 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Learning-Based Feedback Linearization Tracking Control for Nonlinear System with Event-Triggered Model Update
Mar 07, 2022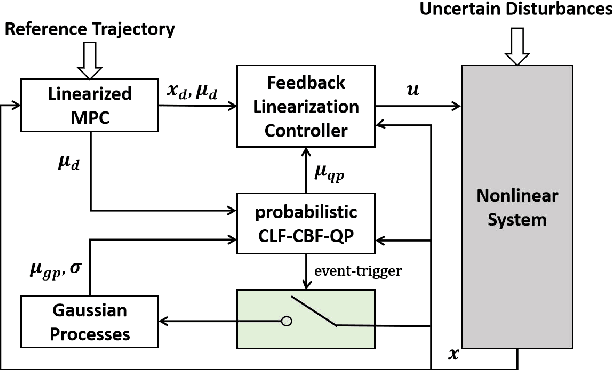
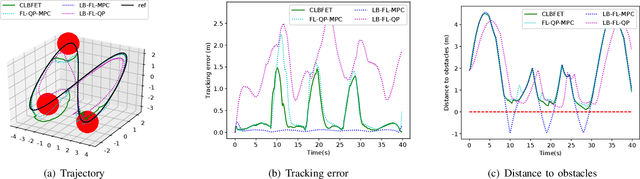
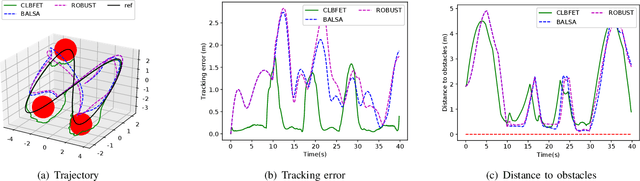
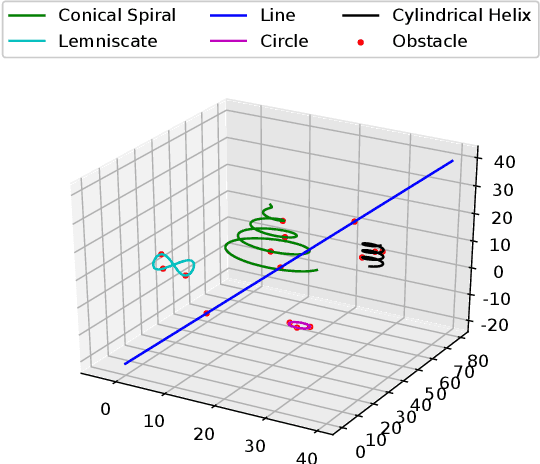
Learning-based methods are powerful in handling complex scenarios. However, it is still challenging to use learning-based methods under uncertain environments while stability, safety, and real-time performance of the system are desired to guarantee. In this paper, we propose a learning-based tracking control scheme based on a feedback linearization controller in which uncertain disturbances are approximated online using Gaussian Processes (GPs). Using the predicted distribution of disturbances given by GPs, a Control Lyapunov Function (CLF) and Control Barrier Function (CBF) based Quadratic Program is applied, with which probabilistic stability and safety are guaranteed. In addition, the trajectory is optimized first by Model Predictive Control (MPC) based on the linearized dynamics systems to further reduce the tracking error. We also design an event trigger for GPs updates to improve efficiency while stability and safety of the system are still guaranteed. The effectiveness of the proposed tracking control strategy is illustrated in numerical simulations.
* 8 pages, 8 figures
Sequential Recommendation via Stochastic Self-Attention
Jan 16, 2022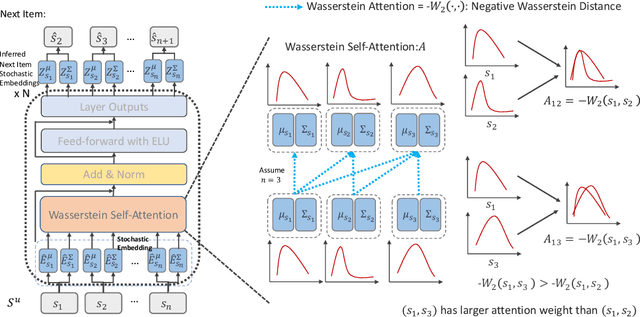
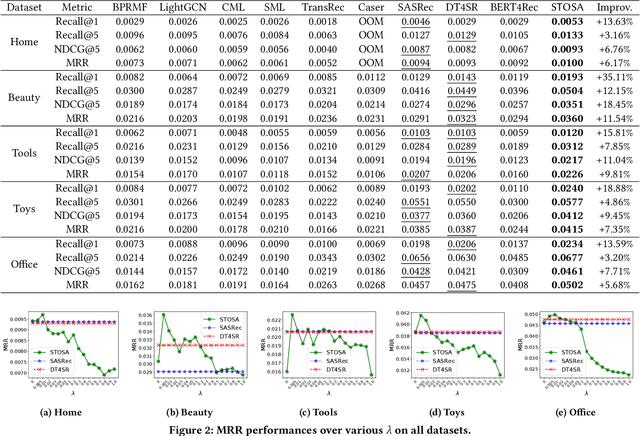

Sequential recommendation models the dynamics of a user's previous behaviors in order to forecast the next item, and has drawn a lot of attention. Transformer-based approaches, which embed items as vectors and use dot-product self-attention to measure the relationship between items, demonstrate superior capabilities among existing sequential methods. However, users' real-world sequential behaviors are \textit{\textbf{uncertain}} rather than deterministic, posing a significant challenge to present techniques. We further suggest that dot-product-based approaches cannot fully capture \textit{\textbf{collaborative transitivity}}, which can be derived in item-item transitions inside sequences and is beneficial for cold start items. We further argue that BPR loss has no constraint on positive and sampled negative items, which misleads the optimization. We propose a novel \textbf{STO}chastic \textbf{S}elf-\textbf{A}ttention~(STOSA) to overcome these issues. STOSA, in particular, embeds each item as a stochastic Gaussian distribution, the covariance of which encodes the uncertainty. We devise a novel Wasserstein Self-Attention module to characterize item-item position-wise relationships in sequences, which effectively incorporates uncertainty into model training. Wasserstein attentions also enlighten the collaborative transitivity learning as it satisfies triangle inequality. Moreover, we introduce a novel regularization term to the ranking loss, which assures the dissimilarity between positive and the negative items. Extensive experiments on five real-world benchmark datasets demonstrate the superiority of the proposed model over state-of-the-art baselines, especially on cold start items. The code is available in \url{https://github.com/zfan20/STOSA}.
Continuous-Time Sequential Recommendation with Temporal Graph Collaborative Transformer
Aug 22, 2021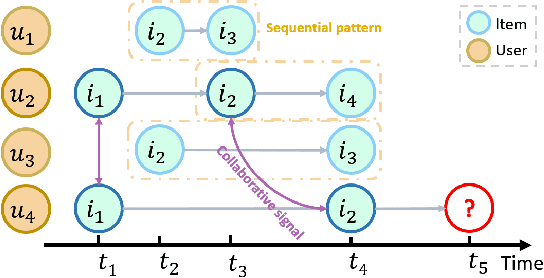
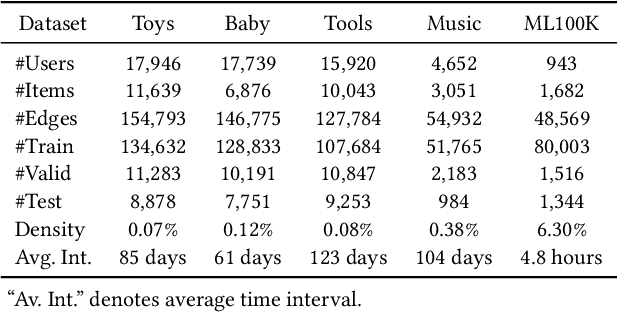
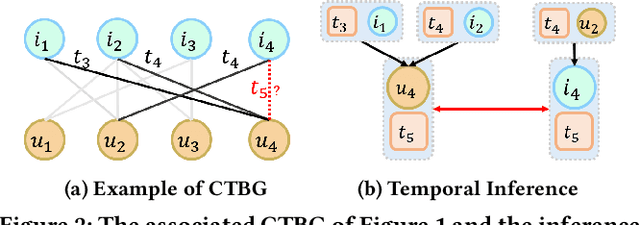
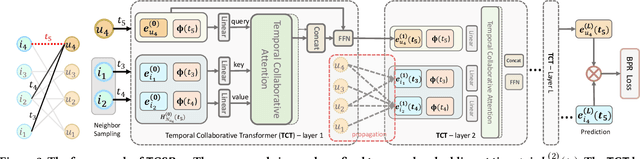
In order to model the evolution of user preference, we should learn user/item embeddings based on time-ordered item purchasing sequences, which is defined as Sequential Recommendation (SR) problem. Existing methods leverage sequential patterns to model item transitions. However, most of them ignore crucial temporal collaborative signals, which are latent in evolving user-item interactions and coexist with sequential patterns. Therefore, we propose to unify sequential patterns and temporal collaborative signals to improve the quality of recommendation, which is rather challenging. Firstly, it is hard to simultaneously encode sequential patterns and collaborative signals. Secondly, it is non-trivial to express the temporal effects of collaborative signals. Hence, we design a new framework Temporal Graph Sequential Recommender (TGSRec) upon our defined continuous-time bi-partite graph. We propose a novel Temporal Collaborative Trans-former (TCT) layer in TGSRec, which advances the self-attention mechanism by adopting a novel collaborative attention. TCT layer can simultaneously capture collaborative signals from both users and items, as well as considering temporal dynamics inside sequential patterns. We propagate the information learned fromTCTlayerover the temporal graph to unify sequential patterns and temporal collaborative signals. Empirical results on five datasets show that TGSRec significantly outperforms other baselines, in average up to 22.5% and 22.1%absolute improvements in Recall@10and MRR, respectively.
Modeling Sequences as Distributions with Uncertainty for Sequential Recommendation
Jun 11, 2021
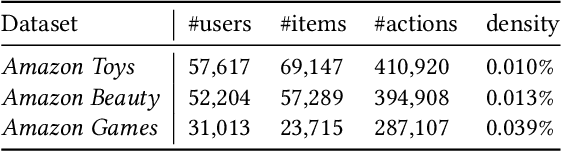
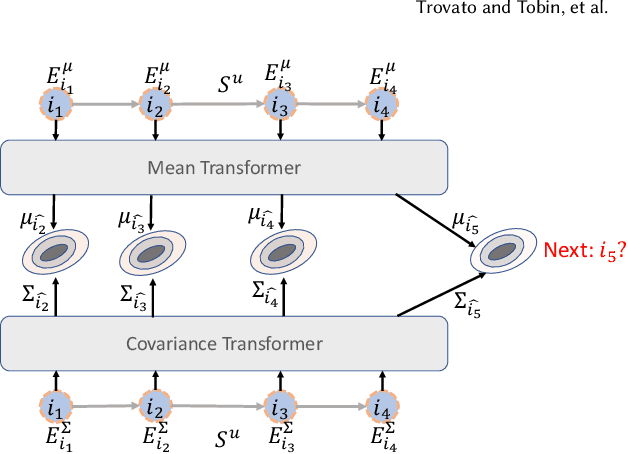
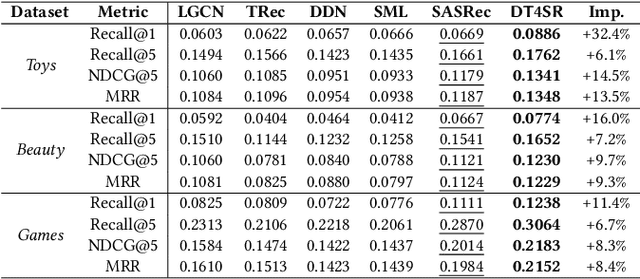
The sequential patterns within the user interactions are pivotal for representing the user's preference and capturing latent relationships among items. The recent advancements of sequence modeling by Transformers advocate the community to devise more effective encoders for the sequential recommendation. Most existing sequential methods assume users are deterministic. However, item-item transitions might fluctuate significantly in several item aspects and exhibit randomness of user interests. This \textit{stochastic characteristics} brings up a solid demand to include uncertainties in representing sequences and items. Additionally, modeling sequences and items with uncertainties expands users' and items' interaction spaces, thus further alleviating cold-start problems. In this work, we propose a Distribution-based Transformer for Sequential Recommendation (DT4SR), which injects uncertainties into sequential modeling. We use Elliptical Gaussian distributions to describe items and sequences with uncertainty. We describe the uncertainty in items and sequences as Elliptical Gaussian distribution. And we adopt Wasserstein distance to measure the similarity between distributions. We devise two novel Trans-formers for modeling mean and covariance, which guarantees the positive-definite property of distributions. The proposed method significantly outperforms the state-of-the-art methods. The experiments on three benchmark datasets also demonstrate its effectiveness in alleviating cold-start issues. The code is available inhttps://github.com/DyGRec/DT4SR.
Safe Learning-based Gradient-free Model Predictive Control Based on Cross-entropy Method
Feb 28, 2021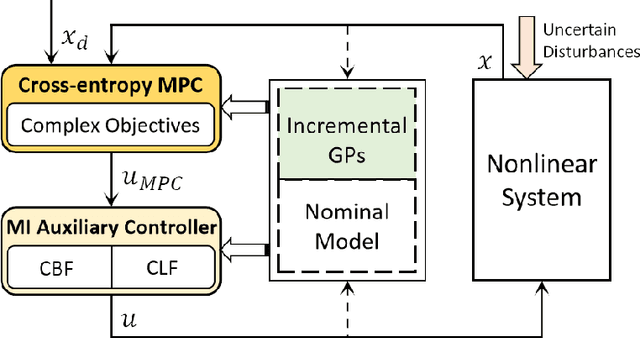
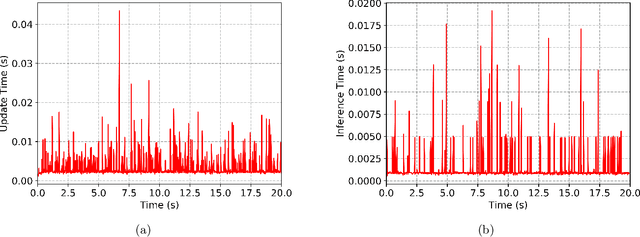

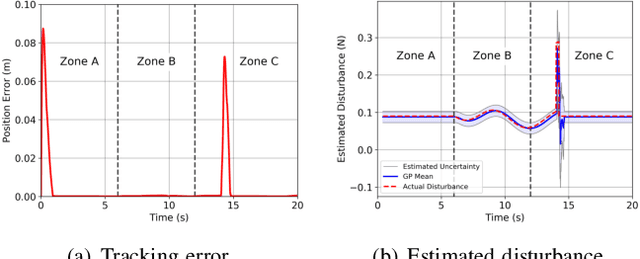
In this paper, a safe and learning-based control framework for model predictive control (MPC) is proposed to optimize nonlinear systems with a gradient-free objective function under uncertain environmental disturbances. The control framework integrates a learning-based MPC with an auxiliary controller in a way of minimal intervention. The learning-based MPC augments the prior nominal model with incremental Gaussian Processes to learn the uncertain disturbances. The cross-entropy method (CEM) is utilized as the sampling-based optimizer for the MPC with a gradient-free objective function. A minimal intervention controller is devised with a control Lyapunov function and a control barrier function to guide the sampling process and endow the system with high probabilistic safety. The proposed algorithm shows a safe and adaptive control performance on a simulated quadrotor in the tasks of trajectory tracking and obstacle avoidance under uncertain wind disturbances.
Learning-Based Safety-Stability-Driven Control for Safety-Critical Systems under Model Uncertainties
Sep 15, 2020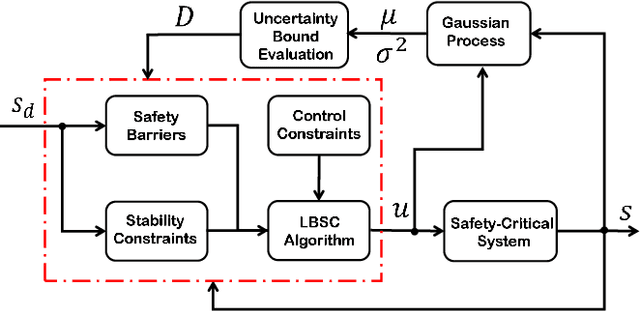
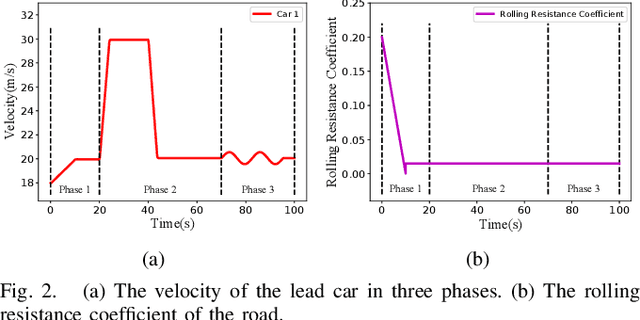
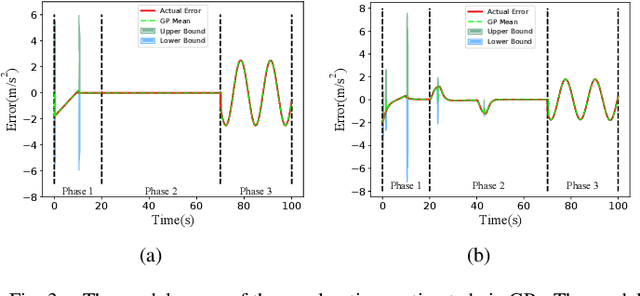
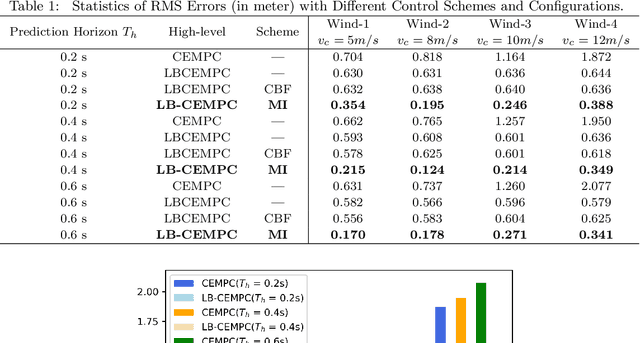
Safety and tracking stability are crucial for safety-critical systems such as self-driving cars, autonomous mobile robots, industrial manipulators. To efficiently control safety-critical systems to ensure their safety and achieve tracking stability, accurate system dynamic models are usually required. However, accurate system models are not always available in practice. In this paper, a learning-based safety-stability-driven control (LBSC) algorithm is presented to guarantee the safety and tracking stability for nonlinear safety-critical systems subject to control input constraints under model uncertainties. Gaussian Processes (GPs) are employed to learn the model error between the nominal model and the actual system dynamics, and the estimated mean and variance of the model error are used to quantify a high-confidence uncertainty bound. Using this estimated uncertainty bound, a safety barrier constraint is devised to ensure safety, and a stability constraint is developed to achieve rapid and accurate tracking. Then the proposed LBSC method is formulated as a quadratic program incorporating the safety barrier, the stability constraint, and the control constraints. The effectiveness of the LBSC method is illustrated on the safety-critical connected cruise control (CCC) system simulator under model uncertainties.
Safe Online Learning Tracking Control for Quadrotors under Wind Disturbances
Sep 08, 2020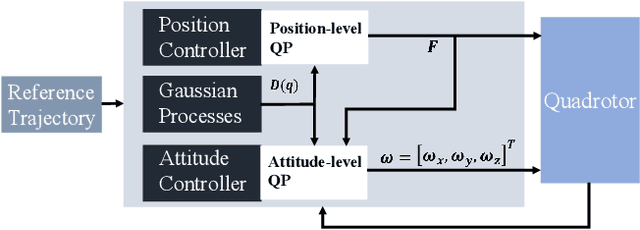
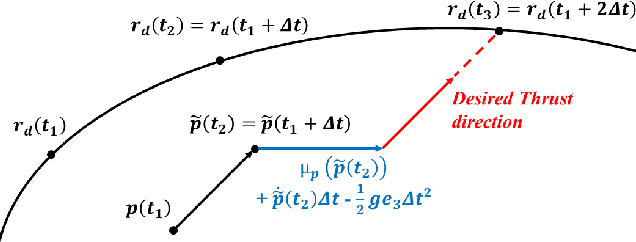
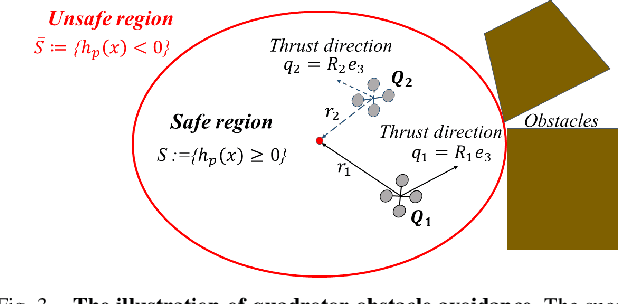
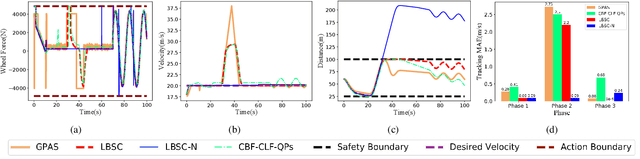
Enforcing safety on precise trajectory tracking is critical for aerial robotics subject to wind disturbances. In this paper, we present a learning-based safety-preserving cascaded quadratic programming control (SPQC) for safe trajectory tracking under wind disturbances. The SPQC controller consists of a position-level controller and an attitude-level controller. Gaussian Processes (GPs) are utilized to estimate the uncertainties caused by wind disturbances, and then a nominal Lyapunov-based cascaded quadratic program (QP) controller is designed to track the reference trajectory. To avoid unexpected obstacles when tracking, safety constraints represented by control barrier functions (CBFs) are enforced on each nominal QP controller in a way of minimal modification. The performance of the proposed SPQC controller is illustrated through numerical validations of (a) trajectory tracking under different wind disturbances, and (b) trajectory tracking in a cluttered environment with a dense time-varying obstacle field under wind disturbances.
JSCN: Joint Spectral Convolutional Network for Cross Domain Recommendation
Oct 18, 2019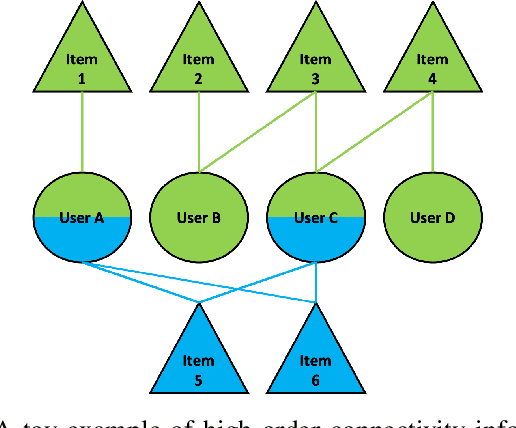
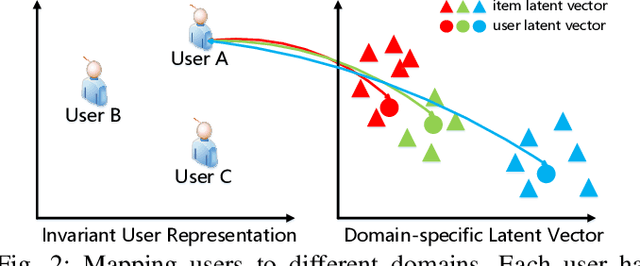
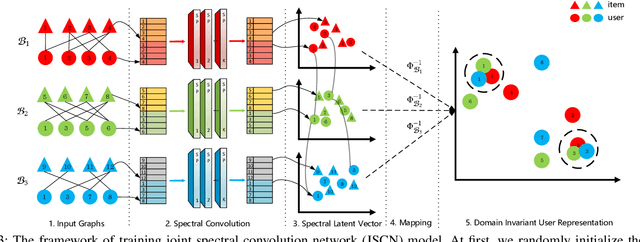
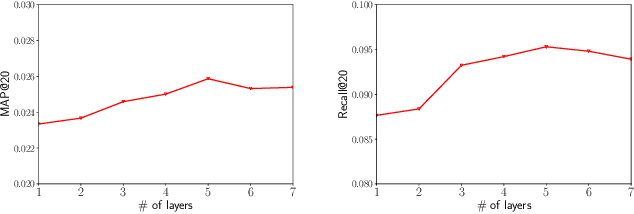
Cross-domain recommendation can alleviate the data sparsity problem in recommender systems. To transfer the knowledge from one domain to another, one can either utilize the neighborhood information or learn a direct mapping function. However, all existing methods ignore the high-order connectivity information in cross-domain recommendation area and suffer from the domain-incompatibility problem. In this paper, we propose a \textbf{J}oint \textbf{S}pectral \textbf{C}onvolutional \textbf{N}etwork (JSCN) for cross-domain recommendation. JSCN will simultaneously operate multi-layer spectral convolutions on different graphs, and jointly learn a domain-invariant user representation with a domain adaptive user mapping module. As a result, the high-order comprehensive connectivity information can be extracted by the spectral convolutions and the information can be transferred across domains with the domain-invariant user mapping. The domain adaptive user mapping module can help the incompatible domains to transfer the knowledge across each other. Extensive experiments on $24$ Amazon rating datasets show the effectiveness of JSCN in the cross-domain recommendation, with $9.2\%$ improvement on recall and $36.4\%$ improvement on MAP compared with state-of-the-art methods. Our code is available online ~\footnote{https://github.com/JimLiu96/JSCN}.
Deep Landscape Forecasting for Real-time Bidding Advertising
May 12, 2019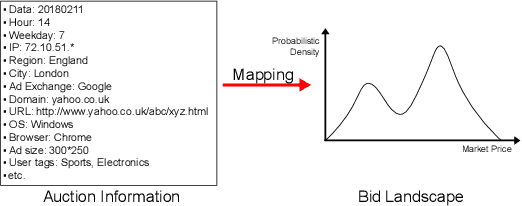
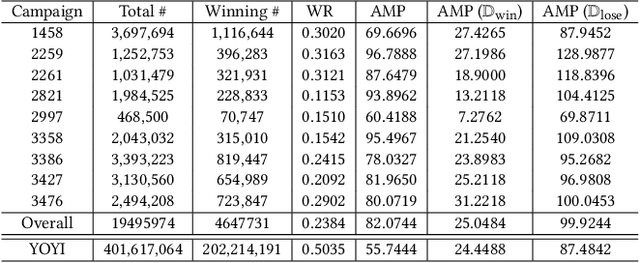
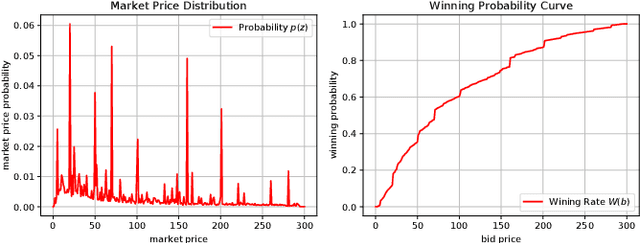
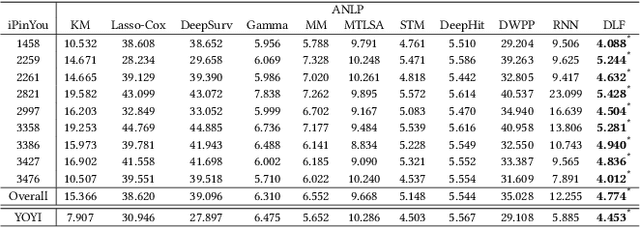
The emergence of real-time auction in online advertising has drawn huge attention of modeling the market competition, i.e., bid landscape forecasting. The problem is formulated as to forecast the probability distribution of market price for each ad auction. With the consideration of the censorship issue which is caused by the second-price auction mechanism, many researchers have devoted their efforts on bid landscape forecasting by incorporating survival analysis from medical research field. However, most existing solutions mainly focus on either counting-based statistics of the segmented sample clusters, or learning a parameterized model based on some heuristic assumptions of distribution forms. Moreover, they neither consider the sequential patterns of the feature over the price space. In order to capture more sophisticated yet flexible patterns at fine-grained level of the data, we propose a Deep Landscape Forecasting (DLF) model which combines deep learning for probability distribution forecasting and survival analysis for censorship handling. Specifically, we utilize a recurrent neural network to flexibly model the conditional winning probability w.r.t. each bid price. Then we conduct the bid landscape forecasting through probability chain rule with strict mathematical derivations. And, in an end-to-end manner, we optimize the model by minimizing two negative likelihood losses with comprehensive motivations. Without any specific assumption for the distribution form of bid landscape, our model shows great advantages over previous works on fitting various sophisticated market price distributions. In the experiments over two large-scale real-world datasets, our model significantly outperforms the state-of-the-art solutions under various metrics.
Automated Multiscale 3D Feature Learning for Vessels Segmentation in Thorax CT Images
Jan 06, 2019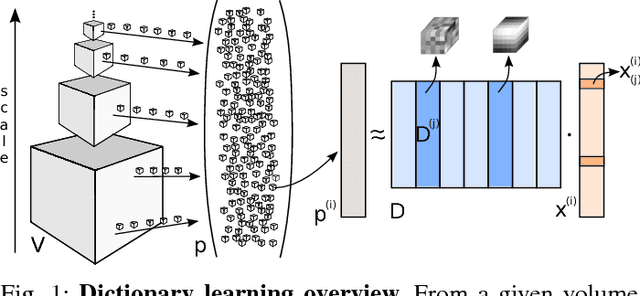
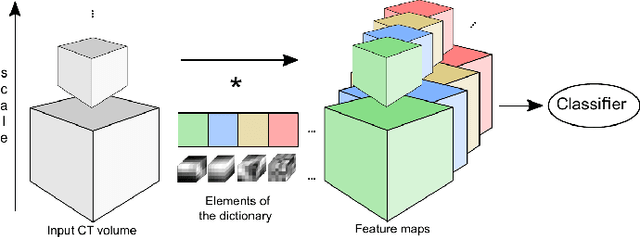

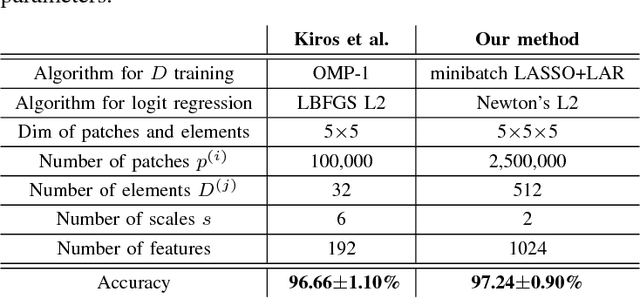
We address the vessel segmentation problem by building upon the multiscale feature learning method of Kiros et al., which achieves the current top score in the VESSEL12 MICCAI challenge. Following their idea of feature learning instead of hand-crafted filters, we have extended the method to learn 3D features. The features are learned in an unsupervised manner in a multi-scale scheme using dictionary learning via least angle regression. The 3D feature kernels are further convolved with the input volumes in order to create feature maps. Those maps are used to train a supervised classifier with the annotated voxels. In order to process the 3D data with a large number of filters a parallel implementation has been developed. The algorithm has been applied on the example scans and annotations provided by the VESSEL12 challenge. We have compared our setup with Kiros et al. by running their implementation. Our current results show an improvement in accuracy over the slice wise method from 96.66$\pm$1.10% to 97.24$\pm$0.90%.