 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation, learning, and planning algorithms for geometric task and motion planning
Mar 09, 2022
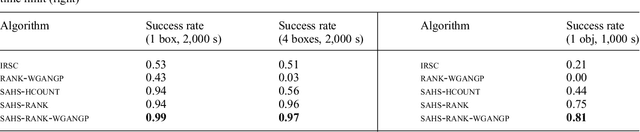


We present a framework for learning to guide geometric task and motion planning (GTAMP). GTAMP is a subclass of task and motion planning in which the goal is to move multiple objects to target regions among movable obstacles. A standard graph search algorithm is not directly applicable, because GTAMP problems involve hybrid search spaces and expensive action feasibility checks. To handle this, we introduce a novel planner that extends basic heuristic search with random sampling and a heuristic function that prioritizes feasibility checking on promising state action pairs. The main drawback of such pure planners is that they lack the ability to learn from planning experience to improve their efficiency. We propose two learning algorithms to address this. The first is an algorithm for learning a rank function that guides the discrete task level search, and the second is an algorithm for learning a sampler that guides the continuous motionlevel search. We propose design principles for designing data efficient algorithms for learning from planning experience and representations for effective generalization. We evaluate our framework in challenging GTAMP problems, and show that we can improve both planning and data efficiency
Specifying and achieving goals in open uncertain robot-manipulation domains
Dec 21, 2021
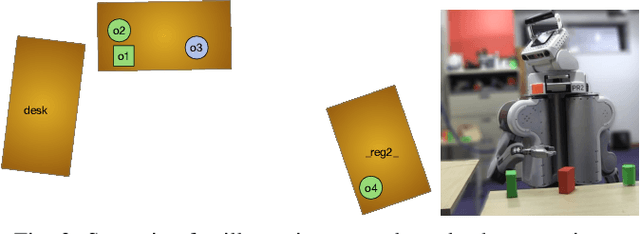
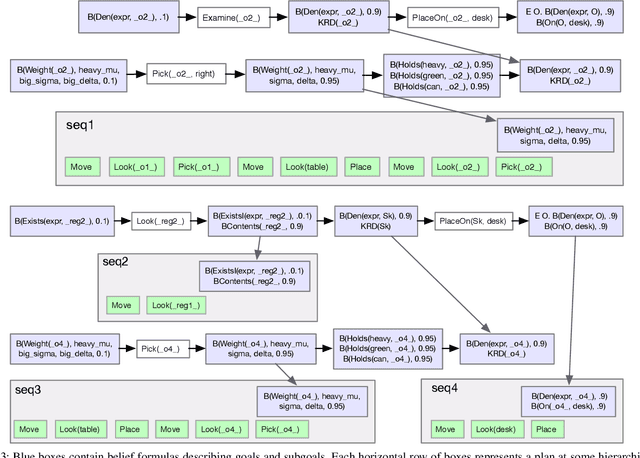

This paper describes an integrated solution to the problem of describing and interpreting goals for robots in open uncertain domains. Given a formal specification of a desired situation, in which objects are described only by their properties, general-purpose planning and reasoning tools are used to derive appropriate actions for a robot. These goals are carried out through an online combination of hierarchical planning, state-estimation, and execution that operates robustly in real robot domains with substantial occlusion and sensing error.
Reinforcement Learning for Classical Planning: Viewing Heuristics as Dense Reward Generators
Sep 30, 2021

Recent advances in reinforcement learning (RL) have led to a growing interest in applying RL to classical planning domains or applying classical planning methods to some complex RL domains. However, the long-horizon goal-based problems found in classical planning lead to sparse rewards for RL, making direct application inefficient. In this paper, we propose to leverage domain-independent heuristic functions commonly used in the classical planning literature to improve the sample efficiency of RL. These classical heuristics act as dense reward generators to alleviate the sparse-rewards issue and enable our RL agent to learn domain-specific value functions as residuals on these heuristics, making learning easier. Correct application of this technique requires consolidating the discounted metric used in RL and the non-discounted metric used in heuristics. We implement the value functions using Neural Logic Machines, a neural network architecture designed for grounded first-order logic inputs. We demonstrate on several classical planning domains that using classical heuristics for RL allows for good sample efficiency compared to sparse-reward RL. We further show that our learned value functions generalize to novel problem instances in the same domain.
Discovering State and Action Abstractions for Generalized Task and Motion Planning
Sep 23, 2021
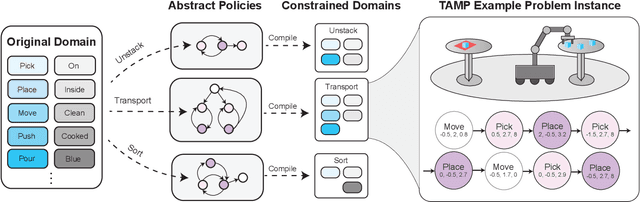
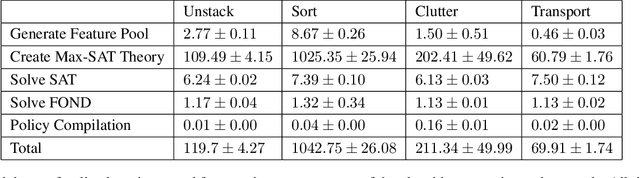
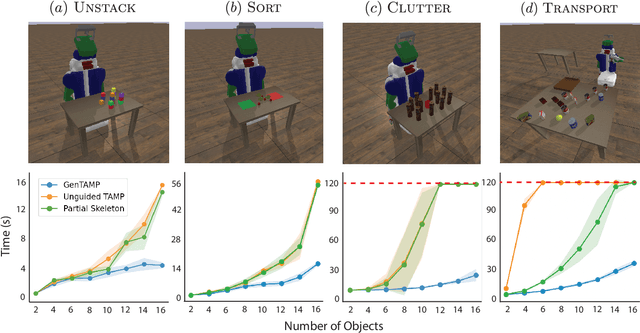
Generalized planning accelerates classical planning by finding an algorithm-like policy that solves multiple instances of a task. A generalized plan can be learned from a few training examples and applied to an entire domain of problems. Generalized planning approaches perform well in discrete AI planning problems that involve large numbers of objects and extended action sequences to achieve the goal. In this paper, we propose an algorithm for learning features, abstractions, and generalized plans for continuous robotic task and motion planning (TAMP) and examine the unique difficulties that arise when forced to consider geometric and physical constraints as a part of the generalized plan. Additionally, we show that these simple generalized plans learned from only a handful of examples can be used to improve the search efficiency of TAMP solvers.
Long-Horizon Manipulation of Unknown Objects via Task and Motion Planning with Estimated Affordances
Aug 10, 2021
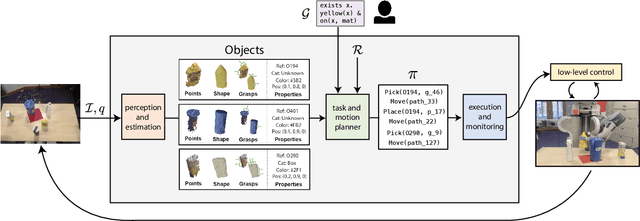


We present a strategy for designing and building very general robot manipulation systems involving the integration of a general-purpose task-and-motion planner with engineered and learned perception modules that estimate properties and affordances of unknown objects. Such systems are closed-loop policies that map from RGB images, depth images, and robot joint encoder measurements to robot joint position commands. We show that following this strategy a task-and-motion planner can be used to plan intelligent behaviors even in the absence of a priori knowledge regarding the set of manipulable objects, their geometries, and their affordances. We explore several different ways of implementing such perceptual modules for segmentation, property detection, shape estimation, and grasp generation. We show how these modules are integrated within the PDDLStream task and motion planning framework. Finally, we demonstrate that this strategy can enable a single system to perform a wide variety of real-world multi-step manipulation tasks, generalizing over a broad class of objects, object arrangements, and goals, without any prior knowledge of the environment and without re-training.
Temporal and Object Quantification Networks
Jun 10, 2021
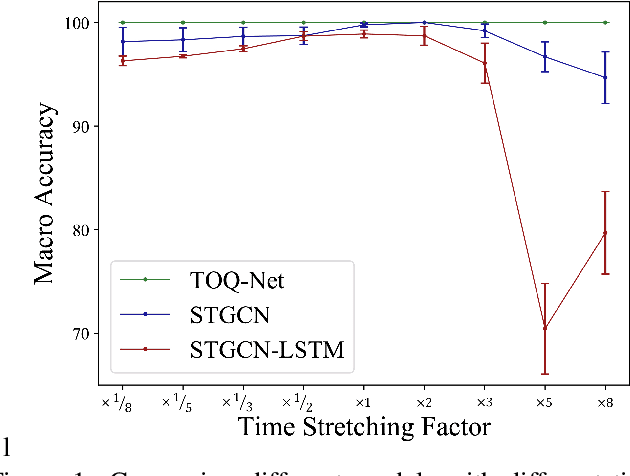
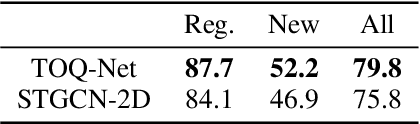
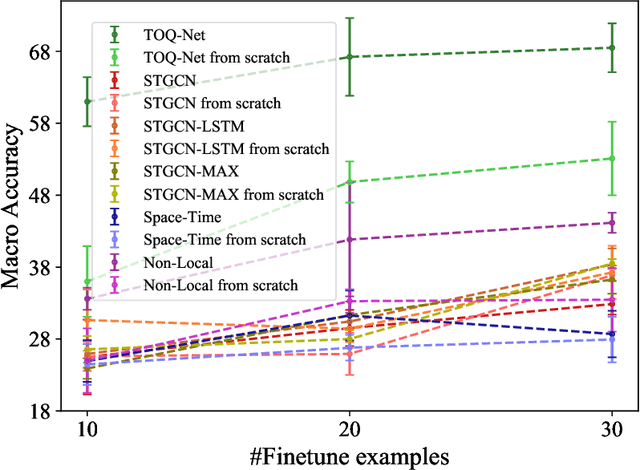
We present Temporal and Object Quantification Networks (TOQ-Nets), a new class of neuro-symbolic networks with a structural bias that enables them to learn to recognize complex relational-temporal events. This is done by including reasoning layers that implement finite-domain quantification over objects and time. The structure allows them to generalize directly to input instances with varying numbers of objects in temporal sequences of varying lengths. We evaluate TOQ-Nets on input domains that require recognizing event-types in terms of complex temporal relational patterns. We demonstrate that TOQ-Nets can generalize from small amounts of data to scenarios containing more objects than were present during training and to temporal warpings of input sequences.
Learning Neuro-Symbolic Relational Transition Models for Bilevel Planning
May 28, 2021

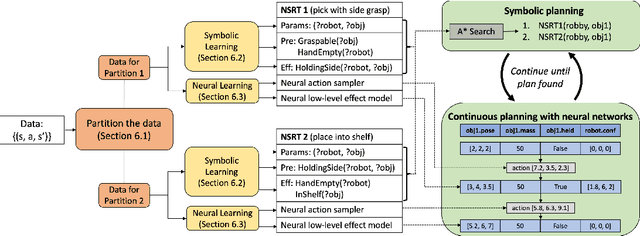

Despite recent, independent progress in model-based reinforcement learning and integrated symbolic-geometric robotic planning, synthesizing these techniques remains challenging because of their disparate assumptions and strengths. In this work, we take a step toward bridging this gap with Neuro-Symbolic Relational Transition Models (NSRTs), a novel class of transition models that are data-efficient to learn, compatible with powerful robotic planning methods, and generalizable over objects. NSRTs have both symbolic and neural components, enabling a bilevel planning scheme where symbolic AI planning in an outer loop guides continuous planning with neural models in an inner loop. Experiments in four robotic planning domains show that NSRTs can be learned after only tens or hundreds of training episodes, and then used for fast planning in new tasks that require up to 60 actions to reach the goal and involve many more objects than were seen during training. Video: https://tinyurl.com/chitnis-nsrts
Learning When to Quit: Meta-Reasoning for Motion Planning
Mar 07, 2021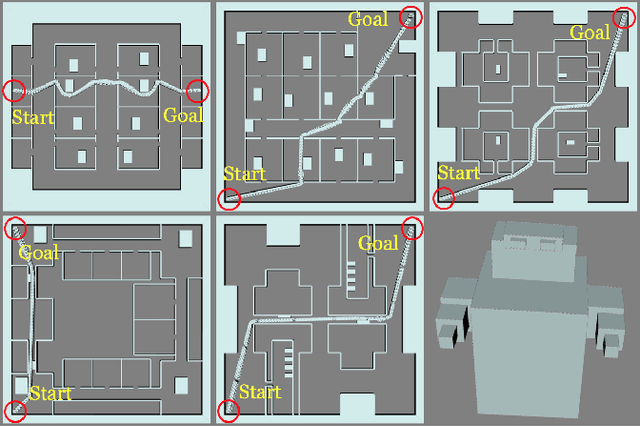
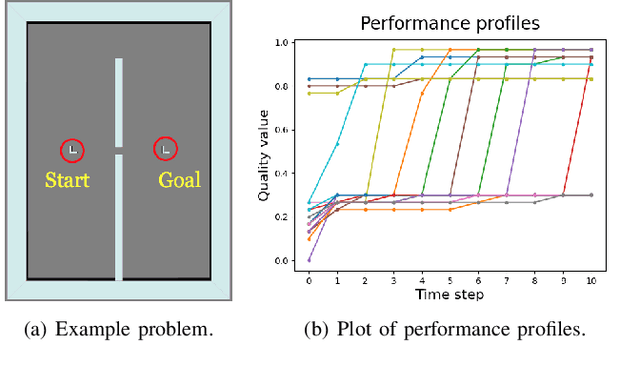
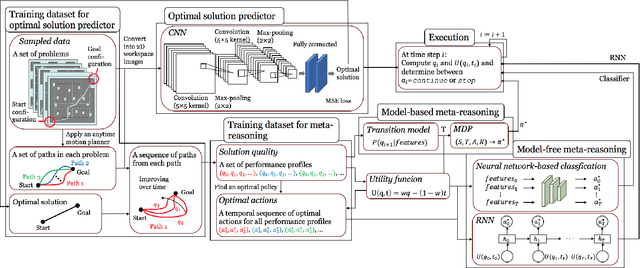
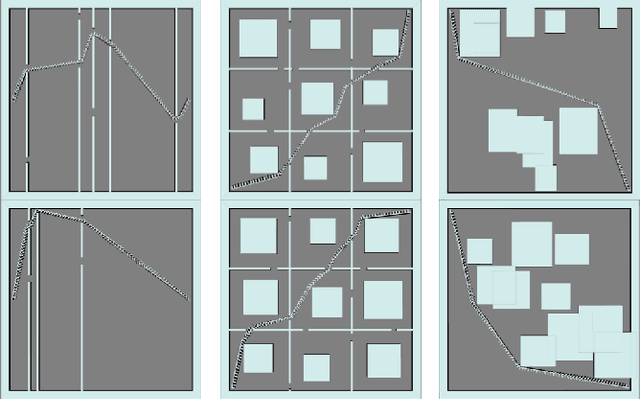
Anytime motion planners are widely used in robotics. However, the relationship between their solution quality and computation time is not well understood, and thus, determining when to quit planning and start execution is unclear. In this paper, we address the problem of deciding when to stop deliberation under bounded computational capacity, so called meta-reasoning, for anytime motion planning. We propose data-driven learning methods, model-based and model-free meta-reasoning, that are applicable to different environment distributions and agnostic to the choice of anytime motion planners. As a part of the framework, we design a convolutional neural network-based optimal solution predictor that predicts the optimal path length from a given 2D workspace image. We empirically evaluate the performance of the proposed methods in simulation in comparison with baselines.
Learning Symbolic Operators for Task and Motion Planning
Feb 28, 2021



Robotic planning problems in hybrid state and action spaces can be solved by integrated task and motion planners (TAMP) that handle the complex interaction between motion-level decisions and task-level plan feasibility. TAMP approaches rely on domain-specific symbolic operators to guide the task-level search, making planning efficient. In this work, we formalize and study the problem of operator learning for TAMP. Central to this study is the view that operators define a lossy abstraction of the transition model of the underlying domain. We then propose a bottom-up relational learning method for operator learning and show how the learned operators can be used for planning in a TAMP system. Experimentally, we provide results in three domains, including long-horizon robotic planning tasks. We find our approach to substantially outperform several baselines, including three graph neural network-based model-free approaches based on recent work. Video: https://youtu.be/iVfpX9BpBRo
Tailoring: encoding inductive biases by optimizing unsupervised objectives at prediction time
Oct 14, 2020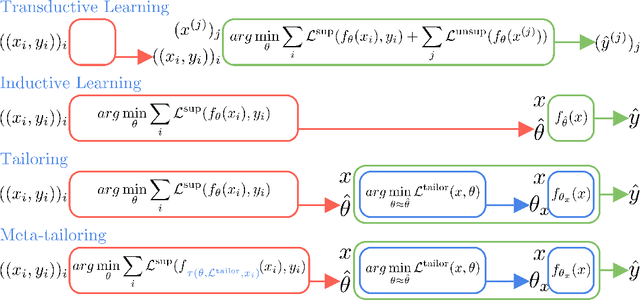
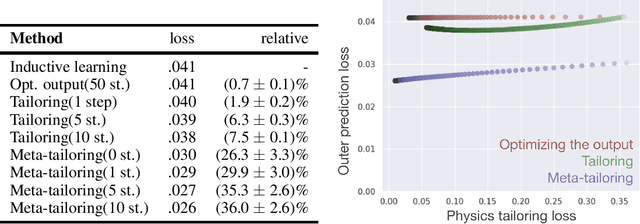
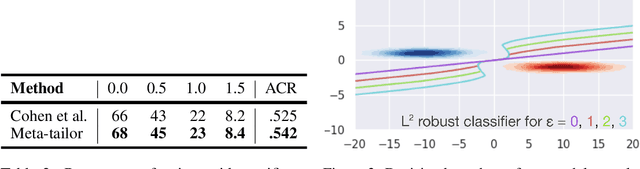
From CNNs to attention mechanisms, encoding inductive biases into neural networks has been a fruitful source of improvement in machine learning. Auxiliary losses are a general way of encoding biases in order to help networks learn better representations by adding extra terms to the loss function. However, since they are minimized on the training data, they suffer from the same generalization gap as regular task losses. Moreover, by changing the loss function, the network is optimizing a different objective than the one we care about. In this work we solve both problems: first, we take inspiration from \textit{transductive learning} and note that, after receiving an input but before making a prediction, we can fine-tune our models on any unsupervised objective. We call this process tailoring, because we customize the model to each input. Second, we formulate a nested optimization (similar to those in meta-learning) and train our models to perform well on the task loss after adapting to the tailoring loss. The advantages of tailoring and meta-tailoring are discussed theoretically and demonstrated empirically on several diverse examples: encoding inductive conservation laws from physics to improve predictions, improving local smoothness to increase robustness to adversarial examples, and using contrastive losses on the query image to improve generalization.