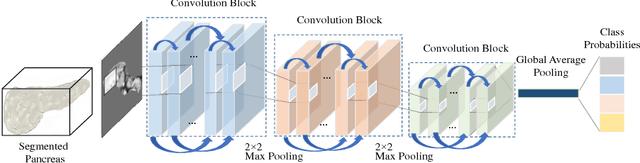
Jun 26, 2025Effective deep feature extraction via feature-level fusion is crucial for multimodal object detection. However, previous studies often involve complex training processes that integrate modality-specific features by stacking multiple feature-level fusion units, leading to significant computational overhead. To address this issue, we propose a new fusion detection baseline that uses a single feature-level fusion unit to enable high-performance detection, thereby simplifying the training process. Based on this approach, we propose a lightweight attention-guided self-modulation feature fusion network (LASFNet), which introduces a novel attention-guided self-modulation feature fusion (ASFF) module that adaptively adjusts the responses of fusion features at both global and local levels based on attention information from different modalities, thereby promoting comprehensive and enriched feature generation. Additionally, a lightweight feature attention transformation module (FATM) is designed at the neck of LASFNet to enhance the focus on fused features and minimize information loss. Extensive experiments on three representative datasets demonstrate that, compared to state-of-the-art methods, our approach achieves a favorable efficiency-accuracy trade-off, reducing the number of parameters and computational cost by as much as 90% and 85%, respectively, while improving detection accuracy (mAP) by 1%-3%. The code will be open-sourced at https://github.com/leileilei2000/LASFNet.
Robust Kidney Abnormality Segmentation: A Validation Study of an AI-Based Framework
May 12, 2025Kidney abnormality segmentation has important potential to enhance the clinical workflow, especially in settings requiring quantitative assessments. Kidney volume could serve as an important biomarker for renal diseases, with changes in volume correlating directly with kidney function. Currently, clinical practice often relies on subjective visual assessment for evaluating kidney size and abnormalities, including tumors and cysts, which are typically staged based on diameter, volume, and anatomical location. To support a more objective and reproducible approach, this research aims to develop a robust, thoroughly validated kidney abnormality segmentation algorithm, made publicly available for clinical and research use. We employ publicly available training datasets and leverage the state-of-the-art medical image segmentation framework nnU-Net. Validation is conducted using both proprietary and public test datasets, with segmentation performance quantified by Dice coefficient and the 95th percentile Hausdorff distance. Furthermore, we analyze robustness across subgroups based on patient sex, age, CT contrast phases, and tumor histologic subtypes. Our findings demonstrate that our segmentation algorithm, trained exclusively on publicly available data, generalizes effectively to external test sets and outperforms existing state-of-the-art models across all tested datasets. Subgroup analyses reveal consistent high performance, indicating strong robustness and reliability. The developed algorithm and associated code are publicly accessible at https://github.com/DIAGNijmegen/oncology-kidney-abnormality-segmentation.
Incorporating Anatomical Awareness for Enhanced Generalizability and Progression Prediction in Deep Learning-Based Radiographic Sacroiliitis Detection
May 12, 2024



Purpose: To examine whether incorporating anatomical awareness into a deep learning model can improve generalizability and enable prediction of disease progression. Methods: This retrospective multicenter study included conventional pelvic radiographs of 4 different patient cohorts focusing on axial spondyloarthritis (axSpA) collected at university and community hospitals. The first cohort, which consisted of 1483 radiographs, was split into training (n=1261) and validation (n=222) sets. The other cohorts comprising 436, 340, and 163 patients, respectively, were used as independent test datasets. For the second cohort, follow-up data of 311 patients was used to examine progression prediction capabilities. Two neural networks were trained, one on images cropped to the bounding box of the sacroiliac joints (anatomy-aware) and the other one on full radiographs. The performance of the models was compared using the area under the receiver operating characteristic curve (AUC), accuracy, sensitivity, and specificity. Results: On the three test datasets, the standard model achieved AUC scores of 0.853, 0.817, 0.947, with an accuracy of 0.770, 0.724, 0.850. Whereas the anatomy-aware model achieved AUC scores of 0.899, 0.846, 0.957, with an accuracy of 0.821, 0.744, 0.906, respectively. The patients who were identified as high risk by the anatomy aware model had an odds ratio of 2.16 (95% CI: 1.19, 3.86) for having progression of radiographic sacroiliitis within 2 years. Conclusion: Anatomical awareness can improve the generalizability of a deep learning model in detecting radiographic sacroiliitis. The model is published as fully open source alongside this study.
MRSegmentator: Robust Multi-Modality Segmentation of 40 Classes in MRI and CT Sequences
May 10, 2024



Purpose: To introduce a deep learning model capable of multi-organ segmentation in MRI scans, offering a solution to the current limitations in MRI analysis due to challenges in resolution, standardized intensity values, and variability in sequences. Materials and Methods: he model was trained on 1,200 manually annotated MRI scans from the UK Biobank, 221 in-house MRI scans and 1228 CT scans, leveraging cross-modality transfer learning from CT segmentation models. A human-in-the-loop annotation workflow was employed to efficiently create high-quality segmentations. The model's performance was evaluated on NAKO and the AMOS22 dataset containing 600 and 60 MRI examinations. Dice Similarity Coefficient (DSC) and Hausdorff Distance (HD) was used to assess segmentation accuracy. The model will be open sourced. Results: The model showcased high accuracy in segmenting well-defined organs, achieving Dice Similarity Coefficient (DSC) scores of 0.97 for the right and left lungs, and 0.95 for the heart. It also demonstrated robustness in organs like the liver (DSC: 0.96) and kidneys (DSC: 0.95 left, 0.95 right), which present more variability. However, segmentation of smaller and complex structures such as the portal and splenic veins (DSC: 0.54) and adrenal glands (DSC: 0.65 left, 0.61 right) revealed the need for further model optimization. Conclusion: The proposed model is a robust, tool for accurate segmentation of 40 anatomical structures in MRI and CT images. By leveraging cross-modality learning and interactive annotation, the model achieves strong performance and generalizability across diverse datasets, making it a valuable resource for researchers and clinicians. It is open source and can be downloaded from https://github.com/hhaentze/MRSegmentator.
Improve Cross-Modality Segmentation by Treating MRI Images as Inverted CT Scans
May 04, 2024



Computed tomography (CT) segmentation models frequently include classes that are not currently supported by magnetic resonance imaging (MRI) segmentation models. In this study, we show that a simple image inversion technique can significantly improve the segmentation quality of CT segmentation models on MRI data, by using the TotalSegmentator model, applied to T1-weighted MRI images, as example. Image inversion is straightforward to implement and does not require dedicated graphics processing units (GPUs), thus providing a quick alternative to complex deep modality-transfer models for generating segmentation masks for MRI data.
MEDBERT.de: A Comprehensive German BERT Model for the Medical Domain
Mar 24, 2023



This paper presents medBERTde, a pre-trained German BERT model specifically designed for the German medical domain. The model has been trained on a large corpus of 4.7 Million German medical documents and has been shown to achieve new state-of-the-art performance on eight different medical benchmarks covering a wide range of disciplines and medical document types. In addition to evaluating the overall performance of the model, this paper also conducts a more in-depth analysis of its capabilities. We investigate the impact of data deduplication on the model's performance, as well as the potential benefits of using more efficient tokenization methods. Our results indicate that domain-specific models such as medBERTde are particularly useful for longer texts, and that deduplication of training data does not necessarily lead to improved performance. Furthermore, we found that efficient tokenization plays only a minor role in improving model performance, and attribute most of the improved performance to the large amount of training data. To encourage further research, the pre-trained model weights and new benchmarks based on radiological data are made publicly available for use by the scientific community.
Machine-Generated Hierarchical Structure of Human Activities to Reveal How Machines Think
Jan 19, 2021
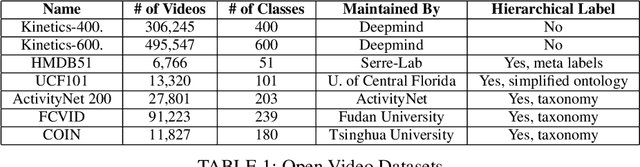
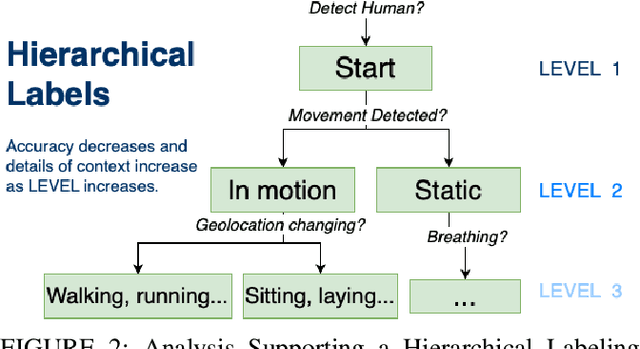
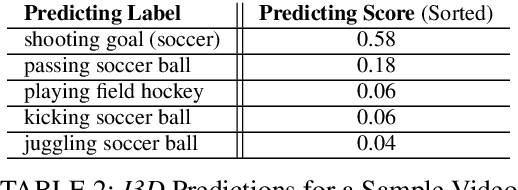
Deep-learning based computer vision models have proved themselves to be ground-breaking approaches to human activity recognition (HAR). However, most existing works are dedicated to improve the prediction accuracy through either creating new model architectures, increasing model complexity, or refining model parameters by training on larger datasets. Here, we propose an alternative idea, differing from existing work, to increase model accuracy and also to shape model predictions to align with human understandings through automatically creating higher-level summarizing labels for similar groups of human activities. First, we argue the importance and feasibility of constructing a hierarchical labeling system for human activity recognition. Then, we utilize the predictions of a black box HAR model to identify similarities between different activities. Finally, we tailor hierarchical clustering methods to automatically generate hierarchical trees of activities and conduct experiments. In this system, the activity labels on the same level will have a designed magnitude of accuracy and reflect a specific amount of activity details. This strategy enables a trade-off between the extent of the details in the recognized activity and the user privacy by masking some sensitive predictions; and also provides possibilities for the use of formerly prohibited invasive models in privacy-concerned scenarios. Since the hierarchy is generated from the machine's perspective, the predictions at the upper levels provide better accuracy, which is especially useful when there are too detailed labels in the training set that are rather trivial to the final prediction goal. Moreover, the analysis of the structure of these trees can reveal the biases in the prediction model and guide future data collection strategies.
Explainable Text-Driven Neural Network for Stock Prediction
Feb 13, 2019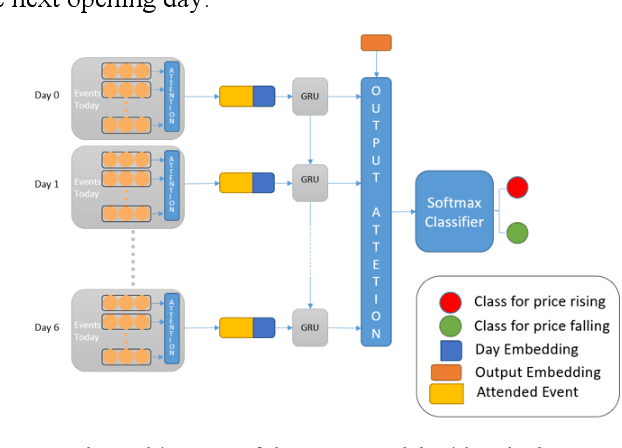
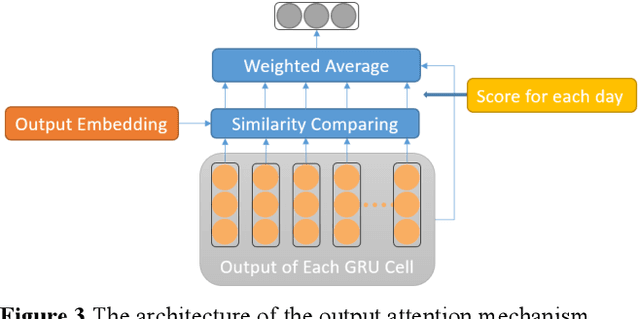

It has been shown that financial news leads to the fluctuation of stock prices. However, previous work on news-driven financial market prediction focused only on predicting stock price movement without providing an explanation. In this paper, we propose a dual-layer attention-based neural network to address this issue. In the initial stage, we introduce a knowledge-based method to adaptively extract relevant financial news. Then, we use input attention to pay more attention to the more influential news and concatenate the day embeddings with the output of the news representation. Finally, we use an output attention mechanism to allocate different weights to different days in terms of their contribution to stock price movement. Thorough empirical studies based upon historical prices of several individual stocks demonstrate the superiority of our proposed method in stock price prediction compared to state-of-the-art methods.
* 10 pages, Proceedings of CCIS2018
Differential Diagnosis for Pancreatic Cysts in CT Scans Using Densely-Connected Convolutional Networks
Jun 19, 2018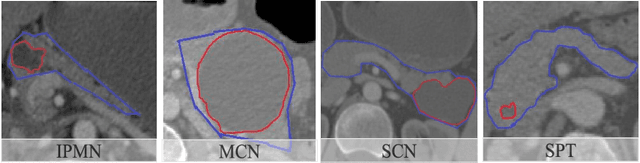

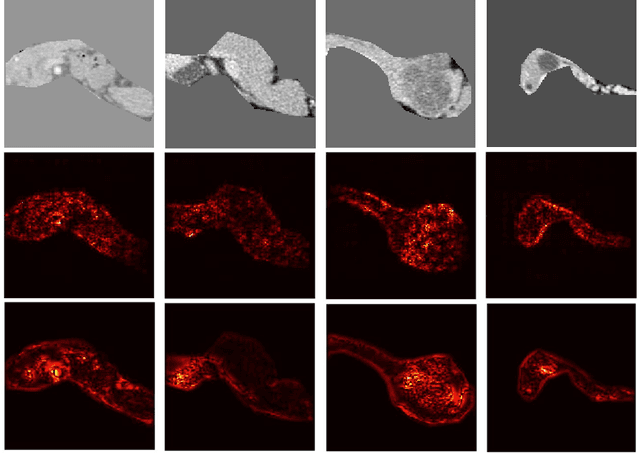
The lethal nature of pancreatic ductal adenocarcinoma (PDAC) calls for early differential diagnosis of pancreatic cysts, which are identified in up to 16% of normal subjects, and some of which may develop into PDAC. Previous computer-aided developments have achieved certain accuracy for classification on segmented cystic lesions in CT. However, pancreatic cysts have a large variation in size and shape, and the precise segmentation of them remains rather challenging, which restricts the computer-aided interpretation of CT images acquired for differential diagnosis. We propose a computer-aided framework for early differential diagnosis of pancreatic cysts without pre-segmenting the lesions using densely-connected convolutional networks (Dense-Net). The Dense-Net learns high-level features from whole abnormal pancreas and builds mappings between medical imaging appearance to different pathological types of pancreatic cysts. To enhance the clinical applicability, we integrate saliency maps in the framework to assist the physicians to understand the decision of the deep learning method. The test on a cohort of 206 patients with 4 pathologically confirmed subtypes of pancreatic cysts has achieved an overall accuracy of 72.8%, which is significantly higher than the baseline accuracy of 48.1%, which strongly supports the clinical potential of our developed method.
Video Compressive Sensing for Spatial Multiplexing Cameras using Motion-Flow Models
Aug 05, 2015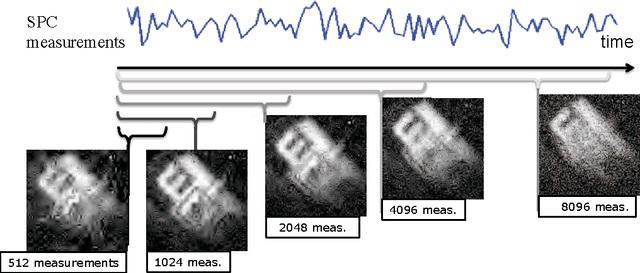
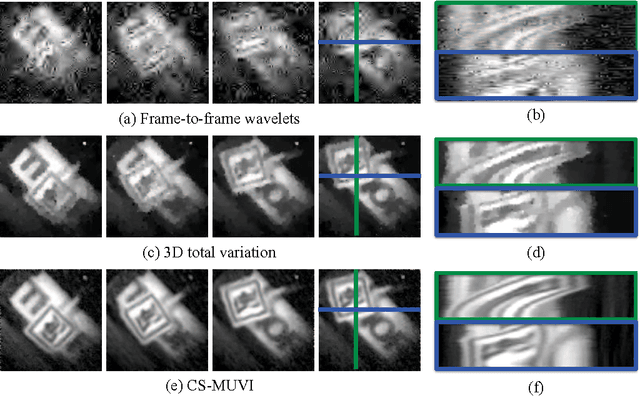
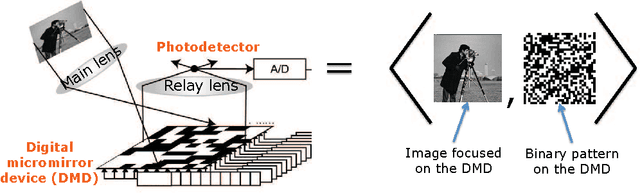
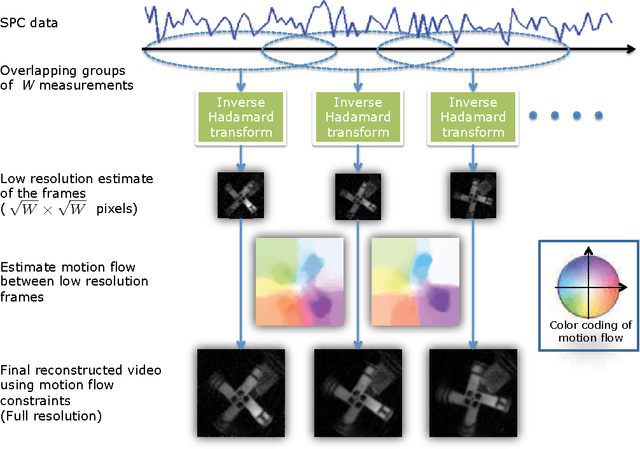
Spatial multiplexing cameras (SMCs) acquire a (typically static) scene through a series of coded projections using a spatial light modulator (e.g., a digital micro-mirror device) and a few optical sensors. This approach finds use in imaging applications where full-frame sensors are either too expensive (e.g., for short-wave infrared wavelengths) or unavailable. Existing SMC systems reconstruct static scenes using techniques from compressive sensing (CS). For videos, however, existing acquisition and recovery methods deliver poor quality. In this paper, we propose the CS multi-scale video (CS-MUVI) sensing and recovery framework for high-quality video acquisition and recovery using SMCs. Our framework features novel sensing matrices that enable the efficient computation of a low-resolution video preview, while enabling high-resolution video recovery using convex optimization. To further improve the quality of the reconstructed videos, we extract optical-flow estimates from the low-resolution previews and impose them as constraints in the recovery procedure. We demonstrate the efficacy of our CS-MUVI framework for a host of synthetic and real measured SMC video data, and we show that high-quality videos can be recovered at roughly $60\times$ compression.