 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCL: Deep Change Feature Learning on Remote Sensing Images in the Metric Space
Jul 23, 2023



Change detection (CD) is an important yet challenging task in the Earth observation field for monitoring Earth surface dynamics. The advent of deep learning techniques has recently propelled automatic CD into a technological revolution. Nevertheless, deep learning-based CD methods are still plagued by two primary issues: 1) insufficient temporal relationship modeling and 2) pseudo-change misclassification. To address these issues, we complement the strong temporal modeling ability of metric learning with the prominent fitting ability of segmentation and propose a deep change feature learning (DeepCL) framework for robust and explainable CD. Firstly, we designed a hard sample-aware contrastive loss, which reweights the importance of hard and simple samples. This loss allows for explicit modeling of the temporal correlation between bi-temporal remote sensing images. Furthermore, the modeled temporal relations are utilized as knowledge prior to guide the segmentation process for detecting change regions. The DeepCL framework is thoroughly evaluated both theoretically and experimentally, demonstrating its superior feature discriminability, resilience against pseudo changes, and adaptability to a variety of CD algorithms. Extensive comparative experiments substantiate the quantitative and qualitative superiority of DeepCL over state-of-the-art CD approaches.
Expediting Building Footprint Segmentation from High-resolution Remote Sensing Images via progressive lenient supervision
Jul 23, 2023The efficacy of building footprint segmentation from remotely sensed images has been hindered by model transfer effectiveness. Many existing building segmentation methods were developed upon the encoder-decoder architecture of U-Net, in which the encoder is finetuned from the newly developed backbone networks that are pre-trained on ImageNet. However, the heavy computational burden of the existing decoder designs hampers the successful transfer of these modern encoder networks to remote sensing tasks. Even the widely-adopted deep supervision strategy fails to mitigate these challenges due to its invalid loss in hybrid regions where foreground and background pixels are intermixed. In this paper, we conduct a comprehensive evaluation of existing decoder network designs for building footprint segmentation and propose an efficient framework denoted as BFSeg to enhance learning efficiency and effectiveness. Specifically, a densely-connected coarse-to-fine feature fusion decoder network that facilitates easy and fast feature fusion across scales is proposed. Moreover, considering the invalidity of hybrid regions in the down-sampled ground truth during the deep supervision process, we present a lenient deep supervision and distillation strategy that enables the network to learn proper knowledge from deep supervision. Building upon these advancements, we have developed a new family of building segmentation networks, which consistently surpass prior works with outstanding performance and efficiency across a wide range of newly developed encoder networks. The code will be released on https://github.com/HaonanGuo/BFSeg-Efficient-Building-Footprint-Segmentation-Framework.
Revolutionizing Agrifood Systems with Artificial Intelligence: A Survey
May 03, 2023



With the world population rapidly increasing, transforming our agrifood systems to be more productive, efficient, safe, and sustainable is crucial to mitigate potential food shortages. Recently, artificial intelligence (AI) techniques such as deep learning (DL) have demonstrated their strong abilities in various areas, including language, vision, remote sensing (RS), and agrifood systems applications. However, the overall impact of AI on agrifood systems remains unclear. In this paper, we thoroughly review how AI techniques can transform agrifood systems and contribute to the modern agrifood industry. Firstly, we summarize the data acquisition methods in agrifood systems, including acquisition, storage, and processing techniques. Secondly, we present a progress review of AI methods in agrifood systems, specifically in agriculture, animal husbandry, and fishery, covering topics such as agrifood classification, growth monitoring, yield prediction, and quality assessment. Furthermore, we highlight potential challenges and promising research opportunities for transforming modern agrifood systems with AI. We hope this survey could offer an overall picture to newcomers in the field and serve as a starting point for their further research.
Scaling-up Remote Sensing Segmentation Dataset with Segment Anything Model
May 03, 2023
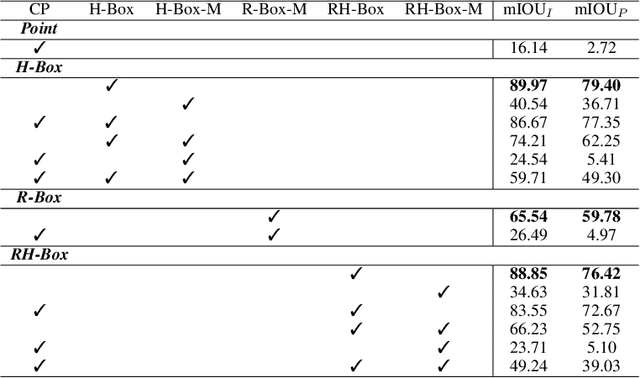


The success of the Segment Anything Model (SAM) demonstrates the significance of data-centric machine learning. However, due to the difficulties and high costs associated with annotating Remote Sensing (RS) images, a large amount of valuable RS data remains unlabeled, particularly at the pixel level. In this study, we leverage SAM and existing RS object detection datasets to develop an efficient pipeline for generating a large-scale RS segmentation dataset, dubbed SAMRS. SAMRS surpasses existing high-resolution RS segmentation datasets in size by several orders of magnitude, and provides object category, location, and instance information that can be used for semantic segmentation, instance segmentation, and object detection, either individually or in combination. We also provide a comprehensive analysis of SAMRS from various aspects. We hope it could facilitate research in RS segmentation, particularly in large model pre-training.
HKNAS: Classification of Hyperspectral Imagery Based on Hyper Kernel Neural Architecture Search
Apr 23, 2023Recent neural architecture search (NAS) based approaches have made great progress in hyperspectral image (HSI) classification tasks. However, the architectures are usually optimized independently of the network weights, increasing searching time and restricting model performances. To tackle these issues, in this paper, different from previous methods that extra define structural parameters, we propose to directly generate structural parameters by utilizing the specifically designed hyper kernels, ingeniously converting the original complex dual optimization problem into easily implemented one-tier optimizations, and greatly shrinking searching costs. Then, we develop a hierarchical multi-module search space whose candidate operations only contain convolutions, and these operations can be integrated into unified kernels. Using the above searching strategy and searching space, we obtain three kinds of networks to separately conduct pixel-level or image-level classifications with 1-D or 3-D convolutions. In addition, by combining the proposed hyper kernel searching scheme with the 3-D convolution decomposition mechanism, we obtain diverse architectures to simulate 3-D convolutions, greatly improving network flexibilities. A series of quantitative and qualitative experiments on six public datasets demonstrate that the proposed methods achieve state-of-the-art results compared with other advanced NAS-based HSI classification approaches.
DCN-T: Dual Context Network with Transformer for Hyperspectral Image Classification
Apr 19, 2023Hyperspectral image (HSI) classification is challenging due to spatial variability caused by complex imaging conditions. Prior methods suffer from limited representation ability, as they train specially designed networks from scratch on limited annotated data. We propose a tri-spectral image generation pipeline that transforms HSI into high-quality tri-spectral images, enabling the use of off-the-shelf ImageNet pretrained backbone networks for feature extraction. Motivated by the observation that there are many homogeneous areas with distinguished semantic and geometric properties in HSIs, which can be used to extract useful contexts, we propose an end-to-end segmentation network named DCN-T. It adopts transformers to effectively encode regional adaptation and global aggregation spatial contexts within and between the homogeneous areas discovered by similarity-based clustering. To fully exploit the rich spectrums of the HSI, we adopt an ensemble approach where all segmentation results of the tri-spectral images are integrated into the final prediction through a voting scheme. Extensive experiments on three public benchmarks show that our proposed method outperforms state-of-the-art methods for HSI classification.
GlobalMind: Global Multi-head Interactive Self-attention Network for Hyperspectral Change Detection
Apr 18, 2023



High spectral resolution imagery of the Earth's surface enables users to monitor changes over time in fine-grained scale, playing an increasingly important role in agriculture, defense, and emergency response. However, most current algorithms are still confined to describing local features and fail to incorporate a global perspective, which limits their ability to capture interactions between global features, thus usually resulting in incomplete change regions. In this paper, we propose a Global Multi-head INteractive self-attention change Detection network (GlobalMind) to explore the implicit correlation between different surface objects and variant land cover transformations, acquiring a comprehensive understanding of the data and accurate change detection result. Firstly, a simple but effective Global Axial Segmentation (GAS) strategy is designed to expand the self-attention computation along the row space or column space of hyperspectral images, allowing the global connection with high efficiency. Secondly, with GAS, the global spatial multi-head interactive self-attention (Global-M) module is crafted to mine the abundant spatial-spectral feature involving potential correlations between the ground objects from the entire rich and complex hyperspectral space. Moreover, to acquire the accurate and complete cross-temporal changes, we devise a global temporal interactive multi-head self-attention (GlobalD) module which incorporates the relevance and variation of bi-temporal spatial-spectral features, deriving the integrate potential same kind of changes in the local and global range with the combination of GAS. We perform extensive experiments on five mostly used hyperspectral datasets, and our method outperforms the state-of-the-art algorithms with high accuracy and efficiency.
Local-Global Temporal Difference Learning for Satellite Video Super-Resolution
Apr 10, 2023



Optical-flow-based and kernel-based approaches have been widely explored for temporal compensation in satellite video super-resolution (VSR). However, these techniques involve high computational consumption and are prone to fail under complex motions. In this paper, we proposed to exploit the well-defined temporal difference for efficient and robust temporal compensation. To fully utilize the temporal information within frames, we separately modeled the short-term and long-term temporal discrepancy since they provide distinctive complementary properties. Specifically, a short-term temporal difference module is designed to extract local motion representations from residual maps between adjacent frames, which provides more clues for accurate texture representation. Meanwhile, the global dependency in the entire frame sequence is explored via long-term difference learning. The differences between forward and backward segments are incorporated and activated to modulate the temporal feature, resulting in holistic global compensation. Besides, we further proposed a difference compensation unit to enrich the interaction between the spatial distribution of the target frame and compensated results, which helps maintain spatial consistency while refining the features to avoid misalignment. Extensive objective and subjective evaluation of five mainstream satellite videos demonstrates that the proposed method performs favorably for satellite VSR. Code will be available at \url{https://github.com/XY-boy/TDMVSR}
One-Step Detection Paradigm for Hyperspectral Anomaly Detection via Spectral Deviation Relationship Learning
Mar 22, 2023



Hyperspectral anomaly detection (HAD) involves identifying the targets that deviate spectrally from their surroundings, without prior knowledge. Recently, deep learning based methods have become the mainstream HAD methods, due to their powerful spatial-spectral feature extraction ability. However, the current deep detection models are optimized to complete a proxy task (two-step paradigm), such as background reconstruction or generation, rather than achieving anomaly detection directly. This leads to suboptimal results and poor transferability, which means that the deep model is trained and tested on the same image. In this paper, an unsupervised transferred direct detection (TDD) model is proposed, which is optimized directly for the anomaly detection task (one-step paradigm) and has transferability. Specially, the TDD model is optimized to identify the spectral deviation relationship according to the anomaly definition. Compared to learning the specific background distribution as most models do, the spectral deviation relationship is universal for different images and guarantees the model transferability. To train the TDD model in an unsupervised manner, an anomaly sample simulation strategy is proposed to generate numerous pairs of anomaly samples. Furthermore, a global self-attention module and a local self-attention module are designed to help the model focus on the "spectrally deviating" relationship. The TDD model was validated on four public HAD datasets. The results show that the proposed TDD model can successfully overcome the limitation of traditional model training and testing on a single image, and the model has a powerful detection ability and excellent transferability.
DDS2M: Self-Supervised Denoising Diffusion Spatio-Spectral Model for Hyperspectral Image Restoration
Mar 19, 2023Diffusion models have recently received a surge of interest due to their impressive performance for image restoration, especially in terms of noise robustness. However, existing diffusion-based methods are trained on a large amount of training data and perform very well in-distribution, but can be quite susceptible to distribution shift. This is especially inappropriate for data-starved hyperspectral image (HSI) restoration. To tackle this problem, this work puts forth a self-supervised diffusion model for HSI restoration, namely Denoising Diffusion Spatio-Spectral Model (\texttt{DDS2M}), which works by inferring the parameters of the proposed Variational Spatio-Spectral Module (VS2M) during the reverse diffusion process, solely using the degraded HSI without any extra training data. In VS2M, a variational inference-based loss function is customized to enable the untrained spatial and spectral networks to learn the posterior distribution, which serves as the transitions of the sampling chain to help reverse the diffusion process. Benefiting from its self-supervised nature and the diffusion process, \texttt{DDS2M} enjoys stronger generalization ability to various HSIs compared to existing diffusion-based methods and superior robustness to noise compared to existing HSI restoration methods. Extensive experiments on HSI denoising, noisy HSI completion and super-resolution on a variety of HSIs demonstrate \texttt{DDS2M}'s superiority over the existing task-specific state-of-the-arts.