 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging End-to-End ASR for Endangered Language Documentation: An Empirical Study on Yoloxóchitl Mixtec
Feb 26, 2021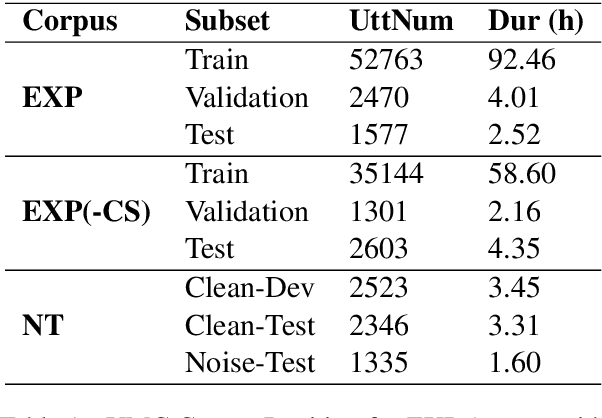
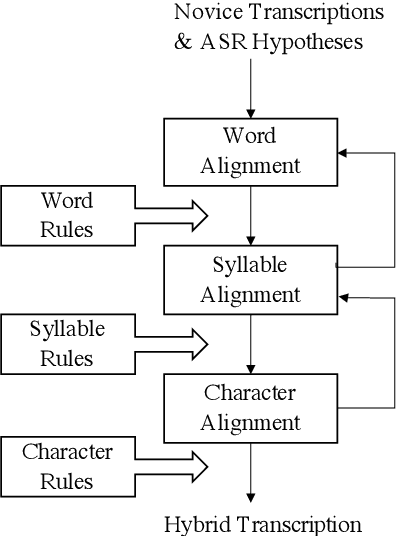

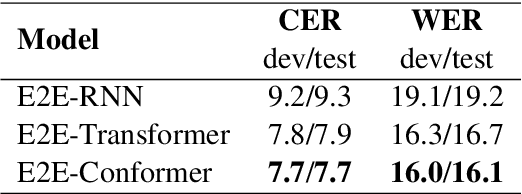
"Transcription bottlenecks", created by a shortage of effective human transcribers are one of the main challenges to endangered language (EL) documentation. Automatic speech recognition (ASR) has been suggested as a tool to overcome such bottlenecks. Following this suggestion, we investigated the effectiveness for EL documentation of end-to-end ASR, which unlike Hidden Markov Model ASR systems, eschews linguistic resources but is instead more dependent on large-data settings. We open source a Yolox\'ochitl Mixtec EL corpus. First, we review our method in building an end-to-end ASR system in a way that would be reproducible by the ASR community. We then propose a novice transcription correction task and demonstrate how ASR systems and novice transcribers can work together to improve EL documentation. We believe this combinatory methodology would mitigate the transcription bottleneck and transcriber shortage that hinders EL documentation.
Orthros: Non-autoregressive End-to-end Speech Translation with Dual-decoder
Nov 06, 2020
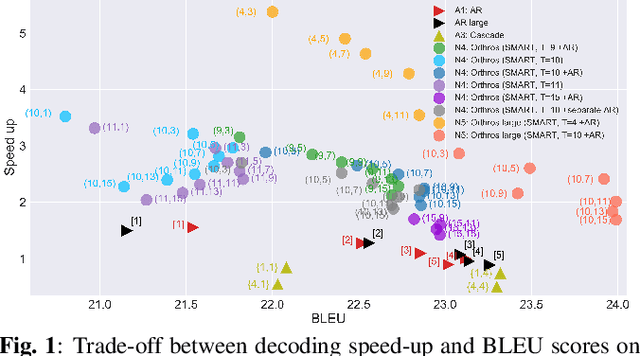
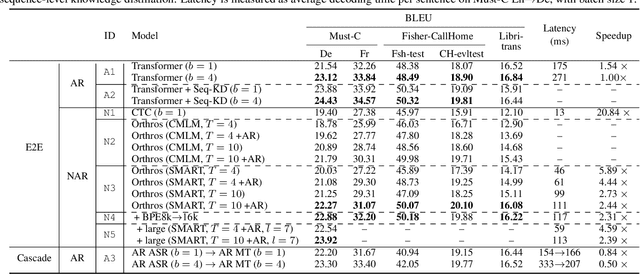
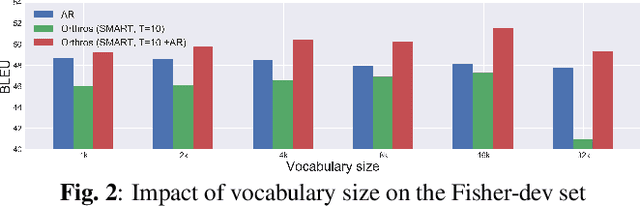
Fast inference speed is an important goal towards real-world deployment of speech translation (ST) systems. End-to-end (E2E) models based on the encoder-decoder architecture are more suitable for this goal than traditional cascaded systems, but their effectiveness regarding decoding speed has not been explored so far. Inspired by recent progress in non-autoregressive (NAR) methods in text-based translation, which generates target tokens in parallel by eliminating conditional dependencies, we study the problem of NAR decoding for E2E-ST. We propose a novel NAR E2E-ST framework, Orthoros, in which both NAR and autoregressive (AR) decoders are jointly trained on the shared speech encoder. The latter is used for selecting better translation among various length candidates generated from the former, which dramatically improves the effectiveness of a large length beam with negligible overhead. We further investigate effective length prediction methods from speech inputs and the impact of vocabulary sizes. Experiments on four benchmarks show the effectiveness of the proposed method in improving inference speed while maintaining competitive translation quality compared to state-of-the-art AR E2E-ST systems.
Very Deep Transformers for Neural Machine Translation
Aug 18, 2020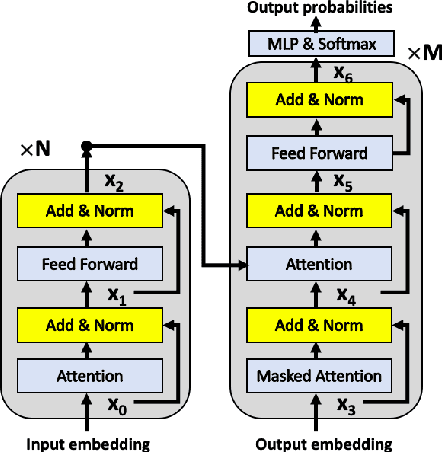
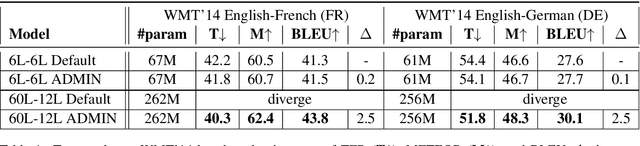
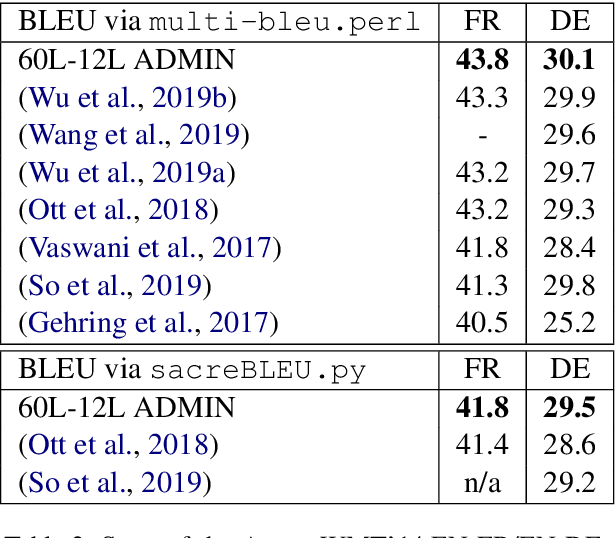
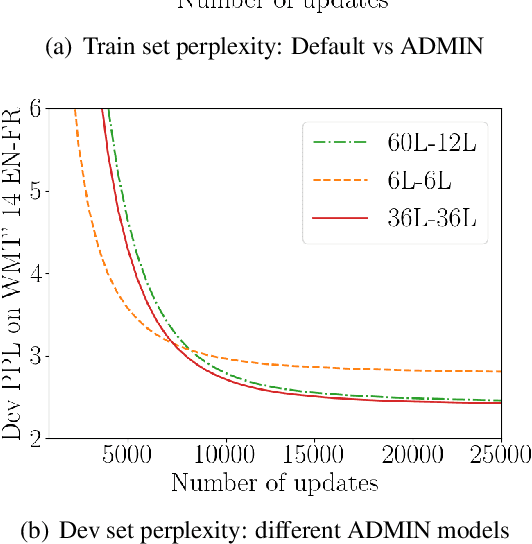
We explore the application of very deep Transformer models for Neural Machine Translation (NMT). Using a simple yet effective initialization technique that stabilizes training, we show that it is feasible to build standard Transformer-based models with up to 60 encoder layers and 12 decoder layers. These deep models outperform their baseline 6-layer counterparts by as much as 2.5 BLEU, and achieve new state-of-the-art benchmark results on WMT14 English-French (43.8 BLEU) and WMT14 English-German (30.1 BLEU).The code and trained models will be publicly available at: https://github.com/namisan/exdeep-nmt.
Modeling Document Interactions for Learning to Rank with Regularized Self-Attention
May 08, 2020
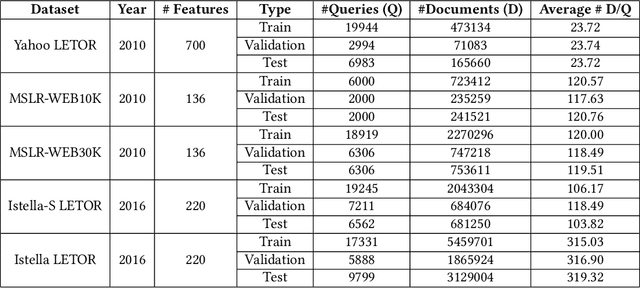
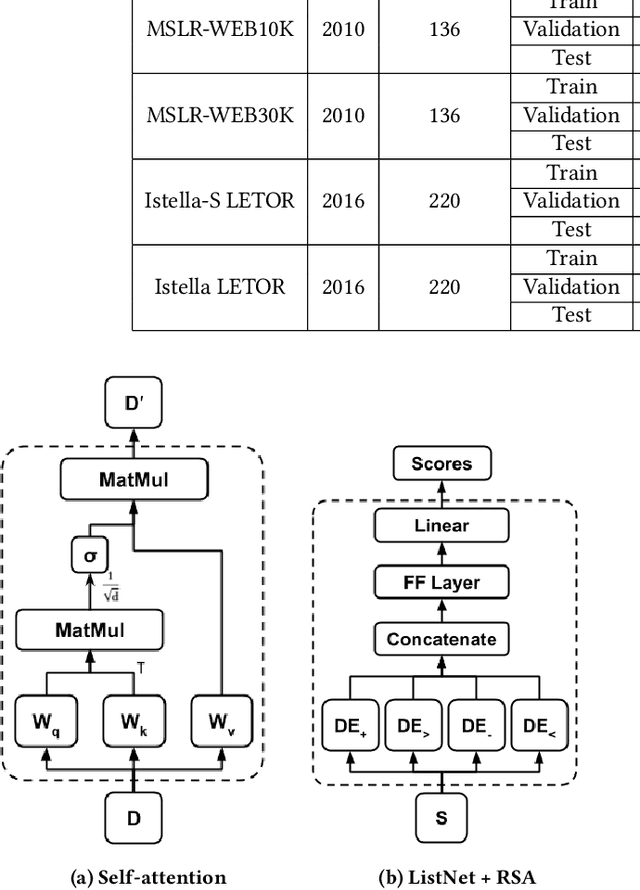
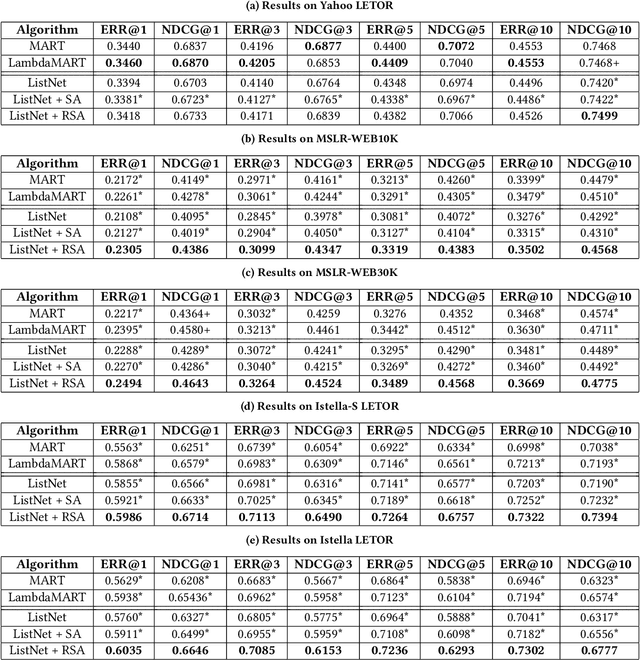
Learning to rank is an important task that has been successfully deployed in many real-world information retrieval systems. Most existing methods compute relevance judgments of documents independently, without holistically considering the entire set of competing documents. In this paper, we explore modeling documents interactions with self-attention based neural networks. Although self-attention networks have achieved state-of-the-art results in many NLP tasks, we find empirically that self-attention provides little benefit over baseline neural learning to rank architecture. To improve the learning of self-attention weights, We propose simple yet effective regularization terms designed to model interactions between documents. Evaluations on publicly available Learning to Rank (LETOR) datasets show that training self-attention network with our proposed regularization terms can significantly outperform existing learning to rank methods.
ESPnet-ST: All-in-One Speech Translation Toolkit
Apr 21, 2020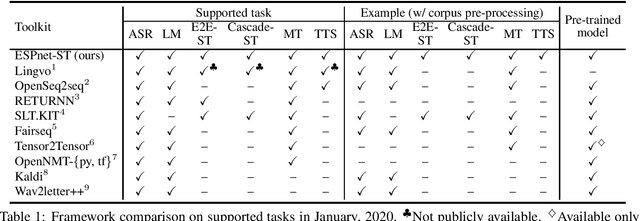
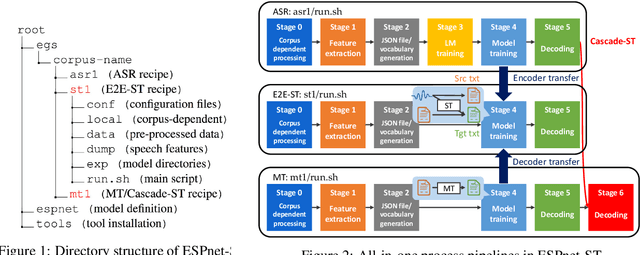


We present ESPnet-ST, which is designed for the quick development of speech-to-speech translation systems in a single framework. ESPnet-ST is a new project inside end-to-end speech processing toolkit, ESPnet, which integrates or newly implements automatic speech recognition, machine translation, and text-to-speech functions for speech translation. We provide all-in-one recipes including data pre-processing, feature extraction, training, and decoding pipelines for a wide range of benchmark datasets. Our reproducible results can match or even outperform the current state-of-the-art performances; these pre-trained models are downloadable. The toolkit is publicly available at https://github.com/espnet/espnet.
When Does Unsupervised Machine Translation Work?
Apr 14, 2020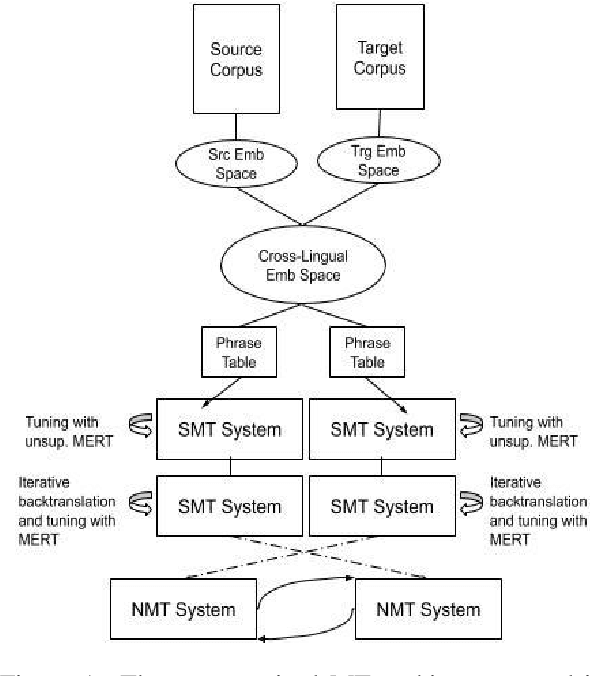
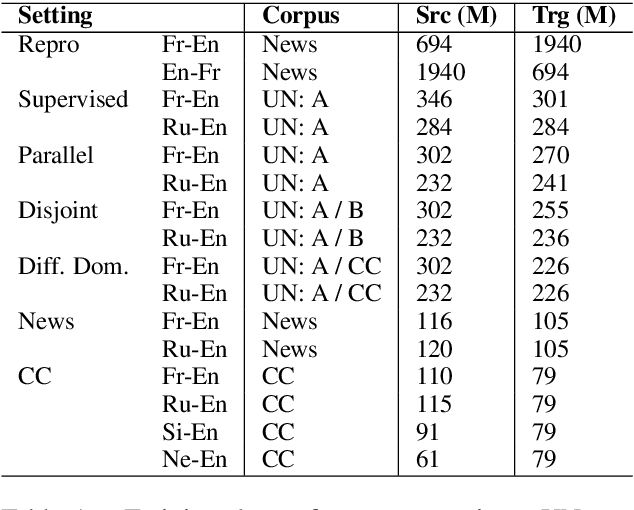
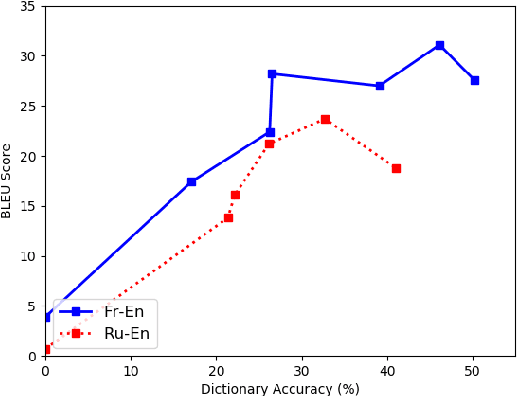

Despite the reported success of unsupervised machine translation (MT), the field has yet to examine the conditions under which these methods succeed, and where they fail. We conduct an extensive empirical evaluation of unsupervised MT using dissimilar language pairs, dissimilar domains, diverse datasets, and authentic low-resource languages. We find that performance rapidly deteriorates when source and target corpora are from different domains, and that random word embedding initialization can dramatically affect downstream translation performance. We additionally find that unsupervised MT performance declines when source and target languages use different scripts, and observe very poor performance on authentic low-resource language pairs. We advocate for extensive empirical evaluation of unsupervised MT systems to highlight failure points and encourage continued research on the most promising paradigms.
Distill, Adapt, Distill: Training Small, In-Domain Models for Neural Machine Translation
Mar 05, 2020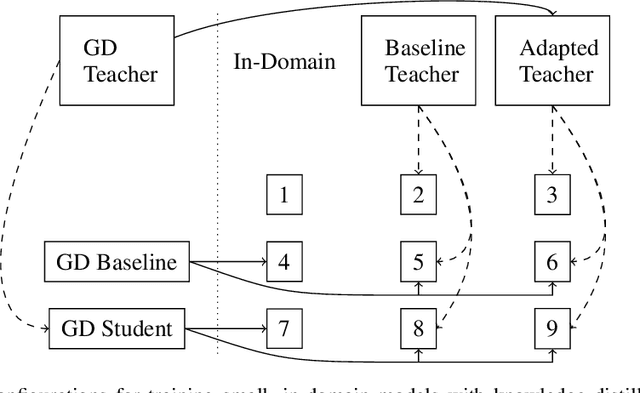

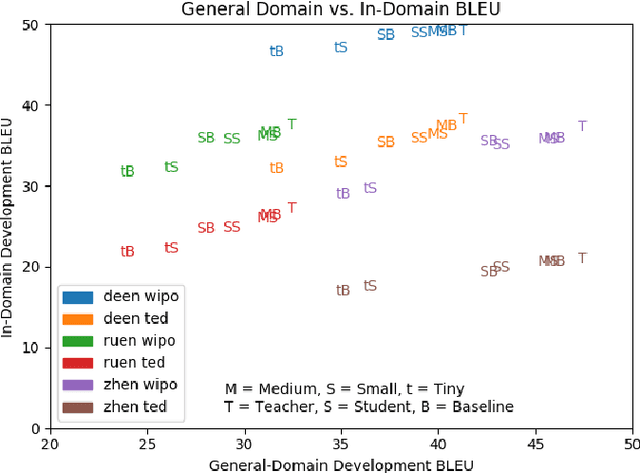
We explore best practices for training small, memory efficient machine translation models with sequence-level knowledge distillation in the domain adaptation setting. While both domain adaptation and knowledge distillation are widely-used, their interaction remains little understood. Our large-scale empirical results in machine translation (on three language pairs with three domains each) suggest distilling twice for best performance: once using general-domain data and again using in-domain data with an adapted teacher.
Machine Translation System Selection from Bandit Feedback
Feb 22, 2020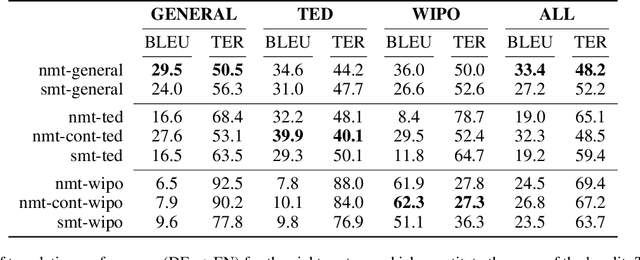
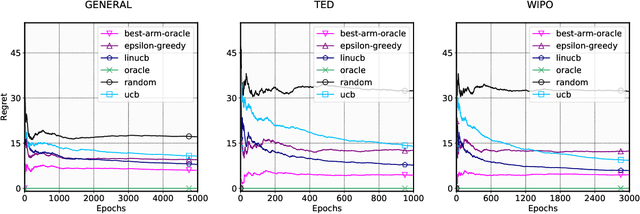
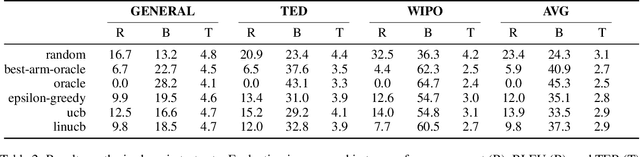
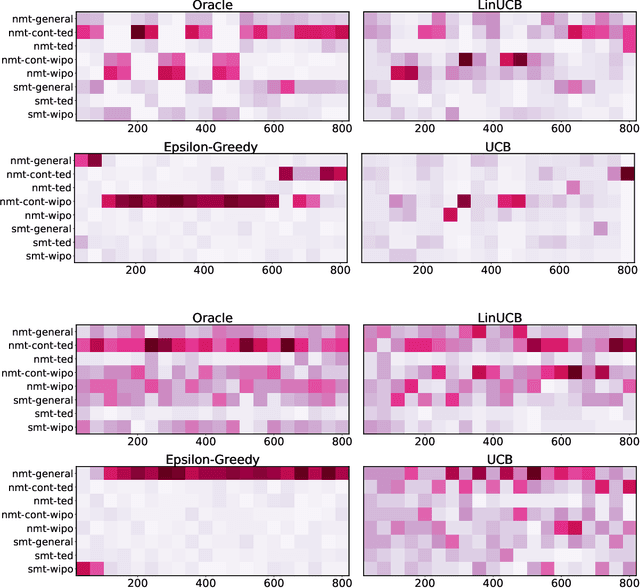
Adapting machine translation systems in the real world is a difficult problem. In contrast to offline training, users cannot provide the type of fine-grained feedback typically used for improving the system. Moreover, users have different translation needs, and even a single user's needs may change over time. In this work we take a different approach, treating the problem of adapting as one of selection. Instead of adapting a single system, we train many translation systems using different architectures and data partitions. Using bandit learning techniques on simulated user feedback, we learn a policy to choose which system to use for a particular translation task. We show that our approach can (1) quickly adapt to address domain changes in translation tasks, (2) outperform the single best system in mixed-domain translation tasks, and (3) make effective instance-specific decisions when using contextual bandit strategies.
Compressing BERT: Studying the Effects of Weight Pruning on Transfer Learning
Feb 19, 2020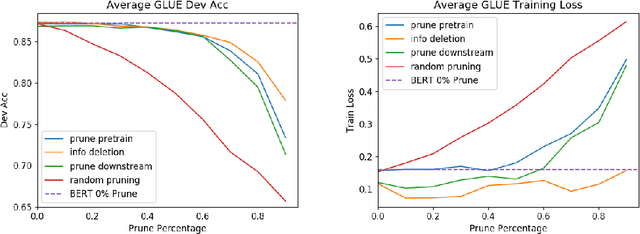
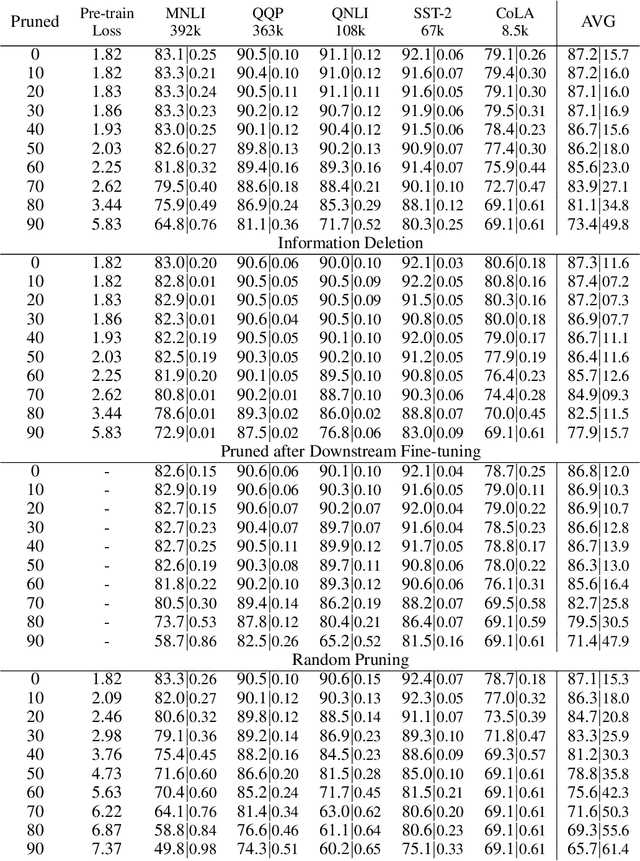
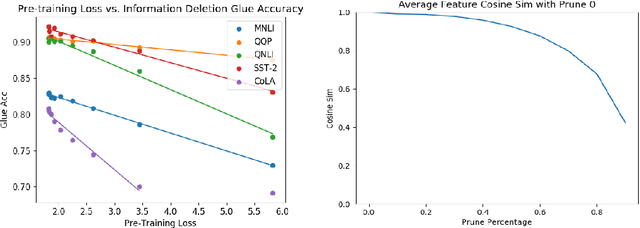
Universal feature extractors, such as BERT for natural language processing and VGG for computer vision, have become effective methods for improving deep learning models without requiring more labeled data. A common paradigm is to pre-train a feature extractor on large amounts of data then fine-tune it as part of a deep learning model on some downstream task (i.e. transfer learning). While effective, feature extractors like BERT may be prohibitively large for some deployment scenarios. We explore weight pruning for BERT and ask: how does compression during pre-training affect transfer learning? We find that pruning affects transfer learning in three broad regimes. Low levels of pruning (30-40\%) do not affect pre-training loss or transfer to downstream tasks at all. Medium levels of pruning increase the pre-training loss and prevent useful pre-training information from being transferred to downstream tasks. High levels of pruning additionally prevent models from fitting downstream datasets, leading to further degradation. Finally, we observe that fine-tuning BERT on a specific task does not improve its prunability. We conclude that BERT can be pruned once during pre-training rather than separately for each task without affecting performance.
Explaining Sequence-Level Knowledge Distillation as Data-Augmentation for Neural Machine Translation
Dec 06, 2019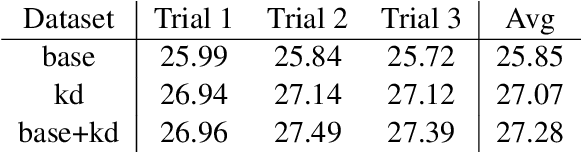
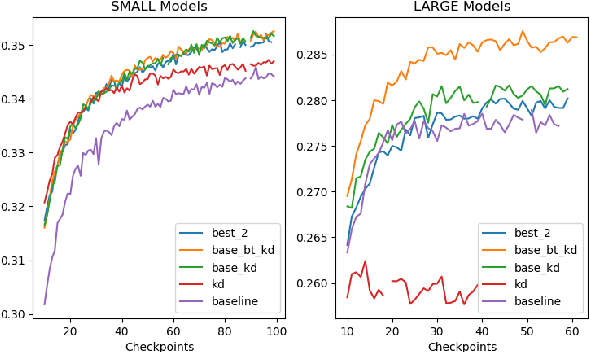
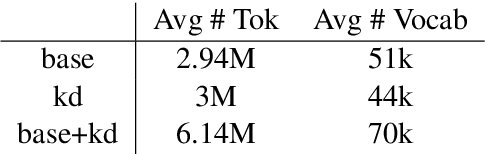
Sequence-level knowledge distillation (SLKD) is a model compression technique that leverages large, accurate teacher models to train smaller, under-parameterized student models. Why does pre-processing MT data with SLKD help us train smaller models? We test the common hypothesis that SLKD addresses a capacity deficiency in students by "simplifying" noisy data points and find it unlikely in our case. Models trained on concatenations of original and "simplified" datasets generalize just as well as baseline SLKD. We then propose an alternative hypothesis under the lens of data augmentation and regularization. We try various augmentation strategies and observe that dropout regularization can become unnecessary. Our methods achieve BLEU gains of 0.7-1.2 on TED Talks.