 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Concepts Lie Within? Detecting and Suppressing Risky Content in Diffusion Transformers
May 11, 2026The rise of text-to-image (T2I) models has increasingly raised concerns regarding the generation of risky content, such as sexual, violent, and copyright-protected images, highlighting the need for effective safeguards within the models themselves. Although existing methods have been proposed to eliminate risky concepts from T2I models, they are primarily developed for earlier U-Net architectures, leaving the state-of-the-art Diffusion-Transformer-based T2I models inadequately protected. This gap stems from a fundamental architectural shift: Diffusion Transformers (DiTs) entangle semantic injection and visual synthesis via joint attention, which makes it difficult to isolate and erase risky content within the generation. To bridge this gap, we investigate how semantic concepts are represented in DiTs and discover that attention heads exhibit concept-specific sensitivity. This property enables both the detection and suppression of risky content. Building on this discovery, we propose AHV-D\&S, a training-free inference-time safeguard for image generation in DiTs. Specifically, AHV-D\&S quantifies each textual token's sensitivity across all attention heads as an Attention Head Vector (AHV), which serves as a discriminative signature for detecting risky generation tendencies. In the inference stage, we propose a momentum-based strategy to dynamically track token-wise AHVs across denoising steps, and a sensitivity-guided adaptive suppression strategy that suppresses the attention weights of identified risky tokens based on head-specific risk scores. Extensive experiments demonstrate that AHV-D\&S effectively suppresses sexual, copyrighted-style, and various harmful content while preserving visual quality, and further exhibits strong robustness against adversarial prompts and transferability across different DiT-based T2I models.
Causal Disentanglement Hidden Markov Model for Fault Diagnosis
Aug 06, 2023



In modern industries, fault diagnosis has been widely applied with the goal of realizing predictive maintenance. The key issue for the fault diagnosis system is to extract representative characteristics of the fault signal and then accurately predict the fault type. In this paper, we propose a Causal Disentanglement Hidden Markov model (CDHM) to learn the causality in the bearing fault mechanism and thus, capture their characteristics to achieve a more robust representation. Specifically, we make full use of the time-series data and progressively disentangle the vibration signal into fault-relevant and fault-irrelevant factors. The ELBO is reformulated to optimize the learning of the causal disentanglement Markov model. Moreover, to expand the scope of the application, we adopt unsupervised domain adaptation to transfer the learned disentangled representations to other working environments. Experiments were conducted on the CWRU dataset and IMS dataset. Relevant results validate the superiority of the proposed method.
Intrinsic Bias Identification on Medical Image Datasets
Mar 29, 2022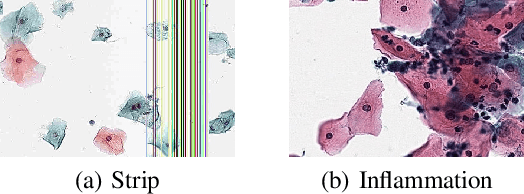
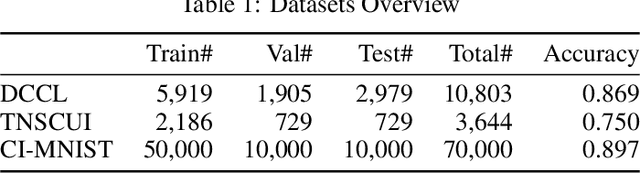
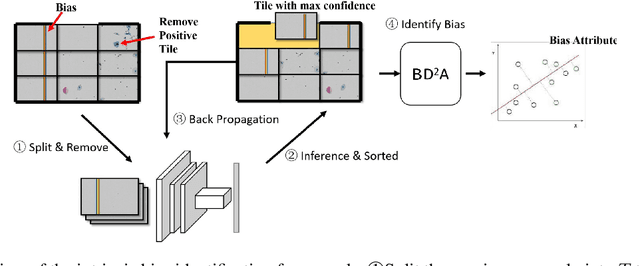
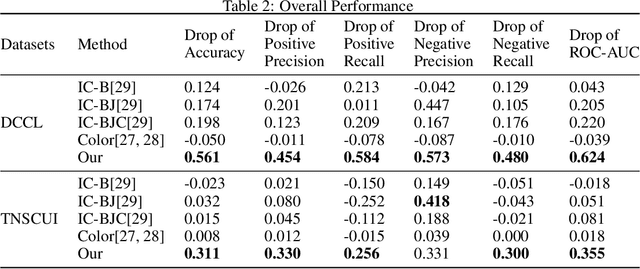
Machine learning based medical image analysis highly depends on datasets. Biases in the dataset can be learned by the model and degrade the generalizability of the applications. There are studies on debiased models. However, scientists and practitioners are difficult to identify implicit biases in the datasets, which causes lack of reliable unbias test datasets to valid models. To tackle this issue, we first define the data intrinsic bias attribute, and then propose a novel bias identification framework for medical image datasets. The framework contains two major components, KlotskiNet and Bias Discriminant Direction Analysis(bdda), where KlostkiNet is to build the mapping which makes backgrounds to distinguish positive and negative samples and bdda provides a theoretical solution on determining bias attributes. Experimental results on three datasets show the effectiveness of the bias attributes discovered by the framework.