 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImLPR: Image-based LiDAR Place Recognition using Vision Foundation Models
May 23, 2025LiDAR Place Recognition (LPR) is a key component in robotic localization, enabling robots to align current scans with prior maps of their environment. While Visual Place Recognition (VPR) has embraced Vision Foundation Models (VFMs) to enhance descriptor robustness, LPR has relied on task-specific models with limited use of pre-trained foundation-level knowledge. This is due to the lack of 3D foundation models and the challenges of using VFM with LiDAR point clouds. To tackle this, we introduce ImLPR, a novel pipeline that employs a pre-trained DINOv2 VFM to generate rich descriptors for LPR. To our knowledge, ImLPR is the first method to leverage a VFM to support LPR. ImLPR converts raw point clouds into Range Image Views (RIV) to leverage VFM in the LiDAR domain. It employs MultiConv adapters and Patch-InfoNCE loss for effective feature learning. We validate ImLPR using public datasets where it outperforms state-of-the-art (SOTA) methods in intra-session and inter-session LPR with top Recall@1 and F1 scores across various LiDARs. We also demonstrate that RIV outperforms Bird's-Eye-View (BEV) as a representation choice for adapting LiDAR for VFM. We release ImLPR as open source for the robotics community.
Boxi: Design Decisions in the Context of Algorithmic Performance for Robotics
Apr 25, 2025Achieving robust autonomy in mobile robots operating in complex and unstructured environments requires a multimodal sensor suite capable of capturing diverse and complementary information. However, designing such a sensor suite involves multiple critical design decisions, such as sensor selection, component placement, thermal and power limitations, compute requirements, networking, synchronization, and calibration. While the importance of these key aspects is widely recognized, they are often overlooked in academia or retained as proprietary knowledge within large corporations. To improve this situation, we present Boxi, a tightly integrated sensor payload that enables robust autonomy of robots in the wild. This paper discusses the impact of payload design decisions made to optimize algorithmic performance for downstream tasks, specifically focusing on state estimation and mapping. Boxi is equipped with a variety of sensors: two LiDARs, 10 RGB cameras including high-dynamic range, global shutter, and rolling shutter models, an RGB-D camera, 7 inertial measurement units (IMUs) of varying precision, and a dual antenna RTK GNSS system. Our analysis shows that time synchronization, calibration, and sensor modality have a crucial impact on the state estimation performance. We frame this analysis in the context of cost considerations and environment-specific challenges. We also present a mobile sensor suite `cookbook` to serve as a comprehensive guideline, highlighting generalizable key design considerations and lessons learned during the development of Boxi. Finally, we demonstrate the versatility of Boxi being used in a variety of applications in real-world scenarios, contributing to robust autonomy. More details and code: https://github.com/leggedrobotics/grand_tour_box
The Oxford Spires Dataset: Benchmarking Large-Scale LiDAR-Visual Localisation, Reconstruction and Radiance Field Methods
Nov 15, 2024



This paper introduces a large-scale multi-modal dataset captured in and around well-known landmarks in Oxford using a custom-built multi-sensor perception unit as well as a millimetre-accurate map from a Terrestrial LiDAR Scanner (TLS). The perception unit includes three synchronised global shutter colour cameras, an automotive 3D LiDAR scanner, and an inertial sensor - all precisely calibrated. We also establish benchmarks for tasks involving localisation, reconstruction, and novel-view synthesis, which enable the evaluation of Simultaneous Localisation and Mapping (SLAM) methods, Structure-from-Motion (SfM) and Multi-view Stereo (MVS) methods as well as radiance field methods such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting. To evaluate 3D reconstruction the TLS 3D models are used as ground truth. Localisation ground truth is computed by registering the mobile LiDAR scans to the TLS 3D models. Radiance field methods are evaluated not only with poses sampled from the input trajectory, but also from viewpoints that are from trajectories which are distant from the training poses. Our evaluation demonstrates a key limitation of state-of-the-art radiance field methods: we show that they tend to overfit to the training poses/images and do not generalise well to out-of-sequence poses. They also underperform in 3D reconstruction compared to MVS systems using the same visual inputs. Our dataset and benchmarks are intended to facilitate better integration of radiance field methods and SLAM systems. The raw and processed data, along with software for parsing and evaluation, can be accessed at https://dynamic.robots.ox.ac.uk/datasets/oxford-spires/.
SiLVR: Scalable Lidar-Visual Reconstruction with Neural Radiance Fields for Robotic Inspection
Mar 11, 2024



We present a neural-field-based large-scale reconstruction system that fuses lidar and vision data to generate high-quality reconstructions that are geometrically accurate and capture photo-realistic textures. This system adapts the state-of-the-art neural radiance field (NeRF) representation to also incorporate lidar data which adds strong geometric constraints on the depth and surface normals. We exploit the trajectory from a real-time lidar SLAM system to bootstrap a Structure-from-Motion (SfM) procedure to both significantly reduce the computation time and to provide metric scale which is crucial for lidar depth loss. We use submapping to scale the system to large-scale environments captured over long trajectories. We demonstrate the reconstruction system with data from a multi-camera, lidar sensor suite onboard a legged robot, hand-held while scanning building scenes for 600 metres, and onboard an aerial robot surveying a multi-storey mock disaster site-building. Website: https://ori-drs.github.io/projects/silvr/
Hilti-Oxford Dataset: A Millimetre-Accurate Benchmark for Simultaneous Localization and Mapping
Aug 21, 2022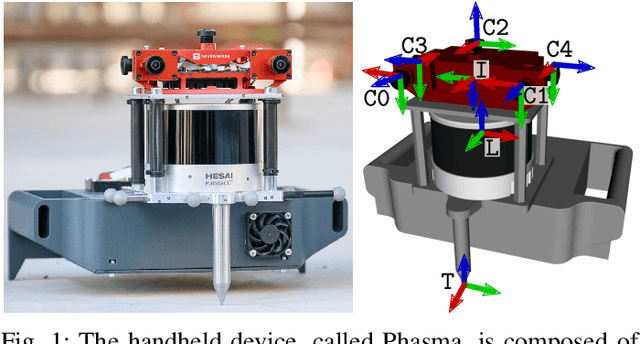



Simultaneous Localization and Mapping (SLAM) is being deployed in real-world applications, however many state-of-the-art solutions still struggle in many common scenarios. A key necessity in progressing SLAM research is the availability of high-quality datasets and fair and transparent benchmarking. To this end, we have created the Hilti-Oxford Dataset, to push state-of-the-art SLAM systems to their limits. The dataset has a variety of challenges ranging from sparse and regular construction sites to a 17th century neoclassical building with fine details and curved surfaces. To encourage multi-modal SLAM approaches, we designed a data collection platform featuring a lidar, five cameras, and an IMU (Inertial Measurement Unit). With the goal of benchmarking SLAM algorithms for tasks where accuracy and robustness are paramount, we implemented a novel ground truth collection method that enables our dataset to accurately measure SLAM pose errors with millimeter accuracy. To further ensure accuracy, the extrinsics of our platform were verified with a micrometer-accurate scanner, and temporal calibration was managed online using hardware time synchronization. The multi-modality and diversity of our dataset attracted a large field of academic and industrial researchers to enter the second edition of the Hilti SLAM challenge, which concluded in June 2022. The results of the challenge show that while the top three teams could achieve accuracy of 2cm or better for some sequences, the performance dropped off in more difficult sequences.