 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Text Generation by Learning from Search
Jul 09, 2020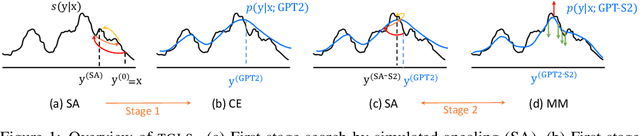
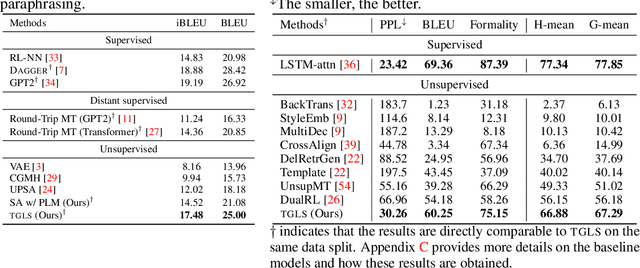
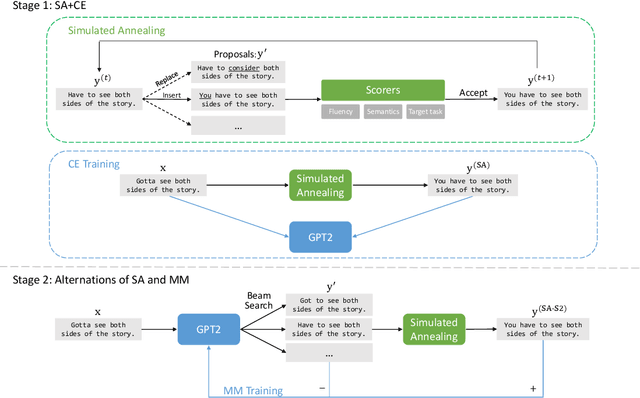
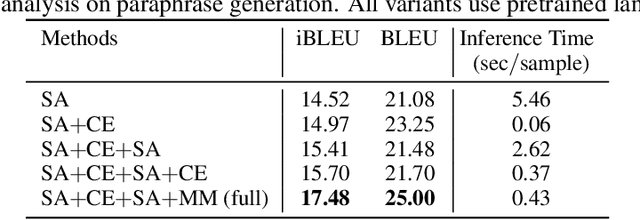
In this work, we present TGLS, a novel framework to unsupervised Text Generation by Learning from Search. We start by applying a strong search algorithm (in particular, simulated annealing) towards a heuristically defined objective that (roughly) estimates the quality of sentences. Then, a conditional generative model learns from the search results, and meanwhile smooth out the noise of search. The alternation between search and learning can be repeated for performance bootstrapping. We demonstrate the effectiveness of TGLS on two real-world natural language generation tasks, paraphrase generation and text formalization. Our model significantly outperforms unsupervised baseline methods in both tasks. Especially, it achieves comparable performance with the state-of-the-art supervised methods in paraphrase generation.
Iterative Edit-Based Unsupervised Sentence Simplification
Jun 17, 2020
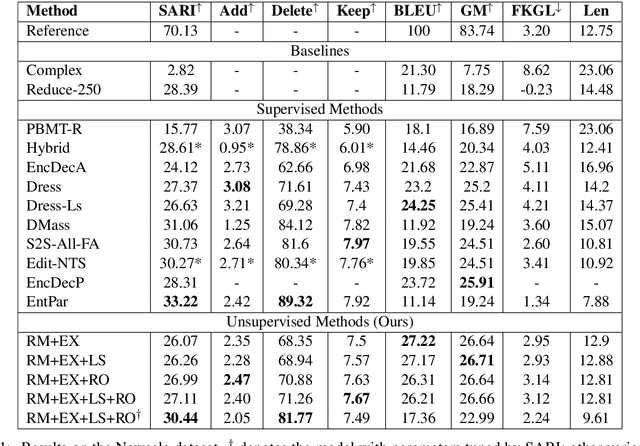
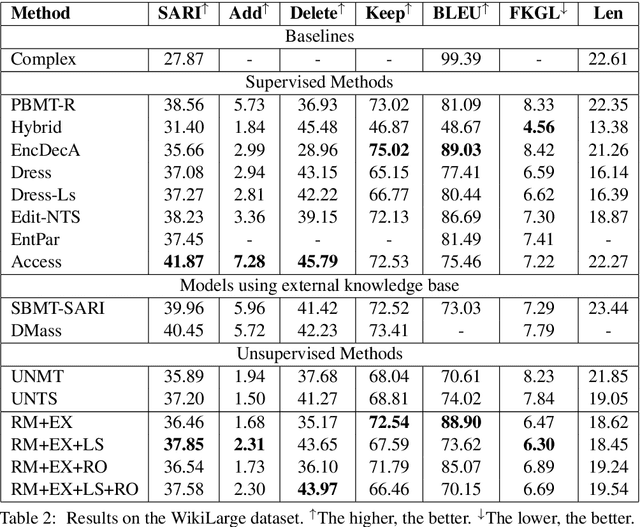
We present a novel iterative, edit-based approach to unsupervised sentence simplification. Our model is guided by a scoring function involving fluency, simplicity, and meaning preservation. Then, we iteratively perform word and phrase-level edits on the complex sentence. Compared with previous approaches, our model does not require a parallel training set, but is more controllable and interpretable. Experiments on Newsela and WikiLarge datasets show that our approach is nearly as effective as state-of-the-art supervised approaches.
Discrete Optimization for Unsupervised Sentence Summarization with Word-Level Extraction
May 04, 2020
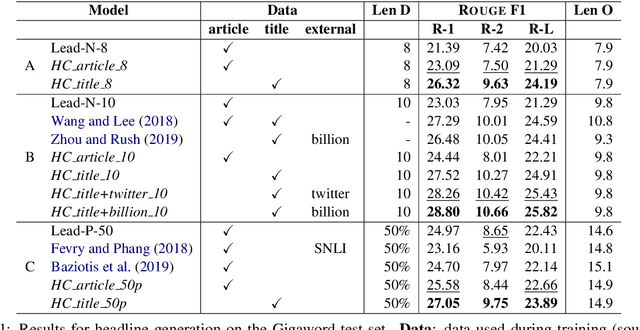
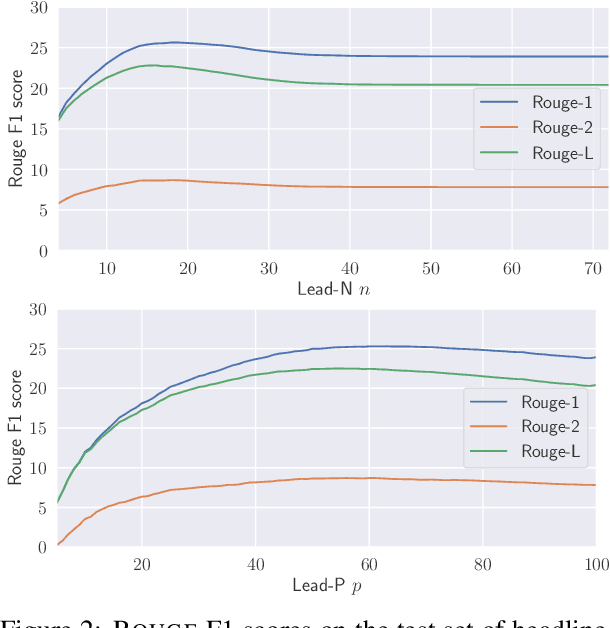
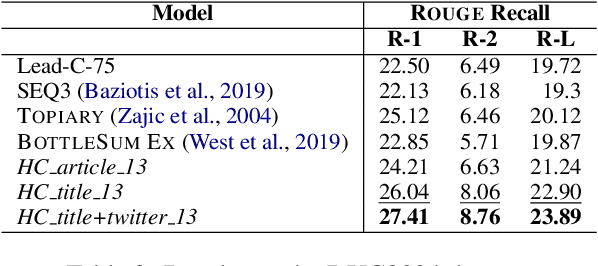
Automatic sentence summarization produces a shorter version of a sentence, while preserving its most important information. A good summary is characterized by language fluency and high information overlap with the source sentence. We model these two aspects in an unsupervised objective function, consisting of language modeling and semantic similarity metrics. We search for a high-scoring summary by discrete optimization. Our proposed method achieves a new state-of-the art for unsupervised sentence summarization according to ROUGE scores. Additionally, we demonstrate that the commonly reported ROUGE F1 metric is sensitive to summary length. Since this is unwillingly exploited in recent work, we emphasize that future evaluation should explicitly group summarization systems by output length brackets.
How Chaotic Are Recurrent Neural Networks?
Apr 28, 2020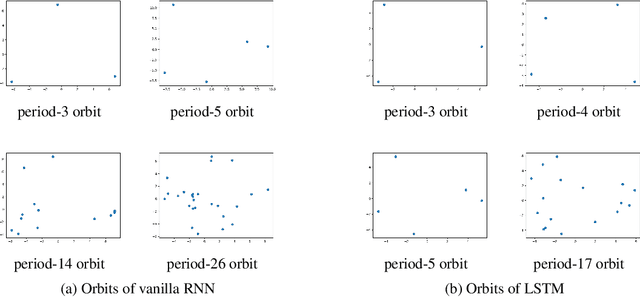


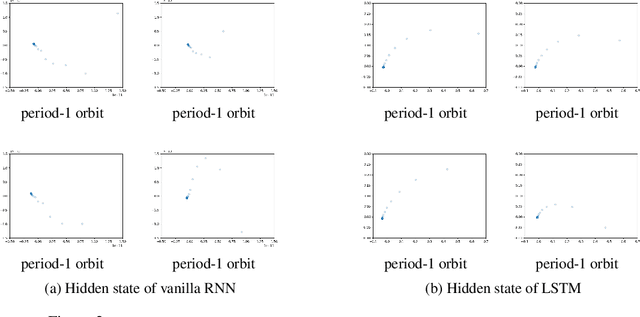
Recurrent neural networks (RNNs) are non-linear dynamic systems. Previous work believes that RNN may suffer from the phenomenon of chaos, where the system is sensitive to initial states and unpredictable in the long run. In this paper, however, we perform a systematic empirical analysis, showing that a vanilla or long short term memory (LSTM) RNN does not exhibit chaotic behavior along the training process in real applications such as text generation. Our findings suggest that future work in this direction should address the other side of non-linear dynamics for RNN.
TreeGen: A Tree-Based Transformer Architecture for Code Generation
Nov 28, 2019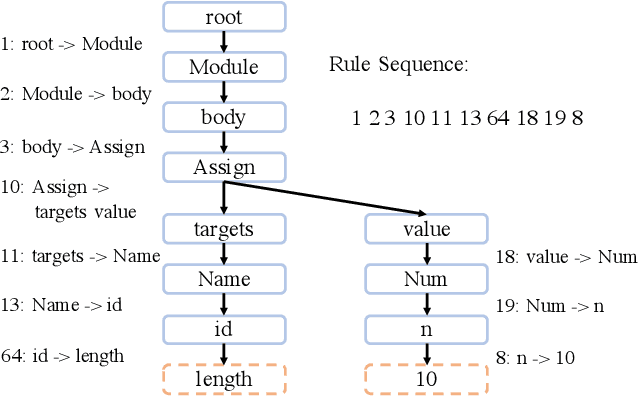
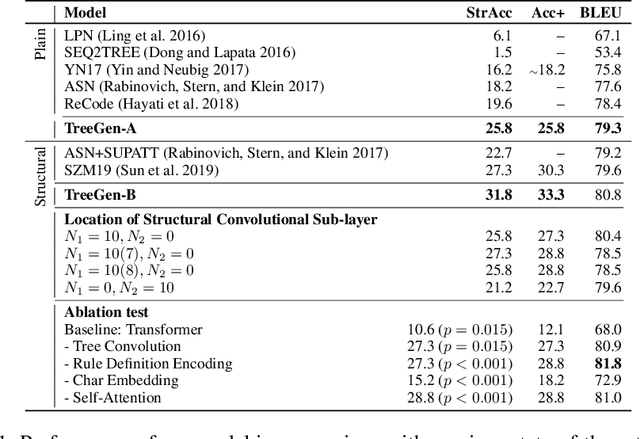
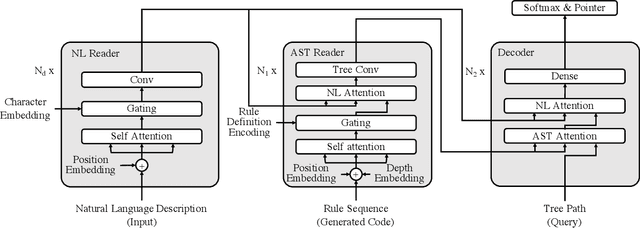
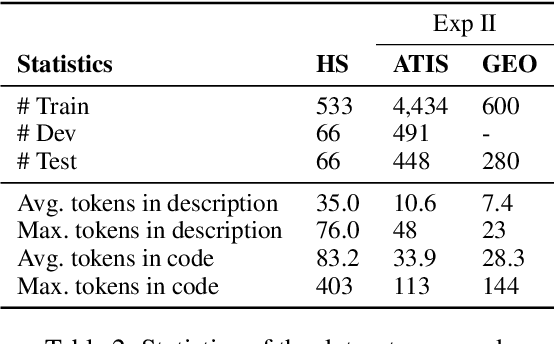
A code generation system generates programming language code based on an input natural language description. State-of-the-art approaches rely on neural networks for code generation. However, these code generators suffer from two problems. One is the long dependency problem, where a code element often depends on another far-away code element. A variable reference, for example, depends on its definition, which may appear quite a few lines before. The other problem is structure modeling, as programs contain rich structural information. In this paper, we propose a novel tree-based neural architecture, TreeGen, for code generation. TreeGen uses the attention mechanism of Transformers to alleviate the long-dependency problem, and introduces a novel AST reader (encoder) to incorporate grammar rules and AST structures into the network. We evaluated TreeGen on a Python benchmark, HearthStone, and two semantic parsing benchmarks, ATIS and GEO. TreeGen outperformed the previous state-of-the-art approach by 4.5 percentage points on HearthStone, and achieved the best accuracy among neural network-based approaches on ATIS (89.1%) and GEO (89.6%). We also conducted an ablation test to better understand each component of our model.
Stylized Text Generation Using Wasserstein Autoencoders with a Mixture of Gaussian Prior
Nov 10, 2019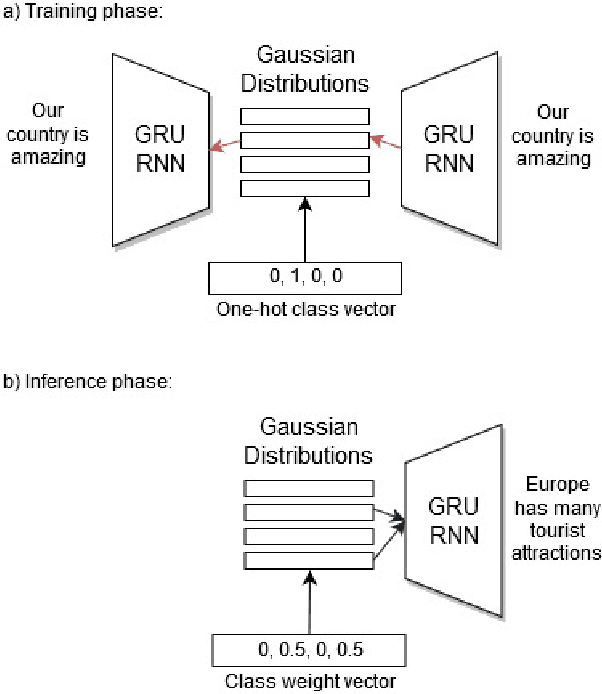
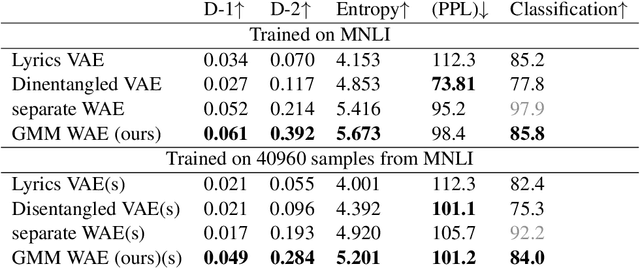

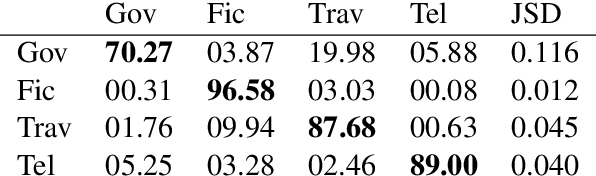
Wasserstein autoencoders are effective for text generation. They do not however provide any control over the style and topic of the generated sentences if the dataset has multiple classes and includes different topics. In this work, we present a semi-supervised approach for generating stylized sentences. Our model is trained on a multi-class dataset and learns the latent representation of the sentences using a mixture of Gaussian prior without any adversarial losses. This allows us to generate sentences in the style of a specified class or multiple classes by sampling from their corresponding prior distributions. Moreover, we can train our model on relatively small datasets and learn the latent representation of a specified class by adding external data with other styles/classes to our dataset. While a simple WAE or VAE cannot generate diverse sentences in this case, generated sentences with our approach are diverse, fluent, and preserve the style and the content of the desired classes.
Conditional Response Generation Using Variational Alignment
Nov 10, 2019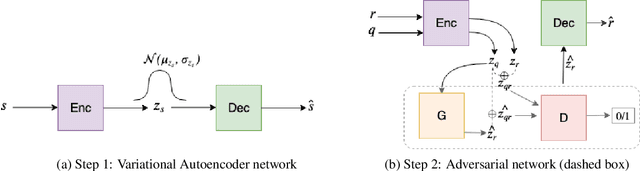
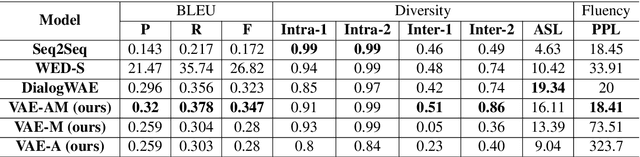
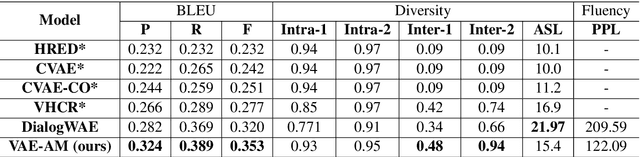
Generating relevant/conditioned responses in dialog is challenging, and requires not only proper modelling of context in the conversation, but also the ability to generate fluent sentences during inference. In this paper, we propose a two-step framework based on generative adversarial nets for generating conditioned responses. Our model first learns meaningful representations of sentences, and then uses a generator to \textit{match} the query with the response distribution. Latent codes from the latter are then used to generate responses. Both quantitative and qualitative evaluations show that our model generates more fluent, relevant and diverse responses than the existing state-of-the-art methods.
Unsupervised Paraphrasing by Simulated Annealing
Sep 10, 2019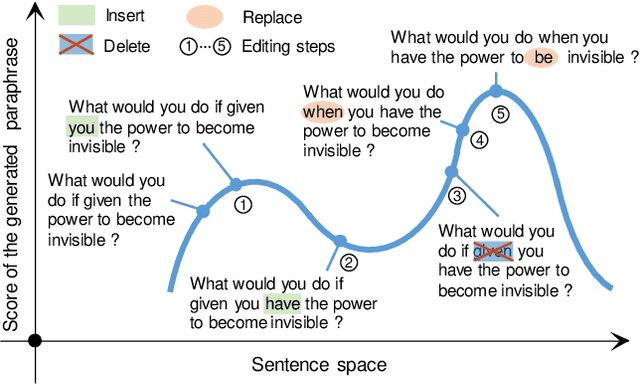
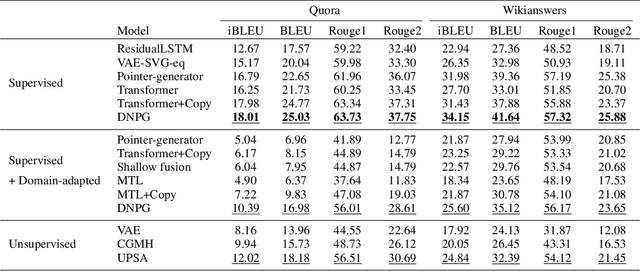

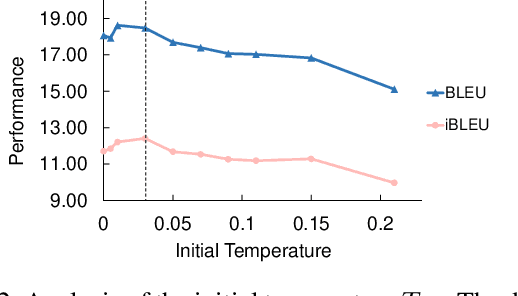
Unsupervised paraphrase generation is a promising and important research topic in natural language processing. We propose UPSA, a novel approach that accomplishes Unsupervised Paraphrasing by Simulated Annealing. We model paraphrase generation as an optimization problem and propose a sophisticated objective function, involving semantic similarity, expression diversity, and language fluency of paraphrases. Then, UPSA searches the sentence space towards this objective by performing a sequence of local editing. Our method is unsupervised and does not require parallel corpora for training, so it could be easily applied to different domains. We evaluate our approach on a variety of benchmark datasets, namely, Quora, Wikianswers, MSCOCO, and Twitter. Extensive results show that UPSA achieves the state-of-the-art performance compared with previous unsupervised methods in terms of both automatic and human evaluations. Further, our approach outperforms most existing domain-adapted supervised models, showing the generalizability of UPSA.
Generating Sentences from Disentangled Syntactic and Semantic Spaces
Jul 06, 2019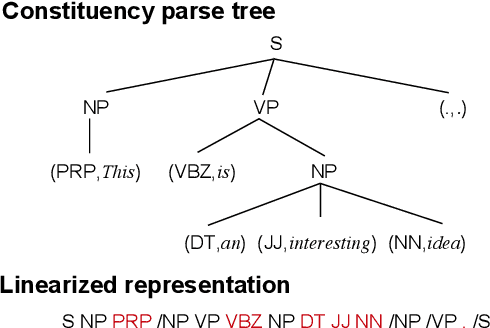
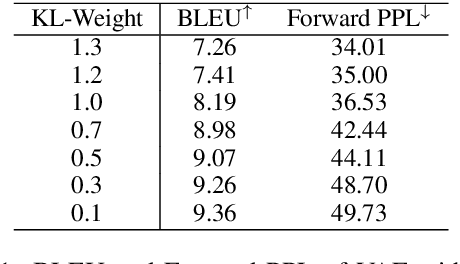
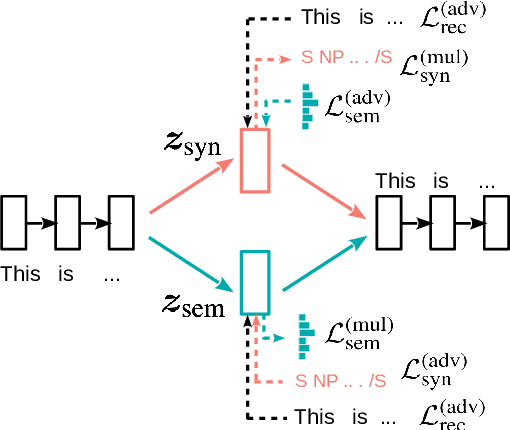
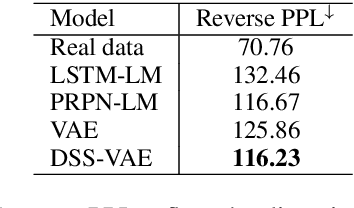
Variational auto-encoders (VAEs) are widely used in natural language generation due to the regularization of the latent space. However, generating sentences from the continuous latent space does not explicitly model the syntactic information. In this paper, we propose to generate sentences from disentangled syntactic and semantic spaces. Our proposed method explicitly models syntactic information in the VAE's latent space by using the linearized tree sequence, leading to better performance of language generation. Additionally, the advantage of sampling in the disentangled syntactic and semantic latent spaces enables us to perform novel applications, such as the unsupervised paraphrase generation and syntax-transfer generation. Experimental results show that our proposed model achieves similar or better performance in various tasks, compared with state-of-the-art related work.
An Imitation Learning Approach to Unsupervised Parsing
Jun 05, 2019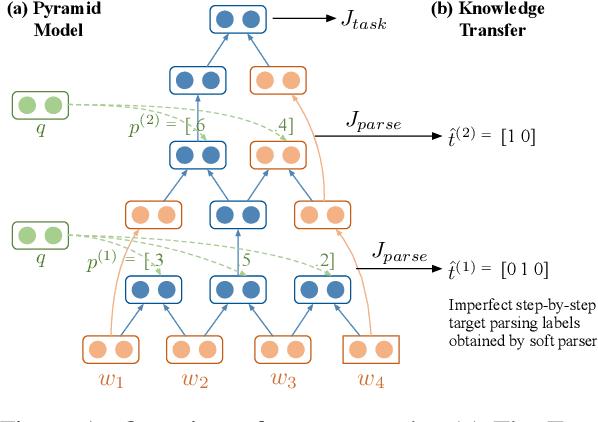
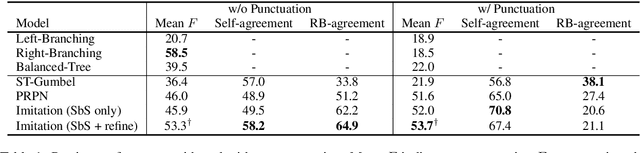
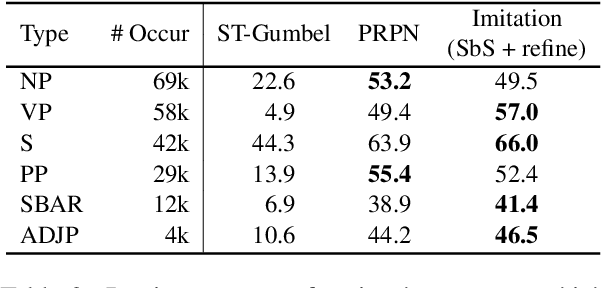
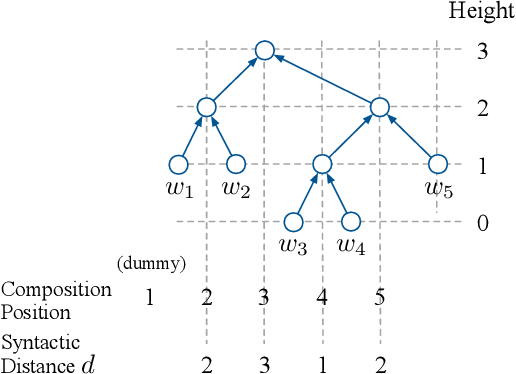
Recently, there has been an increasing interest in unsupervised parsers that optimize semantically oriented objectives, typically using reinforcement learning. Unfortunately, the learned trees often do not match actual syntax trees well. Shen et al. (2018) propose a structured attention mechanism for language modeling (PRPN), which induces better syntactic structures but relies on ad hoc heuristics. Also, their model lacks interpretability as it is not grounded in parsing actions. In our work, we propose an imitation learning approach to unsupervised parsing, where we transfer the syntactic knowledge induced by the PRPN to a Tree-LSTM model with discrete parsing actions. Its policy is then refined by Gumbel-Softmax training towards a semantically oriented objective. We evaluate our approach on the All Natural Language Inference dataset and show that it achieves a new state of the art in terms of parsing $F$-score, outperforming our base models, including the PRPN.