 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Noisy Labels with Distillation
Apr 07, 2017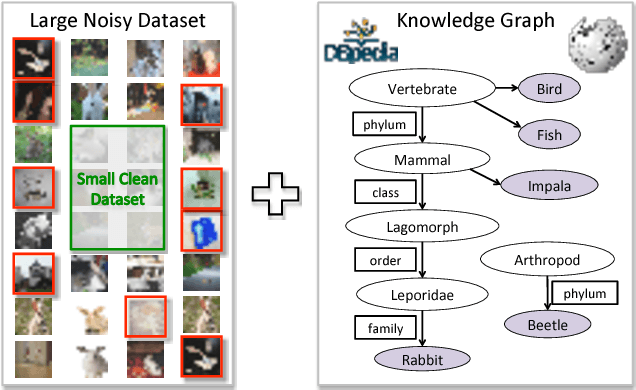

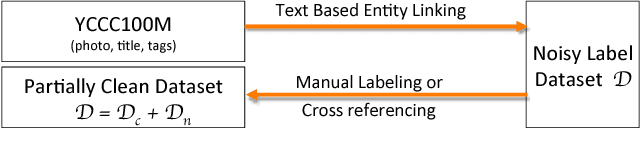
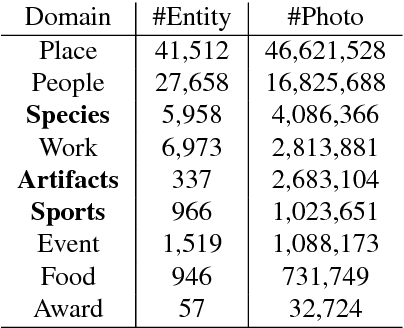
The ability of learning from noisy labels is very useful in many visual recognition tasks, as a vast amount of data with noisy labels are relatively easy to obtain. Traditionally, the label noises have been treated as statistical outliers, and approaches such as importance re-weighting and bootstrap have been proposed to alleviate the problem. According to our observation, the real-world noisy labels exhibit multi-mode characteristics as the true labels, rather than behaving like independent random outliers. In this work, we propose a unified distillation framework to use side information, including a small clean dataset and label relations in knowledge graph, to "hedge the risk" of learning from noisy labels. Furthermore, unlike the traditional approaches evaluated based on simulated label noises, we propose a suite of new benchmark datasets, in Sports, Species and Artifacts domains, to evaluate the task of learning from noisy labels in the practical setting. The empirical study demonstrates the effectiveness of our proposed method in all the domains.
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations
Feb 23, 2016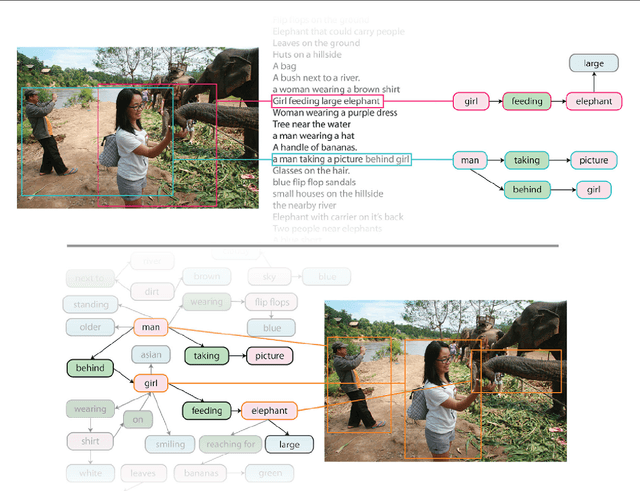
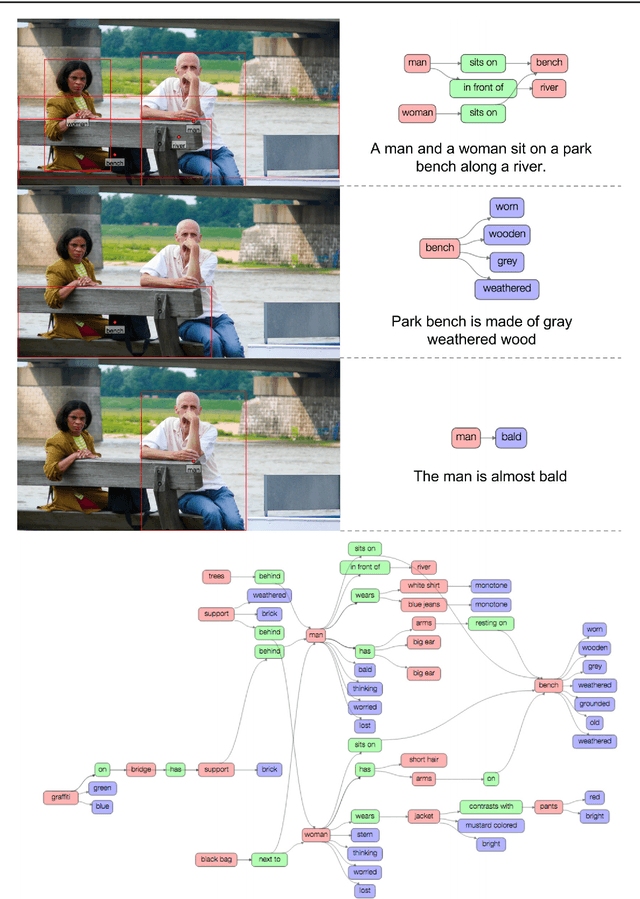

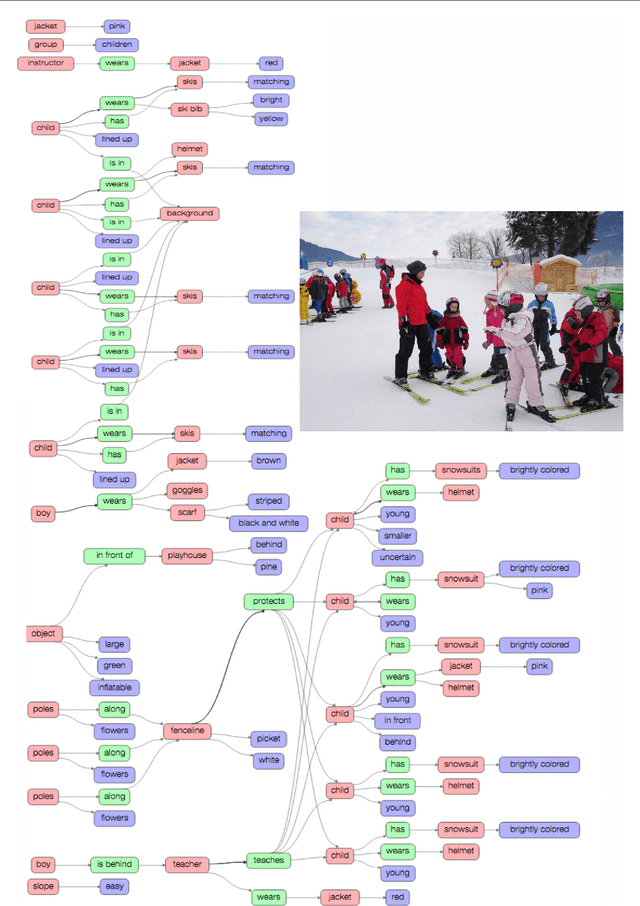
Despite progress in perceptual tasks such as image classification, computers still perform poorly on cognitive tasks such as image description and question answering. Cognition is core to tasks that involve not just recognizing, but reasoning about our visual world. However, models used to tackle the rich content in images for cognitive tasks are still being trained using the same datasets designed for perceptual tasks. To achieve success at cognitive tasks, models need to understand the interactions and relationships between objects in an image. When asked "What vehicle is the person riding?", computers will need to identify the objects in an image as well as the relationships riding(man, carriage) and pulling(horse, carriage) in order to answer correctly that "the person is riding a horse-drawn carriage". In this paper, we present the Visual Genome dataset to enable the modeling of such relationships. We collect dense annotations of objects, attributes, and relationships within each image to learn these models. Specifically, our dataset contains over 100K images where each image has an average of 21 objects, 18 attributes, and 18 pairwise relationships between objects. We canonicalize the objects, attributes, relationships, and noun phrases in region descriptions and questions answer pairs to WordNet synsets. Together, these annotations represent the densest and largest dataset of image descriptions, objects, attributes, relationships, and question answers.
Multi-view Face Detection Using Deep Convolutional Neural Networks
Apr 20, 2015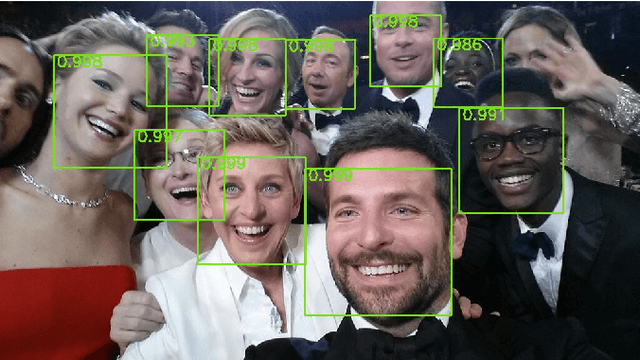
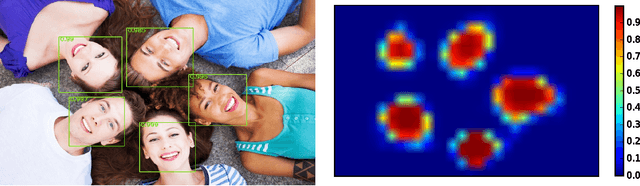

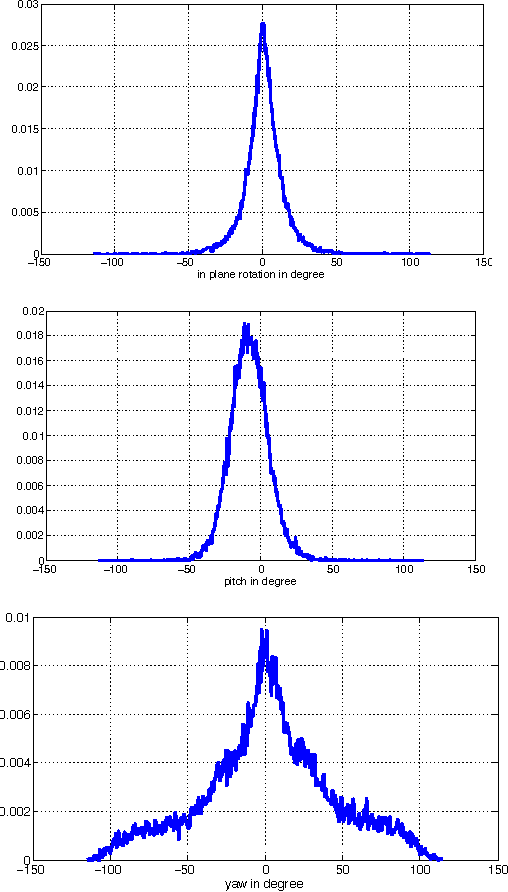
In this paper we consider the problem of multi-view face detection. While there has been significant research on this problem, current state-of-the-art approaches for this task require annotation of facial landmarks, e.g. TSM [25], or annotation of face poses [28, 22]. They also require training dozens of models to fully capture faces in all orientations, e.g. 22 models in HeadHunter method [22]. In this paper we propose Deep Dense Face Detector (DDFD), a method that does not require pose/landmark annotation and is able to detect faces in a wide range of orientations using a single model based on deep convolutional neural networks. The proposed method has minimal complexity; unlike other recent deep learning object detection methods [9], it does not require additional components such as segmentation, bounding-box regression, or SVM classifiers. Furthermore, we analyzed scores of the proposed face detector for faces in different orientations and found that 1) the proposed method is able to detect faces from different angles and can handle occlusion to some extent, 2) there seems to be a correlation between dis- tribution of positive examples in the training set and scores of the proposed face detector. The latter suggests that the proposed methods performance can be further improved by using better sampling strategies and more sophisticated data augmentation techniques. Evaluations on popular face detection benchmark datasets show that our single-model face detector algorithm has similar or better performance compared to the previous methods, which are more complex and require annotations of either different poses or facial landmarks.
Visual Sentiment Prediction with Deep Convolutional Neural Networks
Nov 21, 2014
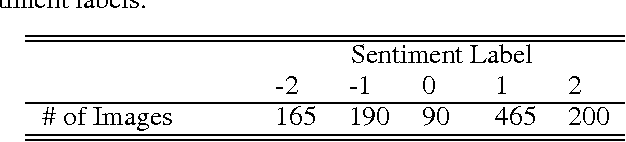
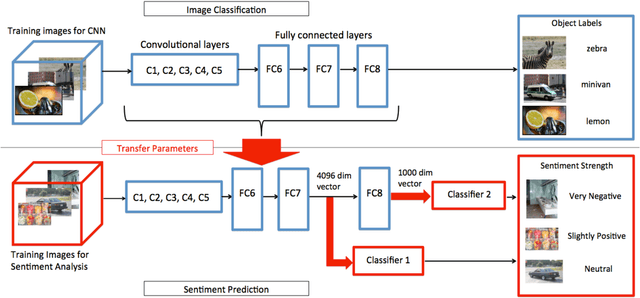

Images have become one of the most popular types of media through which users convey their emotions within online social networks. Although vast amount of research is devoted to sentiment analysis of textual data, there has been very limited work that focuses on analyzing sentiment of image data. In this work, we propose a novel visual sentiment prediction framework that performs image understanding with Deep Convolutional Neural Networks (CNN). Specifically, the proposed sentiment prediction framework performs transfer learning from a CNN with millions of parameters, which is pre-trained on large-scale data for object recognition. Experiments conducted on two real-world datasets from Twitter and Tumblr demonstrate the effectiveness of the proposed visual sentiment analysis framework.
Large-Scale Multi-Label Learning with Incomplete Label Assignments
Jul 06, 2014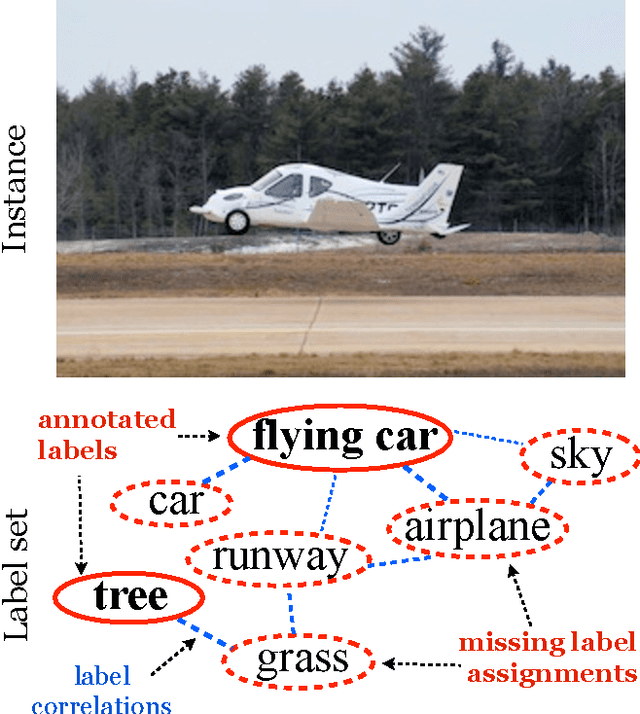

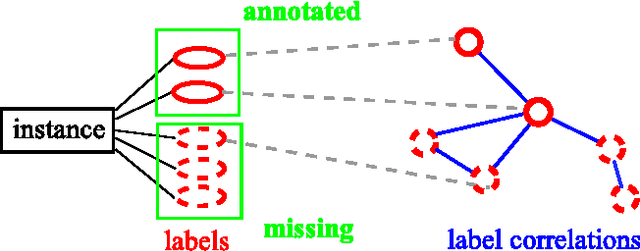

Multi-label learning deals with the classification problems where each instance can be assigned with multiple labels simultaneously. Conventional multi-label learning approaches mainly focus on exploiting label correlations. It is usually assumed, explicitly or implicitly, that the label sets for training instances are fully labeled without any missing labels. However, in many real-world multi-label datasets, the label assignments for training instances can be incomplete. Some ground-truth labels can be missed by the labeler from the label set. This problem is especially typical when the number instances is very large, and the labeling cost is very high, which makes it almost impossible to get a fully labeled training set. In this paper, we study the problem of large-scale multi-label learning with incomplete label assignments. We propose an approach, called MPU, based upon positive and unlabeled stochastic gradient descent and stacked models. Unlike prior works, our method can effectively and efficiently consider missing labels and label correlations simultaneously, and is very scalable, that has linear time complexities over the size of the data. Extensive experiments on two real-world multi-label datasets show that our MPU model consistently outperform other commonly-used baselines.