 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deconfounded Image-Text Matching with Causal Inference
Aug 22, 2024



Prior image-text matching methods have shown remarkable performance on many benchmark datasets, but most of them overlook the bias in the dataset, which exists in intra-modal and inter-modal, and tend to learn the spurious correlations that extremely degrade the generalization ability of the model. Furthermore, these methods often incorporate biased external knowledge from large-scale datasets as prior knowledge into image-text matching model, which is inevitable to force model further learn biased associations. To address above limitations, this paper firstly utilizes Structural Causal Models (SCMs) to illustrate how intra- and inter-modal confounders damage the image-text matching. Then, we employ backdoor adjustment to propose an innovative Deconfounded Causal Inference Network (DCIN) for image-text matching task. DCIN (1) decomposes the intra- and inter-modal confounders and incorporates them into the encoding stage of visual and textual features, effectively eliminating the spurious correlations during image-text matching, and (2) uses causal inference to mitigate biases of external knowledge. Consequently, the model can learn causality instead of spurious correlations caused by dataset bias. Extensive experiments on two well-known benchmark datasets, i.e., Flickr30K and MSCOCO, demonstrate the superiority of our proposed method.
* ACM MM
A Survey of Datasets for Information Diffusion Tasks
Jul 06, 2024



Information diffusion across various new media platforms gradually influences perceptions, decisions, and social behaviors of individual users. In communication studies, the famous Five W's of Communication model (5W Model) has displayed the process of information diffusion clearly. At present, although plenty of studies and corresponding datasets about information diffusion have emerged, a systematic categorization of tasks and an integration of datasets are still lacking. To address this gap, we survey a systematic taxonomy of information diffusion tasks and datasets based on the "5W Model" framework. We first categorize the information diffusion tasks into ten subtasks with definitions and datasets analysis, from three main tasks of information diffusion prediction, social bot detection, and misinformation detection. We also collect the publicly available dataset repository of information diffusion tasks with the available links and compare them based on six attributes affiliated to users and content: user information, social network, bot label, propagation content, propagation network, and veracity label. In addition, we discuss the limitations and future directions of current datasets and research topics to advance the future development of information diffusion. The dataset repository can be accessed at our website https://github.com/fuxiaG/Information-Diffusion-Datasets.
A Training-Free Plug-and-Play Watermark Framework for Stable Diffusion
Apr 08, 2024



Nowadays, the family of Stable Diffusion (SD) models has gained prominence for its high quality outputs and scalability. This has also raised security concerns on social media, as malicious users can create and disseminate harmful content. Existing approaches involve training components or entire SDs to embed a watermark in generated images for traceability and responsibility attribution. However, in the era of AI-generated content (AIGC), the rapid iteration of SDs renders retraining with watermark models costly. To address this, we propose a training-free plug-and-play watermark framework for SDs. Without modifying any components of SDs, we embed diverse watermarks in the latent space, adapting to the denoising process. Our experimental findings reveal that our method effectively harmonizes image quality and watermark invisibility. Furthermore, it performs robustly under various attacks. We also have validated that our method is generalized to multiple versions of SDs, even without retraining the watermark model.
Impart: An Imperceptible and Effective Label-Specific Backdoor Attack
Mar 18, 2024Backdoor attacks have been shown to impose severe threats to real security-critical scenarios. Although previous works can achieve high attack success rates, they either require access to victim models which may significantly reduce their threats in practice, or perform visually noticeable in stealthiness. Besides, there is still room to improve the attack success rates in the scenario that different poisoned samples may have different target labels (a.k.a., the all-to-all setting). In this study, we propose a novel imperceptible backdoor attack framework, named Impart, in the scenario where the attacker has no access to the victim model. Specifically, in order to enhance the attack capability of the all-to-all setting, we first propose a label-specific attack. Different from previous works which try to find an imperceptible pattern and add it to the source image as the poisoned image, we then propose to generate perturbations that align with the target label in the image feature by a surrogate model. In this way, the generated poisoned images are attached with knowledge about the target class, which significantly enhances the attack capability.
Revealing Vulnerabilities in Stable Diffusion via Targeted Attacks
Jan 16, 2024Recent developments in text-to-image models, particularly Stable Diffusion, have marked significant achievements in various applications. With these advancements, there are growing safety concerns about the vulnerability of the model that malicious entities exploit to generate targeted harmful images. However, the existing methods in the vulnerability of the model mainly evaluate the alignment between the prompt and generated images, but fall short in revealing the vulnerability associated with targeted image generation. In this study, we formulate the problem of targeted adversarial attack on Stable Diffusion and propose a framework to generate adversarial prompts. Specifically, we design a gradient-based embedding optimization method to craft reliable adversarial prompts that guide stable diffusion to generate specific images. Furthermore, after obtaining successful adversarial prompts, we reveal the mechanisms that cause the vulnerability of the model. Extensive experiments on two targeted attack tasks demonstrate the effectiveness of our method in targeted attacks. The code can be obtained in https://github.com/datar001/Revealing-Vulnerabilities-in-Stable-Diffusion-via-Targeted-Attacks.
T2IW: Joint Text to Image & Watermark Generation
Sep 07, 2023



Recent developments in text-conditioned image generative models have revolutionized the production of realistic results. Unfortunately, this has also led to an increase in privacy violations and the spread of false information, which requires the need for traceability, privacy protection, and other security measures. However, existing text-to-image paradigms lack the technical capabilities to link traceable messages with image generation. In this study, we introduce a novel task for the joint generation of text to image and watermark (T2IW). This T2IW scheme ensures minimal damage to image quality when generating a compound image by forcing the semantic feature and the watermark signal to be compatible in pixels. Additionally, by utilizing principles from Shannon information theory and non-cooperative game theory, we are able to separate the revealed image and the revealed watermark from the compound image. Furthermore, we strengthen the watermark robustness of our approach by subjecting the compound image to various post-processing attacks, with minimal pixel distortion observed in the revealed watermark. Extensive experiments have demonstrated remarkable achievements in image quality, watermark invisibility, and watermark robustness, supported by our proposed set of evaluation metrics.
IPProtect: protecting the intellectual property of visual datasets during data valuation
Dec 22, 2022



Data trading is essential to accelerate the development of data-driven machine learning pipelines. The central problem in data trading is to estimate the utility of a seller's dataset with respect to a given buyer's machine learning task, also known as data valuation. Typically, data valuation requires one or more participants to share their raw dataset with others, leading to potential risks of intellectual property (IP) violations. In this paper, we tackle the novel task of preemptively protecting the IP of datasets that need to be shared during data valuation. First, we identify and formalize two kinds of novel IP risks in visual datasets: data-item (image) IP and statistical (dataset) IP. Then, we propose a novel algorithm to convert the raw dataset into a sanitized version, that provides resistance to IP violations, while at the same time allowing accurate data valuation. The key idea is to limit the transfer of information from the raw dataset to the sanitized dataset, thereby protecting against potential intellectual property violations. Next, we analyze our method for the likely existence of a solution and immunity against reconstruction attacks. Finally, we conduct extensive experiments on three computer vision datasets demonstrating the advantages of our method in comparison to other baselines.
GlueFL: Reconciling Client Sampling and Model Masking for Bandwidth Efficient Federated Learning
Dec 03, 2022



Federated learning (FL) is an effective technique to directly involve edge devices in machine learning training while preserving client privacy. However, the substantial communication overhead of FL makes training challenging when edge devices have limited network bandwidth. Existing work to optimize FL bandwidth overlooks downstream transmission and does not account for FL client sampling. In this paper we propose GlueFL, a framework that incorporates new client sampling and model compression algorithms to mitigate low download bandwidths of FL clients. GlueFL prioritizes recently used clients and bounds the number of changed positions in compression masks in each round. Across three popular FL datasets and three state-of-the-art strategies, GlueFL reduces downstream client bandwidth by 27% on average and reduces training time by 29% on average.
Revealing Unfair Models by Mining Interpretable Evidence
Jul 12, 2022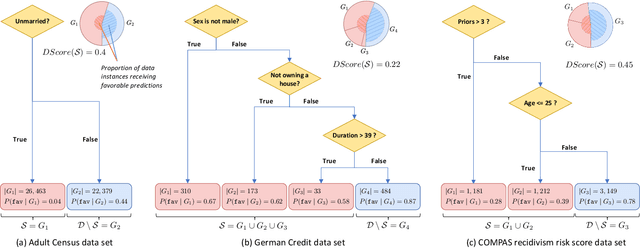
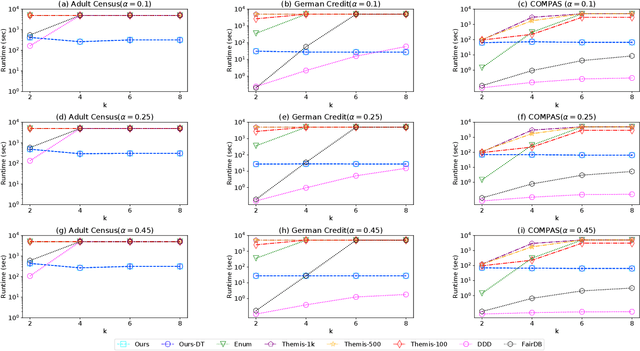
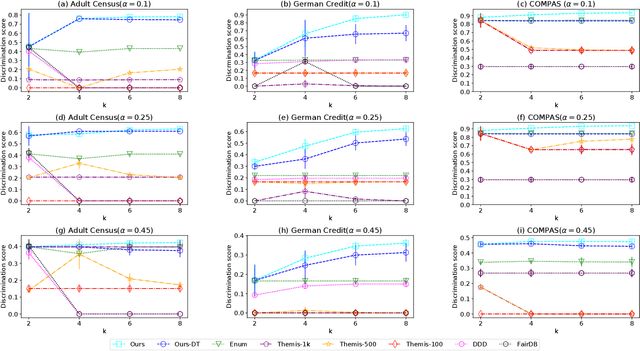
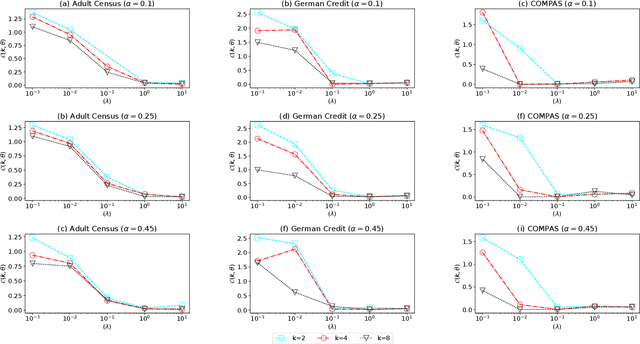
The popularity of machine learning has increased the risk of unfair models getting deployed in high-stake applications, such as justice system, drug/vaccination design, and medical diagnosis. Although there are effective methods to train fair models from scratch, how to automatically reveal and explain the unfairness of a trained model remains a challenging task. Revealing unfairness of machine learning models in interpretable fashion is a critical step towards fair and trustworthy AI. In this paper, we systematically tackle the novel task of revealing unfair models by mining interpretable evidence (RUMIE). The key idea is to find solid evidence in the form of a group of data instances discriminated most by the model. To make the evidence interpretable, we also find a set of human-understandable key attributes and decision rules that characterize the discriminated data instances and distinguish them from the other non-discriminated data. As demonstrated by extensive experiments on many real-world data sets, our method finds highly interpretable and solid evidence to effectively reveal the unfairness of trained models. Moreover, it is much more scalable than all of the baseline methods.
Intrinsic Bias Identification on Medical Image Datasets
Mar 29, 2022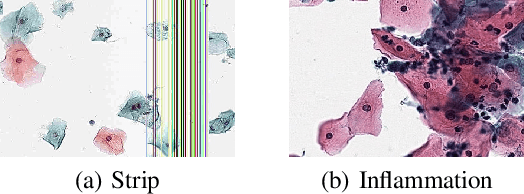
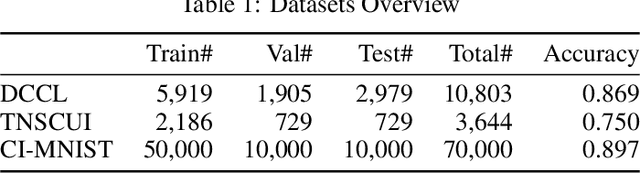
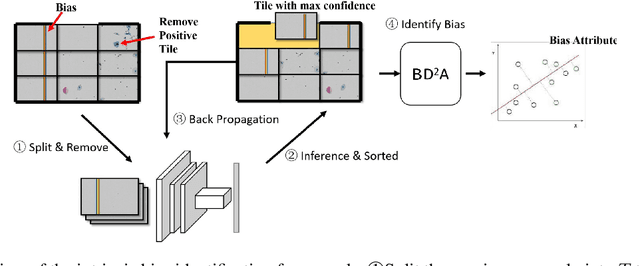
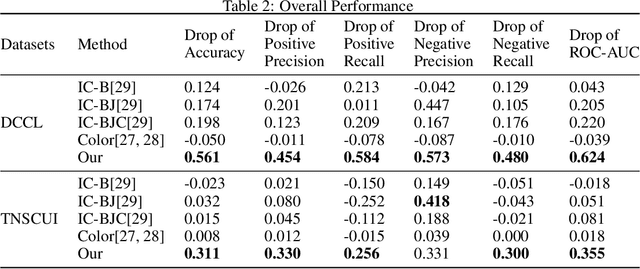
Machine learning based medical image analysis highly depends on datasets. Biases in the dataset can be learned by the model and degrade the generalizability of the applications. There are studies on debiased models. However, scientists and practitioners are difficult to identify implicit biases in the datasets, which causes lack of reliable unbias test datasets to valid models. To tackle this issue, we first define the data intrinsic bias attribute, and then propose a novel bias identification framework for medical image datasets. The framework contains two major components, KlotskiNet and Bias Discriminant Direction Analysis(bdda), where KlostkiNet is to build the mapping which makes backgrounds to distinguish positive and negative samples and bdda provides a theoretical solution on determining bias attributes. Experimental results on three datasets show the effectiveness of the bias attributes discovered by the framework.