 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Distributional Reinforcement Learning: Regularization, Optimization, Acceleration and Sinkhorn Algorithm
Oct 07, 2021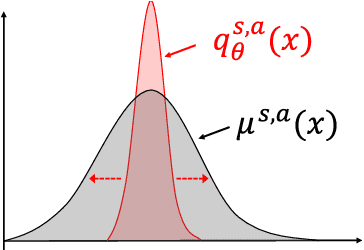
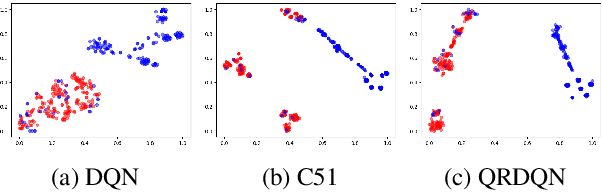
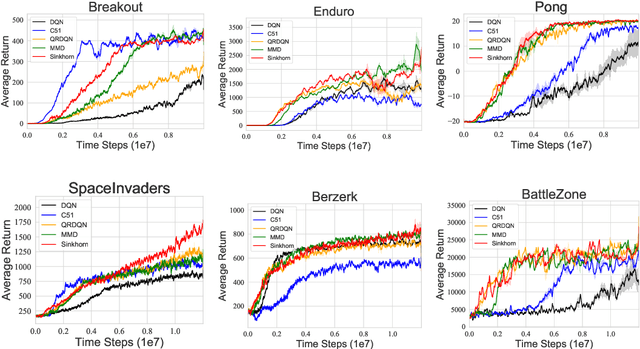
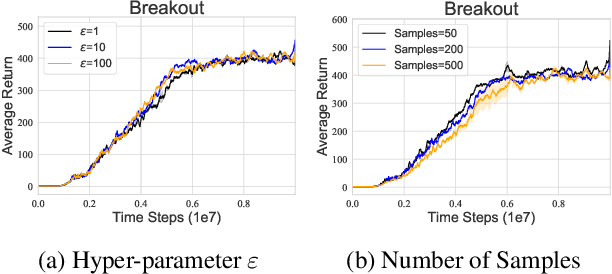
Distributional reinforcement learning~(RL) is a class of state-of-the-art algorithms that estimate the whole distribution of the total return rather than only its expectation. Despite the remarkable performance of distributional RL, a theoretical understanding of its advantages over expectation-based RL remains elusive. In this paper, we interpret distributional RL as entropy-regularized maximum likelihood estimation in the \textit{neural Z-fitted iteration} framework, and establish the connection of the resulting risk-aware regularization with maximum entropy RL. In addition, We shed light on the stability-promoting distributional loss with desirable smoothness properties in distributional RL, which can yield stable optimization and guaranteed generalization. We also analyze the acceleration behavior while optimizing distributional RL algorithms and show that an appropriate approximation to the true target distribution can speed up the convergence. From the perspective of representation, we find that distributional RL encourages state representation from the same action class classified by the policy in tighter clusters. Finally, we propose a class of \textit{Sinkhorn distributional RL} algorithm that interpolates between the Wasserstein distance and maximum mean discrepancy~(MMD). Experiments on a suite of Atari games reveal the competitive performance of our algorithm relative to existing state-of-the-art distributional RL algorithms.
A Simple Unified Framework for Anomaly Detection in Deep Reinforcement Learning
Sep 21, 2021
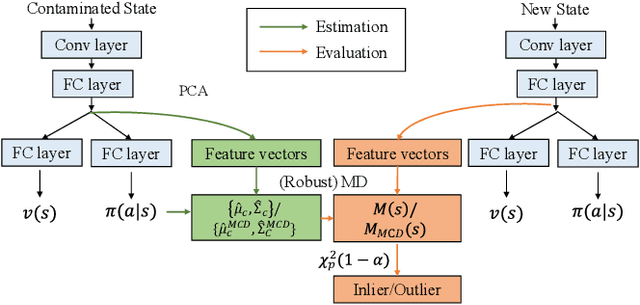
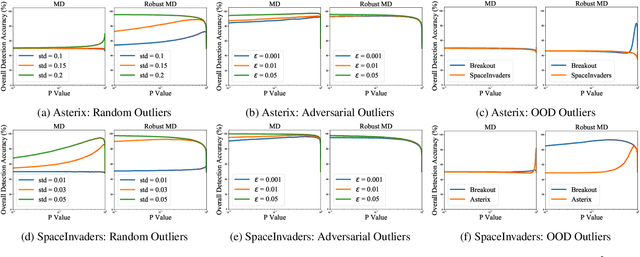
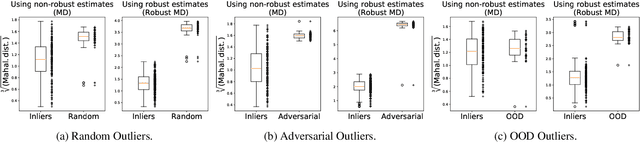
Abnormal states in deep reinforcement learning~(RL) are states that are beyond the scope of an RL policy. Such states may make the RL system unsafe and impede its deployment in real scenarios. In this paper, we propose a simple yet effective anomaly detection framework for deep RL algorithms that simultaneously considers random, adversarial and out-of-distribution~(OOD) state outliers. In particular, we attain the class-conditional distributions for each action class under the Gaussian assumption, and rely on these distributions to discriminate between inliers and outliers based on Mahalanobis Distance~(MD) and Robust Mahalanobis Distance. We conduct extensive experiments on Atari games that verify the effectiveness of our detection strategies. To the best of our knowledge, we present the first in-detail study of statistical and adversarial anomaly detection in deep RL algorithms. This simple unified anomaly detection paves the way towards deploying safe RL systems in real-world applications.
Exploring the Robustness of Distributional Reinforcement Learning against Noisy State Observations
Sep 17, 2021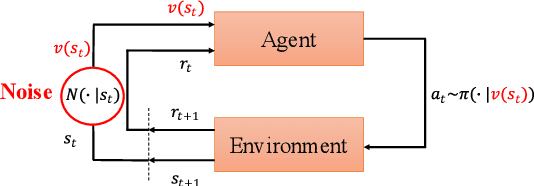
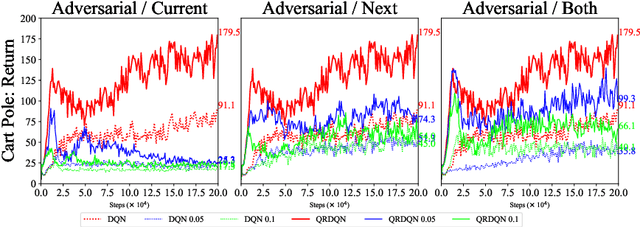
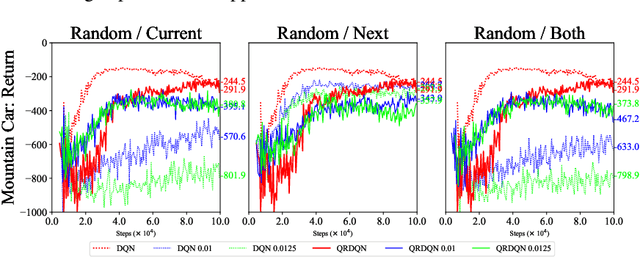
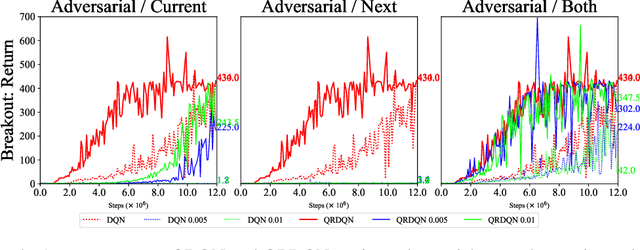
In real scenarios, state observations that an agent observes may contain measurement errors or adversarial noises, misleading the agent to take suboptimal actions or even collapse while training. In this paper, we study the training robustness of distributional Reinforcement Learning~(RL), a class of state-of-the-art methods that estimate the whole distribution, as opposed to only the expectation, of the total return. Firstly, we propose State-Noisy Markov Decision Process~(SN-MDP) in the tabular case to incorporate both random and adversarial state observation noises, in which the contraction of both expectation-based and distributional Bellman operators is derived. Beyond SN-MDP with the function approximation, we theoretically characterize the bounded gradient norm of histogram-based distributional loss, accounting for the better training robustness of distribution RL. We also provide stricter convergence conditions of the Temporal-Difference~(TD) learning under more flexible state noises, as well as the sensitivity analysis by the leverage of influence function. Finally, extensive experiments on the suite of games show that distributional RL enjoys better training robustness compared with its expectation-based counterpart across various state observation noises.
On the Variance of the Fisher Information for Deep Learning
Jul 09, 2021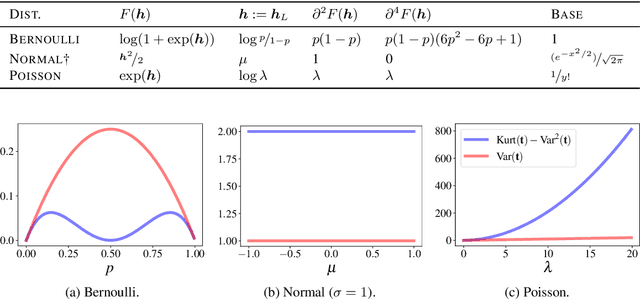
The Fisher information matrix (FIM) has been applied to the realm of deep learning. It is closely related to the loss landscape, the variance of the parameters, second order optimization, and deep learning theory. The exact FIM is either unavailable in closed form or too expensive to compute. In practice, it is almost always estimated based on empirical samples. We investigate two such estimators based on two equivalent representations of the FIM. They are both unbiased and consistent with respect to the underlying "true" FIM. Their estimation quality is characterized by their variance given in closed form. We bound their variances and analyze how the parametric structure of a deep neural network can impact the variance. We discuss the meaning of this variance measure and our bounds in the context of deep learning.
Secure Quantized Training for Deep Learning
Jul 01, 2021

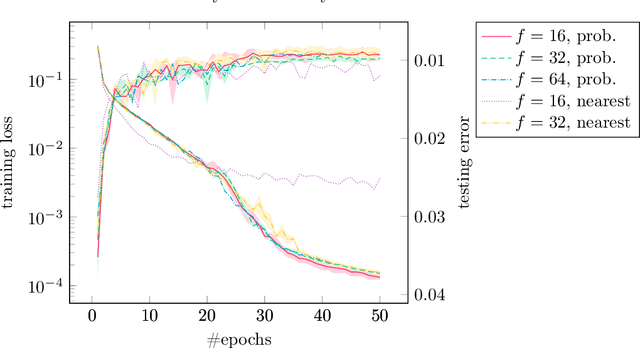
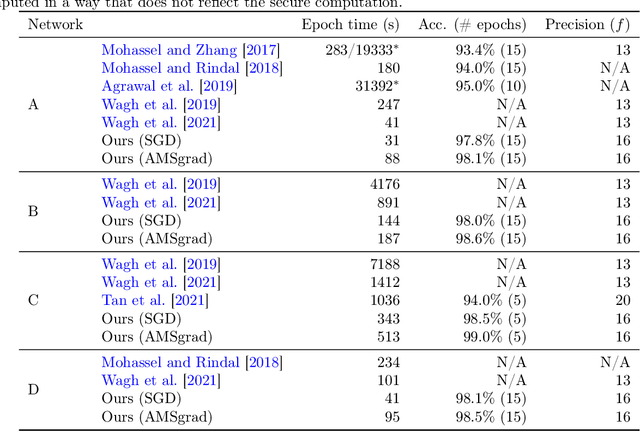
We have implemented training of neural networks in secure multi-party computation (MPC) using quantization commonly used in the said setting. To the best of our knowledge, we are the first to present an MNIST classifier purely trained in MPC that comes within 0.2 percent of the accuracy of the same convolutional neural network trained via plaintext computation. More concretely, we have trained a network with two convolution and two dense layers to 99.2% accuracy in 25 epochs. This took 3.5 hours in our MPC implementation (under one hour for 99% accuracy).
Intent Disentanglement and Feature Self-supervision for Novel Recommendation
Jun 28, 2021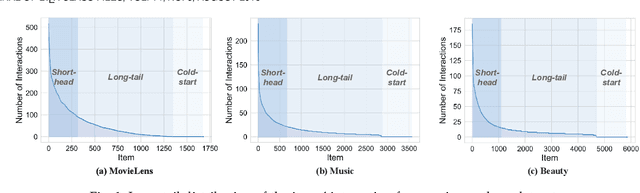
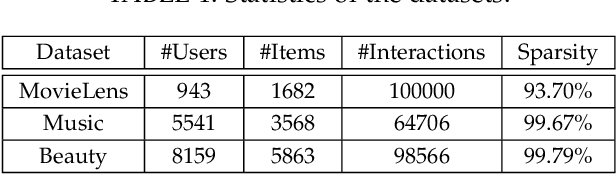
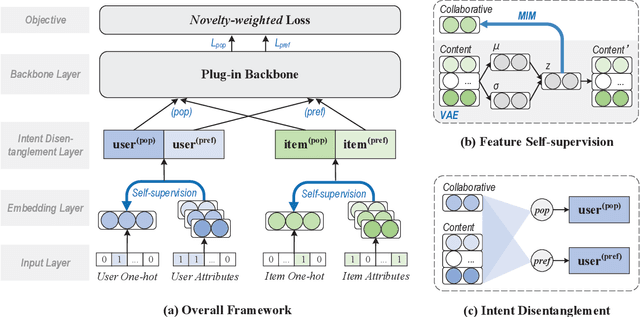
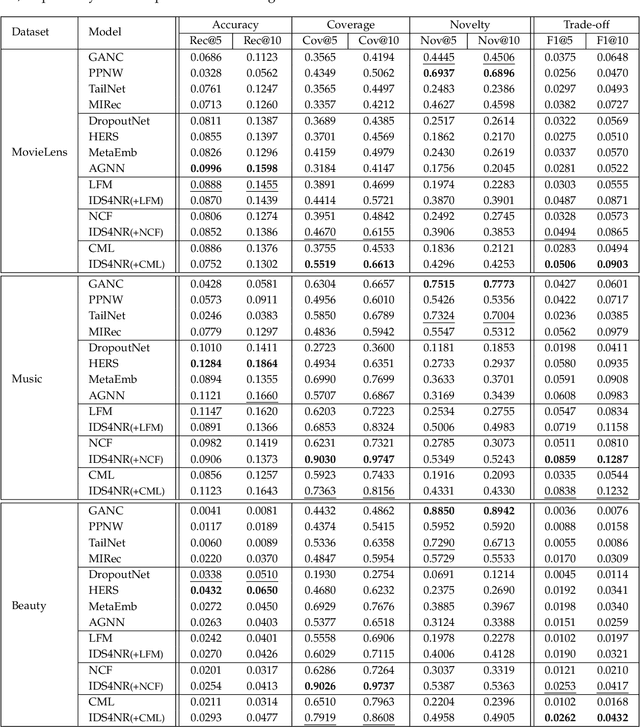
One key property in recommender systems is the long-tail distribution in user-item interactions where most items only have few user feedback. Improving the recommendation of tail items can promote novelty and bring positive effects to both users and providers, and thus is a desirable property of recommender systems. Current novel recommendation studies over-emphasize the importance of tail items without differentiating the degree of users' intent on popularity and often incur a sharp decline of accuracy. Moreover, none of existing methods has ever taken the extreme case of tail items, i.e., cold-start items without any interaction, into consideration. In this work, we first disclose the mechanism that drives a user's interaction towards popular or niche items by disentangling her intent into conformity influence (popularity) and personal interests (preference). We then present a unified end-to-end framework to simultaneously optimize accuracy and novelty targets based on the disentangled intent of popularity and that of preference. We further develop a new paradigm for novel recommendation of cold-start items which exploits the self-supervised learning technique to model the correlation between collaborative features and content features. We conduct extensive experimental results on three real-world datasets. The results demonstrate that our proposed model yields significant improvements over the state-of-the-art baselines in terms of accuracy, novelty, coverage, and trade-off.
Graph Learning: A Survey
May 03, 2021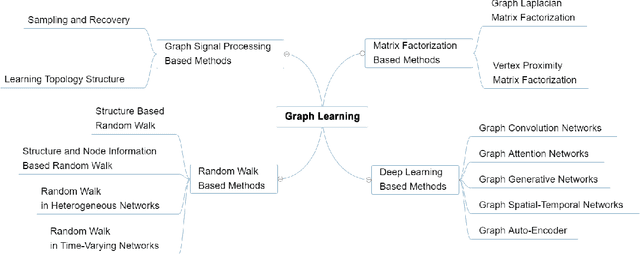
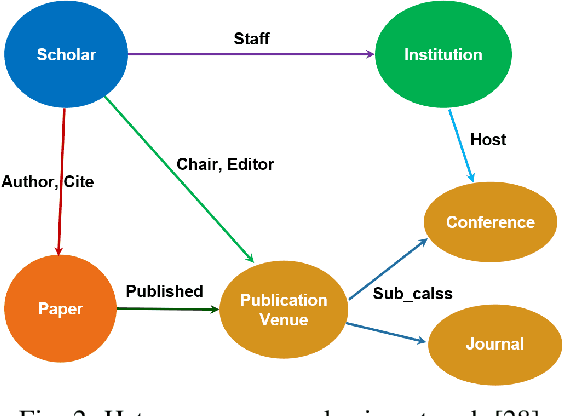
Graphs are widely used as a popular representation of the network structure of connected data. Graph data can be found in a broad spectrum of application domains such as social systems, ecosystems, biological networks, knowledge graphs, and information systems. With the continuous penetration of artificial intelligence technologies, graph learning (i.e., machine learning on graphs) is gaining attention from both researchers and practitioners. Graph learning proves effective for many tasks, such as classification, link prediction, and matching. Generally, graph learning methods extract relevant features of graphs by taking advantage of machine learning algorithms. In this survey, we present a comprehensive overview on the state-of-the-art of graph learning. Special attention is paid to four categories of existing graph learning methods, including graph signal processing, matrix factorization, random walk, and deep learning. Major models and algorithms under these categories are reviewed respectively. We examine graph learning applications in areas such as text, images, science, knowledge graphs, and combinatorial optimization. In addition, we discuss several promising research directions in this field.
* 19 pages, 6 figures
Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression
Apr 06, 2021
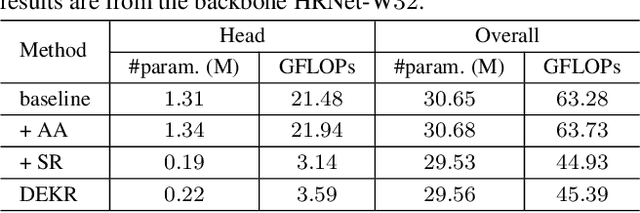

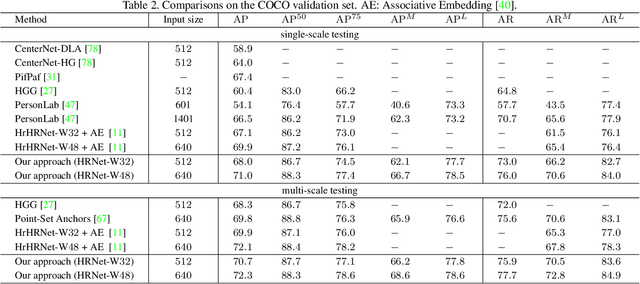
In this paper, we are interested in the bottom-up paradigm of estimating human poses from an image. We study the dense keypoint regression framework that is previously inferior to the keypoint detection and grouping framework. Our motivation is that regressing keypoint positions accurately needs to learn representations that focus on the keypoint regions. We present a simple yet effective approach, named disentangled keypoint regression (DEKR). We adopt adaptive convolutions through pixel-wise spatial transformer to activate the pixels in the keypoint regions and accordingly learn representations from them. We use a multi-branch structure for separate regression: each branch learns a representation with dedicated adaptive convolutions and regresses one keypoint. The resulting disentangled representations are able to attend to the keypoint regions, respectively, and thus the keypoint regression is spatially more accurate. We empirically show that the proposed direct regression method outperforms keypoint detection and grouping methods and achieves superior bottom-up pose estimation results on two benchmark datasets, COCO and CrowdPose. The code and models are available at https://github.com/HRNet/DEKR.
Graph Force Learning
Mar 07, 2021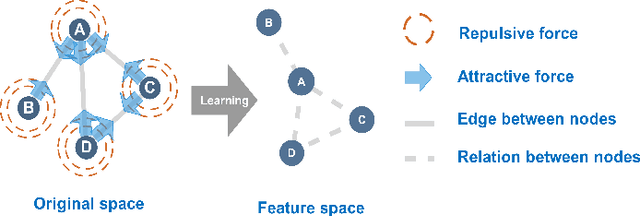
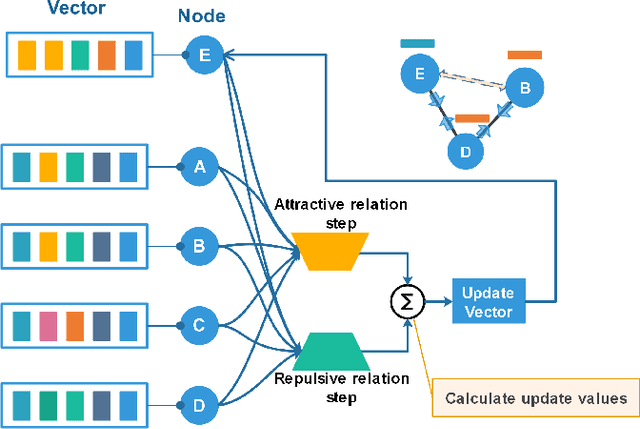
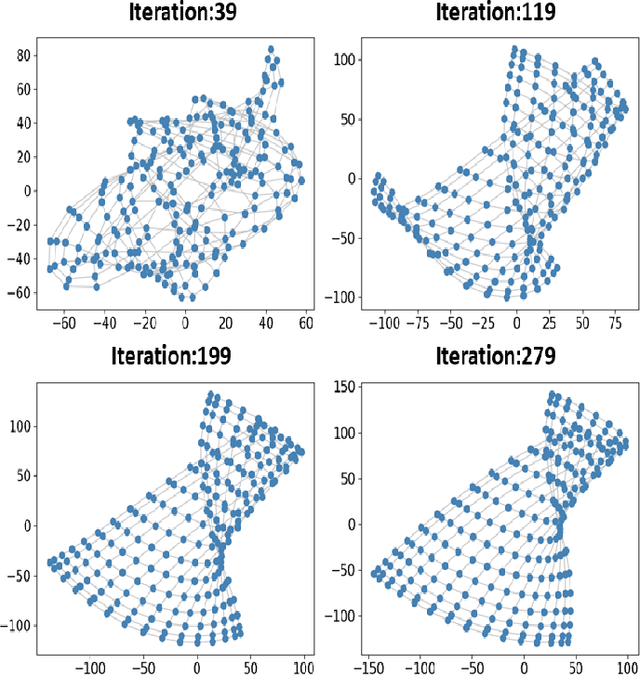
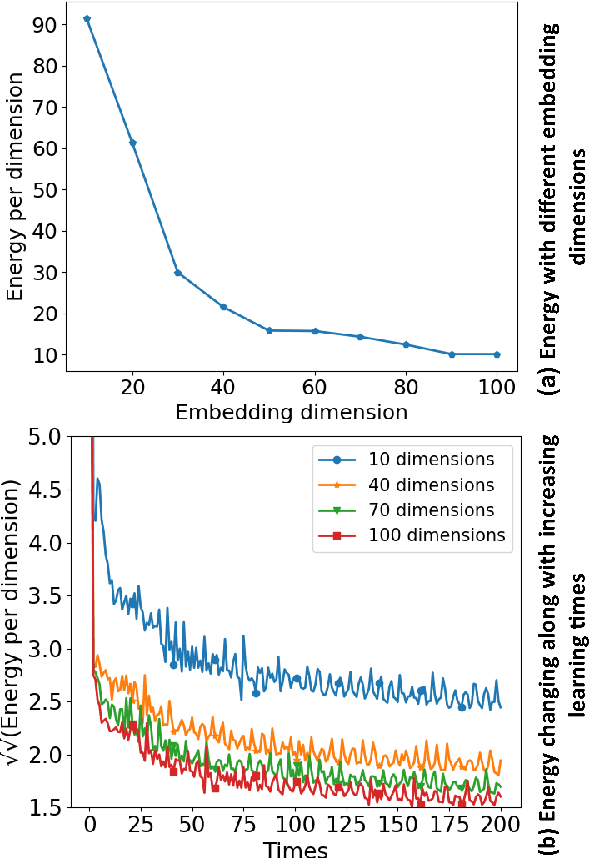
Features representation leverages the great power in network analysis tasks. However, most features are discrete which poses tremendous challenges to effective use. Recently, increasing attention has been paid on network feature learning, which could map discrete features to continued space. Unfortunately, current studies fail to fully preserve the structural information in the feature space due to random negative sampling strategy during training. To tackle this problem, we study the problem of feature learning and novelty propose a force-based graph learning model named GForce inspired by the spring-electrical model. GForce assumes that nodes are in attractive forces and repulsive forces, thus leading to the same representation with the original structural information in feature learning. Comprehensive experiments on benchmark datasets demonstrate the effectiveness of the proposed framework. Furthermore, GForce opens up opportunities to use physics models to model node interaction for graph learning.
Network Representation Learning: From Traditional Feature Learning to Deep Learning
Mar 07, 2021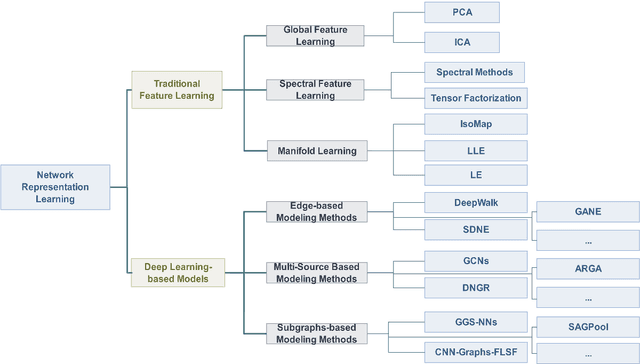
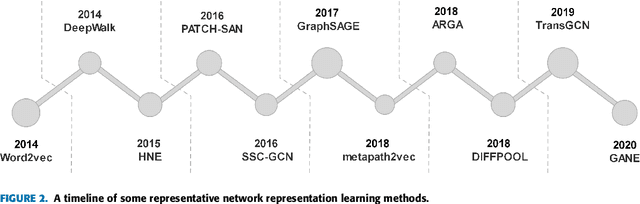
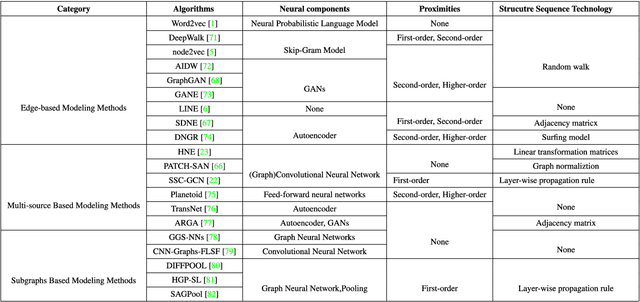
Network representation learning (NRL) is an effective graph analytics technique and promotes users to deeply understand the hidden characteristics of graph data. It has been successfully applied in many real-world tasks related to network science, such as social network data processing, biological information processing, and recommender systems. Deep Learning is a powerful tool to learn data features. However, it is non-trivial to generalize deep learning to graph-structured data since it is different from the regular data such as pictures having spatial information and sounds having temporal information. Recently, researchers proposed many deep learning-based methods in the area of NRL. In this survey, we investigate classical NRL from traditional feature learning method to the deep learning-based model, analyze relationships between them, and summarize the latest progress. Finally, we discuss open issues considering NRL and point out the future directions in this field.