 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenR: An Open Source Framework for Advanced Reasoning with Large Language Models
Oct 12, 2024



In this technical report, we introduce OpenR, an open-source framework designed to integrate key components for enhancing the reasoning capabilities of large language models (LLMs). OpenR unifies data acquisition, reinforcement learning training (both online and offline), and non-autoregressive decoding into a cohesive software platform. Our goal is to establish an open-source platform and community to accelerate the development of LLM reasoning. Inspired by the success of OpenAI's o1 model, which demonstrated improved reasoning abilities through step-by-step reasoning and reinforcement learning, OpenR integrates test-time compute, reinforcement learning, and process supervision to improve reasoning in LLMs. Our work is the first to provide an open-source framework that explores the core techniques of OpenAI's o1 model with reinforcement learning, achieving advanced reasoning capabilities beyond traditional autoregressive methods. We demonstrate the efficacy of OpenR by evaluating it on the MATH dataset, utilising publicly available data and search methods. Our initial experiments confirm substantial gains, with relative improvements in reasoning and performance driven by test-time computation and reinforcement learning through process reward models. The OpenR framework, including code, models, and datasets, is accessible at https://openreasoner.github.io.
Logic Synthesis Optimization with Predictive Self-Supervision via Causal Transformers
Sep 16, 2024



Contemporary hardware design benefits from the abstraction provided by high-level logic gates, streamlining the implementation of logic circuits. Logic Synthesis Optimization (LSO) operates at one level of abstraction within the Electronic Design Automation (EDA) workflow, targeting improvements in logic circuits with respect to performance metrics such as size and speed in the final layout. Recent trends in the field show a growing interest in leveraging Machine Learning (ML) for EDA, notably through ML-guided logic synthesis utilizing policy-based Reinforcement Learning (RL) methods.Despite these advancements, existing models face challenges such as overfitting and limited generalization, attributed to constrained public circuits and the expressiveness limitations of graph encoders. To address these hurdles, and tackle data scarcity issues, we introduce LSOformer, a novel approach harnessing Autoregressive transformer models and predictive SSL to predict the trajectory of Quality of Results (QoR). LSOformer integrates cross-attention modules to merge insights from circuit graphs and optimization sequences, thereby enhancing prediction accuracy for QoR metrics. Experimental studies validate the effectiveness of LSOformer, showcasing its superior performance over baseline architectures in QoR prediction tasks, where it achieves improvements of 5.74%, 4.35%, and 17.06% on the EPFL, OABCD, and proprietary circuits datasets, respectively, in inductive setup.
FuXi-2.0: Advancing machine learning weather forecasting model for practical applications
Sep 11, 2024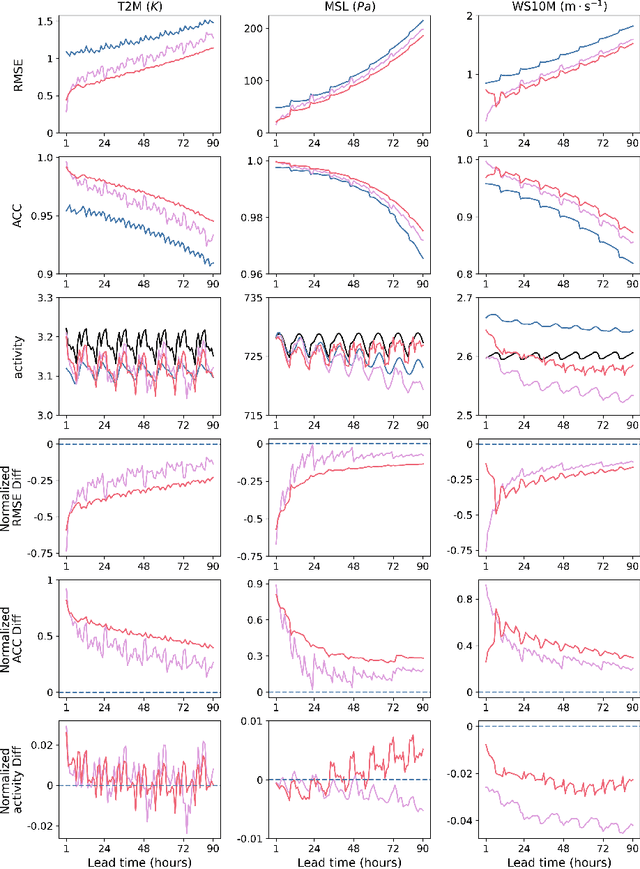
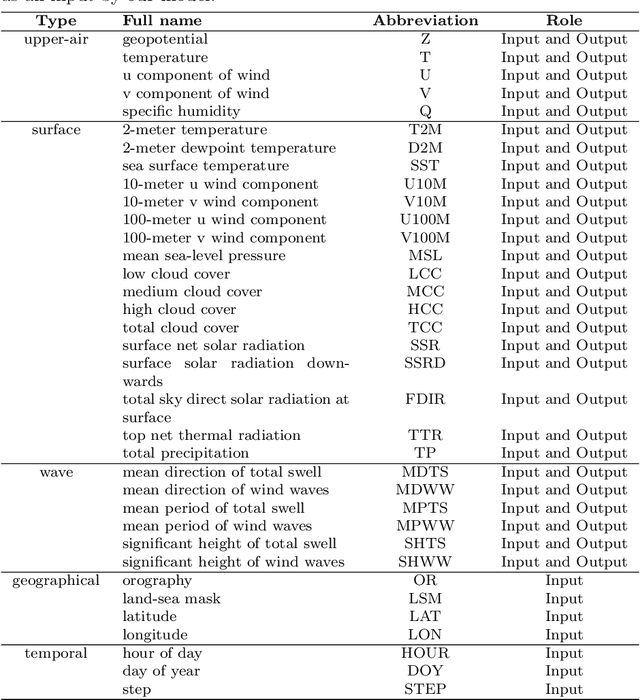
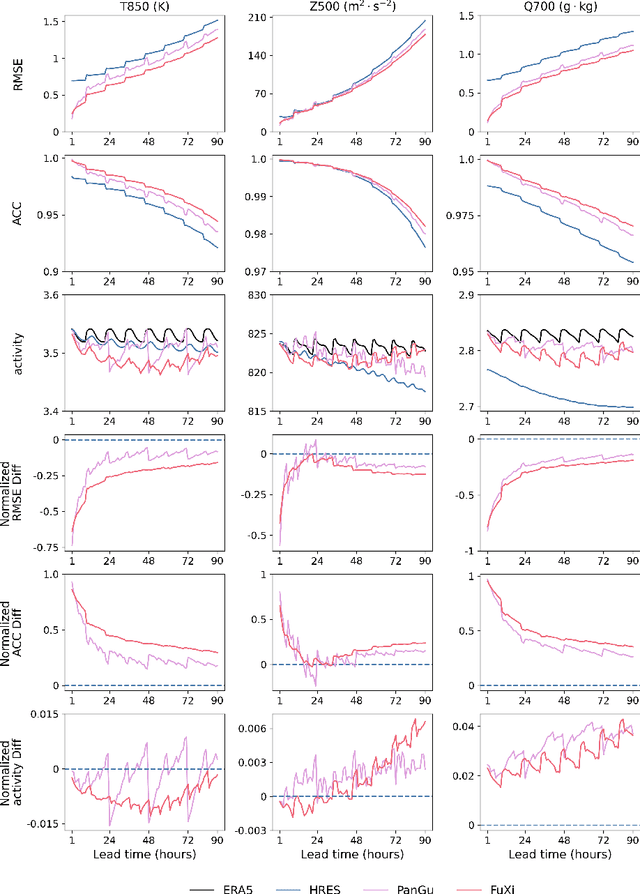
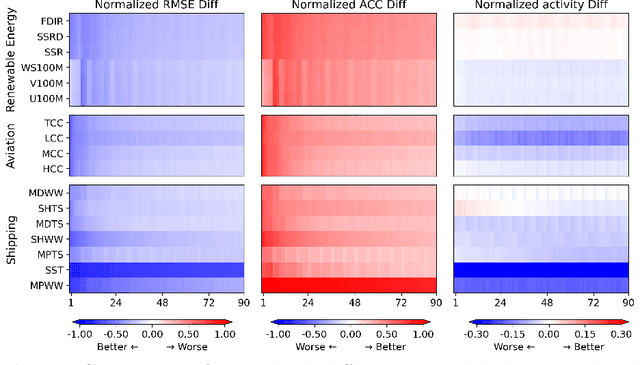
Machine learning (ML) models have become increasingly valuable in weather forecasting, providing forecasts that not only lower computational costs but often match or exceed the accuracy of traditional numerical weather prediction (NWP) models. Despite their potential, ML models typically suffer from limitations such as coarse temporal resolution, typically 6 hours, and a limited set of meteorological variables, limiting their practical applicability. To overcome these challenges, we introduce FuXi-2.0, an advanced ML model that delivers 1-hourly global weather forecasts and includes a comprehensive set of essential meteorological variables, thereby expanding its utility across various sectors like wind and solar energy, aviation, and marine shipping. Our study conducts comparative analyses between ML-based 1-hourly forecasts and those from the high-resolution forecast (HRES) of the European Centre for Medium-Range Weather Forecasts (ECMWF) for various practical scenarios. The results demonstrate that FuXi-2.0 consistently outperforms ECMWF HRES in forecasting key meteorological variables relevant to these sectors. In particular, FuXi-2.0 shows superior performance in wind power forecasting compared to ECMWF HRES, further validating its efficacy as a reliable tool for scenarios demanding precise weather forecasts. Additionally, FuXi-2.0 also integrates both atmospheric and oceanic components, representing a significant step forward in the development of coupled atmospheric-ocean models. Further comparative analyses reveal that FuXi-2.0 provides more accurate forecasts of tropical cyclone intensity than its predecessor, FuXi-1.0, suggesting that there are benefits of an atmosphere-ocean coupled model over atmosphere-only models.
Automate Strategy Finding with LLM in Quant investment
Sep 10, 2024



Despite significant progress in deep learning for financial trading, existing models often face instability and high uncertainty, hindering their practical application. Leveraging advancements in Large Language Models (LLMs) and multi-agent architectures, we propose a novel framework for quantitative stock investment in portfolio management and alpha mining. Our framework addresses these issues by integrating LLMs to generate diversified alphas and employing a multi-agent approach to dynamically evaluate market conditions. This paper proposes a framework where large language models (LLMs) mine alpha factors from multimodal financial data, ensuring a comprehensive understanding of market dynamics. The first module extracts predictive signals by integrating numerical data, research papers, and visual charts. The second module uses ensemble learning to construct a diverse pool of trading agents with varying risk preferences, enhancing strategy performance through a broader market analysis. In the third module, a dynamic weight-gating mechanism selects and assigns weights to the most relevant agents based on real-time market conditions, enabling the creation of an adaptive and context-aware composite alpha formula. Extensive experiments on the Chinese stock markets demonstrate that this framework significantly outperforms state-of-the-art baselines across multiple financial metrics. The results underscore the efficacy of combining LLM-generated alphas with a multi-agent architecture to achieve superior trading performance and stability. This work highlights the potential of AI-driven approaches in enhancing quantitative investment strategies and sets a new benchmark for integrating advanced machine learning techniques in financial trading can also be applied on diverse markets.
MTLSO: A Multi-Task Learning Approach for Logic Synthesis Optimization
Sep 09, 2024



Electronic Design Automation (EDA) is essential for IC design and has recently benefited from AI-based techniques to improve efficiency. Logic synthesis, a key EDA stage, transforms high-level hardware descriptions into optimized netlists. Recent research has employed machine learning to predict Quality of Results (QoR) for pairs of And-Inverter Graphs (AIGs) and synthesis recipes. However, the severe scarcity of data due to a very limited number of available AIGs results in overfitting, significantly hindering performance. Additionally, the complexity and large number of nodes in AIGs make plain GNNs less effective for learning expressive graph-level representations. To tackle these challenges, we propose MTLSO - a Multi-Task Learning approach for Logic Synthesis Optimization. On one hand, it maximizes the use of limited data by training the model across different tasks. This includes introducing an auxiliary task of binary multi-label graph classification alongside the primary regression task, allowing the model to benefit from diverse supervision sources. On the other hand, we employ a hierarchical graph representation learning strategy to improve the model's capacity for learning expressive graph-level representations of large AIGs, surpassing traditional plain GNNs. Extensive experiments across multiple datasets and against state-of-the-art baselines demonstrate the superiority of our method, achieving an average performance gain of 8.22\% for delay and 5.95\% for area.
Up-sampling-only and Adaptive Mesh-based GNN for Simulating Physical Systems
Sep 07, 2024



Traditional simulation of complex mechanical systems relies on numerical solvers of Partial Differential Equations (PDEs), e.g., using the Finite Element Method (FEM). The FEM solvers frequently suffer from intensive computation cost and high running time. Recent graph neural network (GNN)-based simulation models can improve running time meanwhile with acceptable accuracy. Unfortunately, they are hard to tailor GNNs for complex mechanical systems, including such disadvantages as ineffective representation and inefficient message propagation (MP). To tackle these issues, in this paper, with the proposed Up-sampling-only and Adaptive MP techniques, we develop a novel hierarchical Mesh Graph Network, namely UA-MGN, for efficient and effective mechanical simulation. Evaluation on two synthetic and one real datasets demonstrates the superiority of the UA-MGN. For example, on the Beam dataset, compared to the state-of-the-art MS-MGN, UA-MGN leads to 40.99% lower errors but using only 43.48% fewer network parameters and 4.49% fewer floating point operations (FLOPs).
ShortCircuit: AlphaZero-Driven Circuit Design
Aug 19, 2024



Chip design relies heavily on generating Boolean circuits, such as AND-Inverter Graphs (AIGs), from functional descriptions like truth tables. While recent advances in deep learning have aimed to accelerate circuit design, these efforts have mostly focused on tasks other than synthesis, and traditional heuristic methods have plateaued. In this paper, we introduce ShortCircuit, a novel transformer-based architecture that leverages the structural properties of AIGs and performs efficient space exploration. Contrary to prior approaches attempting end-to-end generation of logic circuits using deep networks, ShortCircuit employs a two-phase process combining supervised with reinforcement learning to enhance generalization to unseen truth tables. We also propose an AlphaZero variant to handle the double exponentially large state space and the sparsity of the rewards, enabling the discovery of near-optimal designs. To evaluate the generative performance of our trained model , we extract 500 truth tables from a benchmark set of 20 real-world circuits. ShortCircuit successfully generates AIGs for 84.6% of the 8-input test truth tables, and outperforms the state-of-the-art logic synthesis tool, ABC, by 14.61% in terms of circuits size.
Computation-friendly Graph Neural Network Design by Accumulating Knowledge on Large Language Models
Aug 13, 2024



Graph Neural Networks (GNNs), like other neural networks, have shown remarkable success but are hampered by the complexity of their architecture designs, which heavily depend on specific data and tasks. Traditionally, designing proper architectures involves trial and error, which requires intensive manual effort to optimize various components. To reduce human workload, researchers try to develop automated algorithms to design GNNs. However, both experts and automated algorithms suffer from two major issues in designing GNNs: 1) the substantial computational resources expended in repeatedly trying candidate GNN architectures until a feasible design is achieved, and 2) the intricate and prolonged processes required for humans or algorithms to accumulate knowledge of the interrelationship between graphs, GNNs, and performance. To further enhance the automation of GNN architecture design, we propose a computation-friendly way to empower Large Language Models (LLMs) with specialized knowledge in designing GNNs, thereby drastically shortening the computational overhead and development cycle of designing GNN architectures. Our framework begins by establishing a knowledge retrieval pipeline that comprehends the intercorrelations between graphs, GNNs, and performance. This pipeline converts past model design experiences into structured knowledge for LLM reference, allowing it to quickly suggest initial model proposals. Subsequently, we introduce a knowledge-driven search strategy that emulates the exploration-exploitation process of human experts, enabling quick refinement of initial proposals within a promising scope. Extensive experiments demonstrate that our framework can efficiently deliver promising (e.g., Top-5.77%) initial model proposals for unseen datasets within seconds and without any prior training and achieve outstanding search performance in a few iterations.
Class-aware and Augmentation-free Contrastive Learning from Label Proportion
Aug 13, 2024



Learning from Label Proportion (LLP) is a weakly supervised learning scenario in which training data is organized into predefined bags of instances, disclosing only the class label proportions per bag. This paradigm is essential for user modeling and personalization, where user privacy is paramount, offering insights into user preferences without revealing individual data. LLP faces a unique difficulty: the misalignment between bag-level supervision and the objective of instance-level prediction, primarily due to the inherent ambiguity in label proportion matching. Previous studies have demonstrated deep representation learning can generate auxiliary signals to promote the supervision level in the image domain. However, applying these techniques to tabular data presents significant challenges: 1) they rely heavily on label-invariant augmentation to establish multi-view, which is not feasible with the heterogeneous nature of tabular datasets, and 2) tabular datasets often lack sufficient semantics for perfect class distinction, making them prone to suboptimality caused by the inherent ambiguity of label proportion matching. To address these challenges, we propose an augmentation-free contrastive framework TabLLP-BDC that introduces class-aware supervision (explicitly aware of class differences) at the instance level. Our solution features a two-stage Bag Difference Contrastive (BDC) learning mechanism that establishes robust class-aware instance-level supervision by disassembling the nuance between bag label proportions, without relying on augmentations. Concurrently, our model presents a pioneering multi-task pretraining pipeline tailored for tabular-based LLP, capturing intrinsic tabular feature correlations in alignment with label proportion distribution. Extensive experiments demonstrate that TabLLP-BDC achieves state-of-the-art performance for LLP in the tabular domain.
AHMF: Adaptive Hybrid-Memory-Fusion Model for Driver Attention Prediction
Jul 24, 2024



Accurate driver attention prediction can serve as a critical reference for intelligent vehicles in understanding traffic scenes and making informed driving decisions. Though existing studies on driver attention prediction improved performance by incorporating advanced saliency detection techniques, they overlooked the opportunity to achieve human-inspired prediction by analyzing driving tasks from a cognitive science perspective. During driving, drivers' working memory and long-term memory play crucial roles in scene comprehension and experience retrieval, respectively. Together, they form situational awareness, facilitating drivers to quickly understand the current traffic situation and make optimal decisions based on past driving experiences. To explicitly integrate these two types of memory, this paper proposes an Adaptive Hybrid-Memory-Fusion (AHMF) driver attention prediction model to achieve more human-like predictions. Specifically, the model first encodes information about specific hazardous stimuli in the current scene to form working memories. Then, it adaptively retrieves similar situational experiences from the long-term memory for final prediction. Utilizing domain adaptation techniques, the model performs parallel training across multiple datasets, thereby enriching the accumulated driving experience within the long-term memory module. Compared to existing models, our model demonstrates significant improvements across various metrics on multiple public datasets, proving the effectiveness of integrating hybrid memories in driver attention prediction.