 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentionRetriever: Attention Layers are Secretly Long Document Retrievers
Feb 12, 2026Retrieval augmented generation (RAG) has been widely adopted to help Large Language Models (LLMs) to process tasks involving long documents. However, existing retrieval models are not designed for long document retrieval and fail to address several key challenges of long document retrieval, including context-awareness, causal dependence, and scope of retrieval. In this paper, we proposed AttentionRetriever, a novel long document retrieval model that leverages attention mechanism and entity-based retrieval to build context-aware embeddings for long document and determine the scope of retrieval. With extensive experiments, we found AttentionRetriever is able to outperform existing retrieval models on long document retrieval datasets by a large margin while remaining as efficient as dense retrieval models.
IRB: Automated Generation of Robust Factuality Benchmarks
Feb 08, 2026Static benchmarks for RAG systems often suffer from rapid saturation and require significant manual effort to maintain robustness. To address this, we present IRB, a framework for automatically generating benchmarks to evaluate the factuality of RAG systems. IRB employs a structured generation pipeline utilizing \textit{factual scaffold} and \textit{algorithmic scaffold}. We utilize IRB to construct a benchmark and evaluate frontier LLMs and retrievers. Our results demonstrate that IRB poses a significant challenge for frontier LLMs in the closed-book setting. Furthermore, our evaluation suggests that reasoning LLMs are more reliable, and that improving the retrieval component may yield more cost-effective gains in RAG system correctness than scaling the generator.
ERU-KG: Efficient Reference-aligned Unsupervised Keyphrase Generation
May 30, 2025Unsupervised keyphrase prediction has gained growing interest in recent years. However, existing methods typically rely on heuristically defined importance scores, which may lead to inaccurate informativeness estimation. In addition, they lack consideration for time efficiency. To solve these problems, we propose ERU-KG, an unsupervised keyphrase generation (UKG) model that consists of an informativeness and a phraseness module. The former estimates the relevance of keyphrase candidates, while the latter generate those candidates. The informativeness module innovates by learning to model informativeness through references (e.g., queries, citation contexts, and titles) and at the term-level, thereby 1) capturing how the key concepts of documents are perceived in different contexts and 2) estimating informativeness of phrases more efficiently by aggregating term informativeness, removing the need for explicit modeling of the candidates. ERU-KG demonstrates its effectiveness on keyphrase generation benchmarks by outperforming unsupervised baselines and achieving on average 89\% of the performance of a supervised model for top 10 predictions. Additionally, to highlight its practical utility, we evaluate the model on text retrieval tasks and show that keyphrases generated by ERU-KG are effective when employed as query and document expansions. Furthermore, inference speed tests reveal that ERU-KG is the fastest among baselines of similar model sizes. Finally, our proposed model can switch between keyphrase generation and extraction by adjusting hyperparameters, catering to diverse application requirements.
Unsupervised Open-domain Keyphrase Generation
Jun 19, 2023In this work, we study the problem of unsupervised open-domain keyphrase generation, where the objective is a keyphrase generation model that can be built without using human-labeled data and can perform consistently across domains. To solve this problem, we propose a seq2seq model that consists of two modules, namely \textit{phraseness} and \textit{informativeness} module, both of which can be built in an unsupervised and open-domain fashion. The phraseness module generates phrases, while the informativeness module guides the generation towards those that represent the core concepts of the text. We thoroughly evaluate our proposed method using eight benchmark datasets from different domains. Results on in-domain datasets show that our approach achieves state-of-the-art results compared with existing unsupervised models, and overall narrows the gap between supervised and unsupervised methods down to about 16\%. Furthermore, we demonstrate that our model performs consistently across domains, as it overall surpasses the baselines on out-of-domain datasets.
MAGNeto: An Efficient Deep Learning Method for the Extractive Tags Summarization Problem
Nov 09, 2020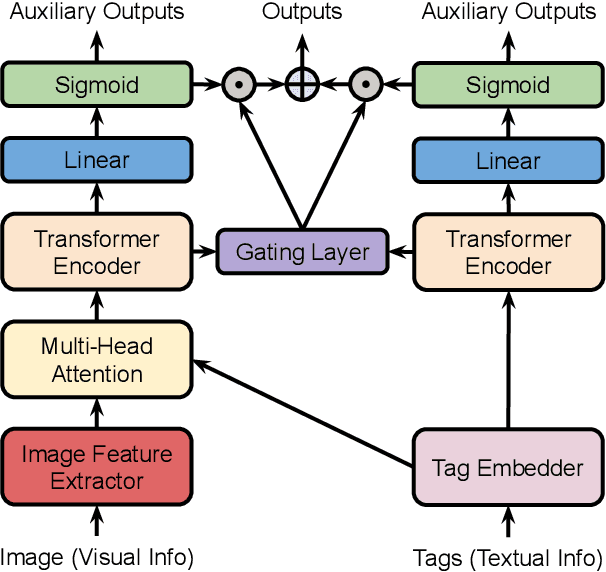

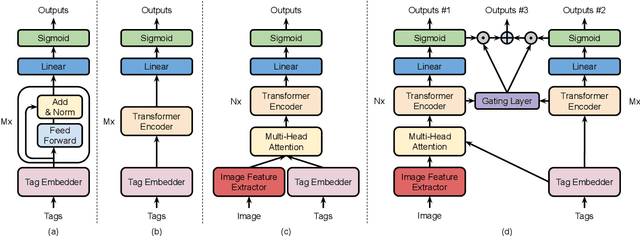
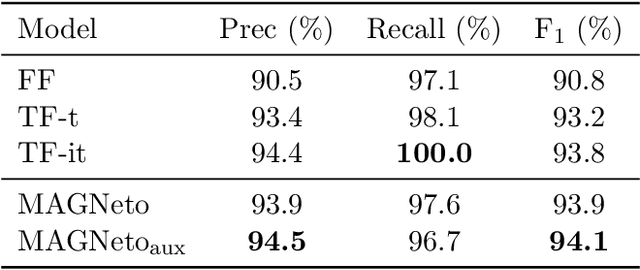
In this work, we study a new image annotation task named Extractive Tags Summarization (ETS). The goal is to extract important tags from the context lying in an image and its corresponding tags. We adjust some state-of-the-art deep learning models to utilize both visual and textual information. Our proposed solution consists of different widely used blocks like convolutional and self-attention layers, together with a novel idea of combining auxiliary loss functions and the gating mechanism to glue and elevate these fundamental components and form a unified architecture. Besides, we introduce a loss function that aims to reduce the imbalance of the training data and a simple but effective data augmentation technique dedicated to alleviates the effect of outliers on the final results. Last but not least, we explore an unsupervised pre-training strategy to further boost the performance of the model by making use of the abundant amount of available unlabeled data. Our model shows the good results as 90% $F_\text{1}$ score on the public NUS-WIDE benchmark, and 50% $F_\text{1}$ score on a noisy large-scale real-world private dataset. Source code for reproducing the experiments is publicly available at: https://github.com/pixta-dev/labteam