 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpart: An Imperceptible and Effective Label-Specific Backdoor Attack
Mar 18, 2024Backdoor attacks have been shown to impose severe threats to real security-critical scenarios. Although previous works can achieve high attack success rates, they either require access to victim models which may significantly reduce their threats in practice, or perform visually noticeable in stealthiness. Besides, there is still room to improve the attack success rates in the scenario that different poisoned samples may have different target labels (a.k.a., the all-to-all setting). In this study, we propose a novel imperceptible backdoor attack framework, named Impart, in the scenario where the attacker has no access to the victim model. Specifically, in order to enhance the attack capability of the all-to-all setting, we first propose a label-specific attack. Different from previous works which try to find an imperceptible pattern and add it to the source image as the poisoned image, we then propose to generate perturbations that align with the target label in the image feature by a surrogate model. In this way, the generated poisoned images are attached with knowledge about the target class, which significantly enhances the attack capability.
Revealing Vulnerabilities in Stable Diffusion via Targeted Attacks
Jan 16, 2024Recent developments in text-to-image models, particularly Stable Diffusion, have marked significant achievements in various applications. With these advancements, there are growing safety concerns about the vulnerability of the model that malicious entities exploit to generate targeted harmful images. However, the existing methods in the vulnerability of the model mainly evaluate the alignment between the prompt and generated images, but fall short in revealing the vulnerability associated with targeted image generation. In this study, we formulate the problem of targeted adversarial attack on Stable Diffusion and propose a framework to generate adversarial prompts. Specifically, we design a gradient-based embedding optimization method to craft reliable adversarial prompts that guide stable diffusion to generate specific images. Furthermore, after obtaining successful adversarial prompts, we reveal the mechanisms that cause the vulnerability of the model. Extensive experiments on two targeted attack tasks demonstrate the effectiveness of our method in targeted attacks. The code can be obtained in https://github.com/datar001/Revealing-Vulnerabilities-in-Stable-Diffusion-via-Targeted-Attacks.
T2IW: Joint Text to Image & Watermark Generation
Sep 07, 2023



Recent developments in text-conditioned image generative models have revolutionized the production of realistic results. Unfortunately, this has also led to an increase in privacy violations and the spread of false information, which requires the need for traceability, privacy protection, and other security measures. However, existing text-to-image paradigms lack the technical capabilities to link traceable messages with image generation. In this study, we introduce a novel task for the joint generation of text to image and watermark (T2IW). This T2IW scheme ensures minimal damage to image quality when generating a compound image by forcing the semantic feature and the watermark signal to be compatible in pixels. Additionally, by utilizing principles from Shannon information theory and non-cooperative game theory, we are able to separate the revealed image and the revealed watermark from the compound image. Furthermore, we strengthen the watermark robustness of our approach by subjecting the compound image to various post-processing attacks, with minimal pixel distortion observed in the revealed watermark. Extensive experiments have demonstrated remarkable achievements in image quality, watermark invisibility, and watermark robustness, supported by our proposed set of evaluation metrics.
IPProtect: protecting the intellectual property of visual datasets during data valuation
Dec 22, 2022



Data trading is essential to accelerate the development of data-driven machine learning pipelines. The central problem in data trading is to estimate the utility of a seller's dataset with respect to a given buyer's machine learning task, also known as data valuation. Typically, data valuation requires one or more participants to share their raw dataset with others, leading to potential risks of intellectual property (IP) violations. In this paper, we tackle the novel task of preemptively protecting the IP of datasets that need to be shared during data valuation. First, we identify and formalize two kinds of novel IP risks in visual datasets: data-item (image) IP and statistical (dataset) IP. Then, we propose a novel algorithm to convert the raw dataset into a sanitized version, that provides resistance to IP violations, while at the same time allowing accurate data valuation. The key idea is to limit the transfer of information from the raw dataset to the sanitized dataset, thereby protecting against potential intellectual property violations. Next, we analyze our method for the likely existence of a solution and immunity against reconstruction attacks. Finally, we conduct extensive experiments on three computer vision datasets demonstrating the advantages of our method in comparison to other baselines.
GlueFL: Reconciling Client Sampling and Model Masking for Bandwidth Efficient Federated Learning
Dec 03, 2022



Federated learning (FL) is an effective technique to directly involve edge devices in machine learning training while preserving client privacy. However, the substantial communication overhead of FL makes training challenging when edge devices have limited network bandwidth. Existing work to optimize FL bandwidth overlooks downstream transmission and does not account for FL client sampling. In this paper we propose GlueFL, a framework that incorporates new client sampling and model compression algorithms to mitigate low download bandwidths of FL clients. GlueFL prioritizes recently used clients and bounds the number of changed positions in compression masks in each round. Across three popular FL datasets and three state-of-the-art strategies, GlueFL reduces downstream client bandwidth by 27% on average and reduces training time by 29% on average.
Revealing Unfair Models by Mining Interpretable Evidence
Jul 12, 2022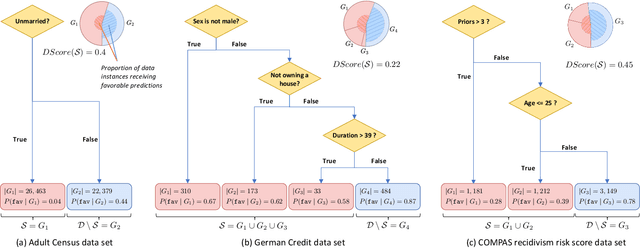
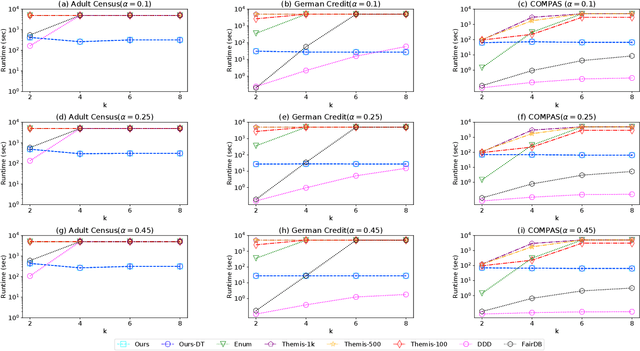
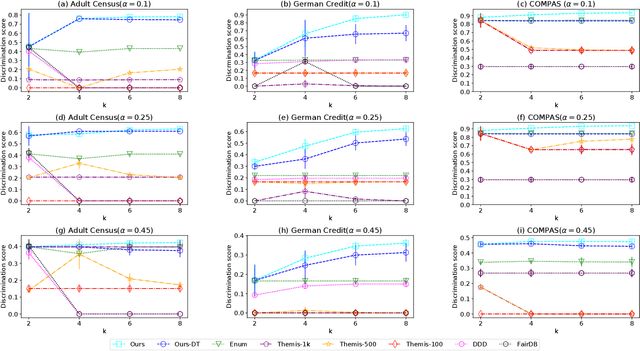
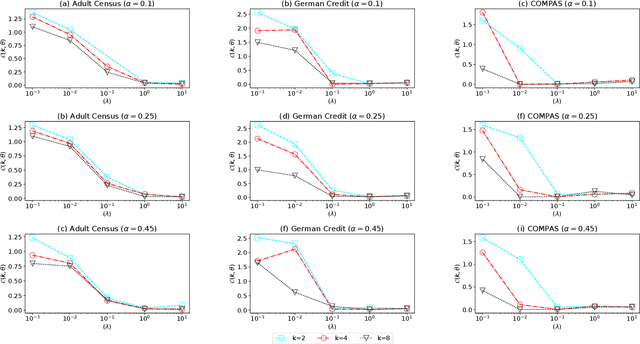
The popularity of machine learning has increased the risk of unfair models getting deployed in high-stake applications, such as justice system, drug/vaccination design, and medical diagnosis. Although there are effective methods to train fair models from scratch, how to automatically reveal and explain the unfairness of a trained model remains a challenging task. Revealing unfairness of machine learning models in interpretable fashion is a critical step towards fair and trustworthy AI. In this paper, we systematically tackle the novel task of revealing unfair models by mining interpretable evidence (RUMIE). The key idea is to find solid evidence in the form of a group of data instances discriminated most by the model. To make the evidence interpretable, we also find a set of human-understandable key attributes and decision rules that characterize the discriminated data instances and distinguish them from the other non-discriminated data. As demonstrated by extensive experiments on many real-world data sets, our method finds highly interpretable and solid evidence to effectively reveal the unfairness of trained models. Moreover, it is much more scalable than all of the baseline methods.
Intrinsic Bias Identification on Medical Image Datasets
Mar 29, 2022
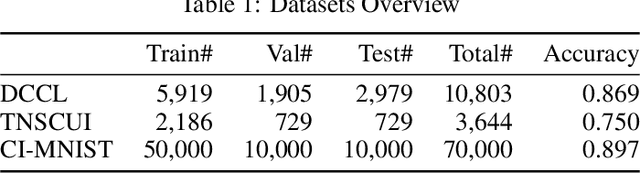
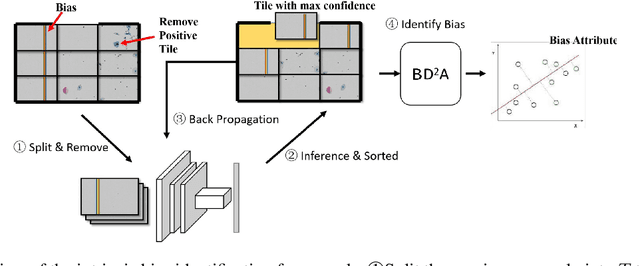
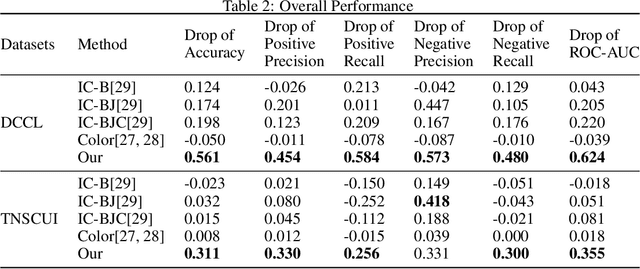
Machine learning based medical image analysis highly depends on datasets. Biases in the dataset can be learned by the model and degrade the generalizability of the applications. There are studies on debiased models. However, scientists and practitioners are difficult to identify implicit biases in the datasets, which causes lack of reliable unbias test datasets to valid models. To tackle this issue, we first define the data intrinsic bias attribute, and then propose a novel bias identification framework for medical image datasets. The framework contains two major components, KlotskiNet and Bias Discriminant Direction Analysis(bdda), where KlostkiNet is to build the mapping which makes backgrounds to distinguish positive and negative samples and bdda provides a theoretical solution on determining bias attributes. Experimental results on three datasets show the effectiveness of the bias attributes discovered by the framework.
Membership Privacy Protection for Image Translation Models via Adversarial Knowledge Distillation
Mar 10, 2022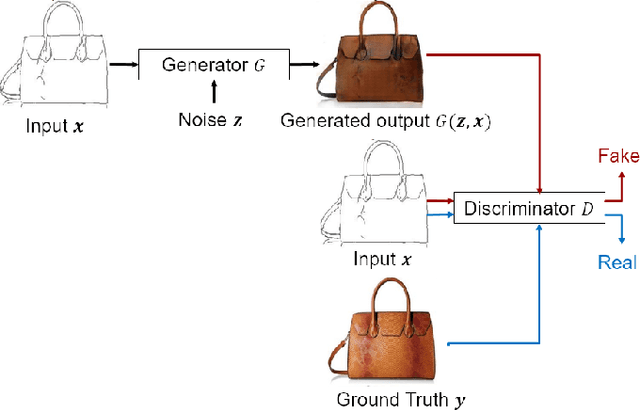
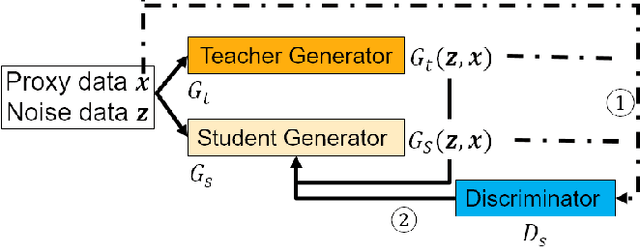
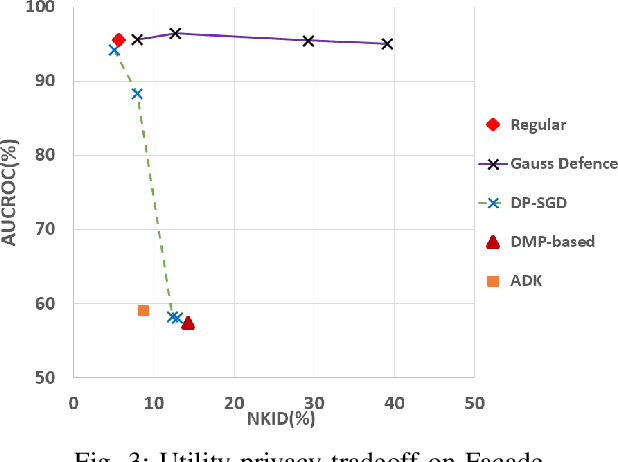
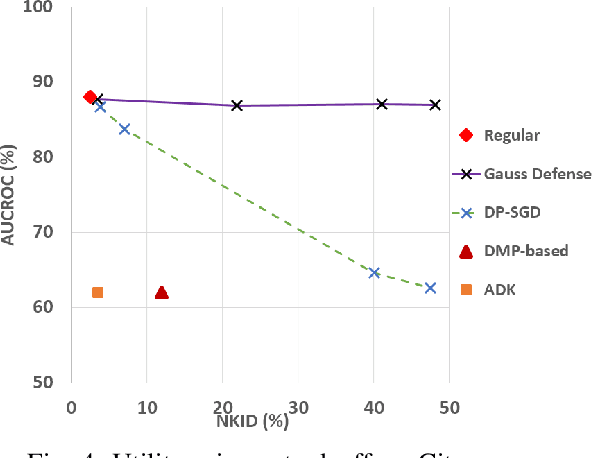
Image-to-image translation models are shown to be vulnerable to the Membership Inference Attack (MIA), in which the adversary's goal is to identify whether a sample is used to train the model or not. With daily increasing applications based on image-to-image translation models, it is crucial to protect the privacy of these models against MIAs. We propose adversarial knowledge distillation (AKD) as a defense method against MIAs for image-to-image translation models. The proposed method protects the privacy of the training samples by improving the generalizability of the model. We conduct experiments on the image-to-image translation models and show that AKD achieves the state-of-the-art utility-privacy tradeoff by reducing the attack performance up to 38.9% compared with the regular training model at the cost of a slight drop in the quality of the generated output images. The experimental results also indicate that the models trained by AKD generalize better than the regular training models. Furthermore, compared with existing defense methods, the results show that at the same privacy protection level, image translation models trained by AKD generate outputs with higher quality; while at the same quality of outputs, AKD enhances the privacy protection over 30%.
Targeted Data Poisoning Attack on News Recommendation System by Content Perturbation
Mar 10, 2022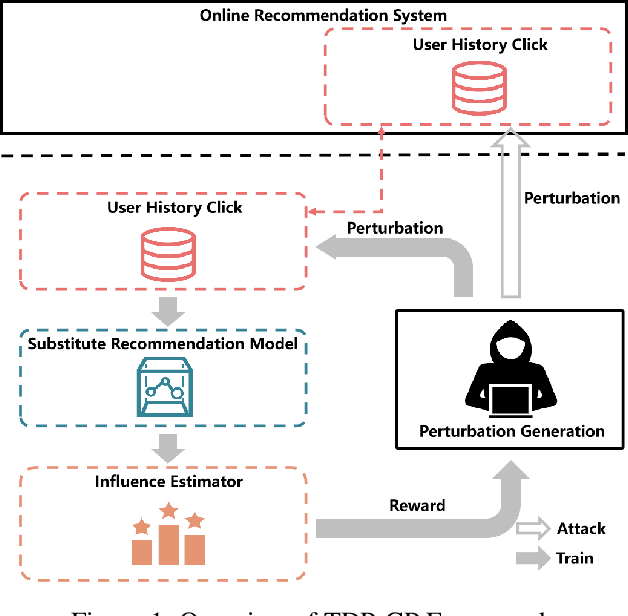
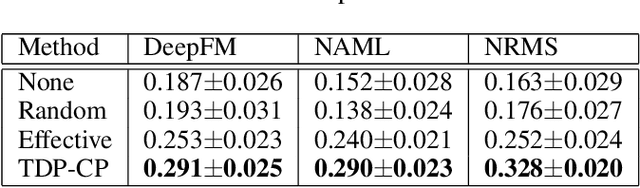
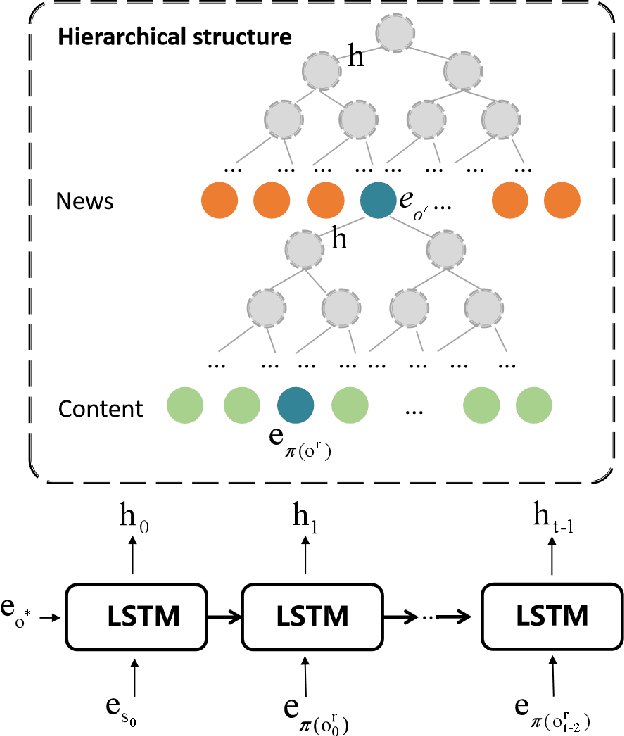
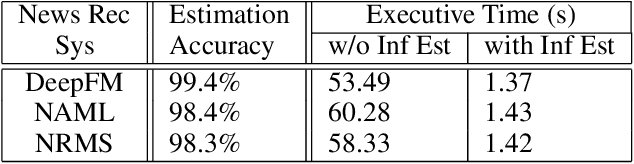
News Recommendation System(NRS) has become a fundamental technology to many online news services. Meanwhile, several studies show that recommendation systems(RS) are vulnerable to data poisoning attacks, and the attackers have the ability to mislead the system to perform as their desires. A widely studied attack approach, injecting fake users, can be applied on the NRS when the NRS is treated the same as the other systems whose items are fixed. However, in the NRS, as each item (i.e. news) is more informative, we propose a novel approach to poison the NRS, which is to perturb contents of some browsed news that results in the manipulation of the rank of the target news. Intuitively, an attack is useless if it is highly likely to be caught, i.e., exposed. To address this, we introduce a notion of the exposure risk and propose a novel problem of attacking a history news dataset by means of perturbations where the goal is to maximize the manipulation of the target news rank while keeping the risk of exposure under a given budget. We design a reinforcement learning framework, called TDP-CP, which contains a two-stage hierarchical model to reduce the searching space. Meanwhile, influence estimation is also applied to save the time on retraining the NRS for rewards. We test the performance of TDP-CP under three NRSs and on different target news. Our experiments show that TDP-CP can increase the rank of the target news successfully with a limited exposure budget.
Mining Minority-class Examples With Uncertainty Estimates
Dec 15, 2021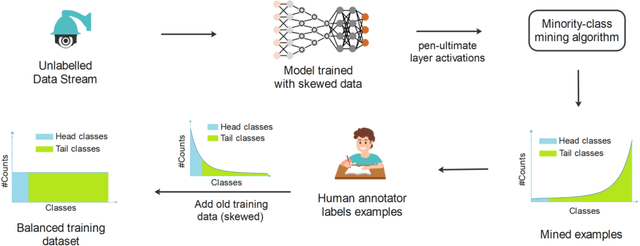

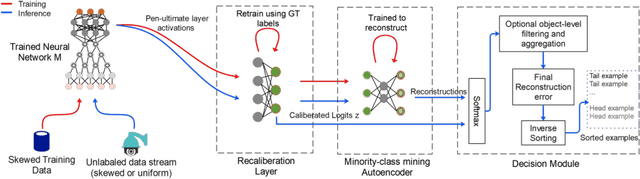
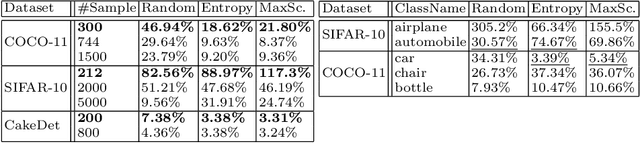
In the real world, the frequency of occurrence of objects is naturally skewed forming long-tail class distributions, which results in poor performance on the statistically rare classes. A promising solution is to mine tail-class examples to balance the training dataset. However, mining tail-class examples is a very challenging task. For instance, most of the otherwise successful uncertainty-based mining approaches struggle due to distortion of class probabilities resulting from skewness in data. In this work, we propose an effective, yet simple, approach to overcome these challenges. Our framework enhances the subdued tail-class activations and, thereafter, uses a one-class data-centric approach to effectively identify tail-class examples. We carry out an exhaustive evaluation of our framework on three datasets spanning over two computer vision tasks. Substantial improvements in the minority-class mining and fine-tuned model's performance strongly corroborate the value of our proposed solution.