 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Realistic Test-Time Training: Sequential Inference and Adaptation by Anchored Clustering
Jun 06, 2022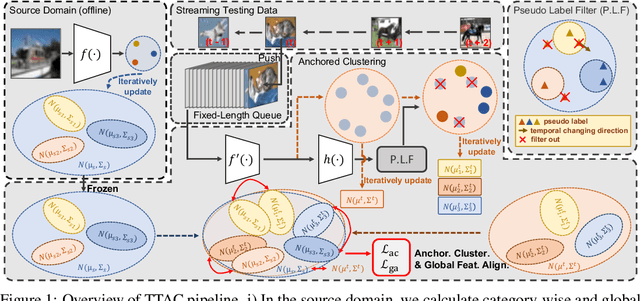
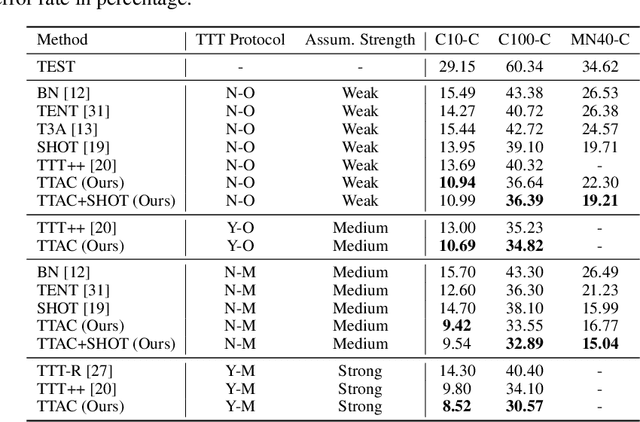
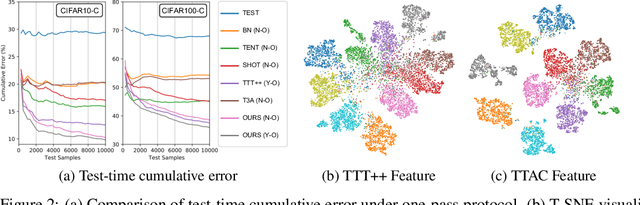
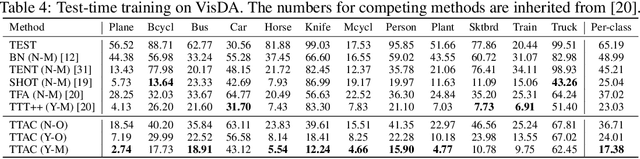
Deploying models on target domain data subject to distribution shift requires adaptation. Test-time training (TTT) emerges as a solution to this adaptation under a realistic scenario where access to full source domain data is not available and instant inference on target domain is required. Despite many efforts into TTT, there is a confusion over the experimental settings, thus leading to unfair comparisons. In this work, we first revisit TTT assumptions and categorize TTT protocols by two key factors. Among the multiple protocols, we adopt a realistic sequential test-time training (sTTT) protocol, under which we further develop a test-time anchored clustering (TTAC) approach to enable stronger test-time feature learning. TTAC discovers clusters in both source and target domain and match the target clusters to the source ones to improve generalization. Pseudo label filtering and iterative updating are developed to improve the effectiveness and efficiency of anchored clustering. We demonstrate that under all TTT protocols TTAC consistently outperforms the state-of-the-art methods on five TTT datasets. We hope this work will provide a fair benchmarking of TTT methods and future research should be compared within respective protocols. A demo code is available at https://github.com/Gorilla-Lab-SCUT/TTAC.
Exploring Diversity-based Active Learning for 3D Object Detection in Autonomous Driving
May 16, 2022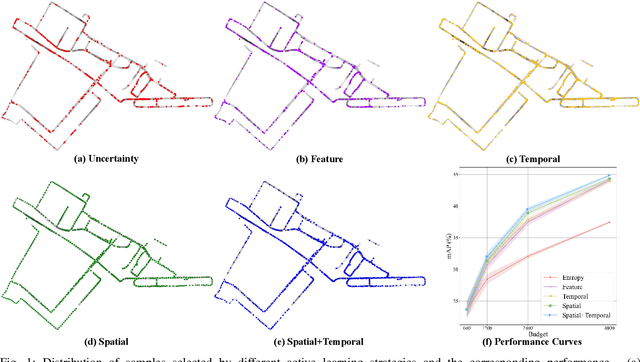
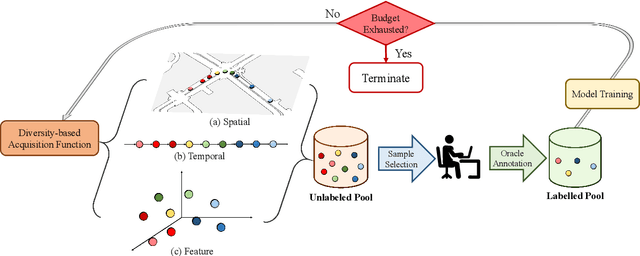
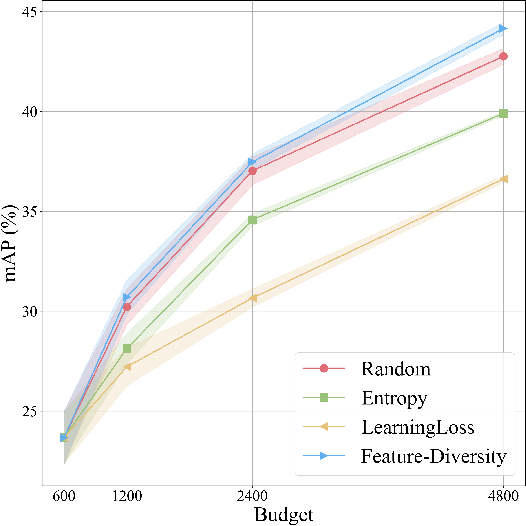
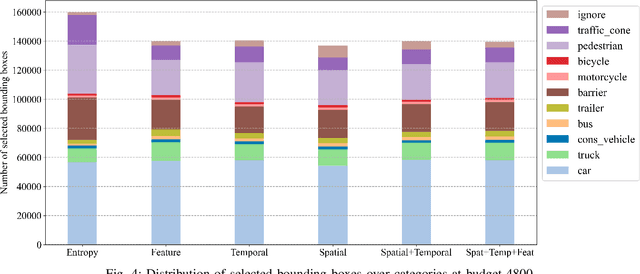
3D object detection has recently received much attention due to its great potential in autonomous vehicle (AV). The success of deep learning based object detectors relies on the availability of large-scale annotated datasets, which is time-consuming and expensive to compile, especially for 3D bounding box annotation. In this work, we investigate diversity-based active learning (AL) as a potential solution to alleviate the annotation burden. Given limited annotation budget, only the most informative frames and objects are automatically selected for human to annotate. Technically, we take the advantage of the multimodal information provided in an AV dataset, and propose a novel acquisition function that enforces spatial and temporal diversity in the selected samples. We benchmark the proposed method against other AL strategies under realistic annotation cost measurement, where the realistic costs for annotating a frame and a 3D bounding box are both taken into consideration. We demonstrate the effectiveness of the proposed method on the nuScenes dataset and show that it outperforms existing AL strategies significantly.
BiCo-Net: Regress Globally, Match Locally for Robust 6D Pose Estimation
May 07, 2022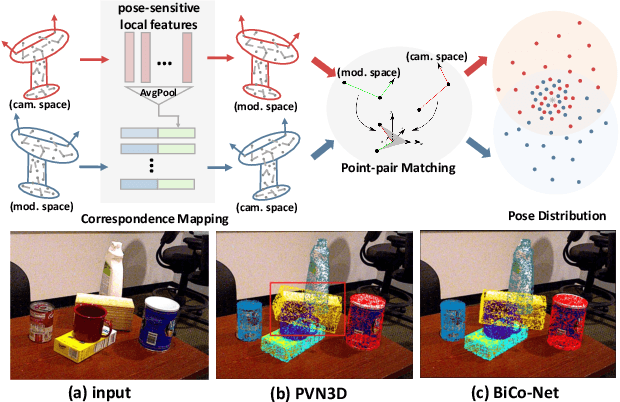
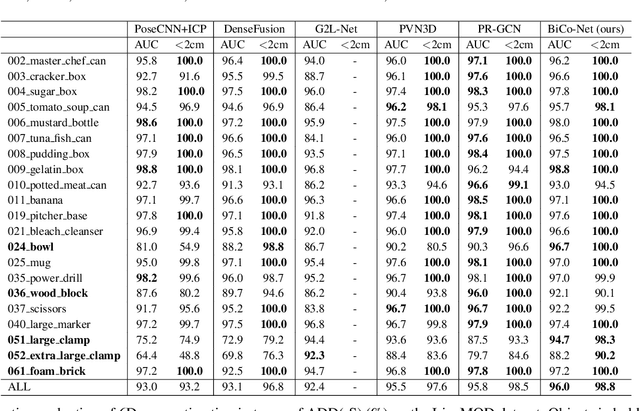
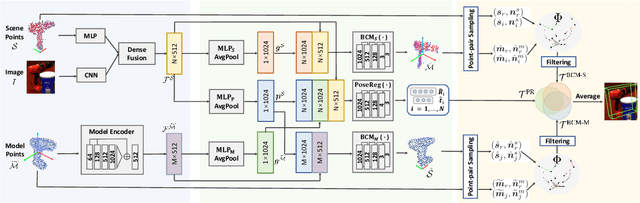

The challenges of learning a robust 6D pose function lie in 1) severe occlusion and 2) systematic noises in depth images. Inspired by the success of point-pair features, the goal of this paper is to recover the 6D pose of an object instance segmented from RGB-D images by locally matching pairs of oriented points between the model and camera space. To this end, we propose a novel Bi-directional Correspondence Mapping Network (BiCo-Net) to first generate point clouds guided by a typical pose regression, which can thus incorporate pose-sensitive information to optimize generation of local coordinates and their normal vectors. As pose predictions via geometric computation only rely on one single pair of local oriented points, our BiCo-Net can achieve robustness against sparse and occluded point clouds. An ensemble of redundant pose predictions from locally matching and direct pose regression further refines final pose output against noisy observations. Experimental results on three popularly benchmarking datasets can verify that our method can achieve state-of-the-art performance, especially for the more challenging severe occluded scenes. Source codes are available at https://github.com/Gorilla-Lab-SCUT/BiCo-Net.
Weakly Supervised 3D Point Cloud Segmentation via Multi-Prototype Learning
May 06, 2022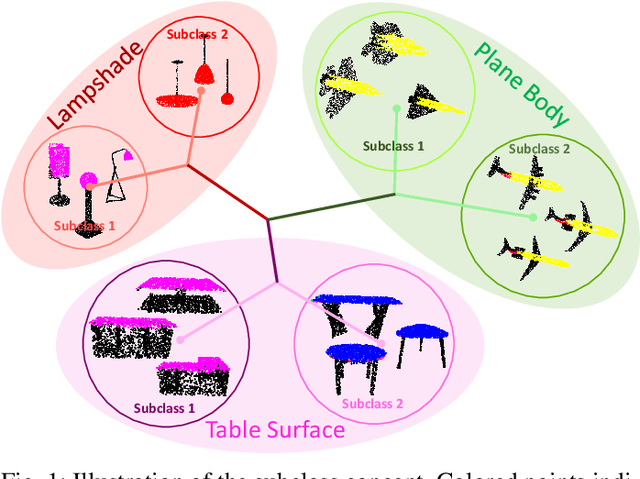
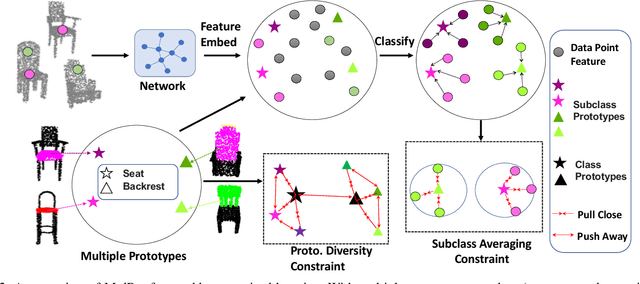
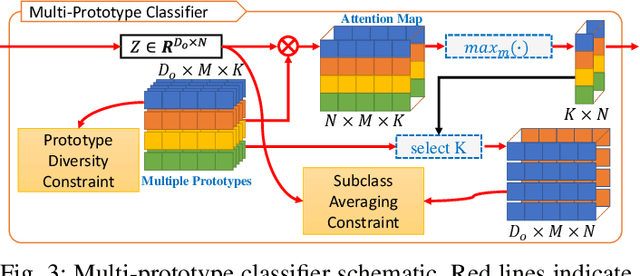

Addressing the annotation challenge in 3D Point Cloud segmentation has inspired research into weakly supervised learning. Existing approaches mainly focus on exploiting manifold and pseudo-labeling to make use of large unlabeled data points. A fundamental challenge here lies in the large intra-class variations of local geometric structure, resulting in subclasses within a semantic class. In this work, we leverage this intuition and opt for maintaining an individual classifier for each subclass. Technically, we design a multi-prototype classifier, each prototype serves as the classifier weights for one subclass. To enable effective updating of multi-prototype classifier weights, we propose two constraints respectively for updating the prototypes w.r.t. all point features and for encouraging the learning of diverse prototypes. Experiments on weakly supervised 3D point cloud segmentation tasks validate the efficacy of proposed method in particular at low-label regime. Our hypothesis is also verified given the consistent discovery of semantic subclasses at no cost of additional annotations.
Surface Reconstruction from Point Clouds: A Survey and a Benchmark
May 05, 2022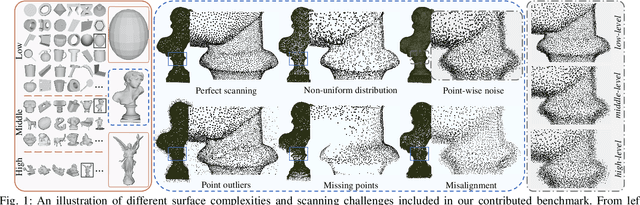
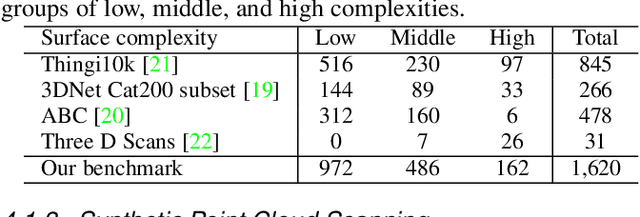
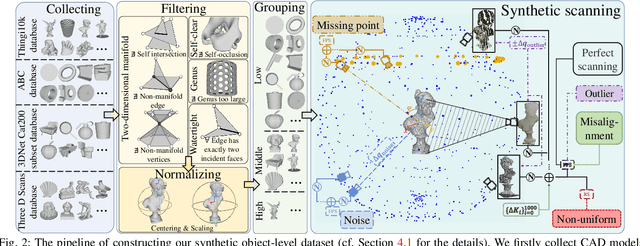
Reconstruction of a continuous surface of two-dimensional manifold from its raw, discrete point cloud observation is a long-standing problem. The problem is technically ill-posed, and becomes more difficult considering that various sensing imperfections would appear in the point clouds obtained by practical depth scanning. In literature, a rich set of methods has been proposed, and reviews of existing methods are also provided. However, existing reviews are short of thorough investigations on a common benchmark. The present paper aims to review and benchmark existing methods in the new era of deep learning surface reconstruction. To this end, we contribute a large-scale benchmarking dataset consisting of both synthetic and real-scanned data; the benchmark includes object- and scene-level surfaces and takes into account various sensing imperfections that are commonly encountered in practical depth scanning. We conduct thorough empirical studies by comparing existing methods on the constructed benchmark, and pay special attention on robustness of existing methods against various scanning imperfections; we also study how different methods generalize in terms of reconstructing complex surface shapes. Our studies help identify the best conditions under which different methods work, and suggest some empirical findings. For example, while deep learning methods are increasingly popular, our systematic studies suggest that, surprisingly, a few classical methods perform even better in terms of both robustness and generalization; our studies also suggest that the practical challenges of misalignment of point sets from multi-view scanning, missing of surface points, and point outliers remain unsolved by all the existing surface reconstruction methods. We expect that the benchmark and our studies would be valuable both for practitioners and as a guidance for new innovations in future research.
Open-Set Semi-Supervised Learning for 3D Point Cloud Understanding
May 02, 2022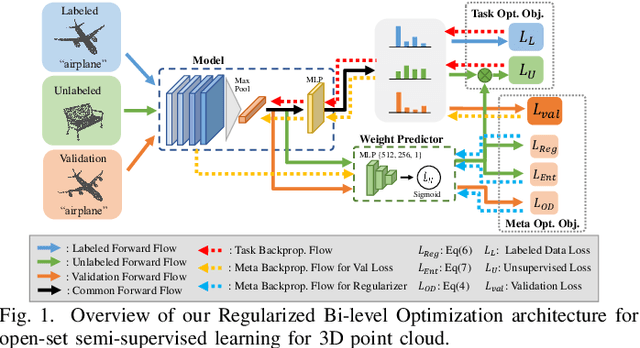
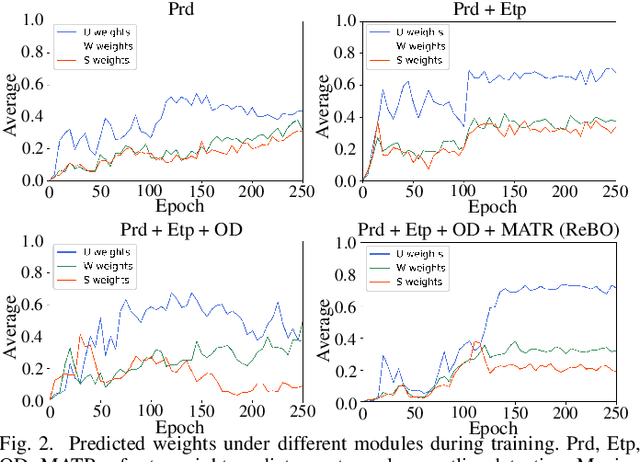
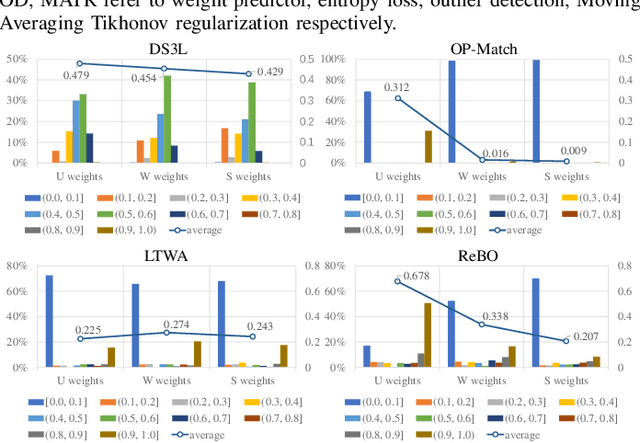
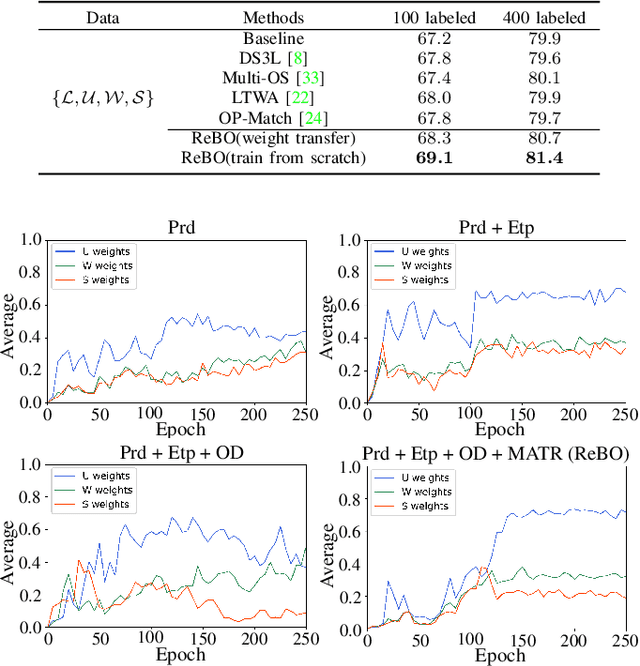
Semantic understanding of 3D point cloud relies on learning models with massively annotated data, which, in many cases, are expensive or difficult to collect. This has led to an emerging research interest in semi-supervised learning (SSL) for 3D point cloud. It is commonly assumed in SSL that the unlabeled data are drawn from the same distribution as that of the labeled ones; This assumption, however, rarely holds true in realistic environments. Blindly using out-of-distribution (OOD) unlabeled data could harm SSL performance. In this work, we propose to selectively utilize unlabeled data through sample weighting, so that only conducive unlabeled data would be prioritized. To estimate the weights, we adopt a bi-level optimization framework which iteratively optimizes a metaobjective on a held-out validation set and a task-objective on a training set. Faced with the instability of efficient bi-level optimizers, we further propose three regularization techniques to enhance the training stability. Extensive experiments on 3D point cloud classification and segmentation tasks verify the effectiveness of our proposed method. We also demonstrate the feasibility of a more efficient training strategy.
Exact Feature Distribution Matching for Arbitrary Style Transfer and Domain Generalization
Mar 25, 2022
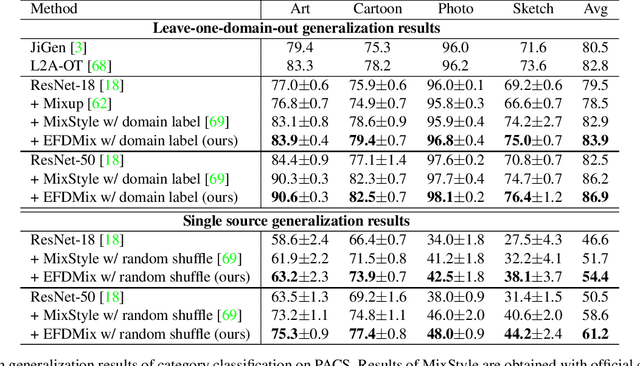


Arbitrary style transfer (AST) and domain generalization (DG) are important yet challenging visual learning tasks, which can be cast as a feature distribution matching problem. With the assumption of Gaussian feature distribution, conventional feature distribution matching methods usually match the mean and standard deviation of features. However, the feature distributions of real-world data are usually much more complicated than Gaussian, which cannot be accurately matched by using only the first-order and second-order statistics, while it is computationally prohibitive to use high-order statistics for distribution matching. In this work, we, for the first time to our best knowledge, propose to perform Exact Feature Distribution Matching (EFDM) by exactly matching the empirical Cumulative Distribution Functions (eCDFs) of image features, which could be implemented by applying the Exact Histogram Matching (EHM) in the image feature space. Particularly, a fast EHM algorithm, named Sort-Matching, is employed to perform EFDM in a plug-and-play manner with minimal cost. The effectiveness of our proposed EFDM method is verified on a variety of AST and DG tasks, demonstrating new state-of-the-art results. Codes are available at https://github.com/YBZh/EFDM.
* To appear in CVPR2022; codes and supplementary material are available at: https://github.com/YBZh/EFDM
VISTA: Boosting 3D Object Detection via Dual Cross-VIew SpaTial Attention
Mar 18, 2022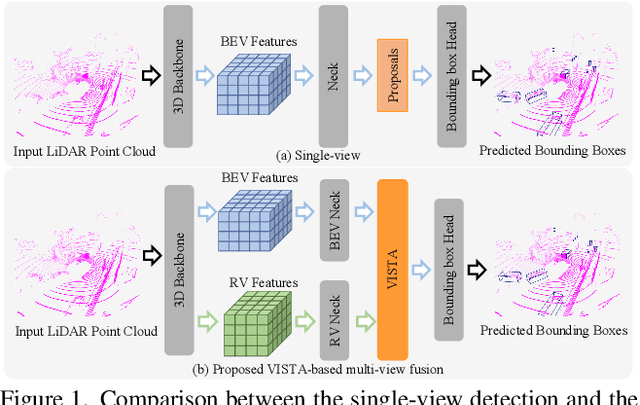
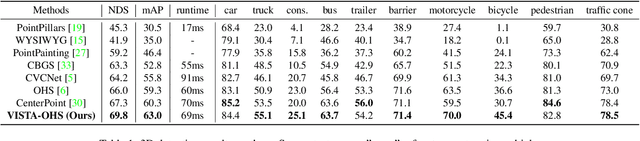
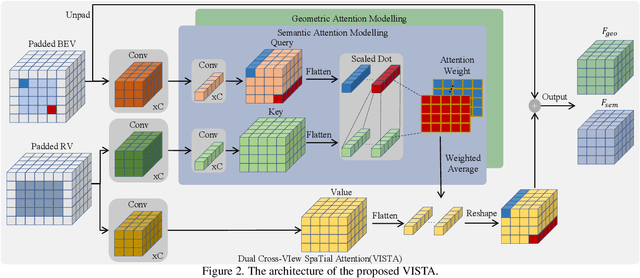

Detecting objects from LiDAR point clouds is of tremendous significance in autonomous driving. In spite of good progress, accurate and reliable 3D detection is yet to be achieved due to the sparsity and irregularity of LiDAR point clouds. Among existing strategies, multi-view methods have shown great promise by leveraging the more comprehensive information from both bird's eye view (BEV) and range view (RV). These multi-view methods either refine the proposals predicted from single view via fused features, or fuse the features without considering the global spatial context; their performance is limited consequently. In this paper, we propose to adaptively fuse multi-view features in a global spatial context via Dual Cross-VIew SpaTial Attention (VISTA). The proposed VISTA is a novel plug-and-play fusion module, wherein the multi-layer perceptron widely adopted in standard attention modules is replaced with a convolutional one. Thanks to the learned attention mechanism, VISTA can produce fused features of high quality for prediction of proposals. We decouple the classification and regression tasks in VISTA, and an additional constraint of attention variance is applied that enables the attention module to focus on specific targets instead of generic points. We conduct thorough experiments on the benchmarks of nuScenes and Waymo; results confirm the efficacy of our designs. At the time of submission, our method achieves 63.0% in overall mAP and 69.8% in NDS on the nuScenes benchmark, outperforming all published methods by up to 24% in safety-crucial categories such as cyclist. The source code in PyTorch is available at https://github.com/Gorilla-Lab-SCUT/VISTA
Quasi-Balanced Self-Training on Noise-Aware Synthesis of Object Point Clouds for Closing Domain Gap
Mar 08, 2022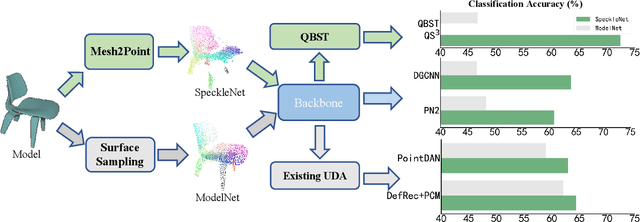
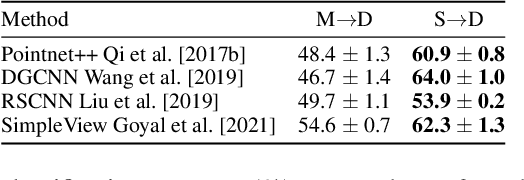
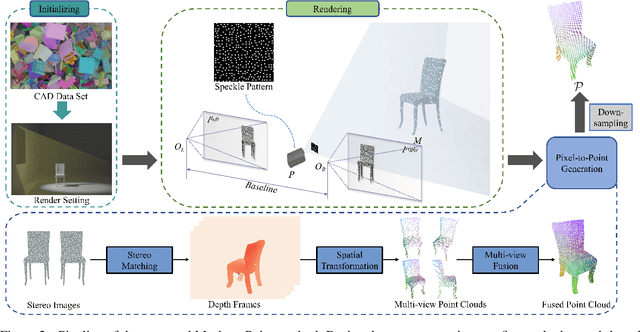
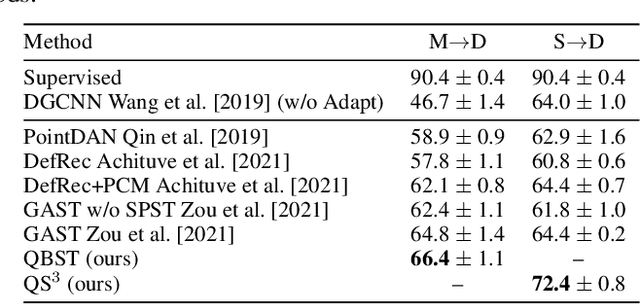
Semantic analyses of object point clouds are largely driven by releasing of benchmarking datasets, including synthetic ones whose instances are sampled from object CAD models. However, learning from synthetic data may not generalize to practical scenarios, where point clouds are typically incomplete, non-uniformly distributed, and noisy. Such a challenge of Simulation-to-Real (Sim2Real) domain gap could be mitigated via learning algorithms of domain adaptation; however, we argue that generation of synthetic point clouds via more physically realistic rendering is a powerful alternative, as systematic non-uniform noise patterns can be captured. To this end, we propose an integrated scheme consisting of physically realistic synthesis of object point clouds via rendering stereo images via projection of speckle patterns onto CAD models and a novel quasi-balanced self-training designed for more balanced data distribution by sparsity-driven selection of pseudo labeled samples for long tailed classes. Experiment results can verify the effectiveness of our method as well as both of its modules for unsupervised domain adaptation on point cloud classification, achieving the state-of-the-art performance.
Sparse Steerable Convolutions: An Efficient Learning of SE(3)-Equivariant Features for Estimation and Tracking of Object Poses in 3D Space
Nov 14, 2021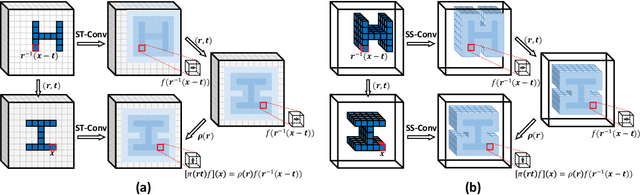
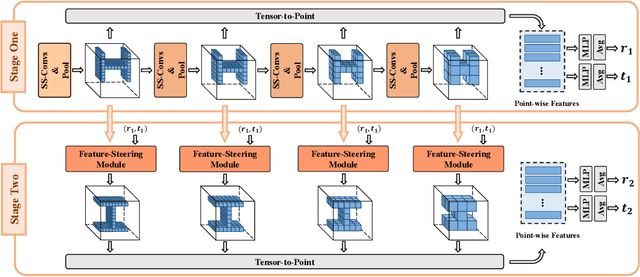
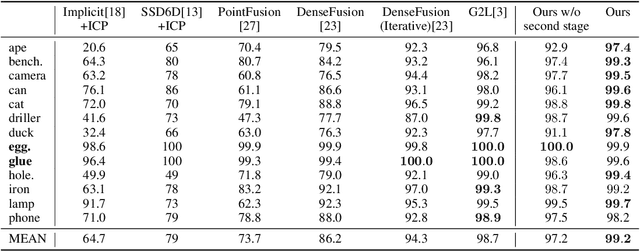
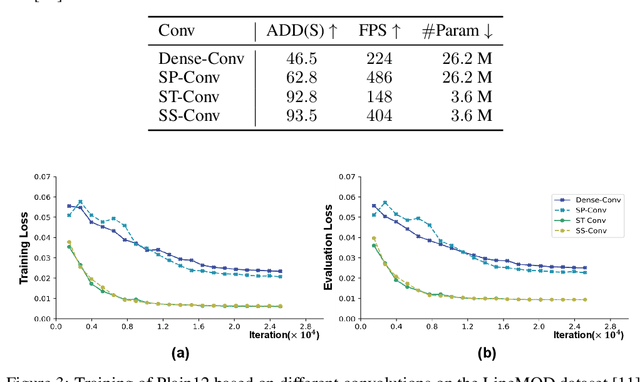
As a basic component of SE(3)-equivariant deep feature learning, steerable convolution has recently demonstrated its advantages for 3D semantic analysis. The advantages are, however, brought by expensive computations on dense, volumetric data, which prevent its practical use for efficient processing of 3D data that are inherently sparse. In this paper, we propose a novel design of Sparse Steerable Convolution (SS-Conv) to address the shortcoming; SS-Conv greatly accelerates steerable convolution with sparse tensors, while strictly preserving the property of SE(3)-equivariance. Based on SS-Conv, we propose a general pipeline for precise estimation of object poses, wherein a key design is a Feature-Steering module that takes the full advantage of SE(3)-equivariance and is able to conduct an efficient pose refinement. To verify our designs, we conduct thorough experiments on three tasks of 3D object semantic analysis, including instance-level 6D pose estimation, category-level 6D pose and size estimation, and category-level 6D pose tracking. Our proposed pipeline based on SS-Conv outperforms existing methods on almost all the metrics evaluated by the three tasks. Ablation studies also show the superiority of our SS-Conv over alternative convolutions in terms of both accuracy and efficiency. Our code is released publicly at https://github.com/Gorilla-Lab-SCUT/SS-Conv.