 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent Factored Generation: Unleashing the Diversity in Your Language Model
Jun 11, 2025Obtaining multiple meaningfully diverse, high quality samples from Large Language Models for a fixed prompt remains an open challenge. Current methods for increasing diversity often only operate at the token-level, paraphrasing the same response. This is problematic because it leads to poor exploration on reasoning problems and to unengaging, repetitive conversational agents. To address this we propose Intent Factored Generation (IFG), factorising the sampling process into two stages. First, we sample a semantically dense intent, e.g., a summary or keywords. Second, we sample the final response conditioning on both the original prompt and the intent from the first stage. This allows us to use a higher temperature during the intent step to promote conceptual diversity, and a lower temperature during the final generation to ensure the outputs are coherent and self-consistent. Additionally, we find that prompting the model to explicitly state its intent for each step of the chain-of-thought before generating the step is beneficial for reasoning tasks. We demonstrate our method's effectiveness across a diverse set of tasks. We show this method improves both pass@k and Reinforcement Learning from Verifier Feedback on maths and code tasks. For instruction-tuning, we combine IFG with Direct Preference Optimisation to increase conversational diversity without sacrificing reward. Finally, we achieve higher diversity while maintaining the quality of generations on a general language modelling task, using a new dataset of reader comments and news articles that we collect and open-source. In summary, we present a simple method of increasing the sample diversity of LLMs while maintaining performance. This method can be implemented by changing the prompt and varying the temperature during generation, making it easy to integrate into many algorithms for gains across various applications.
STUDY: Socially Aware Temporally Casual Decoder Recommender Systems
Jun 02, 2023With the overwhelming amount of data available both on and offline today, recommender systems have become much needed to help users find items tailored to their interests. When social network information exists there are methods that utilize this information to make better recommendations, however the methods are often clunky with complex architectures and training procedures. Furthermore many of the existing methods utilize graph neural networks which are notoriously difficult to train. To address this, we propose Socially-aware Temporally caUsal Decoder recommender sYstems (STUDY). STUDY does joint inference over groups of users who are adjacent in the social network graph using a single forward pass of a modified transformer decoder network. We test our method in a school-based educational content setting, using classroom structure to define social networks. Our method outperforms both social and sequential methods while maintaining the design simplicity of a single homogeneous network that models all interactions in the data. We also carry out ablation studies to understand the drivers of our performance gains and find that our model depends on leveraging a social network structure that effectively models the similarities in user behavior.
A Self-Supervised Auxiliary Loss for Deep RL in Partially Observable Settings
Apr 17, 2021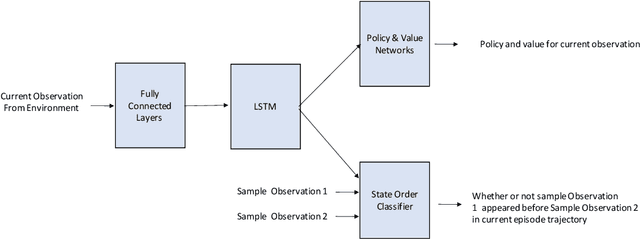


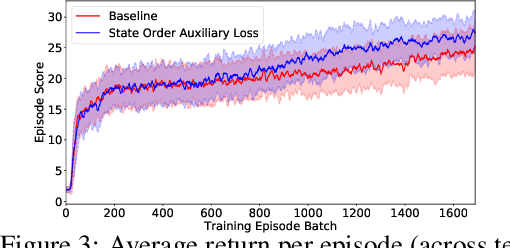
In this work we explore an auxiliary loss useful for reinforcement learning in environments where strong performing agents are required to be able to navigate a spatial environment. The auxiliary loss proposed is to minimize the classification error of a neural network classifier that predicts whether or not a pair of states sampled from the agents current episode trajectory are in order. The classifier takes as input a pair of states as well as the agent's memory. The motivation for this auxiliary loss is that there is a strong correlation with which of a pair of states is more recent in the agents episode trajectory and which of the two states is spatially closer to the agent. Our hypothesis is that learning features to answer this question encourages the agent to learn and internalize in memory representations of states that facilitate spatial reasoning. We tested this auxiliary loss on a navigation task in a gridworld and achieved 9.6% increase in accumulative episode reward compared to a strong baseline approach.
Physical Reasoning Using Dynamics-Aware Models
Feb 20, 2021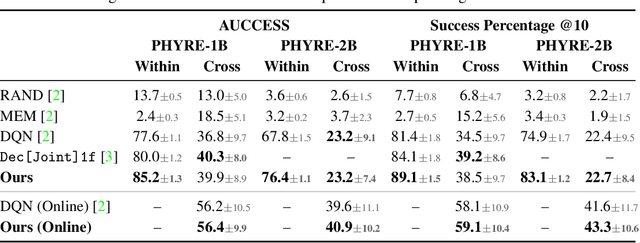
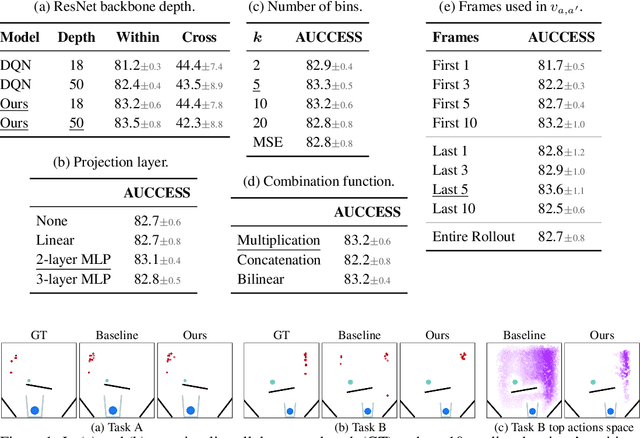
A common approach to solving physical-reasoning tasks is to train a value learner on example tasks. A limitation of such an approach is it requires learning about object dynamics solely from reward values assigned to the final state of a rollout of the environment. This study aims to address this limitation by augmenting the reward value with additional supervisory signals about object dynamics. Specifically,we define a distance measure between the trajectory of two target objects, and use this distance measure to characterize the similarity of two environment rollouts.We train the model to correctly rank rollouts according to this measure in addition to predicting the correct reward. Empirically, we find that this approach leads to substantial performance improvements on the PHYRE benchmark for physical reasoning: our approach obtains a new state-of-the-art on that benchmark.