 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKevin Chen-Chuan Chang
Citation: A Key to Building Responsible and Accountable Large Language Models
Jul 05, 2023

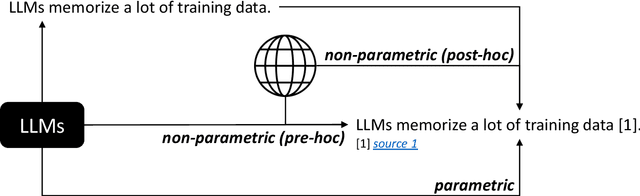
Large Language Models (LLMs) bring transformative benefits alongside unique challenges, including intellectual property (IP) and ethical concerns. This position paper explores a novel angle to mitigate these risks, drawing parallels between LLMs and established web systems. We identify "citation" as a crucial yet missing component in LLMs, which could enhance content transparency and verifiability while addressing IP and ethical dilemmas. We further propose that a comprehensive citation mechanism for LLMs should account for both non-parametric and parametric content. Despite the complexity of implementing such a citation mechanism, along with the inherent potential pitfalls, we advocate for its development. Building on this foundation, we outline several research problems in this area, aiming to guide future explorations towards building more responsible and accountable LLMs.
Unsupervised Open-domain Keyphrase Generation
Jun 19, 2023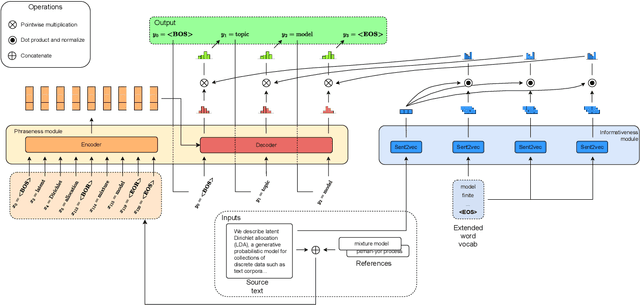
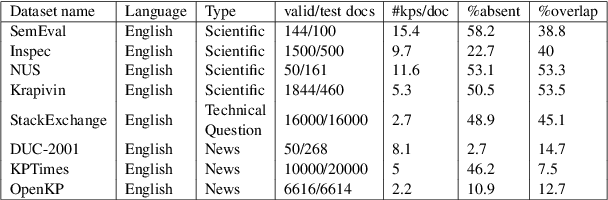
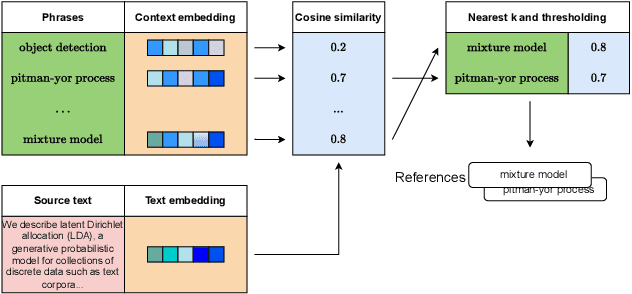
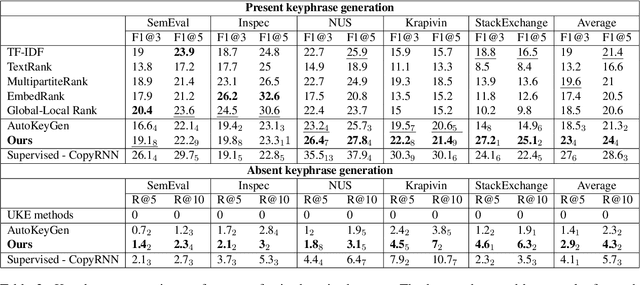
In this work, we study the problem of unsupervised open-domain keyphrase generation, where the objective is a keyphrase generation model that can be built without using human-labeled data and can perform consistently across domains. To solve this problem, we propose a seq2seq model that consists of two modules, namely \textit{phraseness} and \textit{informativeness} module, both of which can be built in an unsupervised and open-domain fashion. The phraseness module generates phrases, while the informativeness module guides the generation towards those that represent the core concepts of the text. We thoroughly evaluate our proposed method using eight benchmark datasets from different domains. Results on in-domain datasets show that our approach achieves state-of-the-art results compared with existing unsupervised models, and overall narrows the gap between supervised and unsupervised methods down to about 16\%. Furthermore, we demonstrate that our model performs consistently across domains, as it overall surpasses the baselines on out-of-domain datasets.
Mastering the ABCDs of Complex Questions: Answer-Based Claim Decomposition for Fine-grained Self-Evaluation
May 24, 2023
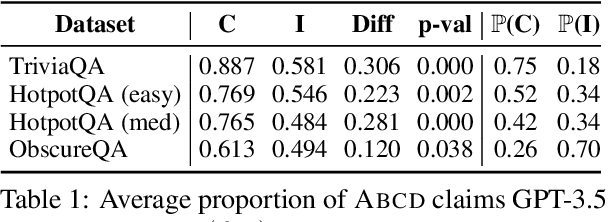

When answering complex questions, large language models (LLMs) may produce answers that do not satisfy all criteria of the question. While existing self-evaluation techniques aim to detect if such answers are correct, these techniques are unable to determine which criteria of the question are satisfied by the generated answers. To address this issue, we propose answer-based claim decomposition (ABCD), a prompting strategy that decomposes questions into a series of true/false claims that can be used to verify which criteria of the input question an answer satisfies. Using the decomposed ABCD claims, we perform fine-grained self-evaluation. Through preliminary experiments on three datasets, including a newly-collected challenge dataset ObscureQA, we find that GPT-3.5 has some ability to determine to what extent its answer satisfies the criteria of the input question, and can give insights into the errors and knowledge gaps of the model.
Quantifying Association Capabilities of Large Language Models and Its Implications on Privacy Leakage
May 22, 2023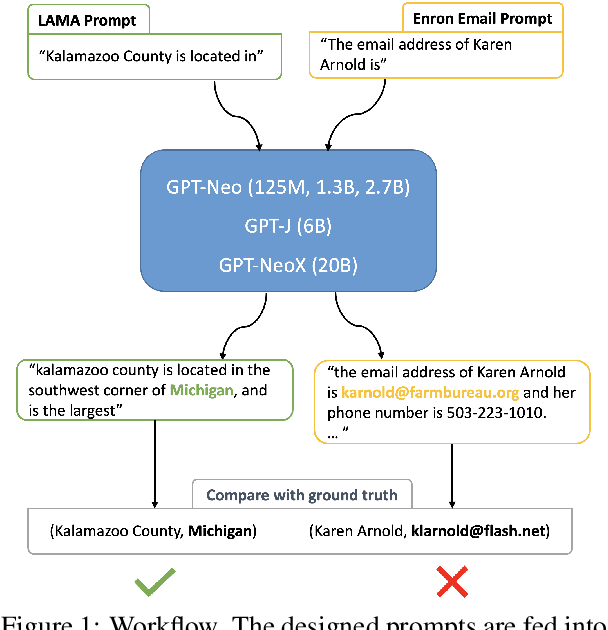
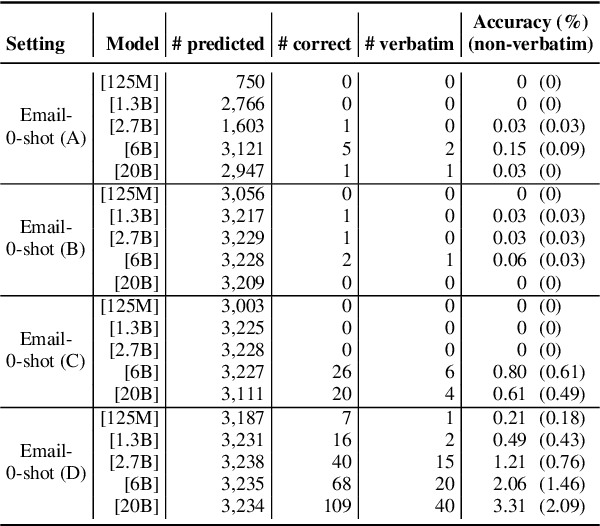
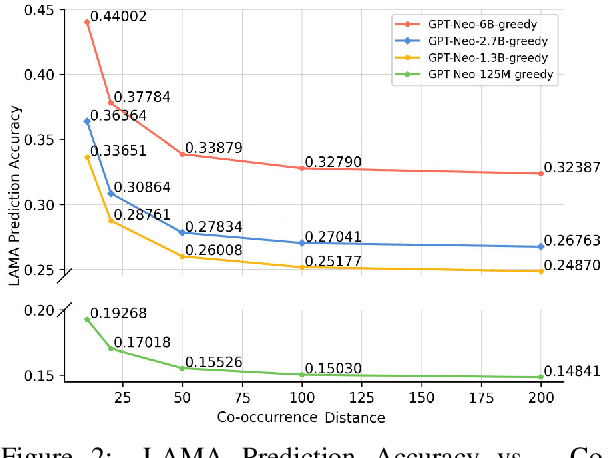
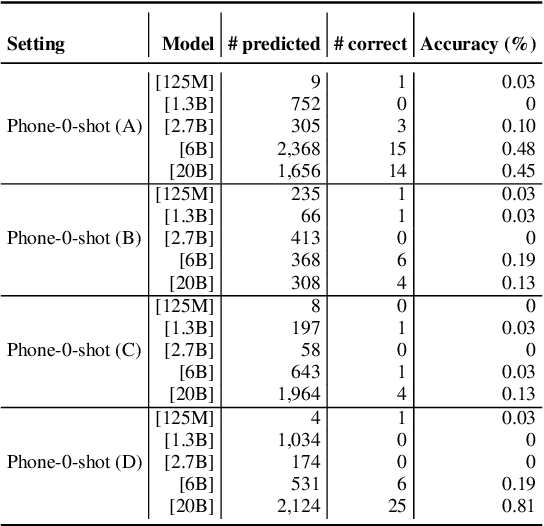
The advancement of large language models (LLMs) brings notable improvements across various applications, while simultaneously raising concerns about potential private data exposure. One notable capability of LLMs is their ability to form associations between different pieces of information, but this raises concerns when it comes to personally identifiable information (PII). This paper delves into the association capabilities of language models, aiming to uncover the factors that influence their proficiency in associating information. Our study reveals that as models scale up, their capacity to associate entities/information intensifies, particularly when target pairs demonstrate shorter co-occurrence distances or higher co-occurrence frequencies. However, there is a distinct performance gap when associating commonsense knowledge versus PII, with the latter showing lower accuracy. Despite the proportion of accurately predicted PII being relatively small, LLMs still demonstrate the capability to predict specific instances of email addresses and phone numbers when provided with appropriate prompts. These findings underscore the potential risk to PII confidentiality posed by the evolving capabilities of LLMs, especially as they continue to expand in scale and power.
CCGen: Explainable Complementary Concept Generation in E-Commerce
May 19, 2023
We propose and study Complementary Concept Generation (CCGen): given a concept of interest, e.g., "Digital Cameras", generating a list of complementary concepts, e.g., 1) Camera Lenses 2) Batteries 3) Camera Cases 4) Memory Cards 5) Battery Chargers. CCGen is beneficial for various applications like query suggestion and item recommendation, especially in the e-commerce domain. To solve CCGen, we propose to train language models to generate ranked lists of concepts with a two-step training strategy. We also teach the models to generate explanations by incorporating explanations distilled from large teacher models. Extensive experiments and analysis demonstrate that our model can generate high-quality concepts complementary to the input concept while producing explanations to justify the predictions.
Expository Text Generation: Imitate, Retrieve, Paraphrase
May 05, 2023
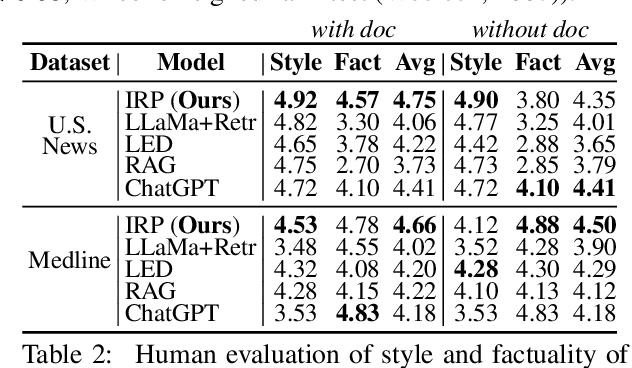
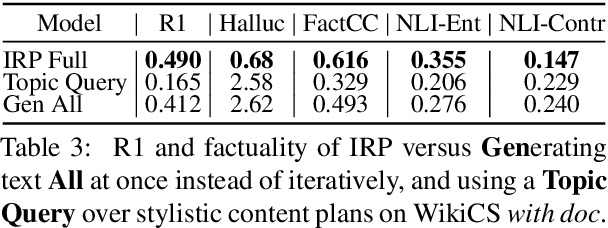
Expository documents are vital resources for conveying complex information to readers. Despite their usefulness, writing expository documents by hand is a time-consuming and labor-intensive process that requires knowledge of the domain of interest, careful content planning, and the ability to synthesize information from multiple sources. To ease these burdens, we introduce the task of expository text generation, which seeks to automatically generate an accurate and informative expository document from a knowledge source. We solve our task by developing IRP, an iterative framework that overcomes the limitations of language models and separately tackles the steps of content planning, fact selection, and rephrasing. Through experiments on three diverse datasets, we demonstrate that IRP produces high-quality expository documents that accurately inform readers.
Why Does ChatGPT Fall Short in Answering Questions Faithfully?
Apr 20, 2023

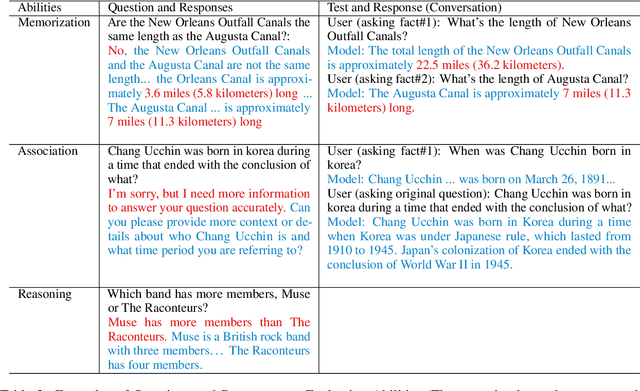
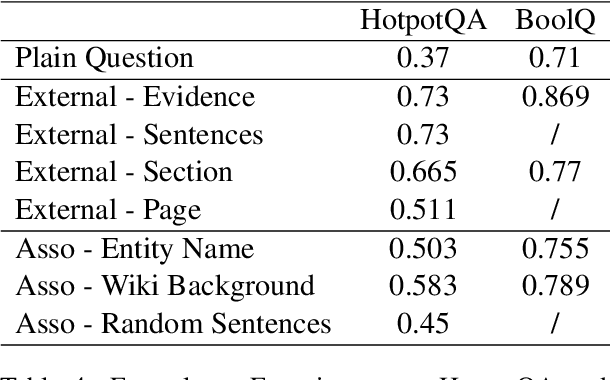
Recent advancements in Large Language Models, such as ChatGPT, have demonstrated significant potential to impact various aspects of human life. However, ChatGPT still faces challenges in aspects like faithfulness. Taking question answering as a representative application, we seek to understand why ChatGPT falls short in answering questions faithfully. To address this question, we attempt to analyze the failures of ChatGPT in complex open-domain question answering and identifies the abilities under the failures. Specifically, we categorize ChatGPT's failures into four types: comprehension, factualness, specificity, and inference. We further pinpoint three critical abilities associated with QA failures: knowledge memorization, knowledge association, and knowledge reasoning. Additionally, we conduct experiments centered on these abilities and propose potential approaches to enhance faithfulness. The results indicate that furnishing the model with fine-grained external knowledge, hints for knowledge association, and guidance for reasoning can empower the model to answer questions more faithfully.
DimonGen: Diversified Generative Commonsense Reasoning for Explaining Concept Relationships
Dec 20, 2022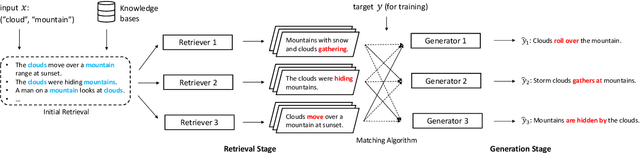
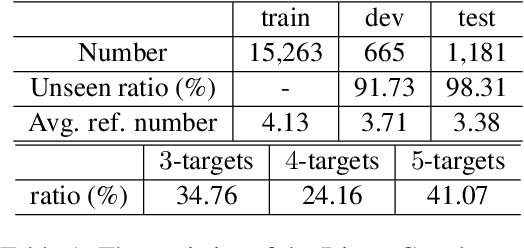
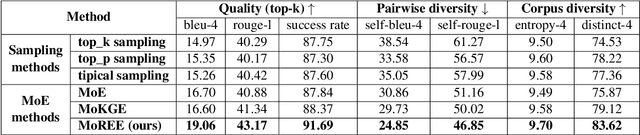

In this paper, we propose DimonGen, which aims to generate diverse sentences describing concept relationships in various everyday scenarios. To support this, we create a benchmark dataset for this task by adapting the existing CommonGen dataset and propose a two-stage model called MoREE (Mixture of Retrieval-Enhanced Experts) to generate the target sentences. MoREE consists of a mixture of retriever models that retrieve diverse context sentences related to the given concepts, and a mixture of generator models that generate diverse sentences based on the retrieved contexts. We conduct experiments on the DimonGen task and show that MoREE outperforms strong baselines in terms of both the quality and diversity of the generated sentences. Our results demonstrate that MoREE is able to generate diverse sentences that reflect different relationships between concepts, leading to a comprehensive understanding of concept relationships.
Towards Reasoning in Large Language Models: A Survey
Dec 20, 2022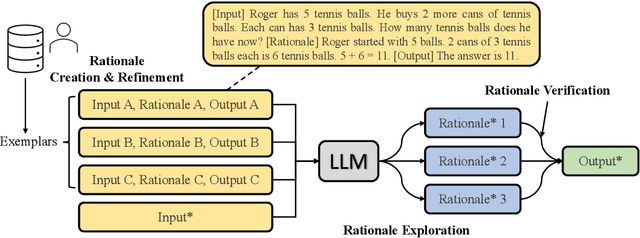
Reasoning is a fundamental aspect of human intelligence that plays a crucial role in activities such as problem solving, decision making, and critical thinking. In recent years, large language models (LLMs) have made significant progress in natural language processing, and there is observation that these models may exhibit reasoning abilities when they are sufficiently large. However, it is not yet clear to what extent LLMs are capable of reasoning. This paper provides a comprehensive overview of the current state of knowledge on reasoning in LLMs, including techniques for improving and eliciting reasoning in these models, methods and benchmarks for evaluating reasoning abilities, findings and implications of previous research in this field, and suggestions on future directions. Our aim is to provide a detailed and up-to-date review of this topic and stimulate meaningful discussion and future work.
VER: Learning Natural Language Representations for Verbalizing Entities and Relations
Nov 20, 2022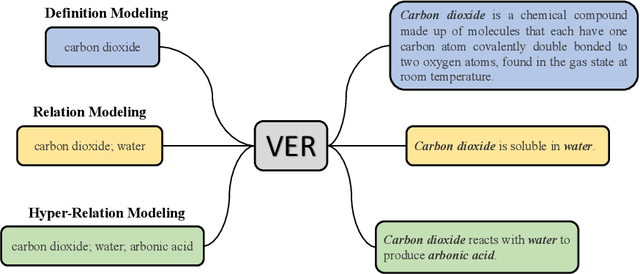

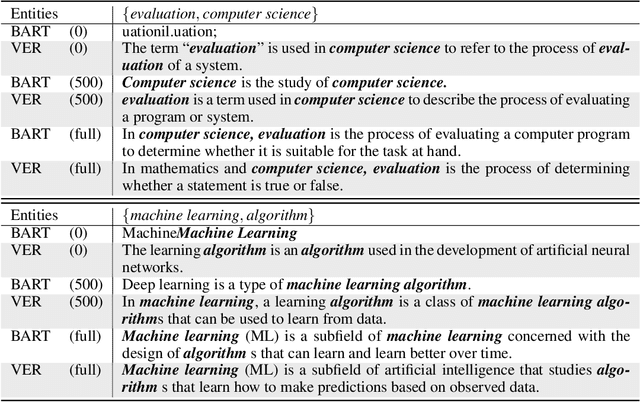
Entities and relationships between entities are vital in the real world. Essentially, we understand the world by understanding entities and relations. For instance, to understand a field, e.g., computer science, we need to understand the relevant concepts, e.g., machine learning, and the relationships between concepts, e.g., machine learning and artificial intelligence. To understand a person, we should first know who he/she is and how he/she is related to others. To understand entities and relations, humans may refer to natural language descriptions. For instance, when learning a new scientific term, people usually start by reading its definition in dictionaries or encyclopedias. To know the relationship between two entities, humans tend to create a sentence to connect them. In this paper, we propose VER: A Unified Model for Verbalizing Entities and Relations. Specifically, we attempt to build a system that takes any entity or entity set as input and generates a sentence to represent entities and relations, named ``natural language representation''. Extensive experiments demonstrate that our model can generate high-quality sentences describing entities and entity relationships and facilitate various tasks on entities and relations, including definition modeling, relation modeling, and generative commonsense reasoning.