 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill, Adapt, Distill: Training Small, In-Domain Models for Neural Machine Translation
Mar 05, 2020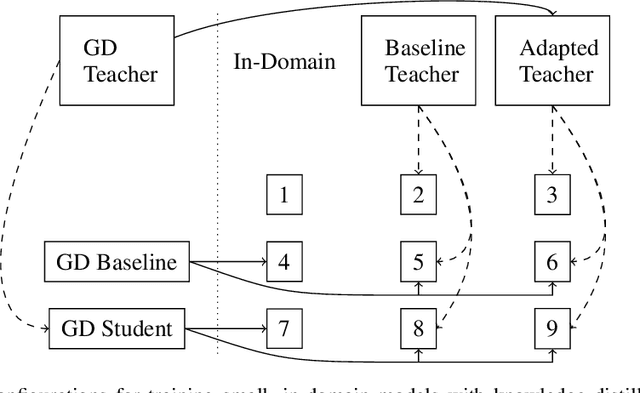

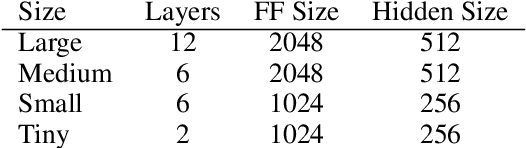
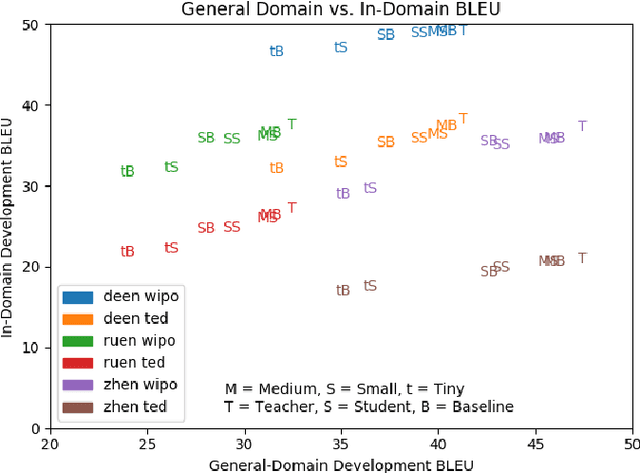
We explore best practices for training small, memory efficient machine translation models with sequence-level knowledge distillation in the domain adaptation setting. While both domain adaptation and knowledge distillation are widely-used, their interaction remains little understood. Our large-scale empirical results in machine translation (on three language pairs with three domains each) suggest distilling twice for best performance: once using general-domain data and again using in-domain data with an adapted teacher.
Compressing BERT: Studying the Effects of Weight Pruning on Transfer Learning
Feb 19, 2020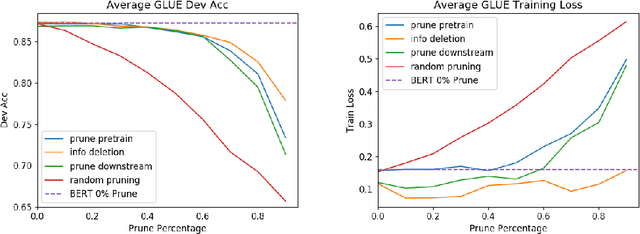
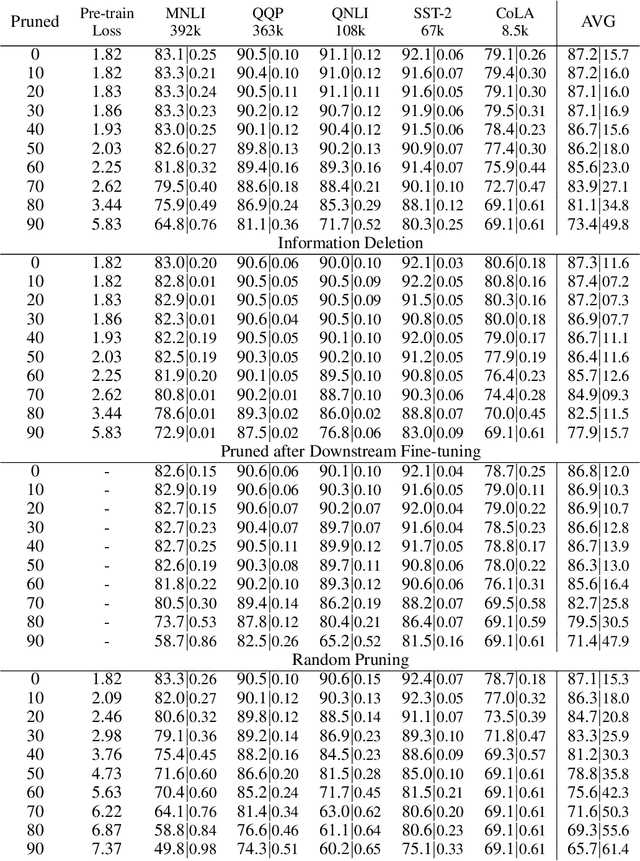
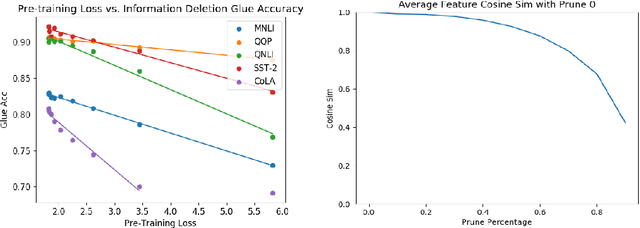
Universal feature extractors, such as BERT for natural language processing and VGG for computer vision, have become effective methods for improving deep learning models without requiring more labeled data. A common paradigm is to pre-train a feature extractor on large amounts of data then fine-tune it as part of a deep learning model on some downstream task (i.e. transfer learning). While effective, feature extractors like BERT may be prohibitively large for some deployment scenarios. We explore weight pruning for BERT and ask: how does compression during pre-training affect transfer learning? We find that pruning affects transfer learning in three broad regimes. Low levels of pruning (30-40\%) do not affect pre-training loss or transfer to downstream tasks at all. Medium levels of pruning increase the pre-training loss and prevent useful pre-training information from being transferred to downstream tasks. High levels of pruning additionally prevent models from fitting downstream datasets, leading to further degradation. Finally, we observe that fine-tuning BERT on a specific task does not improve its prunability. We conclude that BERT can be pruned once during pre-training rather than separately for each task without affecting performance.
Explaining Sequence-Level Knowledge Distillation as Data-Augmentation for Neural Machine Translation
Dec 06, 2019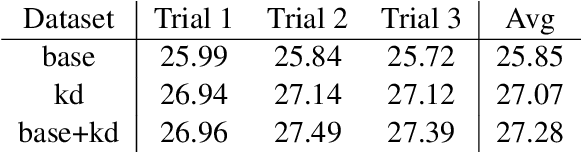
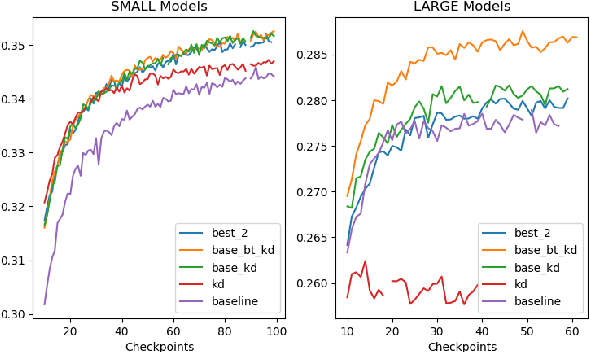
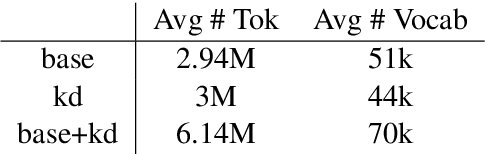
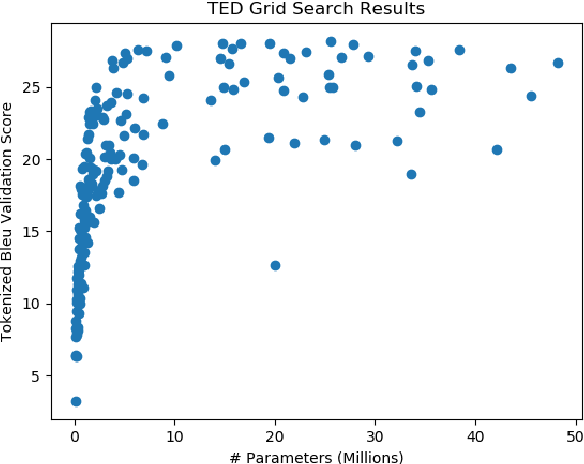
Sequence-level knowledge distillation (SLKD) is a model compression technique that leverages large, accurate teacher models to train smaller, under-parameterized student models. Why does pre-processing MT data with SLKD help us train smaller models? We test the common hypothesis that SLKD addresses a capacity deficiency in students by "simplifying" noisy data points and find it unlikely in our case. Models trained on concatenations of original and "simplified" datasets generalize just as well as baseline SLKD. We then propose an alternative hypothesis under the lens of data augmentation and regularization. We try various augmentation strategies and observe that dropout regularization can become unnecessary. Our methods achieve BLEU gains of 0.7-1.2 on TED Talks.