 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNRMVS: Non-Rigid Multi-View Stereo
Jan 12, 2019

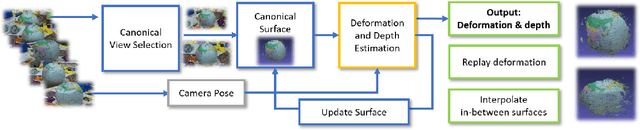
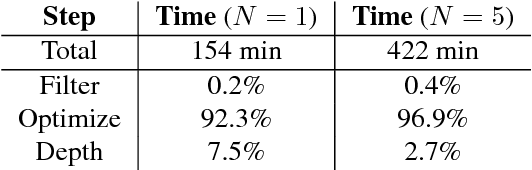
Scene reconstruction from unorganized RGB images is an important task in many computer vision applications. Multi-view Stereo (MVS) is a common solution in photogrammetry applications for the dense reconstruction of a static scene. The static scene assumption, however, limits the general applicability of MVS algorithms, as many day-to-day scenes undergo non-rigid motion, e.g., clothes, faces, or human bodies. In this paper, we open up a new challenging direction: dense 3D reconstruction of scenes with non-rigid changes observed from arbitrary, sparse, and wide-baseline views. We formulate the problem as a joint optimization of deformation and depth estimation, using deformation graphs as the underlying representation. We propose a new sparse 3D to 2D matching technique, together with a dense patch-match evaluation scheme to estimate deformation and depth with photometric consistency. We show that creating a dense 4D structure from a few RGB images with non-rigid changes is possible, and demonstrate that our method can be used to interpolate novel deformed scenes from various combinations of these deformation estimates derived from the sparse views.
Neural RGB->D Sensing: Depth and Uncertainty from a Video Camera
Jan 09, 2019
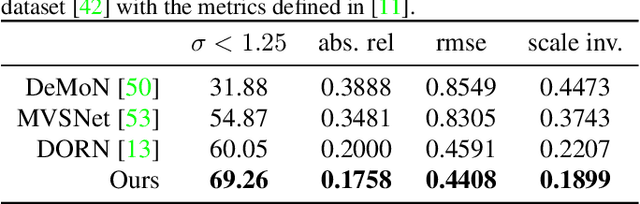
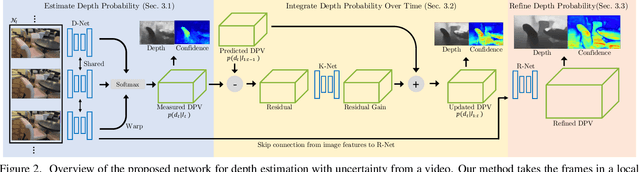
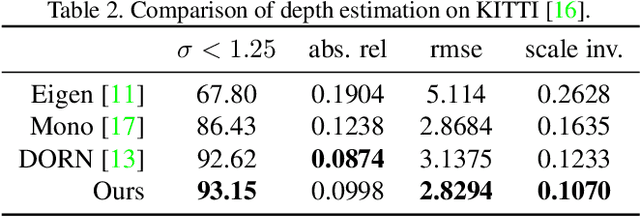
Depth sensing is crucial for 3D reconstruction and scene understanding. Active depth sensors provide dense metric measurements, but often suffer from limitations such as restricted operating ranges, low spatial resolution, sensor interference, and high power consumption. In this paper, we propose a deep learning (DL) method to estimate per-pixel depth and its uncertainty continuously from a monocular video stream, with the goal of effectively turning an RGB camera into an RGB-D camera. Unlike prior DL-based methods, we estimate a depth probability distribution for each pixel rather than a single depth value, leading to an estimate of a 3D depth probability volume for each input frame. These depth probability volumes are accumulated over time under a Bayesian filtering framework as more incoming frames are processed sequentially, which effectively reduces depth uncertainty and improves accuracy, robustness, and temporal stability. Compared to prior work, the proposed approach achieves more accurate and stable results, and generalizes better to new datasets. Experimental results also show the output of our approach can be directly fed into classical RGB-D based 3D scanning methods for 3D scene reconstruction.
Neural Inverse Rendering of an Indoor Scene from a Single Image
Jan 08, 2019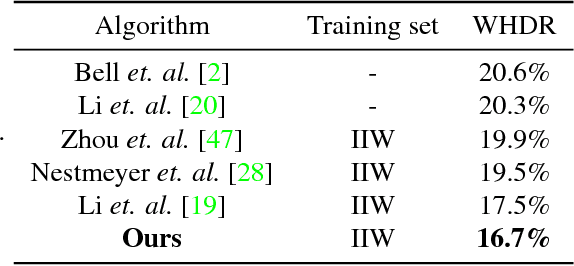
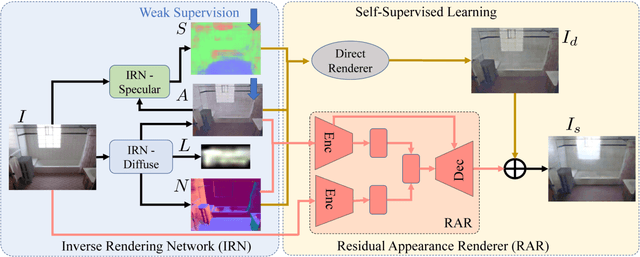


Inverse rendering aims to estimate physical scene attributes (e.g., reflectance, geometry, and lighting) from image(s). As a long-standing, highly ill-posed problem, inverse rendering has been studied primarily for single 3D objects or with methods that solve for only one of the scene attributes. To our knowledge, we are the first to propose a holistic approach for inverse rendering of an indoor scene from a single image with CNNs, which jointly estimates reflectance (albedo and gloss), surface normals and illumination. To address the lack of labeled real-world images, we create a large-scale synthetic dataset, named SUNCG-PBR, with physically-based rendering, which is a significant improvement over prior datasets. For fine-tuning on real images, we perform self-supervised learning using the reconstruction loss, which re-synthesizes the input images from the estimated components. To enable self-supervised learning on real data, our key contribution is the Residual Appearance Renderer (RAR), which can be trained to synthesize complex appearance effects (e.g., inter-reflection, cast shadows, near-field illumination, and realistic shading), which would be neglected otherwise. Experimental results show that our approach outperforms state-of-the-art methods, especially on real images.
PlaneRCNN: 3D Plane Detection and Reconstruction from a Single Image
Jan 08, 2019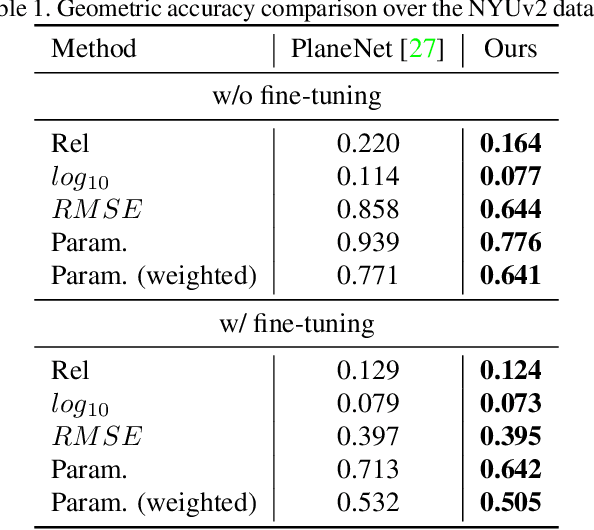
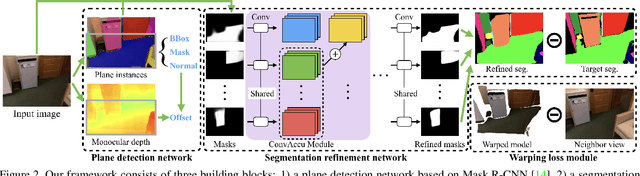
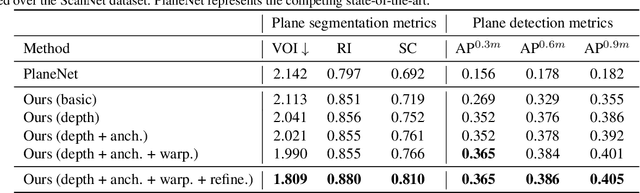

This paper proposes a deep neural architecture, PlaneRCNN, that detects and reconstructs piecewise planar surfaces from a single RGB image. PlaneRCNN employs a variant of Mask R-CNN to detect planes with their plane parameters and segmentation masks. PlaneRCNN then jointly refines all the segmentation masks with a novel loss enforcing the consistency with a nearby view during training. The paper also presents a new benchmark with more fine-grained plane segmentations in the ground-truth, in which, PlaneRCNN outperforms existing state-of-the-art methods with significant margins in the plane detection, segmentation, and reconstruction metrics. PlaneRCNN makes an important step towards robust plane extraction, which would have an immediate impact on a wide range of applications including Robotics, Augmented Reality, and Virtual Reality.
Competitive Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation
Oct 07, 2018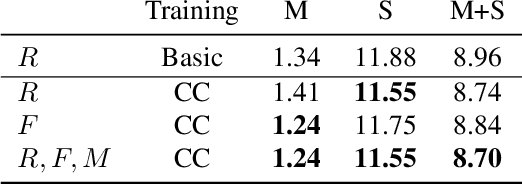
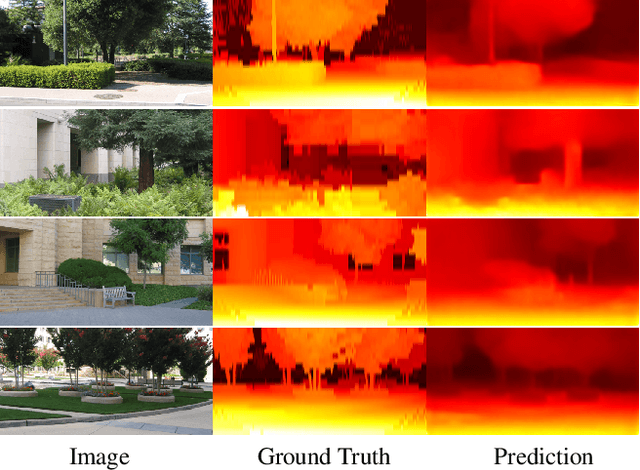
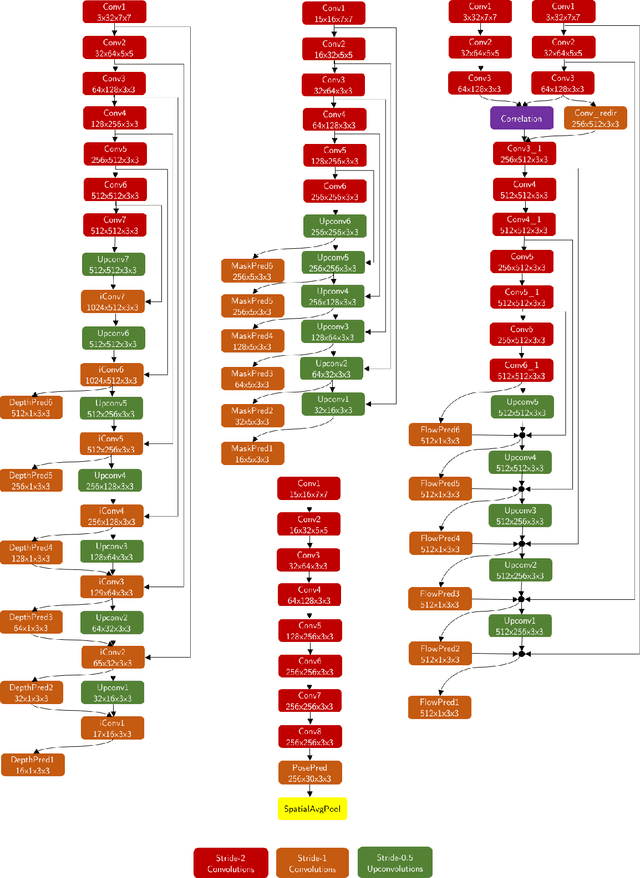
We address the unsupervised learning of several interconnected problems in low-level vision: single view depth prediction, camera motion estimation, optical flow and segmentation of a video into the static scene and moving regions. Our key insight is that these four fundamental vision problems are coupled and, consequently, learning to solve them together simplifies the problem because the solutions can reinforce each other by exploiting known geometric constraints. In order to model geometric constraints, we introduce Competitive Collaboration, a framework that facilitates competition and collaboration between neural networks. We go beyond previous work by exploiting geometry more explicitly and segmenting the scene into static and moving regions. Competitive Collaboration works much like expectation-maximization but with neural networks that act as adversaries, competing to explain pixels that correspond to static or moving regions, and as collaborators through a moderator that assigns pixels to be either static or independently moving. Our novel method integrates all these problems in a common framework and simultaneously reasons about the segmentation of the scene into moving objects and the static background, the camera motion, depth of the static scene structure, and the optical flow of moving objects. Our model is trained without any supervision and achieves state of the art results amongst unsupervised methods.
EOE: Expected Overlap Estimation over Unstructured Point Cloud Data
Aug 06, 2018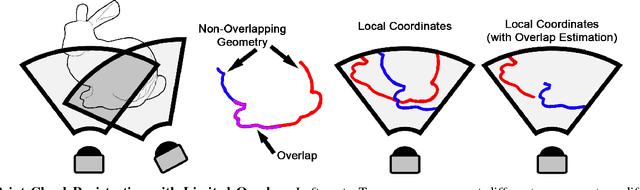
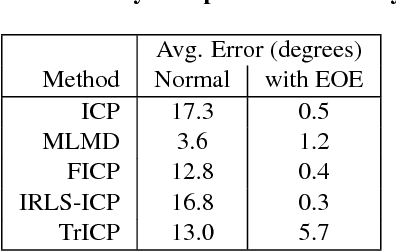
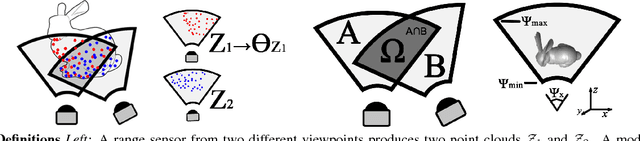
We present an iterative overlap estimation technique to augment existing point cloud registration algorithms that can achieve high performance in difficult real-world situations where large pose displacement and non-overlapping geometry would otherwise cause traditional methods to fail. Our approach estimates overlapping regions through an iterative Expectation Maximization procedure that encodes the sensor field-of-view into the registration process. The proposed technique, Expected Overlap Estimation (EOE), is derived from the observation that differences in field-of-view violate the iid assumption implicitly held by all maximum likelihood based registration techniques. We demonstrate how our approach can augment many popular registration methods with minimal computational overhead. Through experimentation on both synthetic and real-world datasets, we find that adding an explicit overlap estimation step can aid robust outlier handling and increase the accuracy of both ICP-based and GMM-based registration methods, especially in large unstructured domains and where the amount of overlap between point clouds is very small.
Learning Rigidity in Dynamic Scenes with a Moving Camera for 3D Motion Field Estimation
Jul 30, 2018
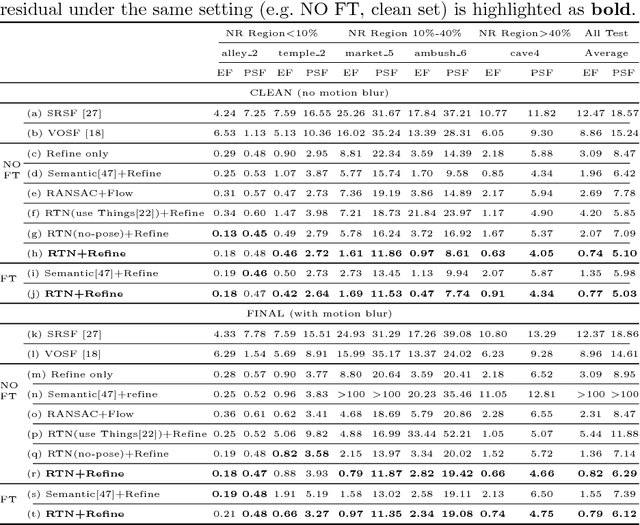
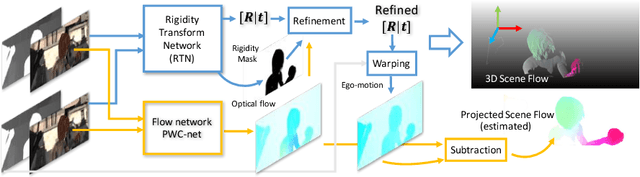
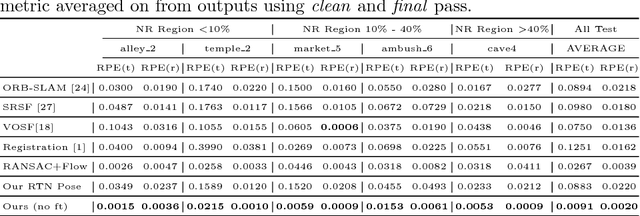
Estimation of 3D motion in a dynamic scene from a temporal pair of images is a core task in many scene understanding problems. In real world applications, a dynamic scene is commonly captured by a moving camera (i.e., panning, tilting or hand-held), increasing the task complexity because the scene is observed from different view points. The main challenge is the disambiguation of the camera motion from scene motion, which becomes more difficult as the amount of rigidity observed decreases, even with successful estimation of 2D image correspondences. Compared to other state-of-the-art 3D scene flow estimation methods, in this paper we propose to \emph{learn} the rigidity of a scene in a supervised manner from a large collection of dynamic scene data, and directly infer a rigidity mask from two sequential images with depths. With the learned network, we show how we can effectively estimate camera motion and projected scene flow using computed 2D optical flow and the inferred rigidity mask. For training and testing the rigidity network, we also provide a new semi-synthetic dynamic scene dataset (synthetic foreground objects with a real background) and an evaluation split that accounts for the percentage of observed non-rigid pixels. Through our evaluation we show the proposed framework outperforms current state-of-the-art scene flow estimation methods in challenging dynamic scenes.
Fast and Accurate Point Cloud Registration using Trees of Gaussian Mixtures
Jul 06, 2018
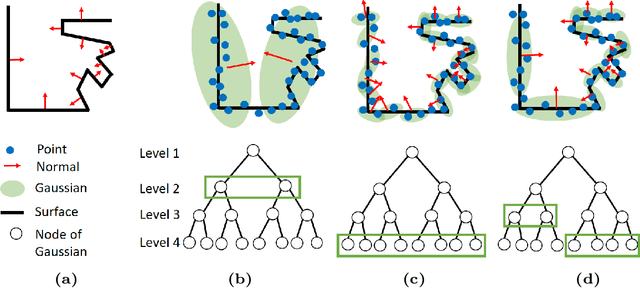
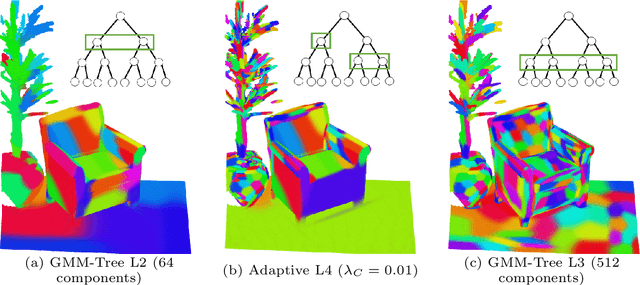

Point cloud registration sits at the core of many important and challenging 3D perception problems including autonomous navigation, SLAM, object/scene recognition, and augmented reality. In this paper, we present a new registration algorithm that is able to achieve state-of-the-art speed and accuracy through its use of a hierarchical Gaussian Mixture Model (GMM) representation. Our method constructs a top-down multi-scale representation of point cloud data by recursively running many small-scale data likelihood segmentations in parallel on a GPU. We leverage the resulting representation using a novel PCA-based optimization criterion that adaptively finds the best scale to perform data association between spatial subsets of point cloud data. Compared to previous Iterative Closest Point and GMM-based techniques, our tree-based point association algorithm performs data association in logarithmic-time while dynamically adjusting the level of detail to best match the complexity and spatial distribution characteristics of local scene geometry. In addition, unlike other GMM methods that restrict covariances to be isotropic, our new PCA-based optimization criterion well-approximates the true MLE solution even when fully anisotropic Gaussian covariances are used. Efficient data association, multi-scale adaptability, and a robust MLE approximation produce an algorithm that is up to an order of magnitude both faster and more accurate than current state-of-the-art on a wide variety of 3D datasets captured from LiDAR to structured light.
A Lightweight Approach for On-the-Fly Reflectance Estimation
Apr 02, 2018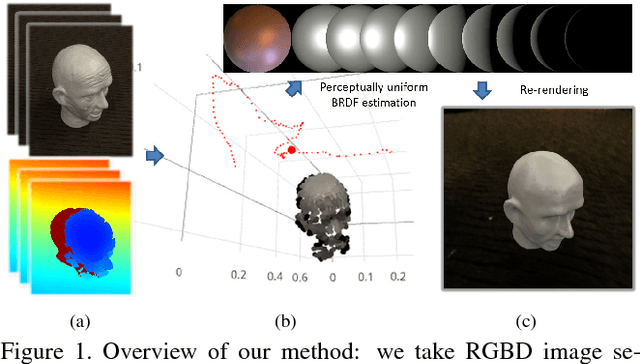
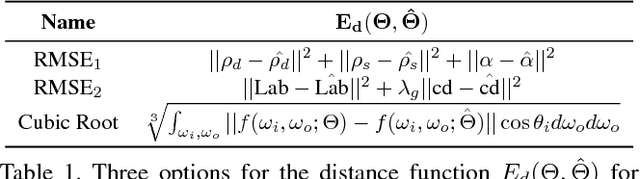
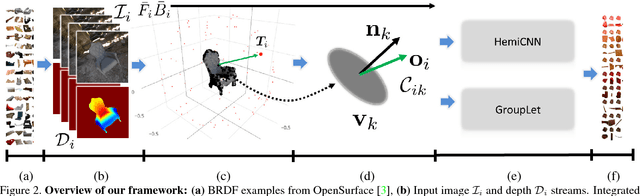
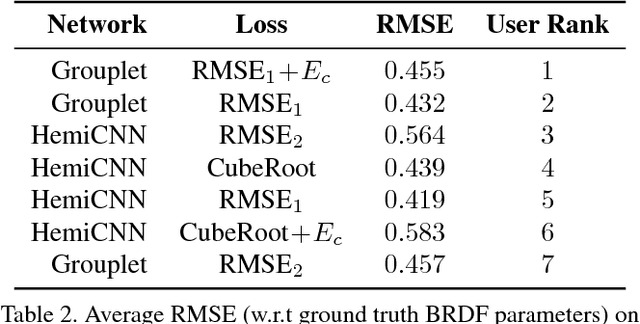
Estimating surface reflectance (BRDF) is one key component for complete 3D scene capture, with wide applications in virtual reality, augmented reality, and human computer interaction. Prior work is either limited to controlled environments (\eg gonioreflectometers, light stages, or multi-camera domes), or requires the joint optimization of shape, illumination, and reflectance, which is often computationally too expensive (\eg hours of running time) for real-time applications. Moreover, most prior work requires HDR images as input which further complicates the capture process. In this paper, we propose a lightweight approach for surface reflectance estimation directly from $8$-bit RGB images in real-time, which can be easily plugged into any 3D scanning-and-fusion system with a commodity RGBD sensor. Our method is learning-based, with an inference time of less than 90ms per scene and a model size of less than 340K bytes. We propose two novel network architectures, HemiCNN and Grouplet, to deal with the unstructured input data from multiple viewpoints under unknown illumination. We further design a loss function to resolve the color-constancy and scale ambiguity. In addition, we have created a large synthetic dataset, SynBRDF, which comprises a total of $500$K RGBD images rendered with a physically-based ray tracer under a variety of natural illumination, covering $5000$ materials and $5000$ shapes. SynBRDF is the first large-scale benchmark dataset for reflectance estimation. Experiments on both synthetic data and real data show that the proposed method effectively recovers surface reflectance, and outperforms prior work for reflectance estimation in uncontrolled environments.
Geometry-Aware Learning of Maps for Camera Localization
Apr 02, 2018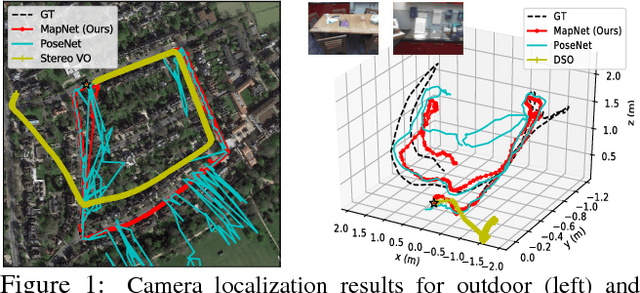

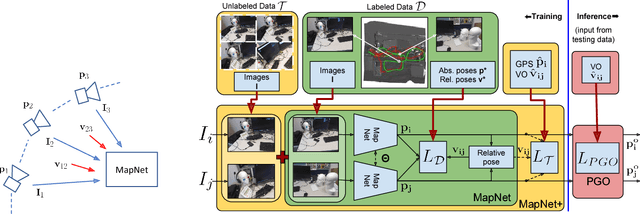
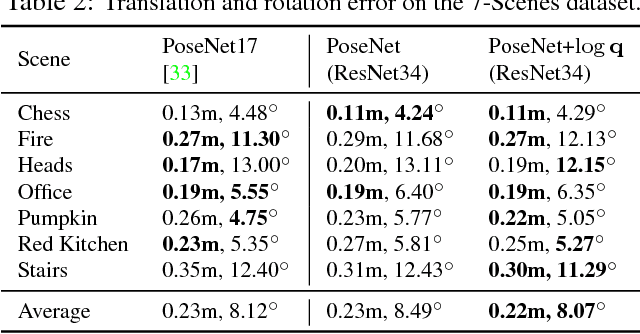
Maps are a key component in image-based camera localization and visual SLAM systems: they are used to establish geometric constraints between images, correct drift in relative pose estimation, and relocalize cameras after lost tracking. The exact definitions of maps, however, are often application-specific and hand-crafted for different scenarios (e.g. 3D landmarks, lines, planes, bags of visual words). We propose to represent maps as a deep neural net called MapNet, which enables learning a data-driven map representation. Unlike prior work on learning maps, MapNet exploits cheap and ubiquitous sensory inputs like visual odometry and GPS in addition to images and fuses them together for camera localization. Geometric constraints expressed by these inputs, which have traditionally been used in bundle adjustment or pose-graph optimization, are formulated as loss terms in MapNet training and also used during inference. In addition to directly improving localization accuracy, this allows us to update the MapNet (i.e., maps) in a self-supervised manner using additional unlabeled video sequences from the scene. We also propose a novel parameterization for camera rotation which is better suited for deep-learning based camera pose regression. Experimental results on both the indoor 7-Scenes dataset and the outdoor Oxford RobotCar dataset show significant performance improvement over prior work. The MapNet project webpage is https://goo.gl/mRB3Au.