 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Translation System Selection from Bandit Feedback
Paper and Code
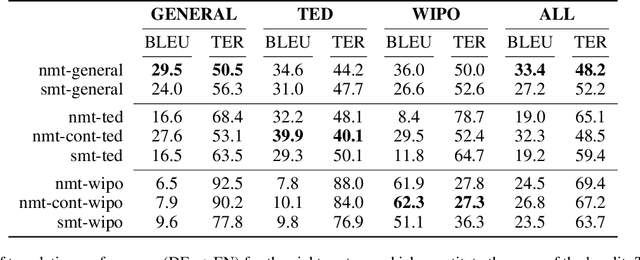
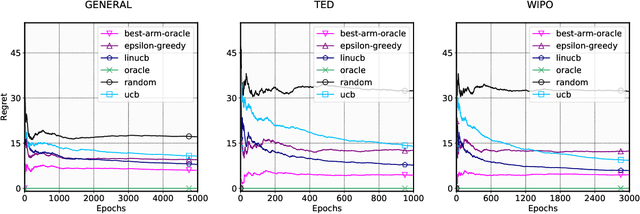
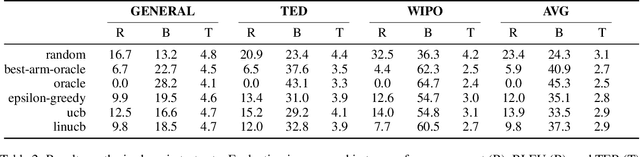
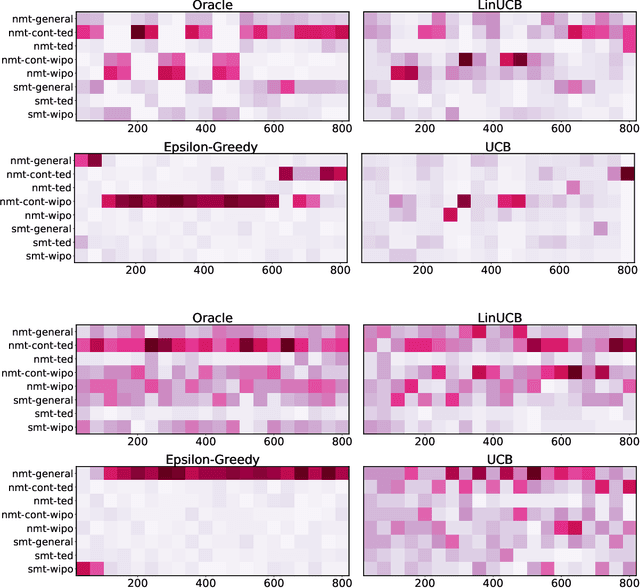
Adapting machine translation systems in the real world is a difficult problem. In contrast to offline training, users cannot provide the type of fine-grained feedback typically used for improving the system. Moreover, users have different translation needs, and even a single user's needs may change over time. In this work we take a different approach, treating the problem of adapting as one of selection. Instead of adapting a single system, we train many translation systems using different architectures and data partitions. Using bandit learning techniques on simulated user feedback, we learn a policy to choose which system to use for a particular translation task. We show that our approach can (1) quickly adapt to address domain changes in translation tasks, (2) outperform the single best system in mixed-domain translation tasks, and (3) make effective instance-specific decisions when using contextual bandit strategies.