 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: Grounding Time Series in Context for Multimodal Embedding and Retrieval
Jun 10, 2025The ubiquity of dynamic data in domains such as weather, healthcare, and energy underscores a growing need for effective interpretation and retrieval of time-series data. These data are inherently tied to domain-specific contexts, such as clinical notes or weather narratives, making cross-modal retrieval essential not only for downstream tasks but also for developing robust time-series foundation models by retrieval-augmented generation (RAG). Despite the increasing demand, time-series retrieval remains largely underexplored. Existing methods often lack semantic grounding, struggle to align heterogeneous modalities, and have limited capacity for handling multi-channel signals. To address this gap, we propose TRACE, a generic multimodal retriever that grounds time-series embeddings in aligned textual context. TRACE enables fine-grained channel-level alignment and employs hard negative mining to facilitate semantically meaningful retrieval. It supports flexible cross-modal retrieval modes, including Text-to-Timeseries and Timeseries-to-Text, effectively linking linguistic descriptions with complex temporal patterns. By retrieving semantically relevant pairs, TRACE enriches downstream models with informative context, leading to improved predictive accuracy and interpretability. Beyond a static retrieval engine, TRACE also serves as a powerful standalone encoder, with lightweight task-specific tuning that refines context-aware representations while maintaining strong cross-modal alignment. These representations achieve state-of-the-art performance on downstream forecasting and classification tasks. Extensive experiments across multiple domains highlight its dual utility, as both an effective encoder for downstream applications and a general-purpose retriever to enhance time-series models.
MTBench: A Multimodal Time Series Benchmark for Temporal Reasoning and Question Answering
Mar 21, 2025


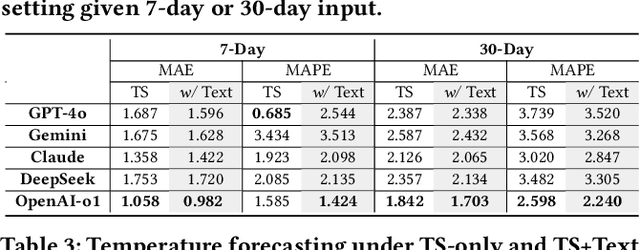
Understanding the relationship between textual news and time-series evolution is a critical yet under-explored challenge in applied data science. While multimodal learning has gained traction, existing multimodal time-series datasets fall short in evaluating cross-modal reasoning and complex question answering, which are essential for capturing complex interactions between narrative information and temporal patterns. To bridge this gap, we introduce Multimodal Time Series Benchmark (MTBench), a large-scale benchmark designed to evaluate large language models (LLMs) on time series and text understanding across financial and weather domains. MTbench comprises paired time series and textual data, including financial news with corresponding stock price movements and weather reports aligned with historical temperature records. Unlike existing benchmarks that focus on isolated modalities, MTbench provides a comprehensive testbed for models to jointly reason over structured numerical trends and unstructured textual narratives. The richness of MTbench enables formulation of diverse tasks that require a deep understanding of both text and time-series data, including time-series forecasting, semantic and technical trend analysis, and news-driven question answering (QA). These tasks target the model's ability to capture temporal dependencies, extract key insights from textual context, and integrate cross-modal information. We evaluate state-of-the-art LLMs on MTbench, analyzing their effectiveness in modeling the complex relationships between news narratives and temporal patterns. Our findings reveal significant challenges in current models, including difficulties in capturing long-term dependencies, interpreting causality in financial and weather trends, and effectively fusing multimodal information.