 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Reflectance Fields for Appearance Acquisition
Aug 16, 2020
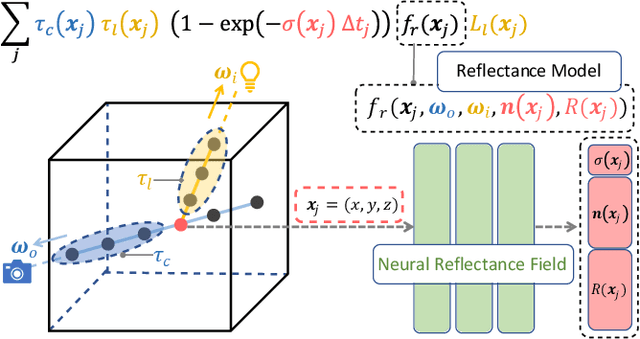
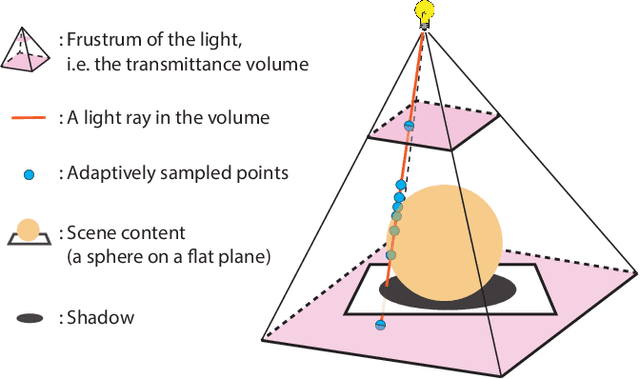
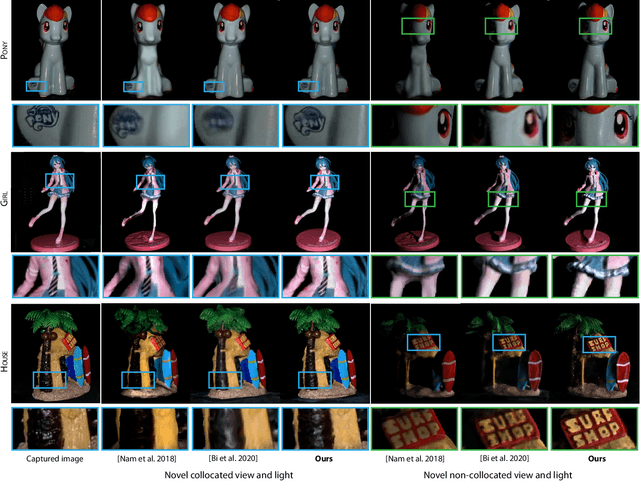
We present Neural Reflectance Fields, a novel deep scene representation that encodes volume density, normal and reflectance properties at any 3D point in a scene using a fully-connected neural network. We combine this representation with a physically-based differentiable ray marching framework that can render images from a neural reflectance field under any viewpoint and light. We demonstrate that neural reflectance fields can be estimated from images captured with a simple collocated camera-light setup, and accurately model the appearance of real-world scenes with complex geometry and reflectance. Once estimated, they can be used to render photo-realistic images under novel viewpoint and (non-collocated) lighting conditions and accurately reproduce challenging effects like specularities, shadows and occlusions. This allows us to perform high-quality view synthesis and relighting that is significantly better than previous methods. We also demonstrate that we can compose the estimated neural reflectance field of a real scene with traditional scene models and render them using standard Monte Carlo rendering engines. Our work thus enables a complete pipeline from high-quality and practical appearance acquisition to 3D scene composition and rendering.
Single View Metrology in the Wild
Aug 11, 2020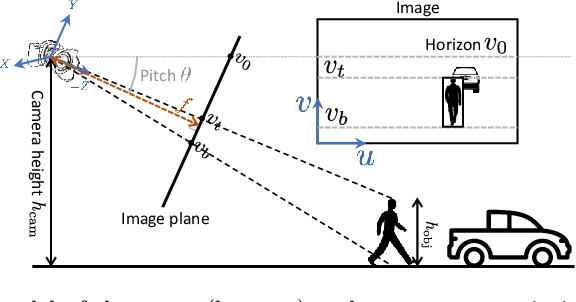

Most 3D reconstruction methods may only recover scene properties up to a global scale ambiguity. We present a novel approach to single view metrology that can recover the absolute scale of a scene represented by 3D heights of objects or camera height above the ground as well as camera parameters of orientation and field of view, using just a monocular image acquired in unconstrained condition. Our method relies on data-driven priors learned by a deep network specifically designed to imbibe weakly supervised constraints from the interplay of the unknown camera with 3D entities such as object heights, through estimation of bounding box projections. We leverage categorical priors for objects such as humans or cars that commonly occur in natural images, as references for scale estimation. We demonstrate state-of-the-art qualitative and quantitative results on several datasets as well as applications including virtual object insertion. Furthermore, the perceptual quality of our outputs is validated by a user study.
Deep Multi Depth Panoramas for View Synthesis
Aug 04, 2020

We propose a learning-based approach for novel view synthesis for multi-camera 360$^{\circ}$ panorama capture rigs. Previous work constructs RGBD panoramas from such data, allowing for view synthesis with small amounts of translation, but cannot handle the disocclusions and view-dependent effects that are caused by large translations. To address this issue, we present a novel scene representation - Multi Depth Panorama (MDP) - that consists of multiple RGBD$\alpha$ panoramas that represent both scene geometry and appearance. We demonstrate a deep neural network-based method to reconstruct MDPs from multi-camera 360$^{\circ}$ images. MDPs are more compact than previous 3D scene representations and enable high-quality, efficient new view rendering. We demonstrate this via experiments on both synthetic and real data and comparisons with previous state-of-the-art methods spanning both learning-based approaches and classical RGBD-based methods.
OpenRooms: An End-to-End Open Framework for Photorealistic Indoor Scene Datasets
Jul 25, 2020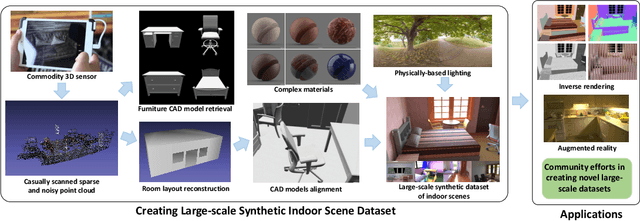


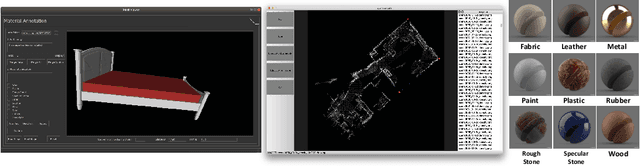
Large-scale photorealistic datasets of indoor scenes, with ground truth geometry, materials and lighting, are important for deep learning applications in scene reconstruction and augmented reality. The associated shape, material and lighting assets can be scanned or artist-created, both of which are expensive; the resulting data is usually proprietary. We aim to make the dataset creation process for indoor scenes widely accessible, allowing researchers to transform casually acquired scans to large-scale datasets with high-quality ground truth. We achieve this by estimating consistent furniture and scene layout, ascribing high quality materials to all surfaces and rendering images with spatially-varying lighting consisting of area lights and environment maps. We demonstrate an instantiation of our approach on the publicly available ScanNet dataset. Deep networks trained on our proposed dataset achieve competitive performance for shape, material and lighting estimation on real images and can be used for photorealistic augmented reality applications, such as object insertion and material editing. Importantly, the dataset and all the tools to create such datasets from scans will be released, enabling others in the community to easily build large-scale datasets of their own. All code, models, data, dataset creation tool will be publicly released on our project page.
Deep Reflectance Volumes: Relightable Reconstructions from Multi-View Photometric Images
Jul 20, 2020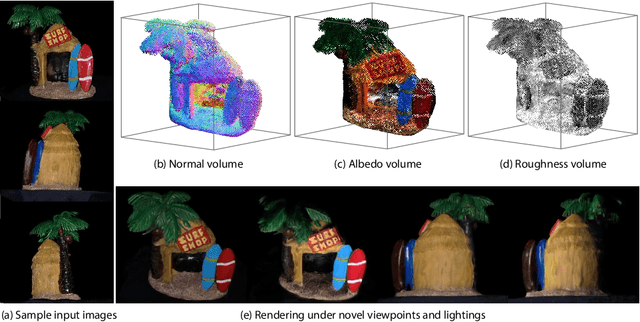
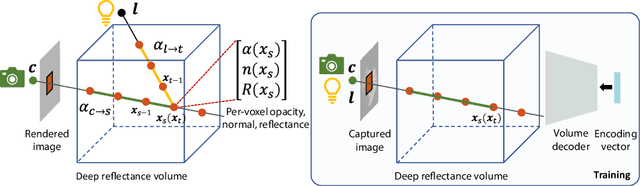

We present a deep learning approach to reconstruct scene appearance from unstructured images captured under collocated point lighting. At the heart of Deep Reflectance Volumes is a novel volumetric scene representation consisting of opacity, surface normal and reflectance voxel grids. We present a novel physically-based differentiable volume ray marching framework to render these scene volumes under arbitrary viewpoint and lighting. This allows us to optimize the scene volumes to minimize the error between their rendered images and the captured images. Our method is able to reconstruct real scenes with challenging non-Lambertian reflectance and complex geometry with occlusions and shadowing. Moreover, it accurately generalizes to novel viewpoints and lighting, including non-collocated lighting, rendering photorealistic images that are significantly better than state-of-the-art mesh-based methods. We also show that our learned reflectance volumes are editable, allowing for modifying the materials of the captured scenes.
State of the Art on Neural Rendering
Apr 08, 2020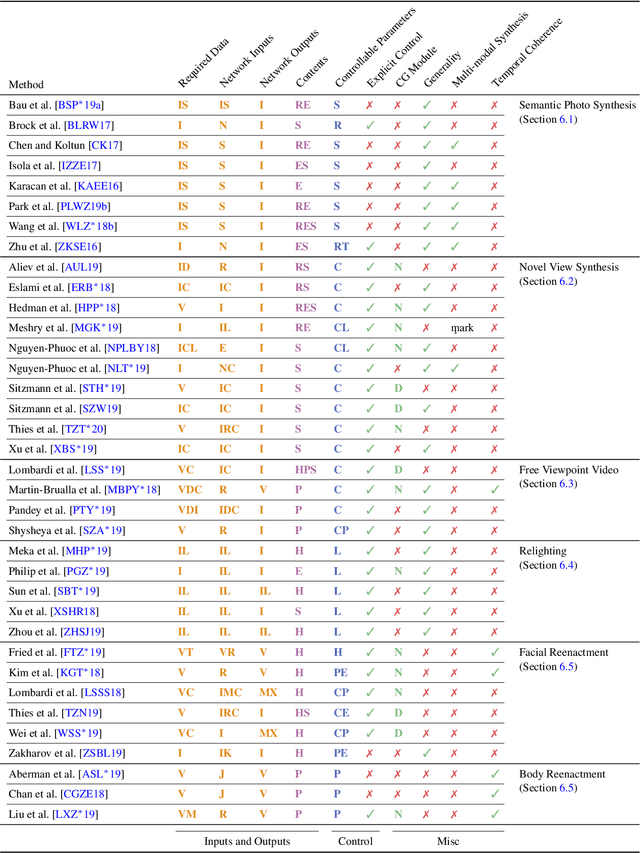



Efficient rendering of photo-realistic virtual worlds is a long standing effort of computer graphics. Modern graphics techniques have succeeded in synthesizing photo-realistic images from hand-crafted scene representations. However, the automatic generation of shape, materials, lighting, and other aspects of scenes remains a challenging problem that, if solved, would make photo-realistic computer graphics more widely accessible. Concurrently, progress in computer vision and machine learning have given rise to a new approach to image synthesis and editing, namely deep generative models. Neural rendering is a new and rapidly emerging field that combines generative machine learning techniques with physical knowledge from computer graphics, e.g., by the integration of differentiable rendering into network training. With a plethora of applications in computer graphics and vision, neural rendering is poised to become a new area in the graphics community, yet no survey of this emerging field exists. This state-of-the-art report summarizes the recent trends and applications of neural rendering. We focus on approaches that combine classic computer graphics techniques with deep generative models to obtain controllable and photo-realistic outputs. Starting with an overview of the underlying computer graphics and machine learning concepts, we discuss critical aspects of neural rendering approaches. This state-of-the-art report is focused on the many important use cases for the described algorithms such as novel view synthesis, semantic photo manipulation, facial and body reenactment, relighting, free-viewpoint video, and the creation of photo-realistic avatars for virtual and augmented reality telepresence. Finally, we conclude with a discussion of the social implications of such technology and investigate open research problems.
Deep CG2Real: Synthetic-to-Real Translation via Image Disentanglement
Mar 27, 2020
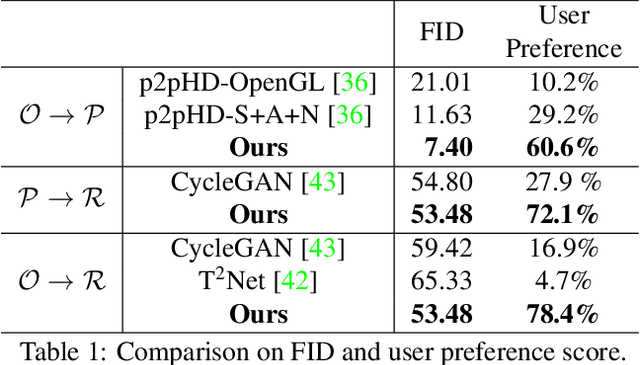
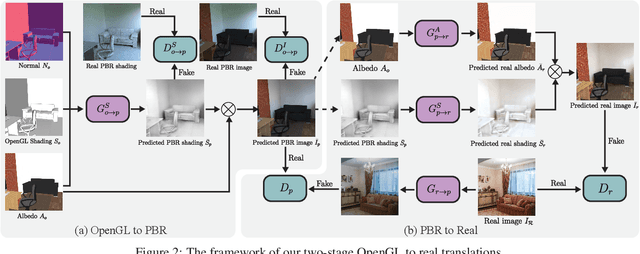
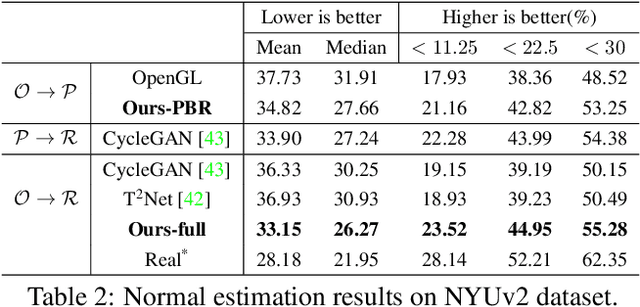
We present a method to improve the visual realism of low-quality, synthetic images, e.g. OpenGL renderings. Training an unpaired synthetic-to-real translation network in image space is severely under-constrained and produces visible artifacts. Instead, we propose a semi-supervised approach that operates on the disentangled shading and albedo layers of the image. Our two-stage pipeline first learns to predict accurate shading in a supervised fashion using physically-based renderings as targets, and further increases the realism of the textures and shading with an improved CycleGAN network. Extensive evaluations on the SUNCG indoor scene dataset demonstrate that our approach yields more realistic images compared to other state-of-the-art approaches. Furthermore, networks trained on our generated "real" images predict more accurate depth and normals than domain adaptation approaches, suggesting that improving the visual realism of the images can be more effective than imposing task-specific losses.
Deep 3D Capture: Geometry and Reflectance from Sparse Multi-View Images
Mar 27, 2020
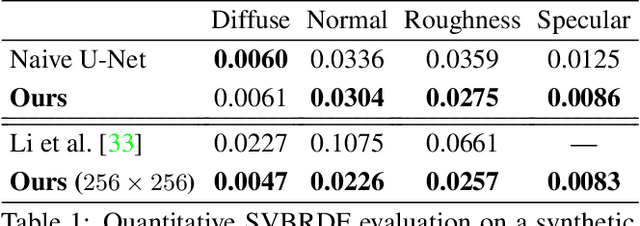
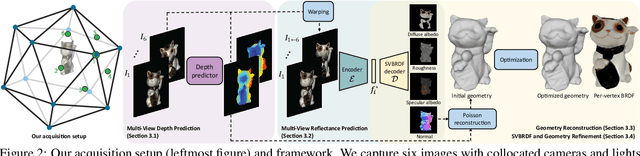
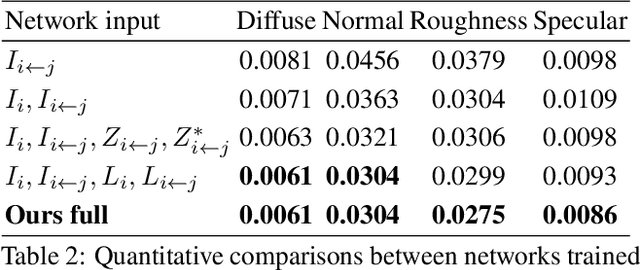
We introduce a novel learning-based method to reconstruct the high-quality geometry and complex, spatially-varying BRDF of an arbitrary object from a sparse set of only six images captured by wide-baseline cameras under collocated point lighting. We first estimate per-view depth maps using a deep multi-view stereo network; these depth maps are used to coarsely align the different views. We propose a novel multi-view reflectance estimation network architecture that is trained to pool features from these coarsely aligned images and predict per-view spatially-varying diffuse albedo, surface normals, specular roughness and specular albedo. We do this by jointly optimizing the latent space of our multi-view reflectance network to minimize the photometric error between images rendered with our predictions and the input images. While previous state-of-the-art methods fail on such sparse acquisition setups, we demonstrate, via extensive experiments on synthetic and real data, that our method produces high-quality reconstructions that can be used to render photorealistic images.
Basis Prediction Networks for Effective Burst Denoising with Large Kernels
Dec 09, 2019
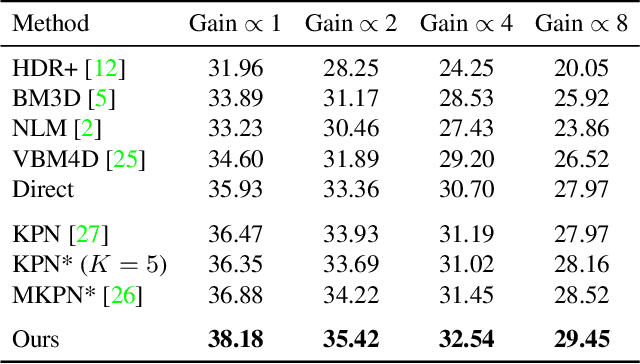
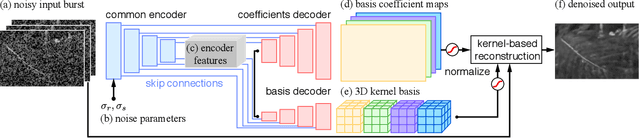
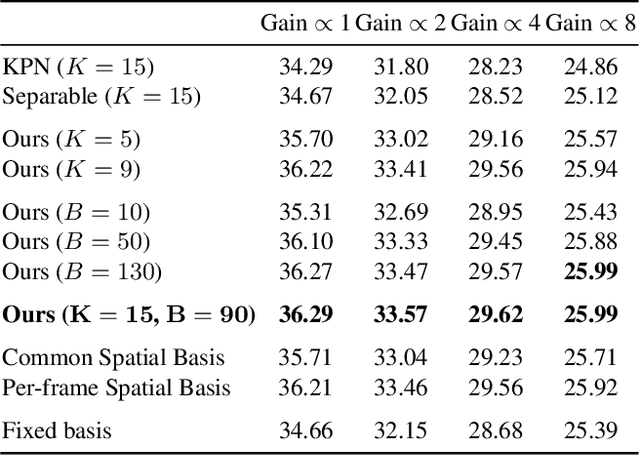
Bursts of images exhibit significant self-similarity across both time and space. This motivates a representation of the kernels as linear combinations of a small set of basis elements. To this end, we introduce a novel basis prediction network that, given an input burst, predicts a set of global basis kernels --- shared within the image --- and the corresponding mixing coefficients --- which are specific to individual pixels. Compared to other state-of-the-art deep learning techniques that output a large tensor of per-pixel spatiotemporal kernels, our formulation substantially reduces the dimensionality of the network output. This allows us to effectively exploit larger denoising kernels and achieve significant quality improvements (over 1dB PSNR) at reduced run-times compared to state-of-the-art methods.
Deep Parametric Indoor Lighting Estimation
Oct 19, 2019

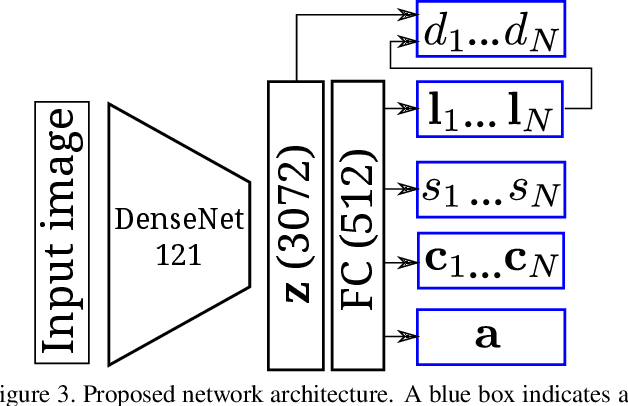

We present a method to estimate lighting from a single image of an indoor scene. Previous work has used an environment map representation that does not account for the localized nature of indoor lighting. Instead, we represent lighting as a set of discrete 3D lights with geometric and photometric parameters. We train a deep neural network to regress these parameters from a single image, on a dataset of environment maps annotated with depth. We propose a differentiable layer to convert these parameters to an environment map to compute our loss; this bypasses the challenge of establishing correspondences between estimated and ground truth lights. We demonstrate, via quantitative and qualitative evaluations, that our representation and training scheme lead to more accurate results compared to previous work, while allowing for more realistic 3D object compositing with spatially-varying lighting.