 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
CODEBLOCK: Learning to Supervise Code at the Right Granularity
Jun 10, 2026Supervised fine-tuning of code LLMs typically applies uniform cross-entropy loss to all response tokens, implicitly assuming that every token provides equally useful learning signal. Recent token-level selection methods challenge this assumption in natural-language SFT by supervising only high-value tokens. However, directly transferring token-level masking to code can break syntactically and semantically coherent program units, because code depends on structural completeness and definition-use relations. We therefore propose CodeBlock, a structure-aware sparse supervision framework that selects structure-complete code evidence rather than isolated tokens. CodeBlock first selects high-quality instruction-response pairs, then partitions code responses into syntactically coherent coding items, estimates their utility by aggregating generalized cross-entropy over core logic tokens, and reranks them with data-flow reach and bridge signals to prioritize blocks that propagate or connect important program dependencies. During training, the full response remains available as context, while loss is applied only to selected code items and informative natural-language tokens. Experiments on six code-generation benchmarks show that CodeBlock achieves stronger average pass@1 than full-token SFT and competitive selection baselines, while using only 1.9% of supervised response tokens.
Short-Path Prompting in LLMs: Analyzing Reasoning Instability and Solutions for Robust Performance
Apr 13, 2025Recent years have witnessed significant progress in large language models' (LLMs) reasoning, which is largely due to the chain-of-thought (CoT) approaches, allowing models to generate intermediate reasoning steps before reaching the final answer. Building on these advances, state-of-the-art LLMs are instruction-tuned to provide long and detailed CoT pathways when responding to reasoning-related questions. However, human beings are naturally cognitive misers and will prompt language models to give rather short responses, thus raising a significant conflict with CoT reasoning. In this paper, we delve into how LLMs' reasoning performance changes when users provide short-path prompts. The results and analysis reveal that language models can reason effectively and robustly without explicit CoT prompts, while under short-path prompting, LLMs' reasoning ability drops significantly and becomes unstable, even on grade-school problems. To address this issue, we propose two approaches: an instruction-guided approach and a fine-tuning approach, both designed to effectively manage the conflict. Experimental results show that both methods achieve high accuracy, providing insights into the trade-off between instruction adherence and reasoning accuracy in current models.
Meta Feature Modulator for Long-tailed Recognition
Aug 08, 2020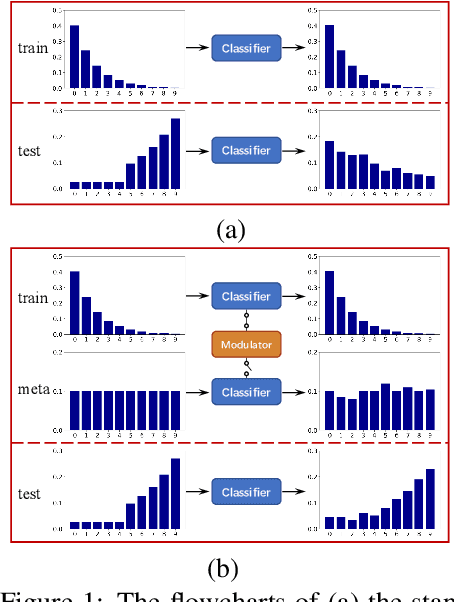
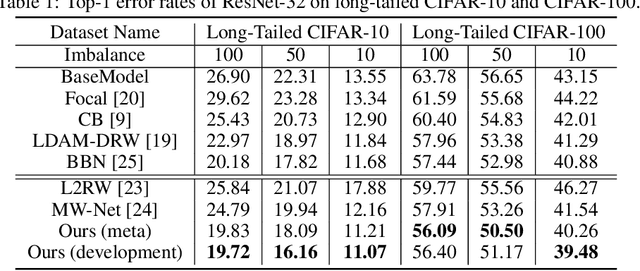
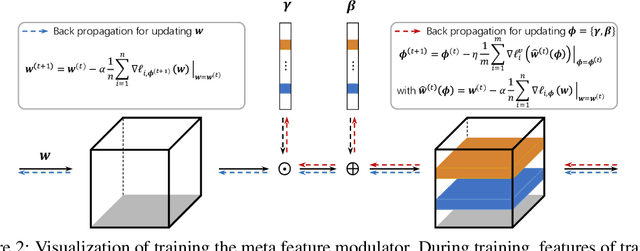

Deep neural networks often degrade significantly when training data suffer from class imbalance problems. Existing approaches, e.g., re-sampling and re-weighting, commonly address this issue by rearranging the label distribution of training data to train the networks fitting well to the implicit balanced label distribution. However, most of them hinder the representative ability of learned features due to insufficient use of intra/inter-sample information of training data. To address this issue, we propose meta feature modulator (MFM), a meta-learning framework to model the difference between the long-tailed training data and the balanced meta data from the perspective of representation learning. Concretely, we employ learnable hyper-parameters (dubbed modulation parameters) to adaptively scale and shift the intermediate features of classification networks, and the modulation parameters are optimized together with the classification network parameters guided by a small amount of balanced meta data. We further design a modulator network to guide the generation of the modulation parameters, and such a meta-learner can be readily adapted to train the classification network on other long-tailed datasets. Extensive experiments on benchmark vision datasets substantiate the superiority of our approach on long-tailed recognition tasks beyond other state-of-the-art methods.