 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonotonic Simultaneous Translation with Chunk-wise Reordering and Refinement
Oct 18, 2021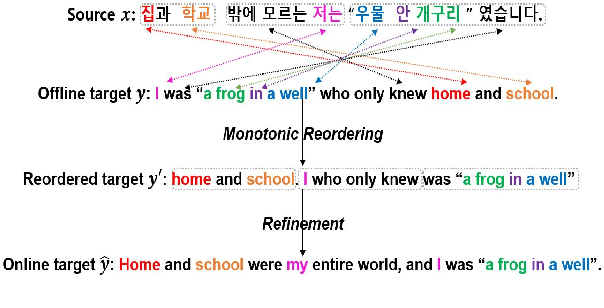
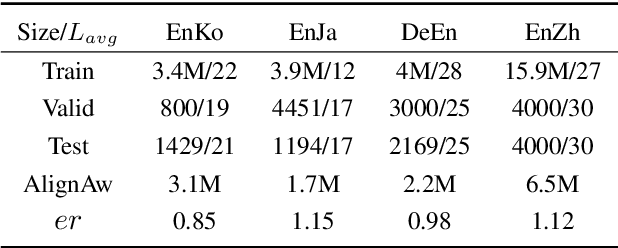
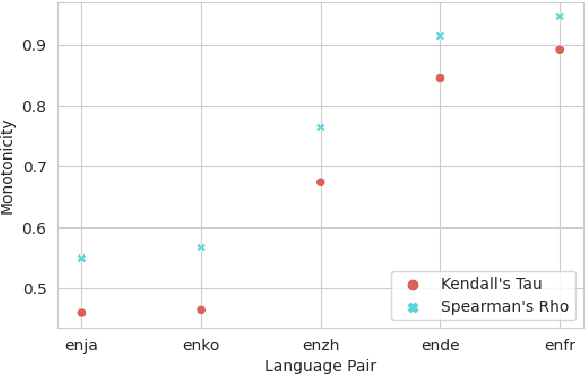
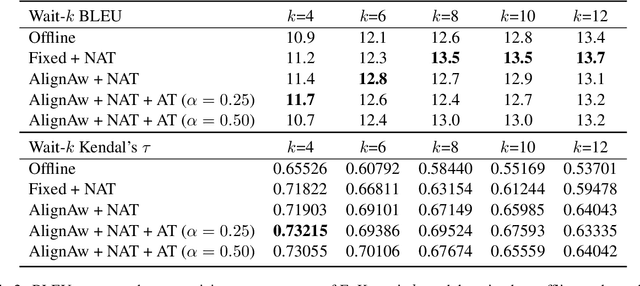
Recent work in simultaneous machine translation is often trained with conventional full sentence translation corpora, leading to either excessive latency or necessity to anticipate as-yet-unarrived words, when dealing with a language pair whose word orders significantly differ. This is unlike human simultaneous interpreters who produce largely monotonic translations at the expense of the grammaticality of a sentence being translated. In this paper, we thus propose an algorithm to reorder and refine the target side of a full sentence translation corpus, so that the words/phrases between the source and target sentences are aligned largely monotonically, using word alignment and non-autoregressive neural machine translation. We then train a widely used wait-k simultaneous translation model on this reordered-and-refined corpus. The proposed approach improves BLEU scores and resulting translations exhibit enhanced monotonicity with source sentences.
Chemical-Reaction-Aware Molecule Representation Learning
Sep 22, 2021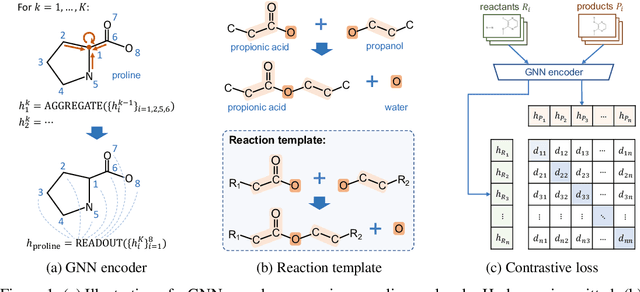
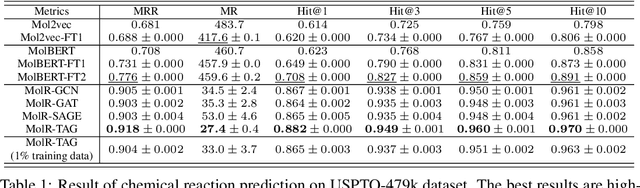
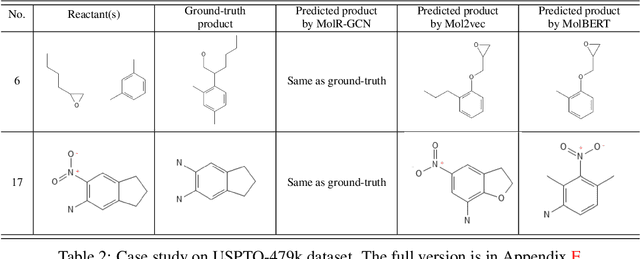
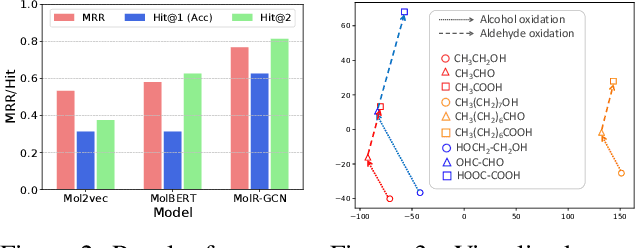
Molecule representation learning (MRL) methods aim to embed molecules into a real vector space. However, existing SMILES-based (Simplified Molecular-Input Line-Entry System) or GNN-based (Graph Neural Networks) MRL methods either take SMILES strings as input that have difficulty in encoding molecule structure information, or over-emphasize the importance of GNN architectures but neglect their generalization ability. Here we propose using chemical reactions to assist learning molecule representation. The key idea of our approach is to preserve the equivalence of molecules with respect to chemical reactions in the embedding space, i.e., forcing the sum of reactant embeddings and the sum of product embeddings to be equal for each chemical equation. This constraint is proven effective to 1) keep the embedding space well-organized and 2) improve the generalization ability of molecule embeddings. Moreover, our model can use any GNN as the molecule encoder and is thus agnostic to GNN architectures. Experimental results demonstrate that our method achieves state-of-the-art performance in a variety of downstream tasks, e.g., 17.4% absolute Hit@1 gain in chemical reaction prediction, 2.3% absolute AUC gain in molecule property prediction, and 18.5% relative RMSE gain in graph-edit-distance prediction, respectively, over the best baseline method. The code is available at https://github.com/hwwang55/MolR.
Stereo Video Reconstruction Without Explicit Depth Maps for Endoscopic Surgery
Sep 16, 2021
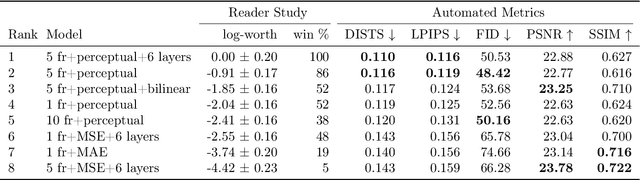
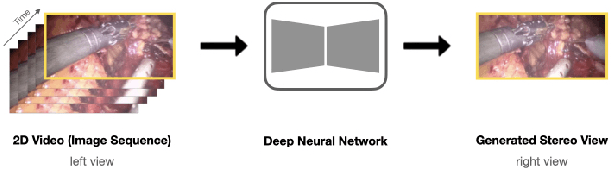
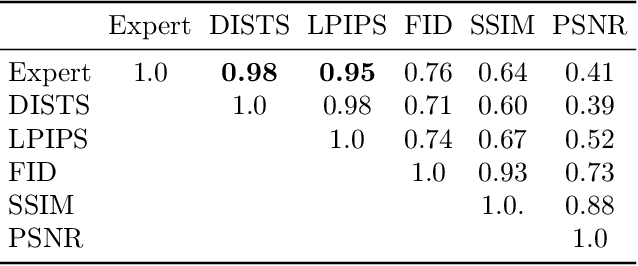
We introduce the task of stereo video reconstruction or, equivalently, 2D-to-3D video conversion for minimally invasive surgical video. We design and implement a series of end-to-end U-Net-based solutions for this task by varying the input (single frame vs. multiple consecutive frames), loss function (MSE, MAE, or perceptual losses), and network architecture. We evaluate these solutions by surveying ten experts - surgeons who routinely perform endoscopic surgery. We run two separate reader studies: one evaluating individual frames and the other evaluating fully reconstructed 3D video played on a VR headset. In the first reader study, a variant of the U-Net that takes as input multiple consecutive video frames and outputs the missing view performs best. We draw two conclusions from this outcome. First, motion information coming from multiple past frames is crucial in recreating stereo vision. Second, the proposed U-Net variant can indeed exploit such motion information for solving this task. The result from the second study further confirms the effectiveness of the proposed U-Net variant. The surgeons reported that they could successfully perceive depth from the reconstructed 3D video clips. They also expressed a clear preference for the reconstructed 3D video over the original 2D video. These two reader studies strongly support the usefulness of the proposed task of stereo reconstruction for minimally invasive surgical video and indicate that deep learning is a promising approach to this task. Finally, we identify two automatic metrics, LPIPS and DISTS, that are strongly correlated with expert judgement and that could serve as proxies for the latter in future studies.
An Empirical Study on Few-shot Knowledge Probing for Pretrained Language Models
Sep 11, 2021

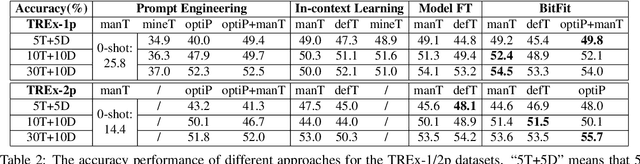
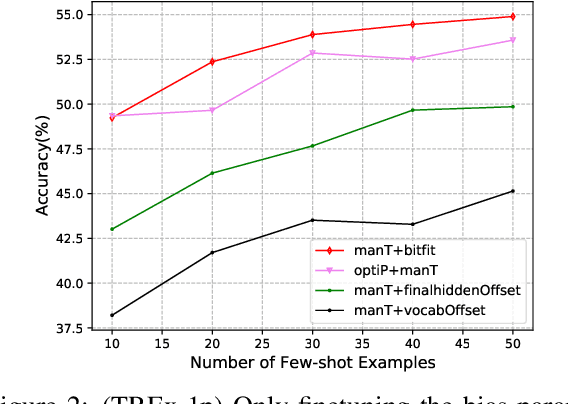
Prompt-based knowledge probing for 1-hop relations has been used to measure how much world knowledge is stored in pretrained language models. Existing work uses considerable amounts of data to tune the prompts for better performance. In this work, we compare a variety of approaches under a few-shot knowledge probing setting, where only a small number (e.g., 10 or 20) of example triples are available. In addition, we create a new dataset named TREx-2p, which contains 2-hop relations. We report that few-shot examples can strongly boost the probing performance for both 1-hop and 2-hop relations. In particular, we find that a simple-yet-effective approach of finetuning the bias vectors in the model outperforms existing prompt-engineering methods. Our dataset and code are available at \url{https://github.com/cloudygoose/fewshot_lama}.
Meta-repository of screening mammography classifiers
Aug 10, 2021
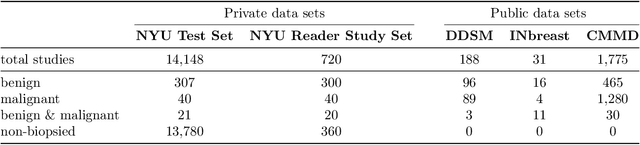
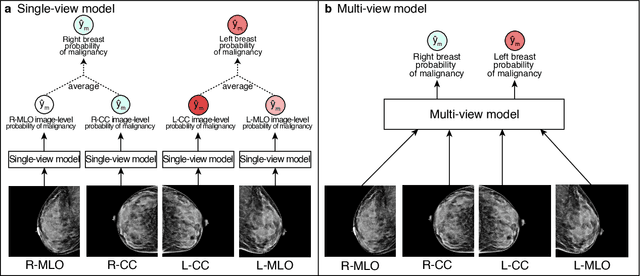
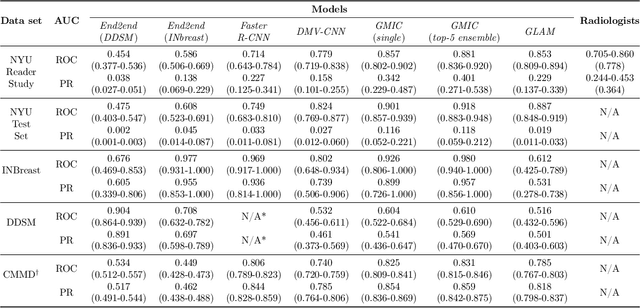
Artificial intelligence (AI) is transforming medicine and showing promise in improving clinical diagnosis. In breast cancer screening, several recent studies show that AI has the potential to improve radiologists' accuracy, subsequently helping in early cancer diagnosis and reducing unnecessary workup. As the number of proposed models and their complexity grows, it is becoming increasingly difficult to re-implement them in order to reproduce the results and to compare different approaches. To enable reproducibility of research in this application area and to enable comparison between different methods, we release a meta-repository containing deep learning models for classification of screening mammograms. This meta-repository creates a framework that enables the evaluation of machine learning models on any private or public screening mammography data set. At its inception, our meta-repository contains five state-of-the-art models with open-source implementations and cross-platform compatibility. We compare their performance on five international data sets: two private New York University breast cancer screening data sets as well as three public (DDSM, INbreast and Chinese Mammography Database) data sets. Our framework has a flexible design that can be generalized to other medical image analysis tasks. The meta-repository is available at https://www.github.com/nyukat/mammography_metarepository.
AAVAE: Augmentation-Augmented Variational Autoencoders
Jul 26, 2021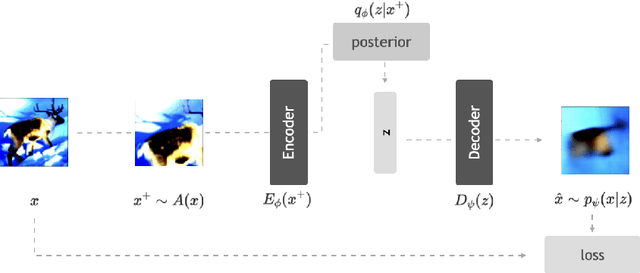
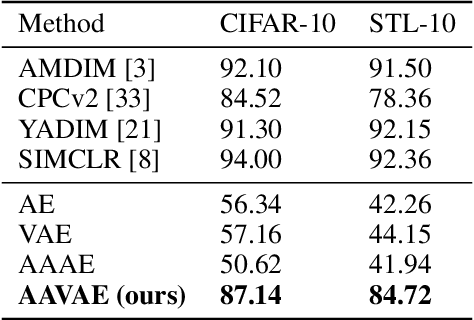
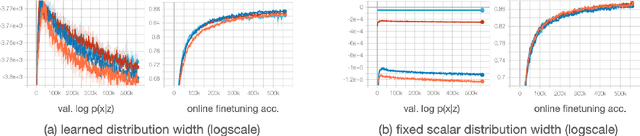
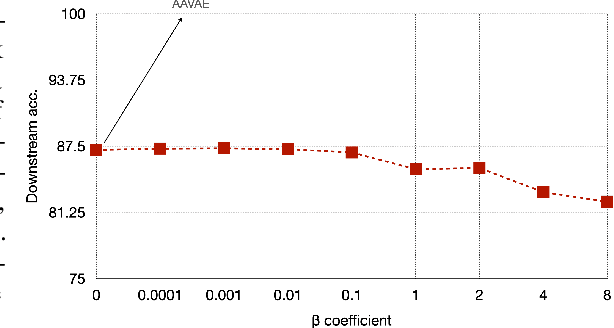
Recent methods for self-supervised learning can be grouped into two paradigms: contrastive and non-contrastive approaches. Their success can largely be attributed to data augmentation pipelines which generate multiple views of a single input that preserve the underlying semantics. In this work, we introduce augmentation-augmented variational autoencoders (AAVAE), a third approach to self-supervised learning based on autoencoding. We derive AAVAE starting from the conventional variational autoencoder (VAE), by replacing the KL divergence regularization, which is agnostic to the input domain, with data augmentations that explicitly encourage the internal representations to encode domain-specific invariances and equivariances. We empirically evaluate the proposed AAVAE on image classification, similar to how recent contrastive and non-contrastive learning algorithms have been evaluated. Our experiments confirm the effectiveness of data augmentation as a replacement for KL divergence regularization. The AAVAE outperforms the VAE by 30% on CIFAR-10 and 40% on STL-10. The results for AAVAE are largely comparable to the state-of-the-art for self-supervised learning.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021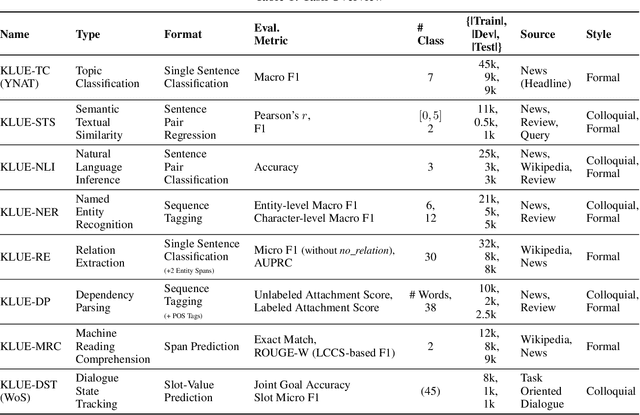
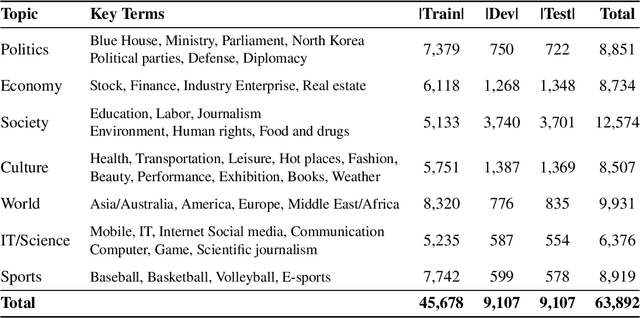
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.
Mode recovery in neural autoregressive sequence modeling
Jun 10, 2021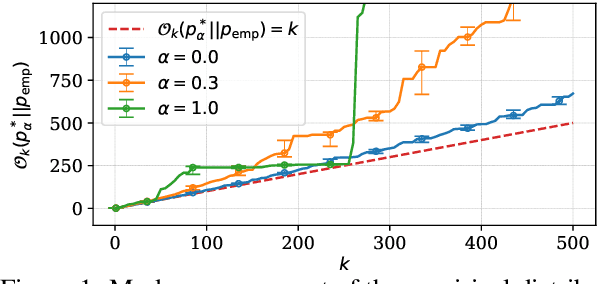
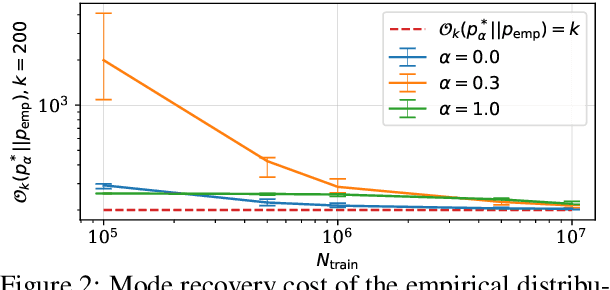
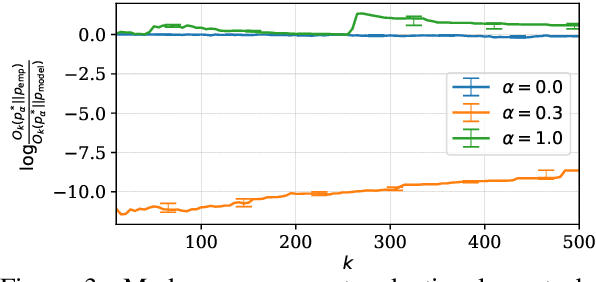
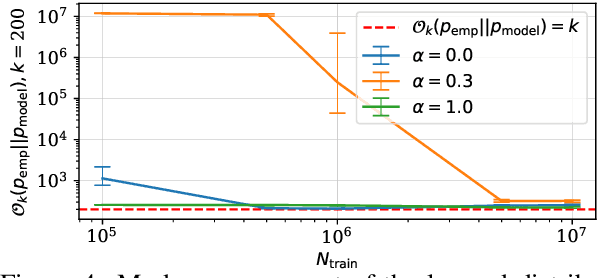
Despite its wide use, recent studies have revealed unexpected and undesirable properties of neural autoregressive sequence models trained with maximum likelihood, such as an unreasonably high affinity to short sequences after training and to infinitely long sequences at decoding time. We propose to study these phenomena by investigating how the modes, or local maxima, of a distribution are maintained throughout the full learning chain of the ground-truth, empirical, learned and decoding-induced distributions, via the newly proposed mode recovery cost. We design a tractable testbed where we build three types of ground-truth distributions: (1) an LSTM based structured distribution, (2) an unstructured distribution where probability of a sequence does not depend on its content, and (3) a product of these two which we call a semi-structured distribution. Our study reveals both expected and unexpected findings. First, starting with data collection, mode recovery cost strongly relies on the ground-truth distribution and is most costly with the semi-structured distribution. Second, after learning, mode recovery cost from the ground-truth distribution may increase or decrease compared to data collection, with the largest cost degradation occurring with the semi-structured ground-truth distribution. Finally, the ability of the decoding-induced distribution to recover modes from the learned distribution is highly impacted by the choices made earlier in the learning chain. We conclude that future research must consider the entire learning chain in order to fully understand the potentials and perils and to further improve neural autoregressive sequence models.
Comparing Test Sets with Item Response Theory
Jun 01, 2021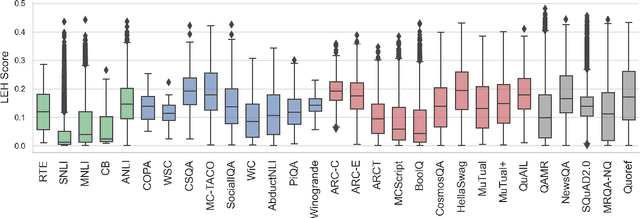
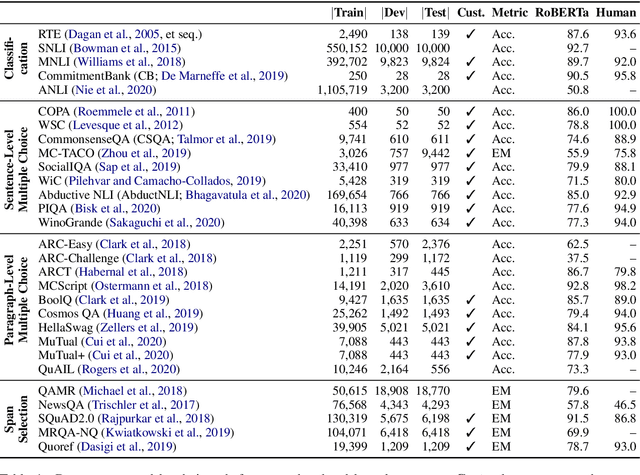
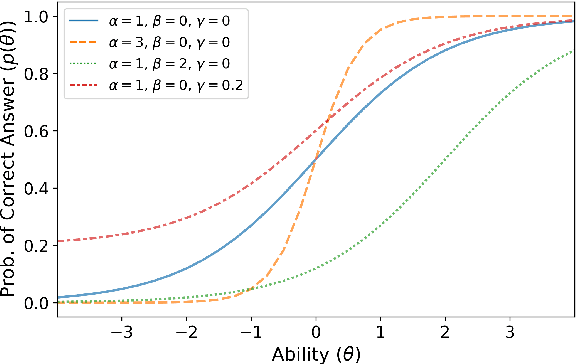

Recent years have seen numerous NLP datasets introduced to evaluate the performance of fine-tuned models on natural language understanding tasks. Recent results from large pretrained models, though, show that many of these datasets are largely saturated and unlikely to be able to detect further progress. What kind of datasets are still effective at discriminating among strong models, and what kind of datasets should we expect to be able to detect future improvements? To measure this uniformly across datasets, we draw on Item Response Theory and evaluate 29 datasets using predictions from 18 pretrained Transformer models on individual test examples. We find that Quoref, HellaSwag, and MC-TACO are best suited for distinguishing among state-of-the-art models, while SNLI, MNLI, and CommitmentBank seem to be saturated for current strong models. We also observe span selection task format, which is used for QA datasets like QAMR or SQuAD2.0, is effective in differentiating between strong and weak models.
True Few-Shot Learning with Language Models
May 24, 2021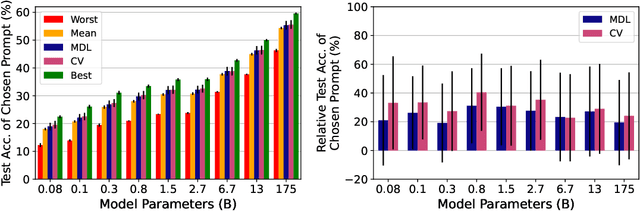
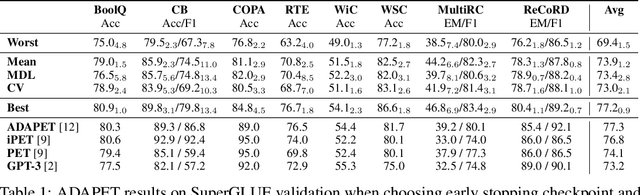
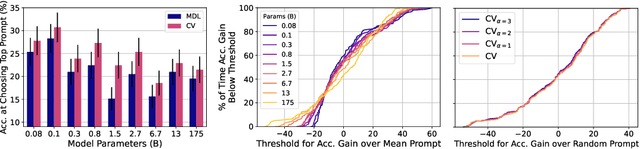

Pretrained language models (LMs) perform well on many tasks even when learning from a few examples, but prior work uses many held-out examples to tune various aspects of learning, such as hyperparameters, training objectives, and natural language templates ("prompts"). Here, we evaluate the few-shot ability of LMs when such held-out examples are unavailable, a setting we call true few-shot learning. We test two model selection criteria, cross-validation and minimum description length, for choosing LM prompts and hyperparameters in the true few-shot setting. On average, both marginally outperform random selection and greatly underperform selection based on held-out examples. Moreover, selection criteria often prefer models that perform significantly worse than randomly-selected ones. We find similar results even when taking into account our uncertainty in a model's true performance during selection, as well as when varying the amount of computation and number of examples used for selection. Overall, our findings suggest that prior work significantly overestimated the true few-shot ability of LMs given the difficulty of few-shot model selection.