 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Pose Estimation for Fine-Grained Object Categories
Jun 13, 2018
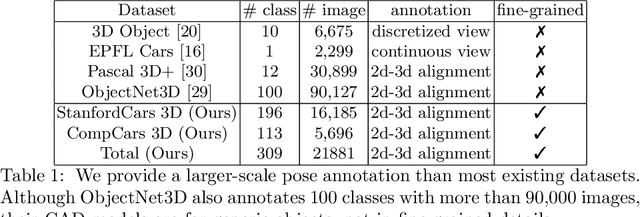

Existing object pose estimation datasets are related to generic object types and there is so far no dataset for fine-grained object categories. In this work, we introduce a new large dataset to benchmark pose estimation for fine-grained objects, thanks to the availability of both 2D and 3D fine-grained data recently. Specifically, we augment two popular fine-grained recognition datasets (StanfordCars and CompCars) by finding a fine-grained 3D CAD model for each sub-category and manually annotating each object in images with 3D pose. We show that, with enough training data, a full perspective model with continuous parameters can be estimated using 2D appearance information alone. We achieve this via a framework based on Faster/Mask R-CNN. This goes beyond previous works on category-level pose estimation, which only estimate discrete/continuous viewpoint angles or recover rotation matrices often with the help of key points. Furthermore, with fine-grained 3D models available, we incorporate a novel 3D representation named as location field into the CNN-based pose estimation framework to further improve the performance.
VITON: An Image-based Virtual Try-on Network
Jun 12, 2018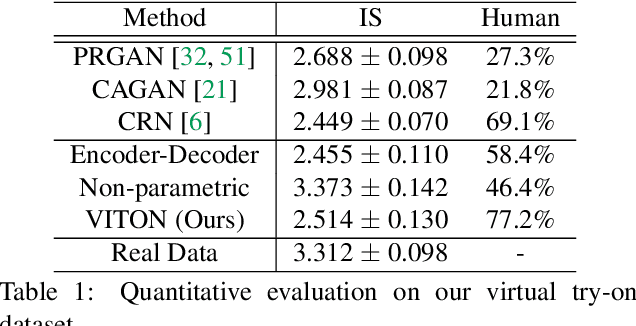
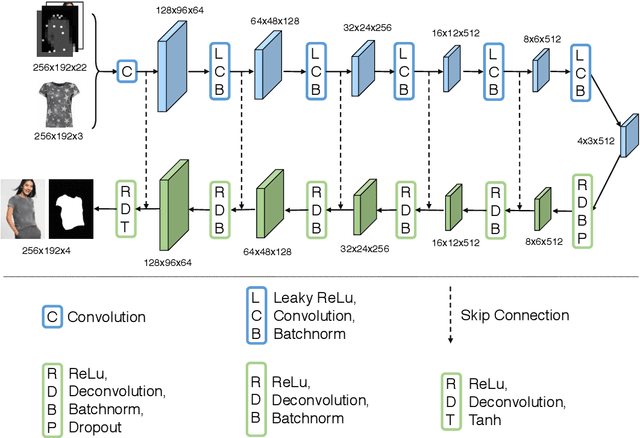


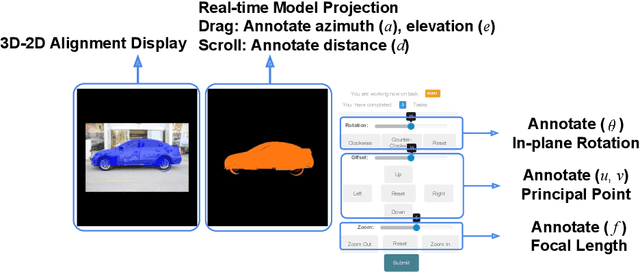
We present an image-based VIirtual Try-On Network (VITON) without using 3D information in any form, which seamlessly transfers a desired clothing item onto the corresponding region of a person using a coarse-to-fine strategy. Conditioned upon a new clothing-agnostic yet descriptive person representation, our framework first generates a coarse synthesized image with the target clothing item overlaid on that same person in the same pose. We further enhance the initial blurry clothing area with a refinement network. The network is trained to learn how much detail to utilize from the target clothing item, and where to apply to the person in order to synthesize a photo-realistic image in which the target item deforms naturally with clear visual patterns. Experiments on our newly collected Zalando dataset demonstrate its promise in the image-based virtual try-on task over state-of-the-art generative models.
Learning a Discriminative Filter Bank within a CNN for Fine-grained Recognition
Jun 12, 2018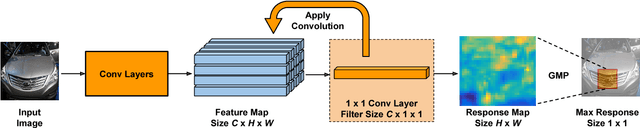
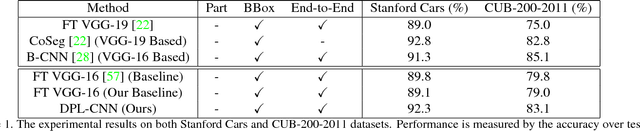
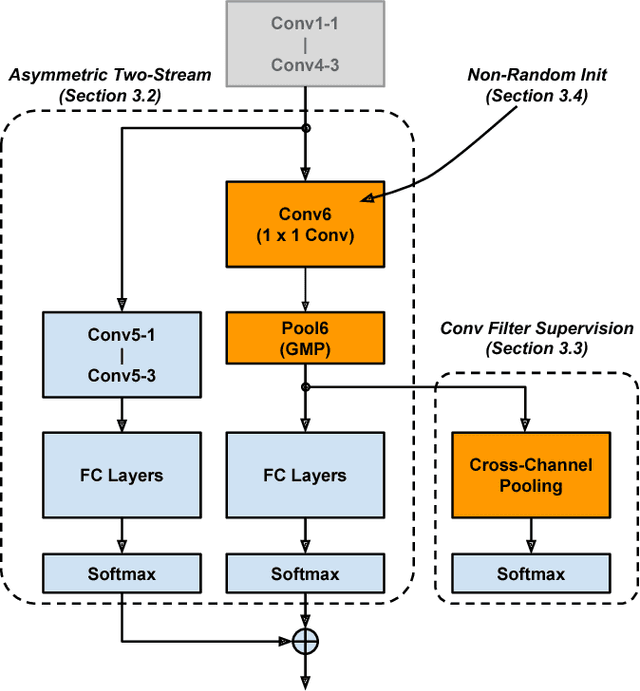
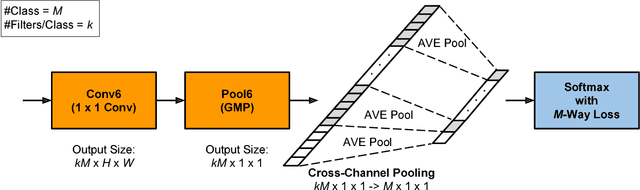
Compared to earlier multistage frameworks using CNN features, recent end-to-end deep approaches for fine-grained recognition essentially enhance the mid-level learning capability of CNNs. Previous approaches achieve this by introducing an auxiliary network to infuse localization information into the main classification network, or a sophisticated feature encoding method to capture higher order feature statistics. We show that mid-level representation learning can be enhanced within the CNN framework, by learning a bank of convolutional filters that capture class-specific discriminative patches without extra part or bounding box annotations. Such a filter bank is well structured, properly initialized and discriminatively learned through a novel asymmetric multi-stream architecture with convolutional filter supervision and a non-random layer initialization. Experimental results show that our approach achieves state-of-the-art on three publicly available fine-grained recognition datasets (CUB-200-2011, Stanford Cars and FGVC-Aircraft). Ablation studies and visualizations are provided to understand our approach.
An Analysis of Scale Invariance in Object Detection - SNIP
May 25, 2018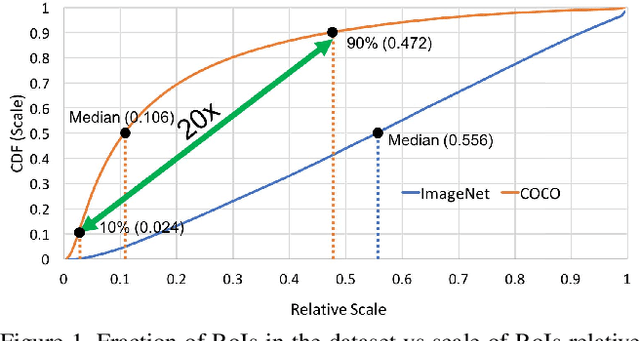

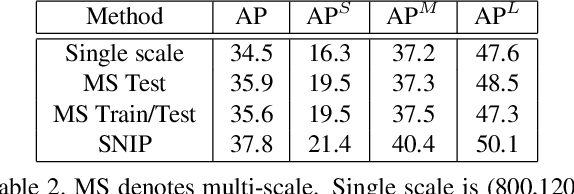
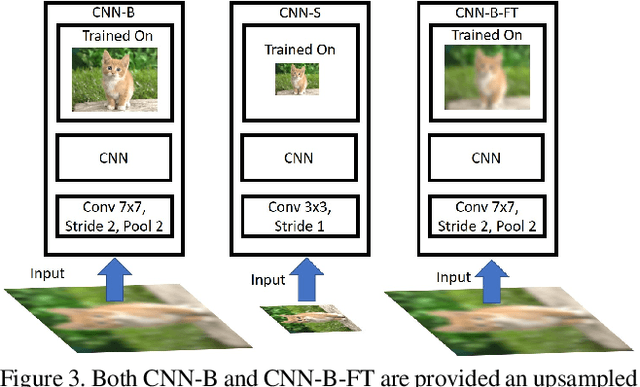
An analysis of different techniques for recognizing and detecting objects under extreme scale variation is presented. Scale specific and scale invariant design of detectors are compared by training them with different configurations of input data. By evaluating the performance of different network architectures for classifying small objects on ImageNet, we show that CNNs are not robust to changes in scale. Based on this analysis, we propose to train and test detectors on the same scales of an image-pyramid. Since small and large objects are difficult to recognize at smaller and larger scales respectively, we present a novel training scheme called Scale Normalization for Image Pyramids (SNIP) which selectively back-propagates the gradients of object instances of different sizes as a function of the image scale. On the COCO dataset, our single model performance is 45.7% and an ensemble of 3 networks obtains an mAP of 48.3%. We use off-the-shelf ImageNet-1000 pre-trained models and only train with bounding box supervision. Our submission won the Best Student Entry in the COCO 2017 challenge. Code will be made available at \url{http://bit.ly/2yXVg4c}.
Learning Rich Features for Image Manipulation Detection
May 13, 2018

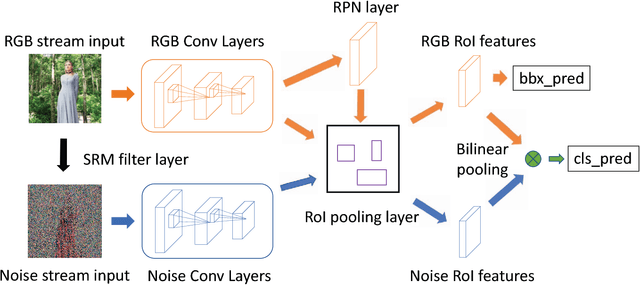

Image manipulation detection is different from traditional semantic object detection because it pays more attention to tampering artifacts than to image content, which suggests that richer features need to be learned. We propose a two-stream Faster R-CNN network and train it endto- end to detect the tampered regions given a manipulated image. One of the two streams is an RGB stream whose purpose is to extract features from the RGB image input to find tampering artifacts like strong contrast difference, unnatural tampered boundaries, and so on. The other is a noise stream that leverages the noise features extracted from a steganalysis rich model filter layer to discover the noise inconsistency between authentic and tampered regions. We then fuse features from the two streams through a bilinear pooling layer to further incorporate spatial co-occurrence of these two modalities. Experiments on four standard image manipulation datasets demonstrate that our two-stream framework outperforms each individual stream, and also achieves state-of-the-art performance compared to alternative methods with robustness to resizing and compression.
DCAN: Dual Channel-wise Alignment Networks for Unsupervised Scene Adaptation
Apr 16, 2018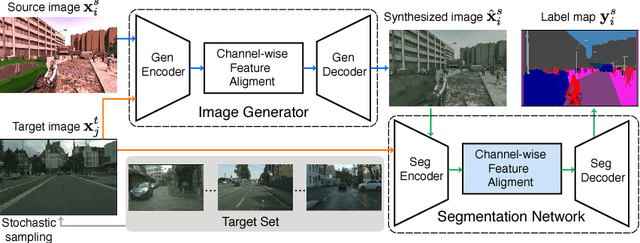
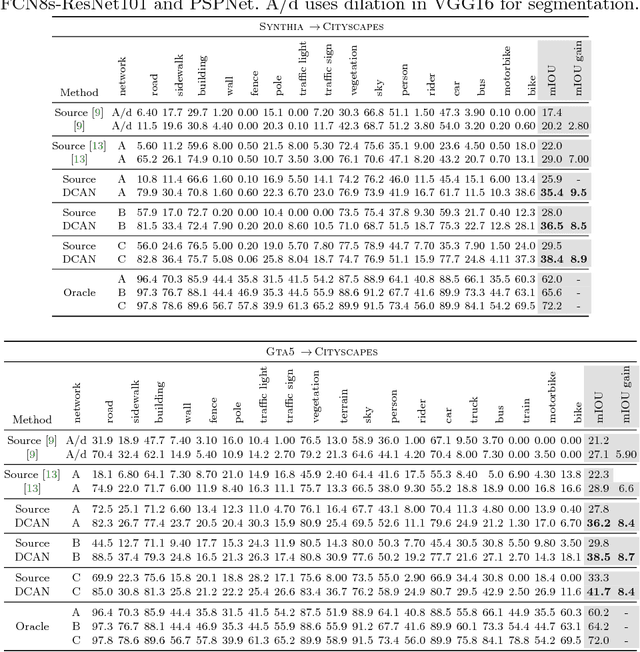

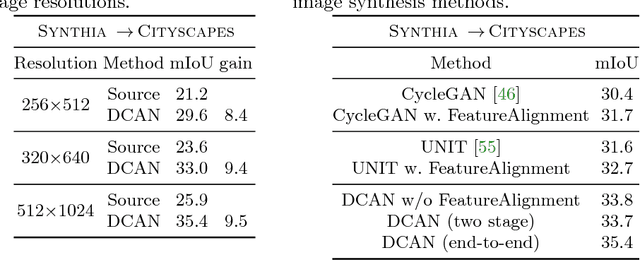
Harvesting dense pixel-level annotations to train deep neural networks for semantic segmentation is extremely expensive and unwieldy at scale. While learning from synthetic data where labels are readily available sounds promising, performance degrades significantly when testing on novel realistic data due to domain discrepancies. We present Dual Channel-wise Alignment Networks (DCAN), a simple yet effective approach to reduce domain shift at both pixel-level and feature-level. Exploring statistics in each channel of CNN feature maps, our framework performs channel-wise feature alignment, which preserves spatial structures and semantic information, in both an image generator and a segmentation network. In particular, given an image from the source domain and unlabeled samples from the target domain, the generator synthesizes new images on-the-fly to resemble samples from the target domain in appearance and the segmentation network further refines high-level features before predicting semantic maps, both of which leverage feature statistics of sampled images from the target domain. Unlike much recent and concurrent work relying on adversarial training, our framework is lightweight and easy to train. Extensive experiments on adapting models trained on synthetic segmentation benchmarks to real urban scenes demonstrate the effectiveness of the proposed framework.
BlockDrop: Dynamic Inference Paths in Residual Networks
Apr 12, 2018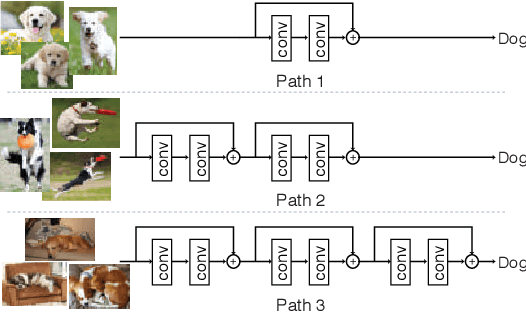
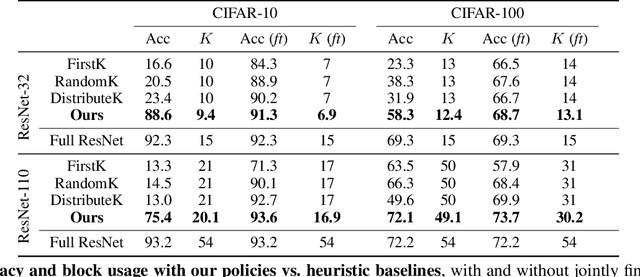
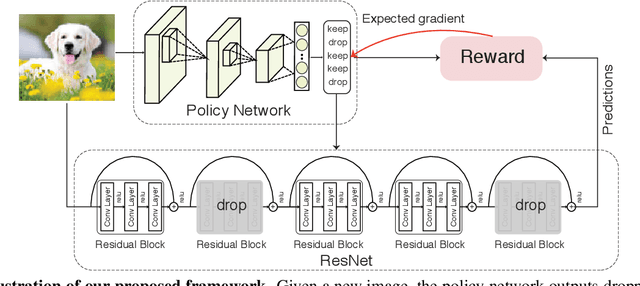
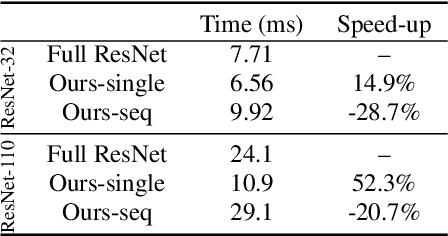
Very deep convolutional neural networks offer excellent recognition results, yet their computational expense limits their impact for many real-world applications. We introduce BlockDrop, an approach that learns to dynamically choose which layers of a deep network to execute during inference so as to best reduce total computation without degrading prediction accuracy. Exploiting the robustness of Residual Networks (ResNets) to layer dropping, our framework selects on-the-fly which residual blocks to evaluate for a given novel image. In particular, given a pretrained ResNet, we train a policy network in an associative reinforcement learning setting for the dual reward of utilizing a minimal number of blocks while preserving recognition accuracy. We conduct extensive experiments on CIFAR and ImageNet. The results provide strong quantitative and qualitative evidence that these learned policies not only accelerate inference but also encode meaningful visual information. Built upon a ResNet-101 model, our method achieves a speedup of 20\% on average, going as high as 36\% for some images, while maintaining the same 76.4\% top-1 accuracy on ImageNet.
Representing Videos based on Scene Layouts for Recognizing Agent-in-Place Actions
Apr 04, 2018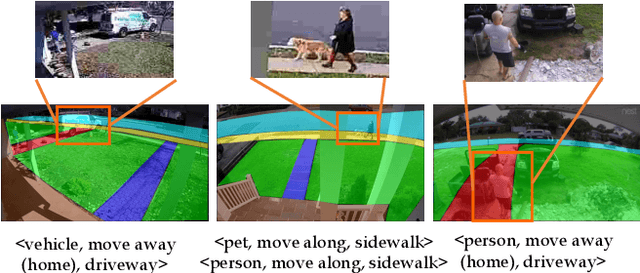
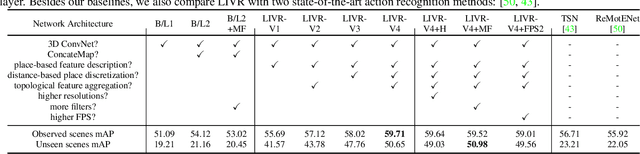
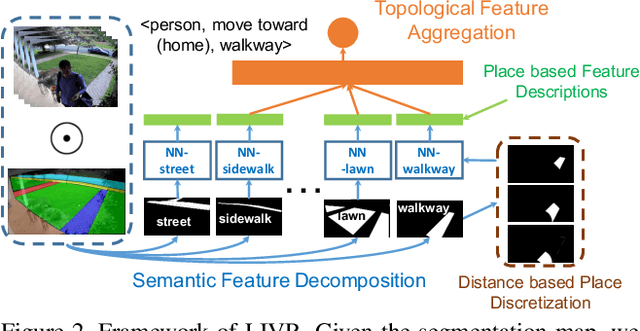
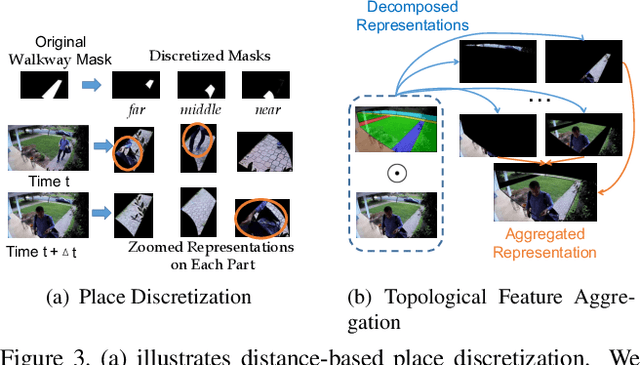
We address the recognition of agent-in-place actions, which are associated with agents who perform them and places where they occur, in the context of outdoor home surveillance. We introduce a representation of the geometry and topology of scene layouts so that a network can generalize from the layouts observed in the training set to unseen layouts in the test set. This Layout-Induced Video Representation (LIVR) abstracts away low-level appearance variance and encodes geometric and topological relationships of places in a specific scene layout. LIVR partitions the semantic features of a video clip into different places to force the network to learn place-based feature descriptions; to predict the confidence of each action, LIVR aggregates features from the place associated with an action and its adjacent places on the scene layout. We introduce the Agent-in-Place Action dataset to show that our method allows neural network models to generalize significantly better to unseen scenes.
Two-Stream Neural Networks for Tampered Face Detection
Mar 29, 2018

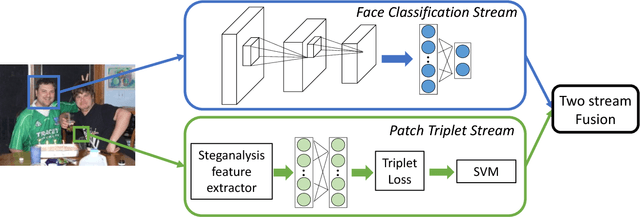
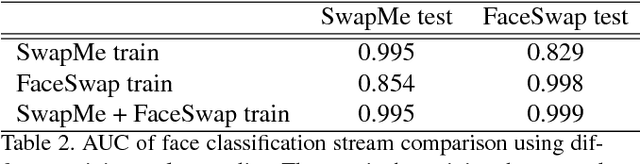
We propose a two-stream network for face tampering detection. We train GoogLeNet to detect tampering artifacts in a face classification stream, and train a patch based triplet network to leverage features capturing local noise residuals and camera characteristics as a second stream. In addition, we use two different online face swapping applications to create a new dataset that consists of 2010 tampered images, each of which contains a tampered face. We evaluate the proposed two-stream network on our newly collected dataset. Experimental results demonstrate the effectiveness of our method.
Dynamic Zoom-in Network for Fast Object Detection in Large Images
Mar 27, 2018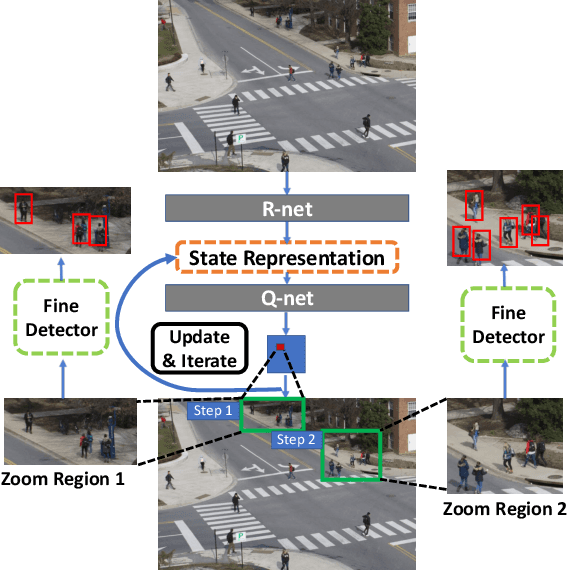
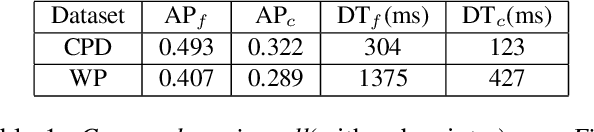
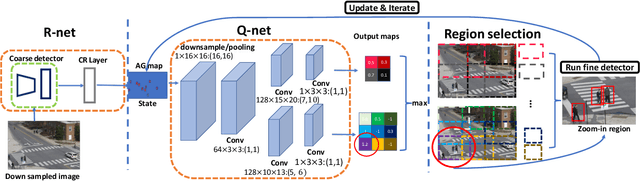
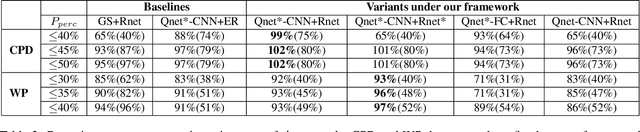
We introduce a generic framework that reduces the computational cost of object detection while retaining accuracy for scenarios where objects with varied sizes appear in high resolution images. Detection progresses in a coarse-to-fine manner, first on a down-sampled version of the image and then on a sequence of higher resolution regions identified as likely to improve the detection accuracy. Built upon reinforcement learning, our approach consists of a model (R-net) that uses coarse detection results to predict the potential accuracy gain for analyzing a region at a higher resolution and another model (Q-net) that sequentially selects regions to zoom in. Experiments on the Caltech Pedestrians dataset show that our approach reduces the number of processed pixels by over 50% without a drop in detection accuracy. The merits of our approach become more significant on a high resolution test set collected from YFCC100M dataset, where our approach maintains high detection performance while reducing the number of processed pixels by about 70% and the detection time by over 50%.