 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Weakly Supervised Pre-Training of Visual Perception Models
Jan 20, 2022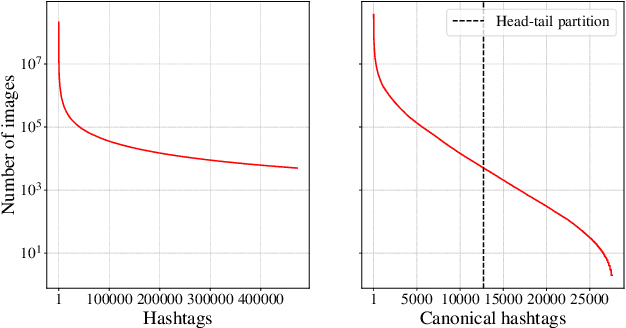
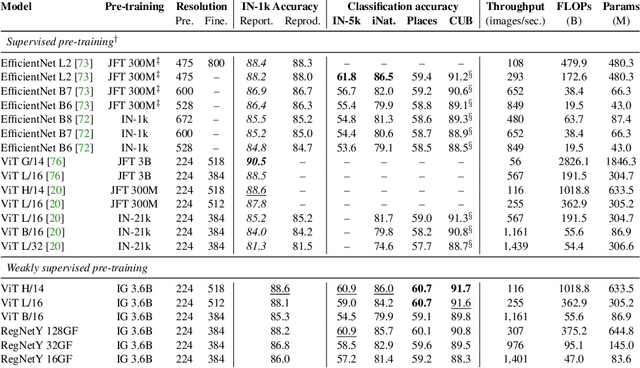
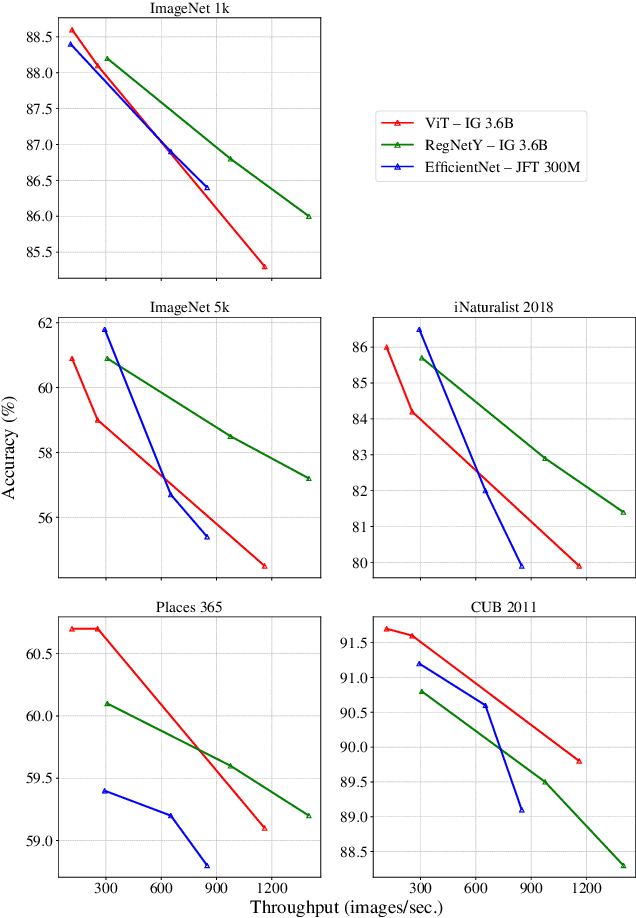
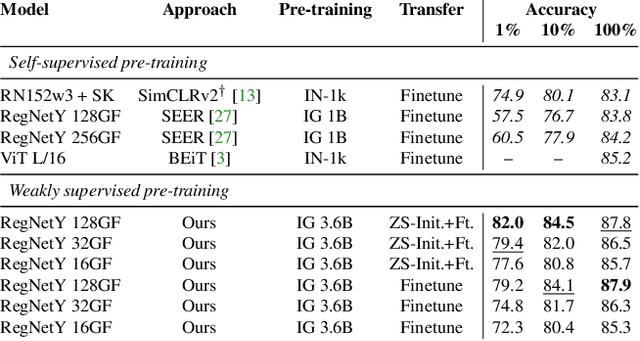
Model pre-training is a cornerstone of modern visual recognition systems. Although fully supervised pre-training on datasets like ImageNet is still the de-facto standard, recent studies suggest that large-scale weakly supervised pre-training can outperform fully supervised approaches. This paper revisits weakly-supervised pre-training of models using hashtag supervision with modern versions of residual networks and the largest-ever dataset of images and corresponding hashtags. We study the performance of the resulting models in various transfer-learning settings including zero-shot transfer. We also compare our models with those obtained via large-scale self-supervised learning. We find our weakly-supervised models to be very competitive across all settings, and find they substantially outperform their self-supervised counterparts. We also include an investigation into whether our models learned potentially troubling associations or stereotypes. Overall, our results provide a compelling argument for the use of weakly supervised learning in the development of visual recognition systems. Our models, Supervised Weakly through hashtAGs (SWAG), are available publicly.
Submix: Practical Private Prediction for Large-Scale Language Models
Jan 04, 2022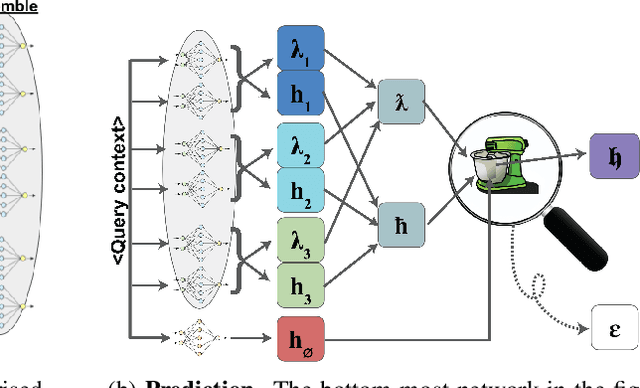

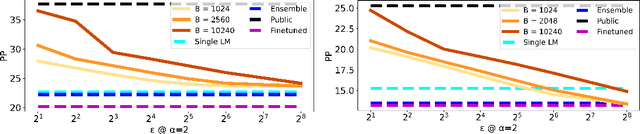
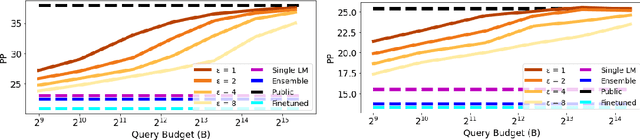
Recent data-extraction attacks have exposed that language models can memorize some training samples verbatim. This is a vulnerability that can compromise the privacy of the model's training data. In this work, we introduce SubMix: a practical protocol for private next-token prediction designed to prevent privacy violations by language models that were fine-tuned on a private corpus after pre-training on a public corpus. We show that SubMix limits the leakage of information that is unique to any individual user in the private corpus via a relaxation of group differentially private prediction. Importantly, SubMix admits a tight, data-dependent privacy accounting mechanism, which allows it to thwart existing data-extraction attacks while maintaining the utility of the language model. SubMix is the first protocol that maintains privacy even when publicly releasing tens of thousands of next-token predictions made by large transformer-based models such as GPT-2.
CrypTen: Secure Multi-Party Computation Meets Machine Learning
Sep 02, 2021Secure multi-party computation (MPC) allows parties to perform computations on data while keeping that data private. This capability has great potential for machine-learning applications: it facilitates training of machine-learning models on private data sets owned by different parties, evaluation of one party's private model using another party's private data, etc. Although a range of studies implement machine-learning models via secure MPC, such implementations are not yet mainstream. Adoption of secure MPC is hampered by the absence of flexible software frameworks that "speak the language" of machine-learning researchers and engineers. To foster adoption of secure MPC in machine learning, we present CrypTen: a software framework that exposes popular secure MPC primitives via abstractions that are common in modern machine-learning frameworks, such as tensor computations, automatic differentiation, and modular neural networks. This paper describes the design of CrypTen and measure its performance on state-of-the-art models for text classification, speech recognition, and image classification. Our benchmarks show that CrypTen's GPU support and high-performance communication between (an arbitrary number of) parties allows it to perform efficient private evaluation of modern machine-learning models under a semi-honest threat model. For example, two parties using CrypTen can securely predict phonemes in speech recordings using Wav2Letter faster than real-time. We hope that CrypTen will spur adoption of secure MPC in the machine-learning community.
Fixes That Fail: Self-Defeating Improvements in Machine-Learning Systems
Mar 22, 2021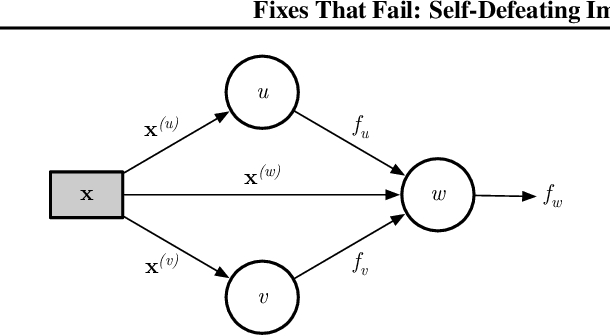
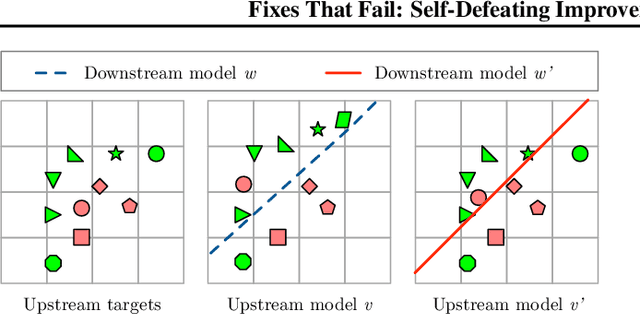
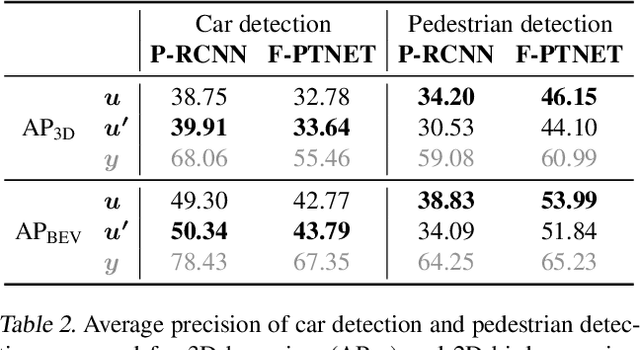
Machine-learning systems such as self-driving cars or virtual assistants are composed of a large number of machine-learning models that recognize image content, transcribe speech, analyze natural language, infer preferences, rank options, etc. These systems can be represented as directed acyclic graphs in which each vertex is a model, and models feed each other information over the edges. Oftentimes, the models are developed and trained independently, which raises an obvious concern: Can improving a machine-learning model make the overall system worse? We answer this question affirmatively by showing that improving a model can deteriorate the performance of downstream models, even after those downstream models are retrained. Such self-defeating improvements are the result of entanglement between the models. We identify different types of entanglement and demonstrate via simple experiments how they can produce self-defeating improvements. We also show that self-defeating improvements emerge in a realistic stereo-based object detection system.
Measuring Data Leakage in Machine-Learning Models with Fisher Information
Feb 23, 2021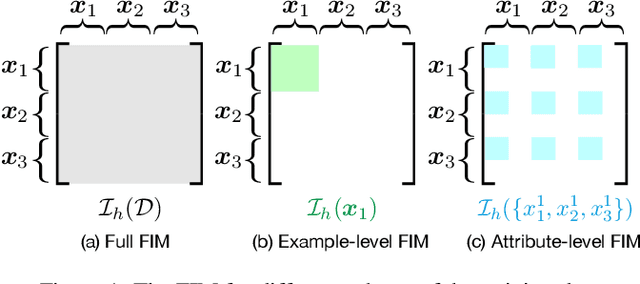
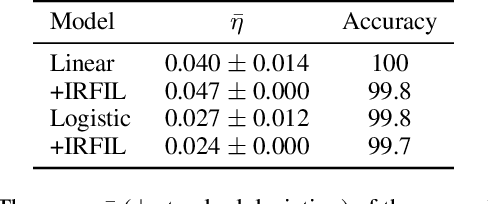
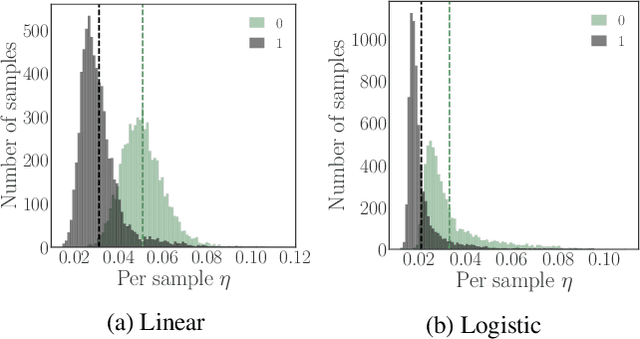

Machine-learning models contain information about the data they were trained on. This information leaks either through the model itself or through predictions made by the model. Consequently, when the training data contains sensitive attributes, assessing the amount of information leakage is paramount. We propose a method to quantify this leakage using the Fisher information of the model about the data. Unlike the worst-case a priori guarantees of differential privacy, Fisher information loss measures leakage with respect to specific examples, attributes, or sub-populations within the dataset. We motivate Fisher information loss through the Cram\'{e}r-Rao bound and delineate the implied threat model. We provide efficient methods to compute Fisher information loss for output-perturbed generalized linear models. Finally, we empirically validate Fisher information loss as a useful measure of information leakage.
Making Paper Reviewing Robust to Bid Manipulation Attacks
Feb 22, 2021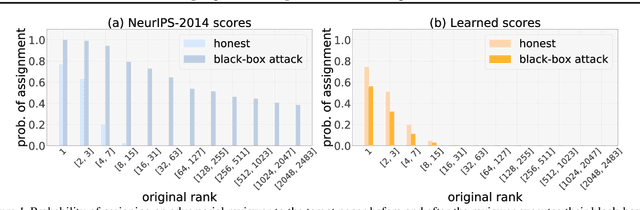
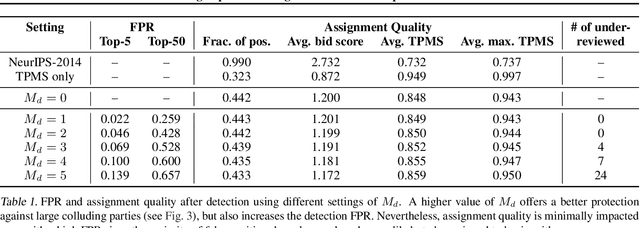
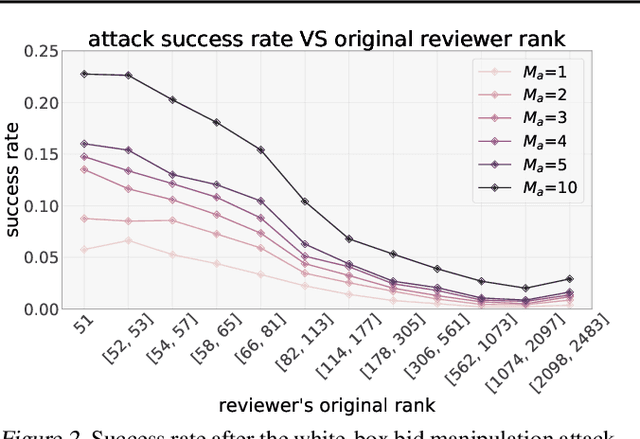
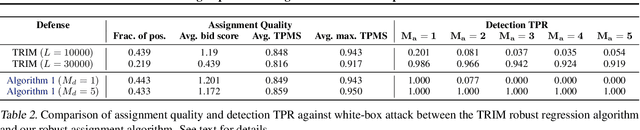
Most computer science conferences rely on paper bidding to assign reviewers to papers. Although paper bidding enables high-quality assignments in days of unprecedented submission numbers, it also opens the door for dishonest reviewers to adversarially influence paper reviewing assignments. Anecdotal evidence suggests that some reviewers bid on papers by "friends" or colluding authors, even though these papers are outside their area of expertise, and recommend them for acceptance without considering the merit of the work. In this paper, we study the efficacy of such bid manipulation attacks and find that, indeed, they can jeopardize the integrity of the review process. We develop a novel approach for paper bidding and assignment that is much more robust against such attacks. We show empirically that our approach provides robustness even when dishonest reviewers collude, have full knowledge of the assignment system's internal workings, and have access to the system's inputs. In addition to being more robust, the quality of our paper review assignments is comparable to that of current, non-robust assignment approaches.
Physical Reasoning Using Dynamics-Aware Models
Feb 20, 2021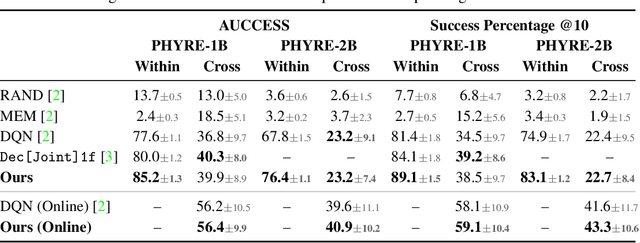
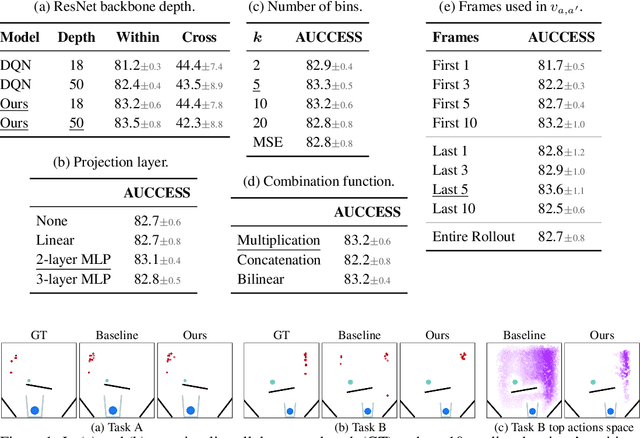
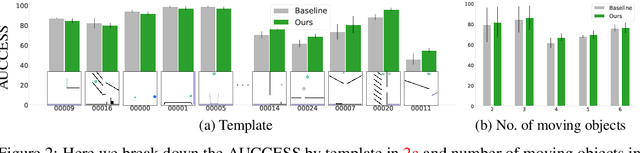
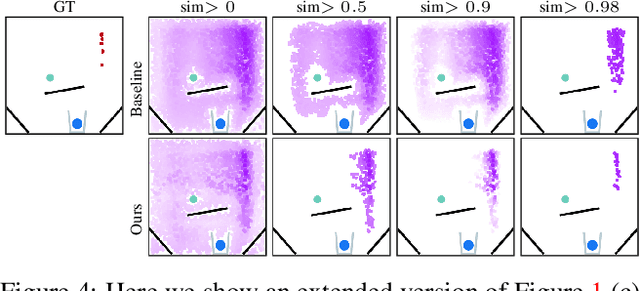
A common approach to solving physical-reasoning tasks is to train a value learner on example tasks. A limitation of such an approach is it requires learning about object dynamics solely from reward values assigned to the final state of a rollout of the environment. This study aims to address this limitation by augmenting the reward value with additional supervisory signals about object dynamics. Specifically,we define a distance measure between the trajectory of two target objects, and use this distance measure to characterize the similarity of two environment rollouts.We train the model to correctly rank rollouts according to this measure in addition to predicting the correct reward. Empirically, we find that this approach leads to substantial performance improvements on the PHYRE benchmark for physical reasoning: our approach obtains a new state-of-the-art on that benchmark.
Data Appraisal Without Data Sharing
Dec 11, 2020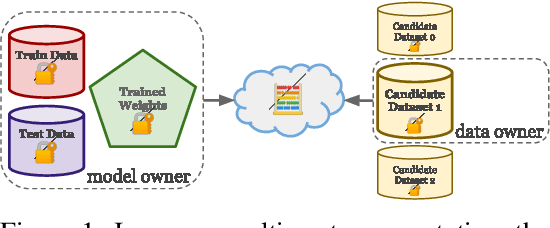

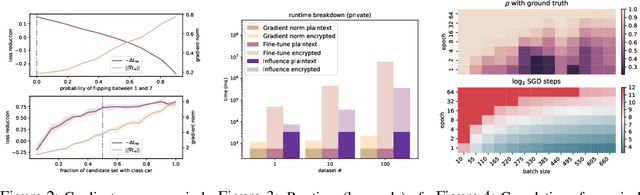
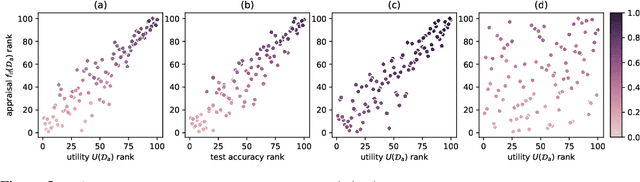
One of the most effective approaches to improving the performance of a machine-learning model is to acquire additional training data. To do so, a model owner may seek to acquire relevant training data from a data owner. Before procuring the data, the model owner needs to appraise the data. However, the data owner generally does not want to share the data until after an agreement is reached. The resulting Catch-22 prevents efficient data markets from forming. To address this problem, we develop data appraisal methods that do not require data sharing by using secure multi-party computation. Specifically, we study methods that: (1) compute parameter gradient norms, (2) perform model fine-tuning, and (3) compute influence functions. Our experiments show that influence functions provide an appealing trade-off between high-quality appraisal and required computation.
The Trade-Offs of Private Prediction
Jul 09, 2020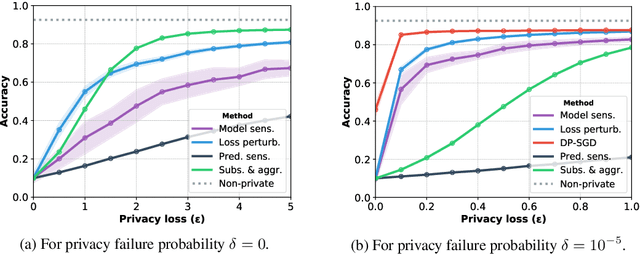
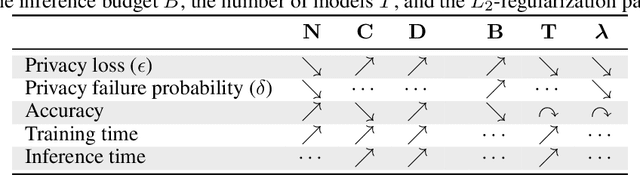
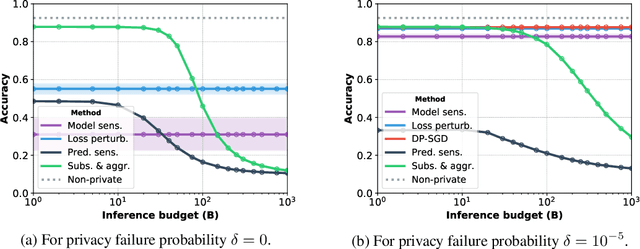
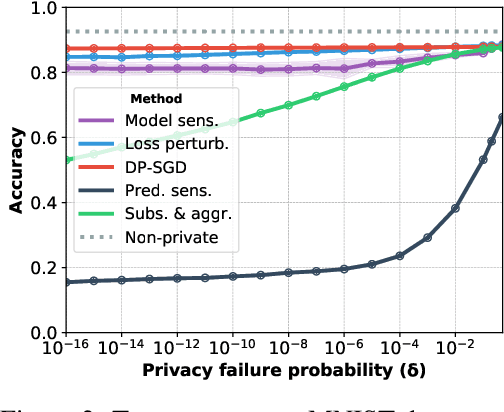
Machine learning models leak information about their training data every time they reveal a prediction. This is problematic when the training data needs to remain private. Private prediction methods limit how much information about the training data is leaked by each prediction. Private prediction can also be achieved using models that are trained by private training methods. In private prediction, both private training and private prediction methods exhibit trade-offs between privacy, privacy failure probability, amount of training data, and inference budget. Although these trade-offs are theoretically well-understood, they have hardly been studied empirically. This paper presents the first empirical study into the trade-offs of private prediction. Our study sheds light on which methods are best suited for which learning setting. Perhaps surprisingly, we find private training methods outperform private prediction methods in a wide range of private prediction settings.
Forward Prediction for Physical Reasoning
Jun 18, 2020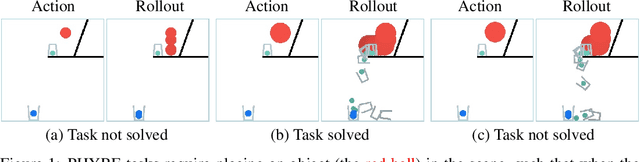

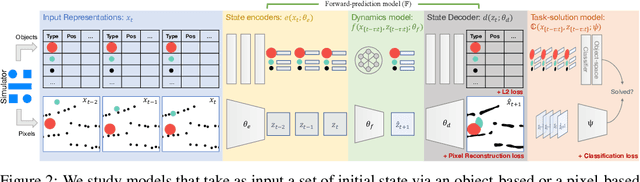
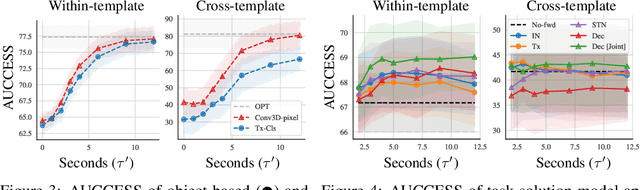
Physical reasoning requires forward prediction: the ability to forecast what will happen next given some initial world state. We study the performance of state-of-the-art forward-prediction models in complex physical-reasoning tasks. We do so by incorporating models that operate on object or pixel-based representations of the world, into simple physical-reasoning agents. We find that forward-prediction models improve the performance of physical-reasoning agents, particularly on complex tasks that involve many objects. However, we also find that these improvements are contingent on the training tasks being similar to the test tasks, and that generalization to different tasks is more challenging. Surprisingly, we observe that forward predictors with better pixel accuracy do not necessarily lead to better physical-reasoning performance. Nevertheless, our best models set a new state-of-the-art on the PHYRE benchmark for physical reasoning.