 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Human Optical Flow and Pose
Oct 28, 2022We propose a bootstrapping framework to enhance human optical flow and pose. We show that, for videos involving humans in scenes, we can improve both the optical flow and the pose estimation quality of humans by considering the two tasks at the same time. We enhance optical flow estimates by fine-tuning them to fit the human pose estimates and vice versa. In more detail, we optimize the pose and optical flow networks to, at inference time, agree with each other. We show that this results in state-of-the-art results on the Human 3.6M and 3D Poses in the Wild datasets, as well as a human-related subset of the Sintel dataset, both in terms of pose estimation accuracy and the optical flow accuracy at human joint locations. Code available at https://github.com/ubc-vision/bootstrapping-human-optical-flow-and-pose
Attention Beats Concatenation for Conditioning Neural Fields
Sep 21, 2022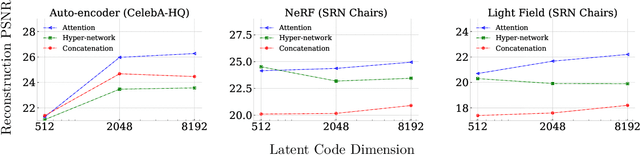


Neural fields model signals by mapping coordinate inputs to sampled values. They are becoming an increasingly important backbone architecture across many fields from vision and graphics to biology and astronomy. In this paper, we explore the differences between common conditioning mechanisms within these networks, an essential ingredient in shifting neural fields from memorization of signals to generalization, where the set of signals lying on a manifold is modelled jointly. In particular, we are interested in the scaling behaviour of these mechanisms to increasingly high-dimensional conditioning variables. As we show in our experiments, high-dimensional conditioning is key to modelling complex data distributions, thus it is important to determine what architecture choices best enable this when working on such problems. To this end, we run experiments modelling 2D, 3D, and 4D signals with neural fields, employing concatenation, hyper-network, and attention-based conditioning strategies -- a necessary but laborious effort that has not been performed in the literature. We find that attention-based conditioning outperforms other approaches in a variety of settings.
Estimating Visual Information From Audio Through Manifold Learning
Aug 03, 2022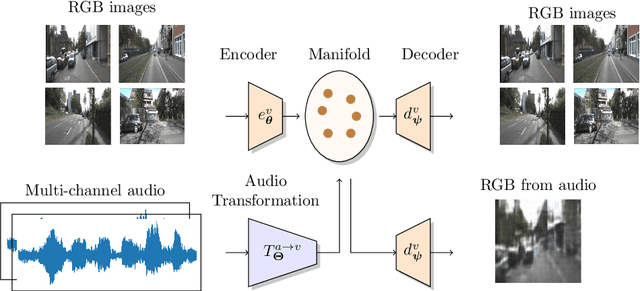
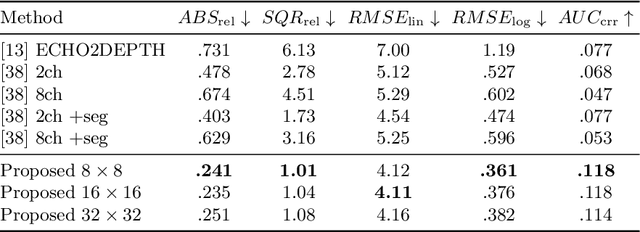

We propose a new framework for extracting visual information about a scene only using audio signals. Audio-based methods can overcome some of the limitations of vision-based methods i.e., they do not require "line-of-sight", are robust to occlusions and changes in illumination, and can function as a backup in case vision/lidar sensors fail. Therefore, audio-based methods can be useful even for applications in which only visual information is of interest Our framework is based on Manifold Learning and consists of two steps. First, we train a Vector-Quantized Variational Auto-Encoder to learn the data manifold of the particular visual modality we are interested in. Second, we train an Audio Transformation network to map multi-channel audio signals to the latent representation of the corresponding visual sample. We show that our method is able to produce meaningful images from audio using a publicly available audio/visual dataset. In particular, we consider the prediction of the following visual modalities from audio: depth and semantic segmentation. We hope the findings of our work can facilitate further research in visual information extraction from audio. Code is available at: https://github.com/ubc-vision/audio_manifold.
NeuralBF: Neural Bilateral Filtering for Top-down Instance Segmentation on Point Clouds
Jul 20, 2022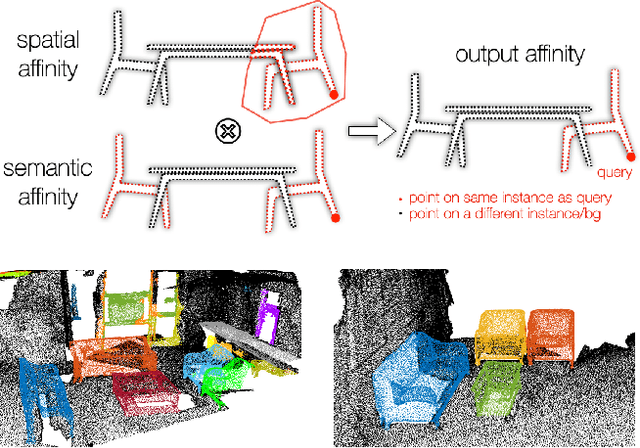
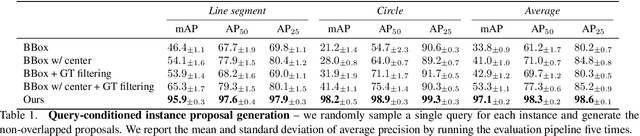
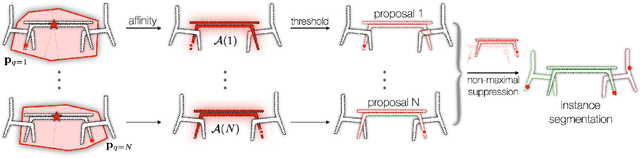
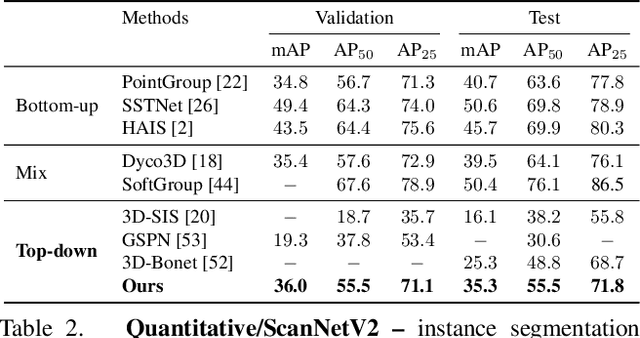
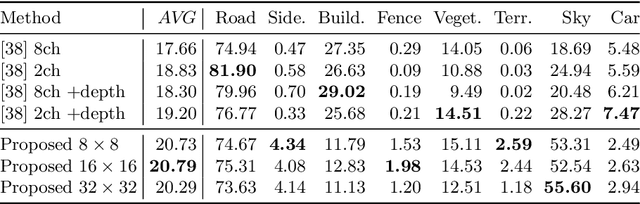
We introduce a method for instance proposal generation for 3D point clouds. Existing techniques typically directly regress proposals in a single feed-forward step, leading to inaccurate estimation. We show that this serves as a critical bottleneck, and propose a method based on iterative bilateral filtering with learned kernels. Following the spirit of bilateral filtering, we consider both the deep feature embeddings of each point, as well as their locations in the 3D space. We show via synthetic experiments that our method brings drastic improvements when generating instance proposals for a given point of interest. We further validate our method on the challenging ScanNet benchmark, achieving the best instance segmentation performance amongst the sub-category of top-down methods.
TUSK: Task-Agnostic Unsupervised Keypoints
Jun 16, 2022
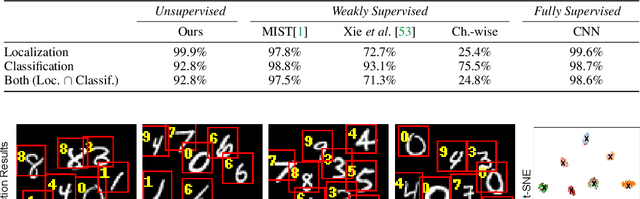
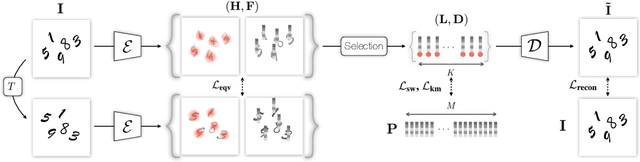

Existing unsupervised methods for keypoint learning rely heavily on the assumption that a specific keypoint type (e.g. elbow, digit, abstract geometric shape) appears only once in an image. This greatly limits their applicability, as each instance must be isolated before applying the method-an issue that is never discussed or evaluated. We thus propose a novel method to learn Task-agnostic, UnSupervised Keypoints (TUSK) which can deal with multiple instances. To achieve this, instead of the commonly-used strategy of detecting multiple heatmaps, each dedicated to a specific keypoint type, we use a single heatmap for detection, and enable unsupervised learning of keypoint types through clustering. Specifically, we encode semantics into the keypoints by teaching them to reconstruct images from a sparse set of keypoints and their descriptors, where the descriptors are forced to form distinct clusters in feature space around learned prototypes. This makes our approach amenable to a wider range of tasks than any previous unsupervised keypoint method: we show experiments on multiple-instance detection and classification, object discovery, and landmark detection-all unsupervised-with performance on par with the state of the art, while also being able to deal with multiple instances.
FlowNet-PET: Unsupervised Learning to Perform Respiratory Motion Correction in PET Imaging
May 27, 2022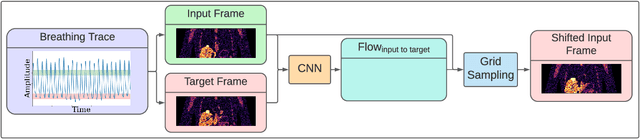
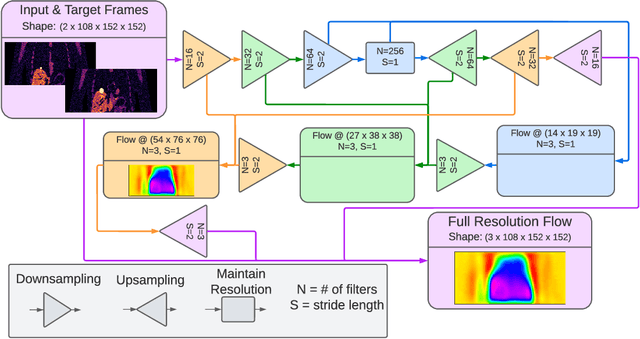
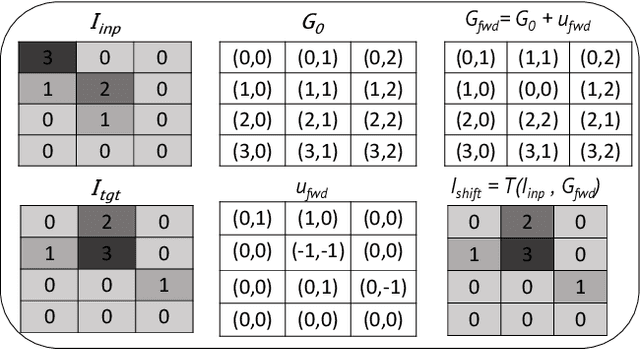
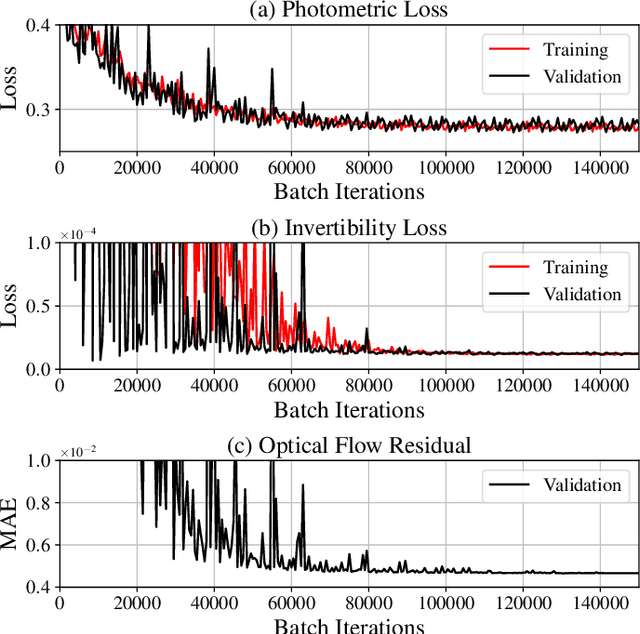
To correct for breathing motion in PET imaging, an interpretable and unsupervised deep learning technique, FlowNet-PET, was constructed. The network was trained to predict the optical flow between two PET frames from different breathing amplitude ranges. As a result, the trained model groups different retrospectively-gated PET images together into a motion-corrected single bin, providing a final image with similar counting statistics as a non-gated image, but without the blurring effects that were initially observed. As a proof-of-concept, FlowNet-PET was applied to anthropomorphic digital phantom data, which provided the possibility to design robust metrics to quantify the corrections. When comparing the predicted optical flows to the ground truths, the median absolute error was found to be smaller than the pixel and slice widths, even for the phantom with a diaphragm movement of 21 mm. The improvements were illustrated by comparing against images without motion and computing the intersection over union (IoU) of the tumors as well as the enclosed activity and coefficient of variation (CoV) within the no-motion tumor volume before and after the corrections were applied. The average relative improvements provided by the network were 54%, 90%, and 76% for the IoU, total activity, and CoV, respectively. The results were then compared against the conventional retrospective phase binning approach. FlowNet-PET achieved similar results as retrospective binning, but only required one sixth of the scan duration. The code and data used for training and analysis has been made publicly available (https://github.com/teaghan/FlowNet_PET).
A Simple Method to Boost Human Pose Estimation Accuracy by Correcting the Joint Regressor for the Human3.6m Dataset
Apr 29, 2022
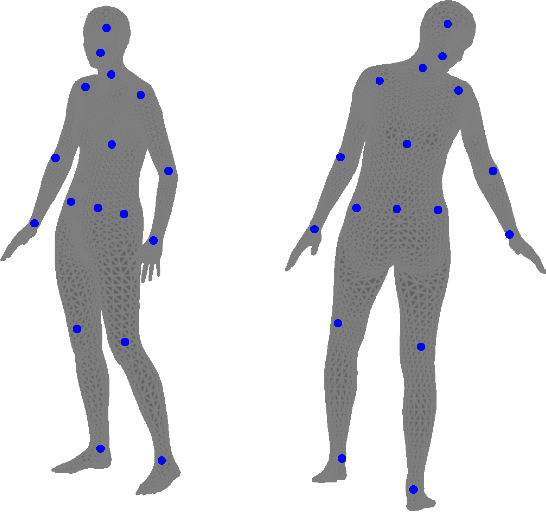


Many human pose estimation methods estimate Skinned Multi-Person Linear (SMPL) models and regress the human joints from these SMPL estimates. In this work, we show that the most widely used SMPL-to-joint linear layer (joint regressor) is inaccurate, which may mislead pose evaluation results. To achieve a more accurate joint regressor, we propose a method to create pseudo-ground-truth SMPL poses, which can then be used to train an improved regressor. Specifically, we optimize SMPL estimates coming from a state-of-the-art method so that its projection matches the silhouettes of humans in the scene, as well as the ground-truth 2D joint locations. While the quality of this pseudo-ground-truth is challenging to assess due to the lack of actual ground-truth SMPL, with the Human 3.6m dataset, we qualitatively show that our joint locations are more accurate and that our regressor leads to improved pose estimations results on the test set without any need for retraining. We release our code and joint regressor at https://github.com/ubc-vision/joint-regressor-refinement
NeuMan: Neural Human Radiance Field from a Single Video
Mar 23, 2022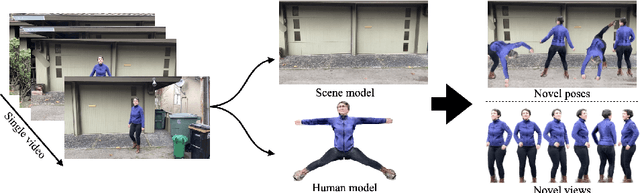

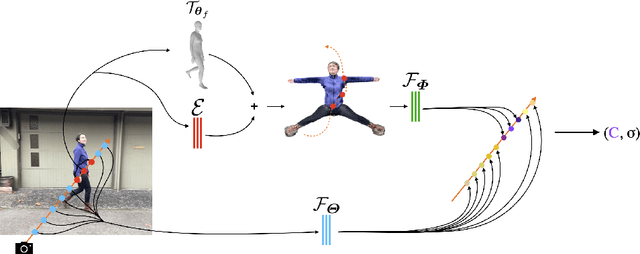
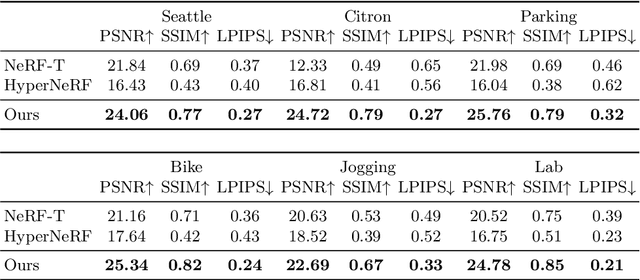
Photorealistic rendering and reposing of humans is important for enabling augmented reality experiences. We propose a novel framework to reconstruct the human and the scene that can be rendered with novel human poses and views from just a single in-the-wild video. Given a video captured by a moving camera, we train two NeRF models: a human NeRF model and a scene NeRF model. To train these models, we rely on existing methods to estimate the rough geometry of the human and the scene. Those rough geometry estimates allow us to create a warping field from the observation space to the canonical pose-independent space, where we train the human model in. Our method is able to learn subject specific details, including cloth wrinkles and accessories, from just a 10 seconds video clip, and to provide high quality renderings of the human under novel poses, from novel views, together with the background.
Kubric: A scalable dataset generator
Mar 07, 2022

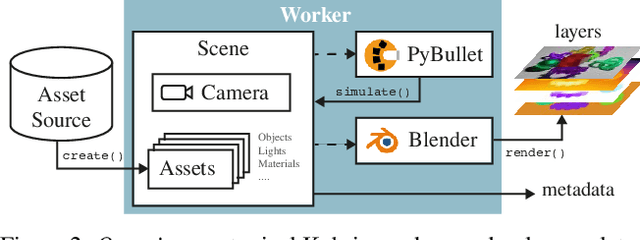
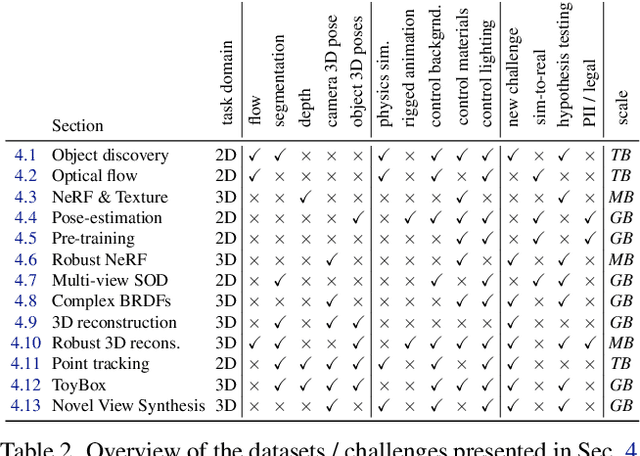
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
Repurposing Existing Deep Networks for Caption and Aesthetic-Guided Image Cropping
Jan 07, 2022
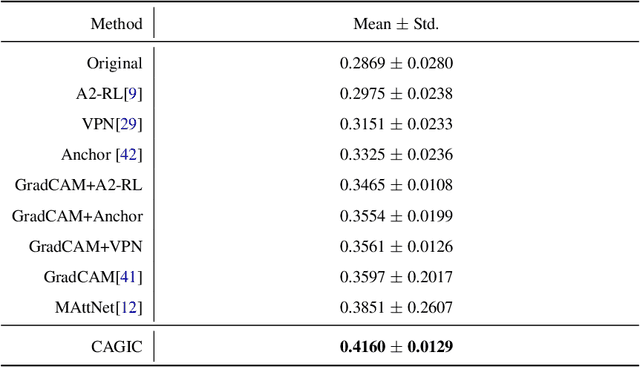
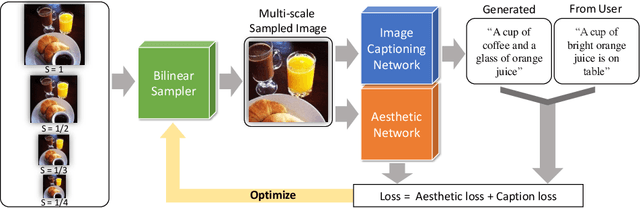
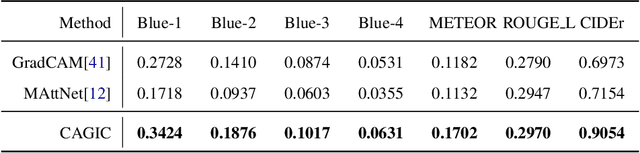
We propose a novel optimization framework that crops a given image based on user description and aesthetics. Unlike existing image cropping methods, where one typically trains a deep network to regress to crop parameters or cropping actions, we propose to directly optimize for the cropping parameters by repurposing pre-trained networks on image captioning and aesthetic tasks, without any fine-tuning, thereby avoiding training a separate network. Specifically, we search for the best crop parameters that minimize a combined loss of the initial objectives of these networks. To make the optimization table, we propose three strategies: (i) multi-scale bilinear sampling, (ii) annealing the scale of the crop region, therefore effectively reducing the parameter space, (iii) aggregation of multiple optimization results. Through various quantitative and qualitative evaluations, we show that our framework can produce crops that are well-aligned to intended user descriptions and aesthetically pleasing.