 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure multiparty computations in floating-point arithmetic
Jan 09, 2020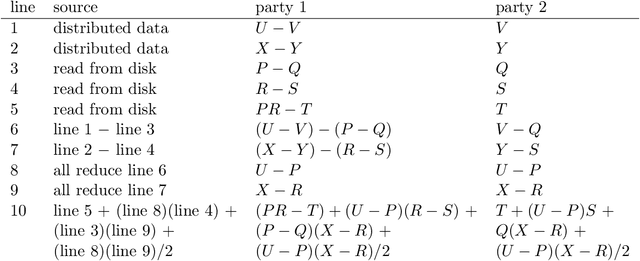
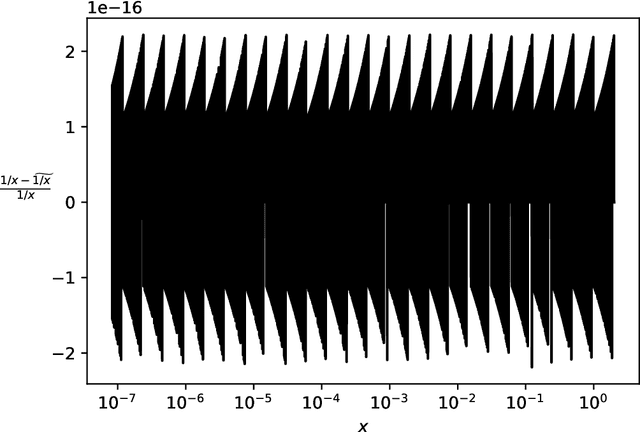
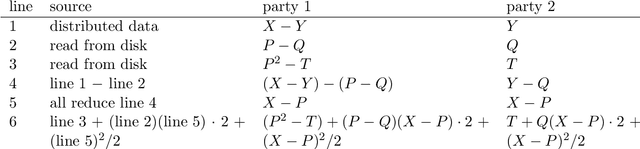
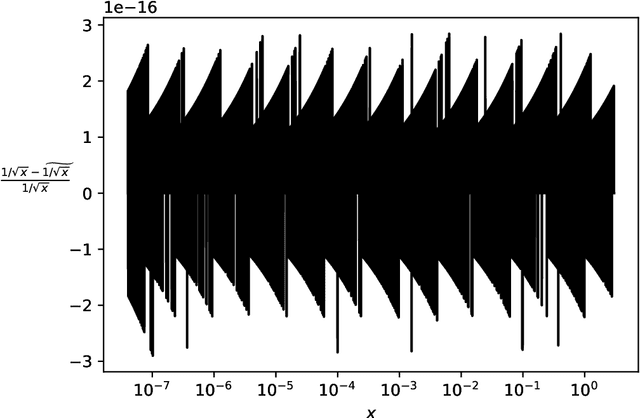
Secure multiparty computations enable the distribution of so-called shares of sensitive data to multiple parties such that the multiple parties can effectively process the data while being unable to glean much information about the data (at least not without collusion among all parties to put back together all the shares). Thus, the parties may conspire to send all their processed results to a trusted third party (perhaps the data provider) at the conclusion of the computations, with only the trusted third party being able to view the final results. Secure multiparty computations for privacy-preserving machine-learning turn out to be possible using solely standard floating-point arithmetic, at least with a carefully controlled leakage of information less than the loss of accuracy due to roundoff, all backed by rigorous mathematical proofs of worst-case bounds on information loss and numerical stability in finite-precision arithmetic. Numerical examples illustrate the high performance attained on commodity off-the-shelf hardware for generalized linear models, including ordinary linear least-squares regression, binary and multinomial logistic regression, probit regression, and Poisson regression.
Convolutional Networks with Dense Connectivity
Jan 08, 2020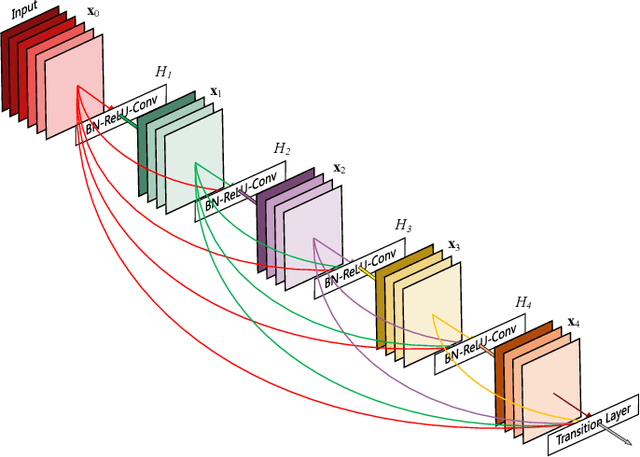
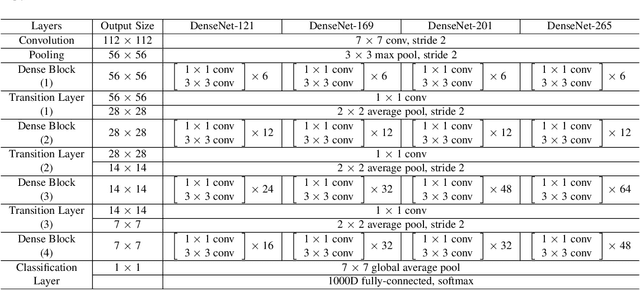

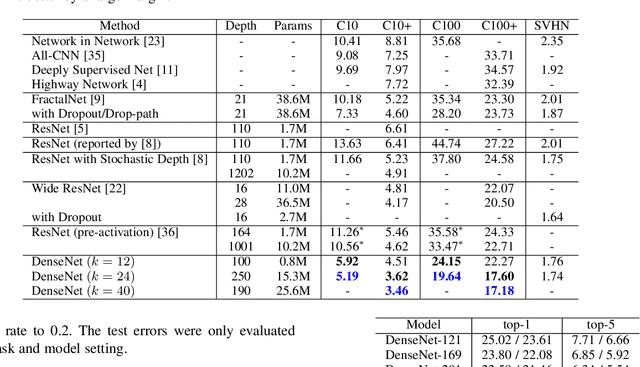
Recent work has shown that convolutional networks can be substantially deeper, more accurate, and efficient to train if they contain shorter connections between layers close to the input and those close to the output. In this paper, we embrace this observation and introduce the Dense Convolutional Network (DenseNet), which connects each layer to every other layer in a feed-forward fashion.Whereas traditional convolutional networks with L layers have L connections - one between each layer and its subsequent layer - our network has L(L+1)/2 direct connections. For each layer, the feature-maps of all preceding layers are used as inputs, and its own feature-maps are used as inputs into all subsequent layers. DenseNets have several compelling advantages: they alleviate the vanishing-gradient problem, encourage feature reuse and substantially improve parameter efficiency. We evaluate our proposed architecture on four highly competitive object recognition benchmark tasks (CIFAR-10, CIFAR-100, SVHN, and ImageNet). DenseNets obtain significant improvements over the state-of-the-art on most of them, whilst requiring less parameters and computation to achieve high performance.
Measuring Dataset Granularity
Dec 21, 2019
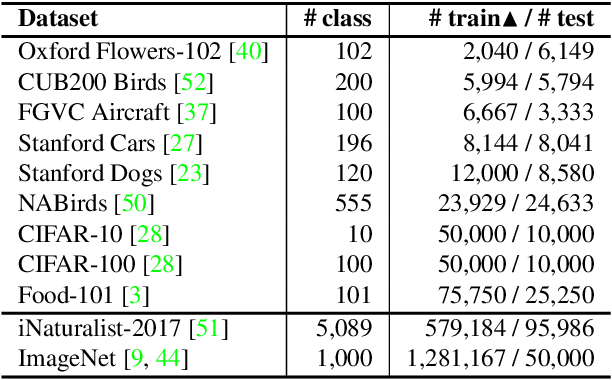
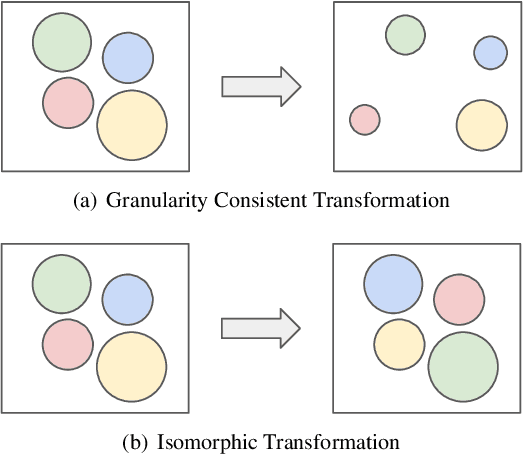
Despite the increasing visibility of fine-grained recognition in our field, "fine-grained'' has thus far lacked a precise definition. In this work, building upon clustering theory, we pursue a framework for measuring dataset granularity. We argue that dataset granularity should depend not only on the data samples and their labels, but also on the distance function we choose. We propose an axiomatic framework to capture desired properties for a dataset granularity measure and provide examples of measures that satisfy these properties. We assess each measure via experiments on datasets with hierarchical labels of varying granularity. When measuring granularity in commonly used datasets with our measure, we find that certain datasets that are widely considered fine-grained in fact contain subsets of considerable size that are substantially more coarse-grained than datasets generally regarded as coarse-grained. We also investigate the interplay between dataset granularity with a variety of factors and find that fine-grained datasets are more difficult to learn from, more difficult to transfer to, more difficult to perform few-shot learning with, and more vulnerable to adversarial attacks.
Self-Supervised Learning of Pretext-Invariant Representations
Dec 04, 2019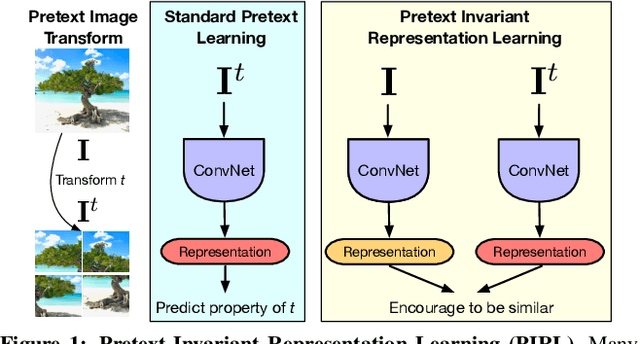
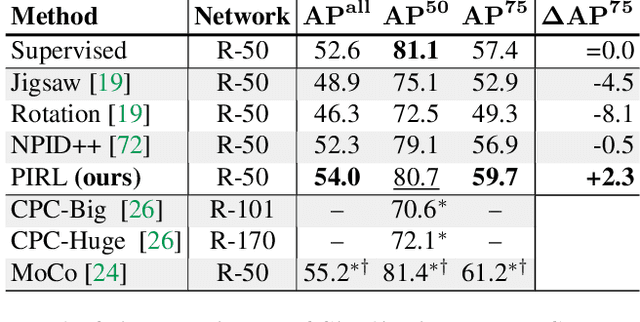
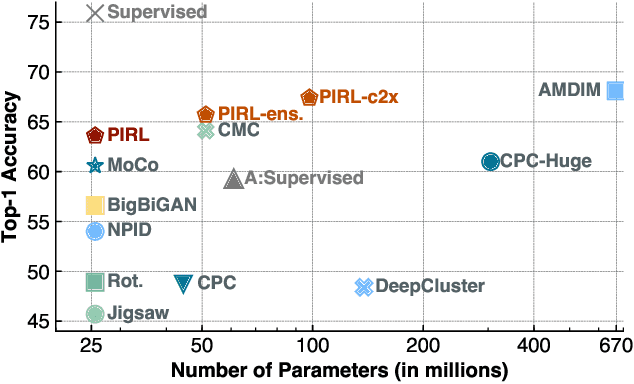
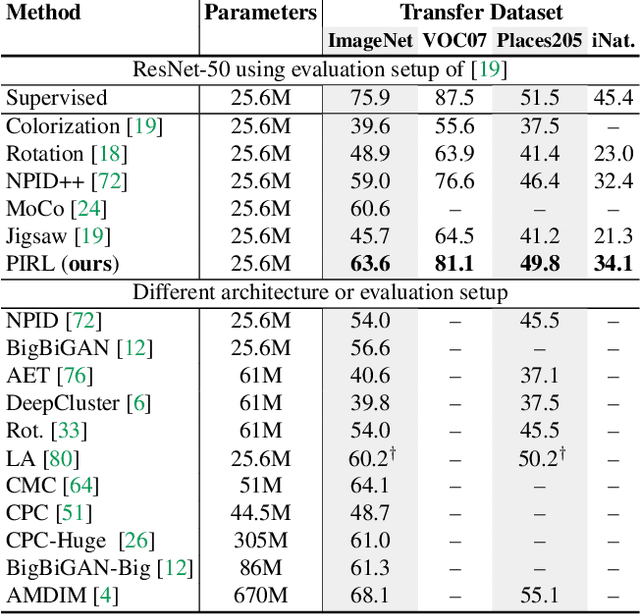
The goal of self-supervised learning from images is to construct image representations that are semantically meaningful via pretext tasks that do not require semantic annotations for a large training set of images. Many pretext tasks lead to representations that are covariant with image transformations. We argue that, instead, semantic representations ought to be invariant under such transformations. Specifically, we develop Pretext-Invariant Representation Learning (PIRL, pronounced as "pearl") that learns invariant representations based on pretext tasks. We use PIRL with a commonly used pretext task that involves solving jigsaw puzzles. We find that PIRL substantially improves the semantic quality of the learned image representations. Our approach sets a new state-of-the-art in self-supervised learning from images on several popular benchmarks for self-supervised learning. Despite being unsupervised, PIRL outperforms supervised pre-training in learning image representations for object detection. Altogether, our results demonstrate the potential of self-supervised learning of image representations with good invariance properties.
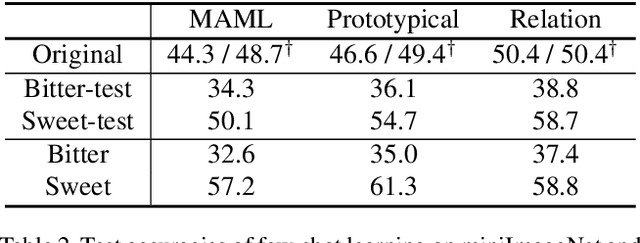
SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning
Nov 16, 2019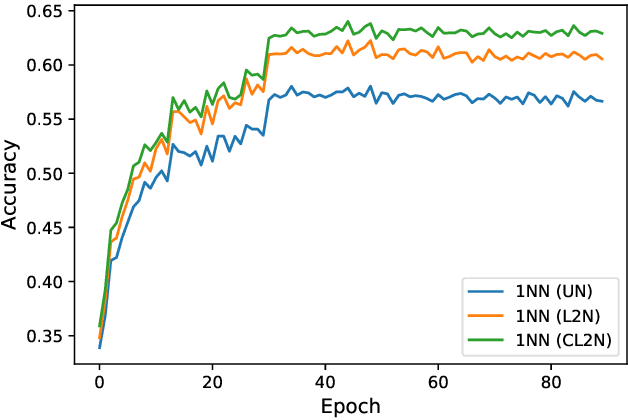
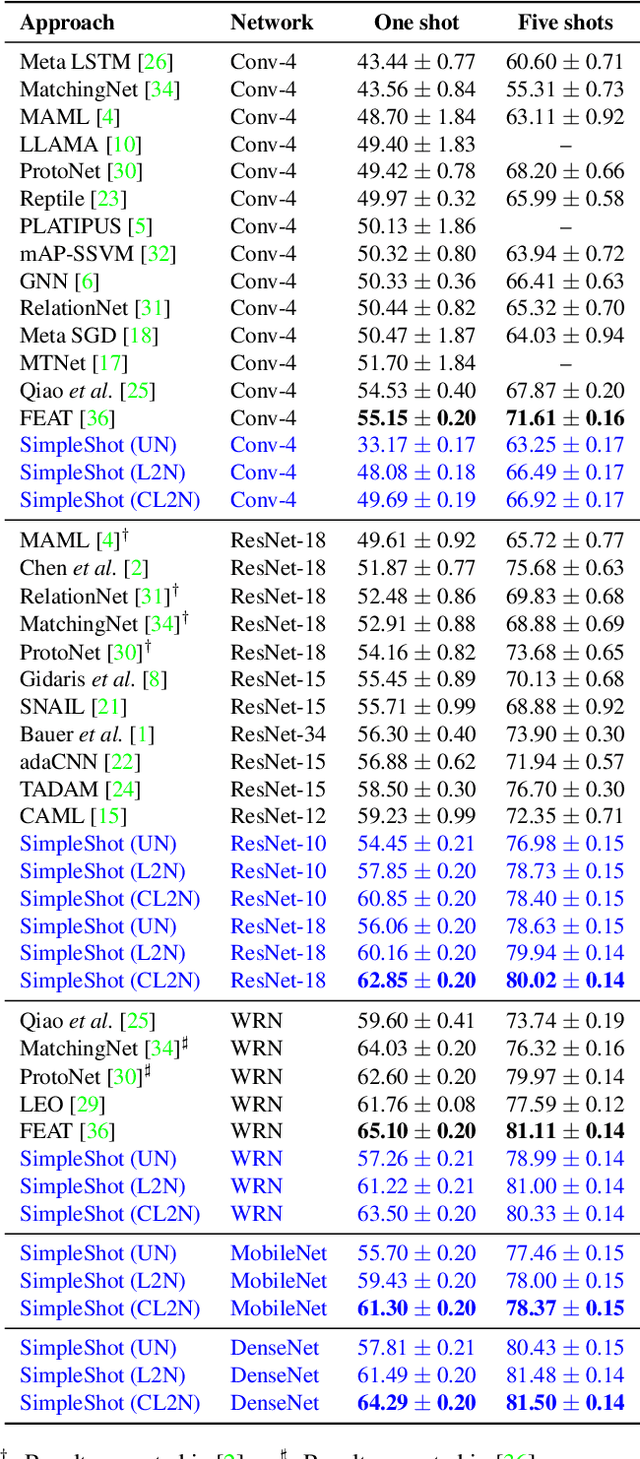
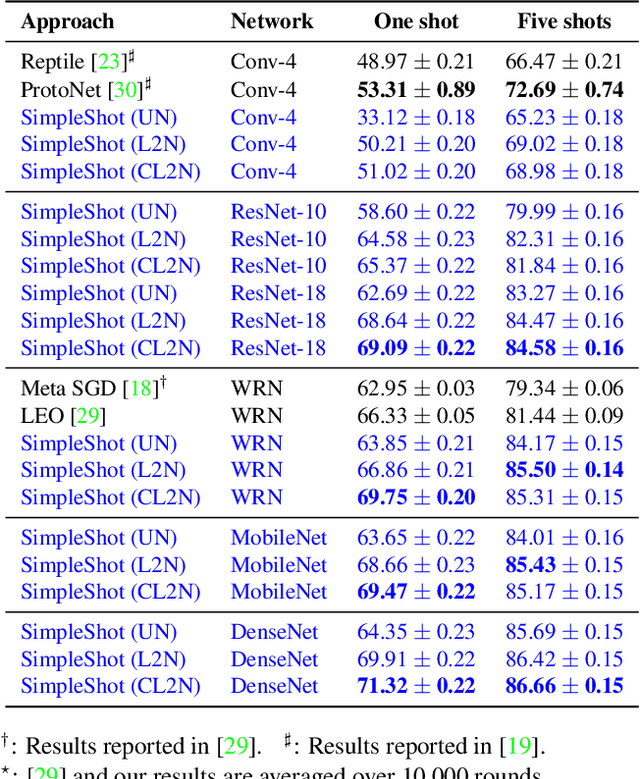
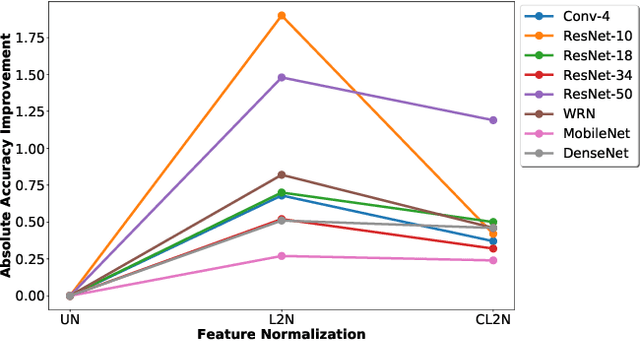
Few-shot learners aim to recognize new object classes based on a small number of labeled training examples. To prevent overfitting, state-of-the-art few-shot learners use meta-learning on convolutional-network features and perform classification using a nearest-neighbor classifier. This paper studies the accuracy of nearest-neighbor baselines without meta-learning. Surprisingly, we find simple feature transformations suffice to obtain competitive few-shot learning accuracies. For example, we find that a nearest-neighbor classifier used in combination with mean-subtraction and L2-normalization outperforms prior results in three out of five settings on the miniImageNet dataset.
Certified Data Removal from Machine Learning Models
Nov 11, 2019
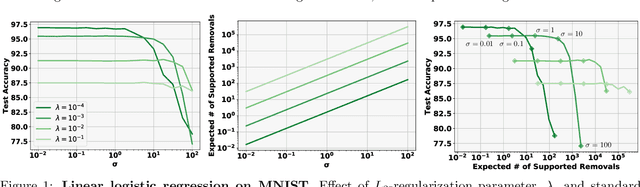
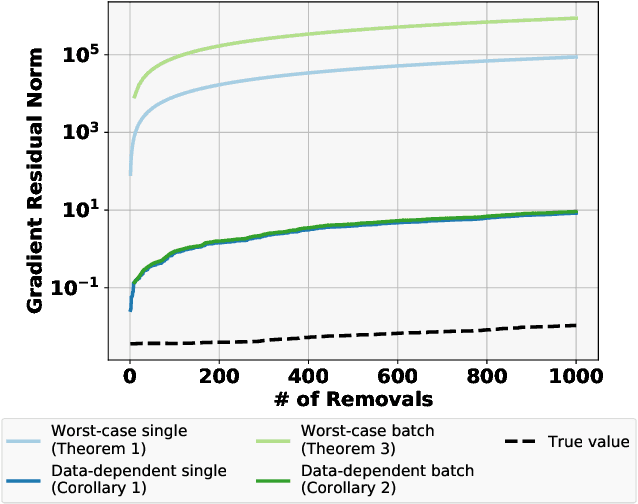

Good data stewardship requires removal of data at the request of the data's owner. This raises the question if and how a trained machine-learning model, which implicitly stores information about its training data, should be affected by such a removal request. Is it possible to "remove" data from a machine-learning model? We study this problem by defining certified removal: a very strong theoretical guarantee that a model from which data is removed cannot be distinguished from a model that never observed the data to begin with. We develop a certified-removal mechanism for linear classifiers and empirically study learning settings in which this mechanism is practical.
Privacy-Preserving Contextual Bandits
Oct 14, 2019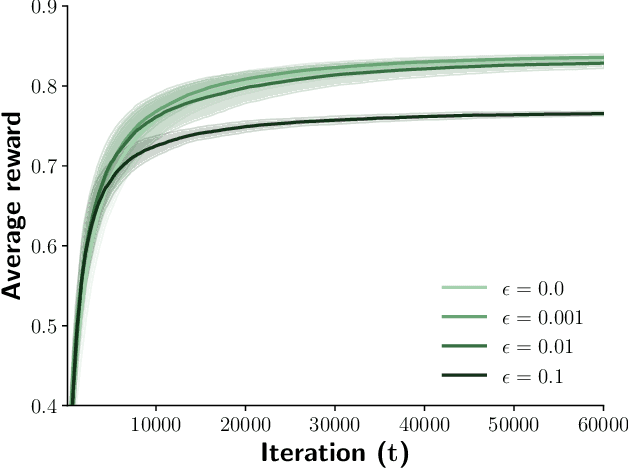
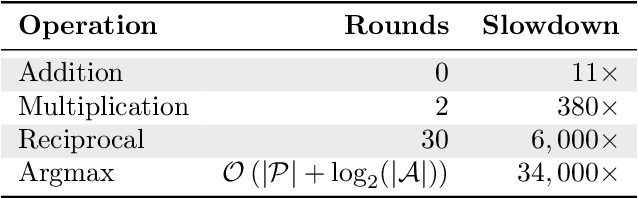
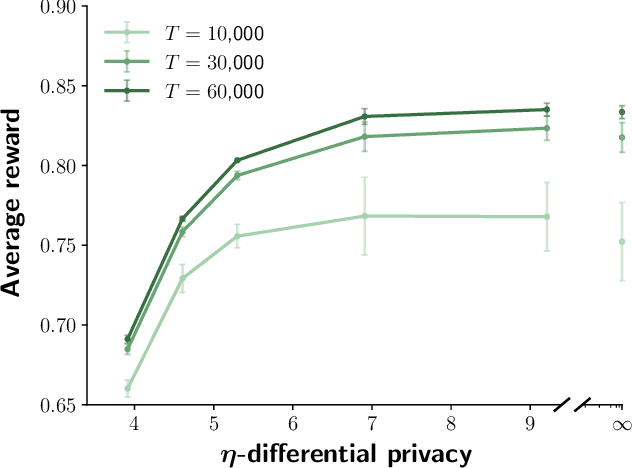
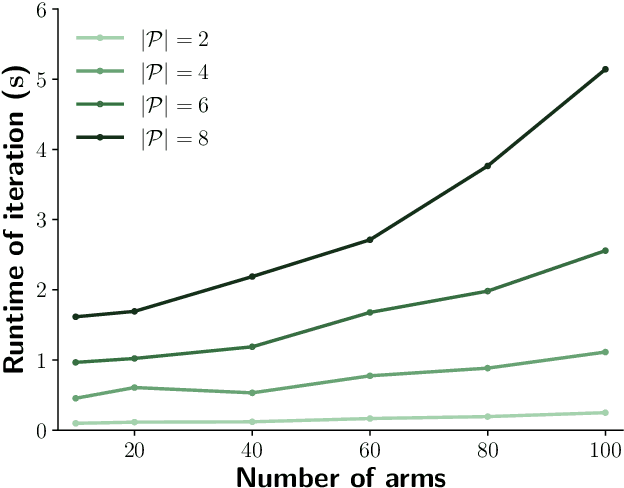
Contextual bandits are online learners that, given an input, select an arm and receive a reward for that arm. They use the reward as a learning signal and aim to maximize the total reward over the inputs. Contextual bandits are commonly used to solve recommendation or ranking problems. This paper considers a learning setting in which multiple parties aim to train a contextual bandit together in a private way: the parties aim to maximize the total reward but do not want to share any of the relevant information they possess with the other parties. Specifically, multiple parties have access to (different) features that may benefit the learner but that cannot be shared with other parties. One of the parties pulls the arm but other parties may not learn which arm was pulled. One party receives the reward but the other parties may not learn the reward value. This paper develops a privacy-preserving contextual bandit algorithm that combines secure multi-party computation with a differential private mechanism based on epsilon-greedy exploration in contextual bandits.
PHYRE: A New Benchmark for Physical Reasoning
Aug 15, 2019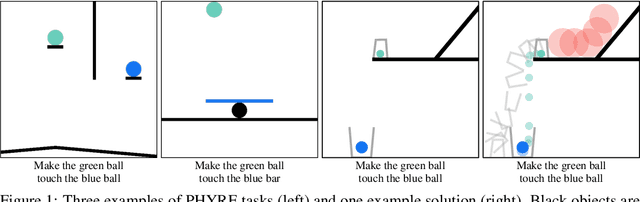
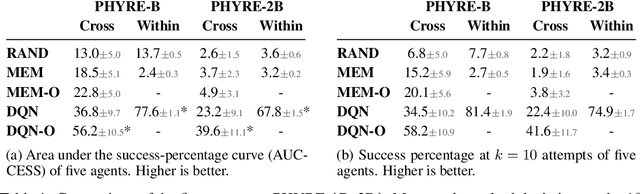
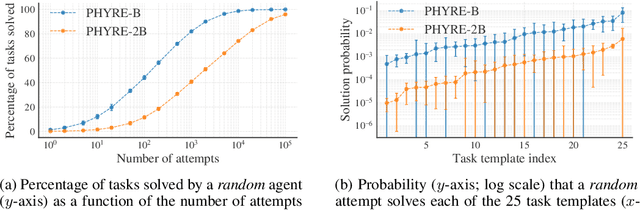
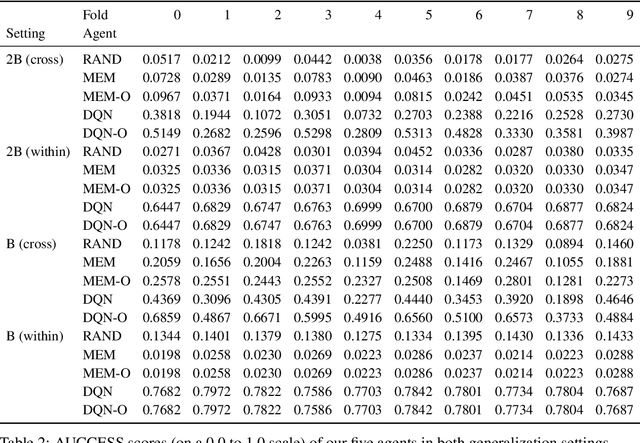
Understanding and reasoning about physics is an important ability of intelligent agents. We develop the PHYRE benchmark for physical reasoning that contains a set of simple classical mechanics puzzles in a 2D physical environment. The benchmark is designed to encourage the development of learning algorithms that are sample-efficient and generalize well across puzzles. We test several modern learning algorithms on PHYRE and find that these algorithms fall short in solving the puzzles efficiently. We expect that PHYRE will encourage the development of novel sample-efficient agents that learn efficient but useful models of physics. For code and to play PHYRE for yourself, please visit https://player.phyre.ai.
Does Object Recognition Work for Everyone?
Jun 18, 2019
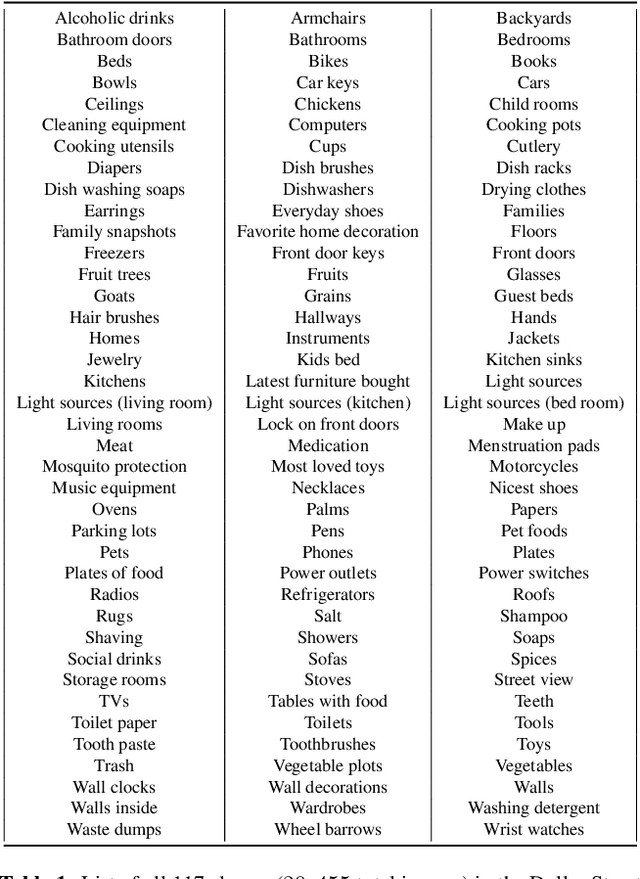
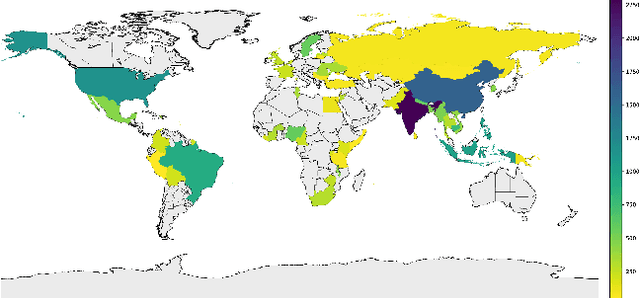
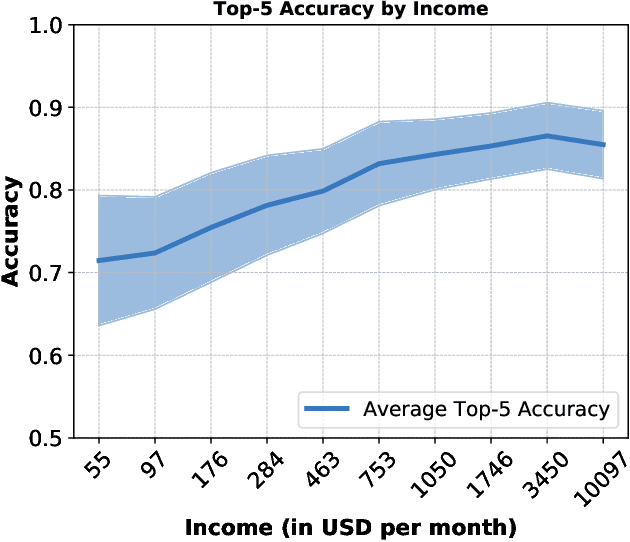
The paper analyzes the accuracy of publicly available object-recognition systems on a geographically diverse dataset. This dataset contains household items and was designed to have a more representative geographical coverage than commonly used image datasets in object recognition. We find that the systems perform relatively poorly on household items that commonly occur in countries with a low household income. Qualitative analyses suggest the drop in performance is primarily due to appearance differences within an object class (e.g., dish soap) and due to items appearing in a different context (e.g., toothbrushes appearing outside of bathrooms). The results of our study suggest that further work is needed to make object-recognition systems work equally well for people across different countries and income levels.
Defense Against Adversarial Images using Web-Scale Nearest-Neighbor Search
Mar 05, 2019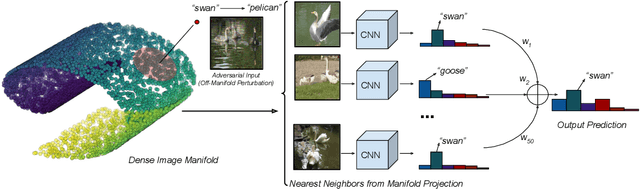


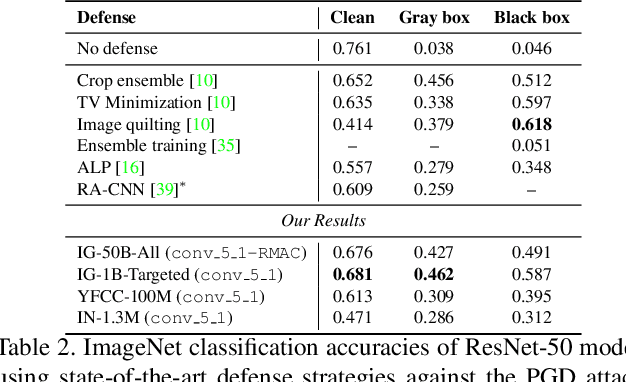
A plethora of recent work has shown that convolutional networks are not robust to adversarial images: images that are created by perturbing a sample from the data distribution as to maximize the loss on the perturbed example. In this work, we hypothesize that adversarial perturbations move the image away from the image manifold in the sense that there exists no physical process that could have produced the adversarial image. This hypothesis suggests that a successful defense mechanism against adversarial images should aim to project the images back onto the image manifold. We study such defense mechanisms, which approximate the projection onto the unknown image manifold by a nearest-neighbor search against a web-scale image database containing tens of billions of images. Empirical evaluations of this defense strategy on ImageNet suggest that it is very effective in attack settings in which the adversary does not have access to the image database. We also propose two novel attack methods to break nearest-neighbor defenses, and demonstrate conditions under which nearest-neighbor defense fails. We perform a series of ablation experiments, which suggest that there is a trade-off between robustness and accuracy in our defenses, that a large image database (with hundreds of millions of images) is crucial to get good performance, and that careful construction the image database is important to be robust against attacks tailored to circumvent our defenses.