 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee Your Heart: Psychological states Interpretation through Visual Creations
Feb 11, 2023



In psychoanalysis, generating interpretations to one's psychological state through visual creations is facing significant demands. The two main tasks of existing studies in the field of computer vision, sentiment/emotion classification and affective captioning, can hardly satisfy the requirement of psychological interpreting. To meet the demands for psychoanalysis, we introduce a challenging task, \textbf{V}isual \textbf{E}motion \textbf{I}nterpretation \textbf{T}ask (VEIT). VEIT requires AI to generate reasonable interpretations of creator's psychological state through visual creations. To support the task, we present a multimodal dataset termed SpyIn (\textbf{S}and\textbf{p}la\textbf{y} \textbf{In}terpretation Dataset), which is psychological theory supported and professional annotated. Dataset analysis illustrates that SpyIn is not only able to support VEIT, but also more challenging compared with other captioning datasets. Building on SpyIn, we conduct experiments of several image captioning method, and propose a visual-semantic combined model which obtains a SOTA result on SpyIn. The results indicate that VEIT is a more challenging task requiring scene graph information and psychological knowledge. Our work also show a promise for AI to analyze and explain inner world of humanity through visual creations.
PECAN: Leveraging Policy Ensemble for Context-Aware Zero-Shot Human-AI Coordination
Jan 16, 2023



Zero-shot human-AI coordination holds the promise of collaborating with humans without human data. Prevailing methods try to train the ego agent with a population of partners via self-play. However, this kind of method suffers from two problems: 1) The diversity of a population with finite partners is limited, thereby limiting the capacity of the trained ego agent to collaborate with a novel human; 2) Current methods only provide a common best response for every partner in the population, which may result in poor zero-shot coordination performance with a novel partner or humans. To address these issues, we first propose the policy ensemble method to increase the diversity of partners in the population, and then develop a context-aware method enabling the ego agent to analyze and identify the partner's potential policy primitives so that it can take different actions accordingly. In this way, the ego agent is able to learn more universal cooperative behaviors for collaborating with diverse partners. We conduct experiments on the Overcooked environment, and evaluate the zero-shot human-AI coordination performance of our method with both behavior-cloned human proxies and real humans. The results demonstrate that our method significantly increases the diversity of partners and enables ego agents to learn more diverse behaviors than baselines, thus achieving state-of-the-art performance in all scenarios.
InsPro: Propagating Instance Query and Proposal for Online Video Instance Segmentation
Jan 05, 2023Video instance segmentation (VIS) aims at segmenting and tracking objects in videos. Prior methods typically generate frame-level or clip-level object instances first and then associate them by either additional tracking heads or complex instance matching algorithms. This explicit instance association approach increases system complexity and fails to fully exploit temporal cues in videos. In this paper, we design a simple, fast and yet effective query-based framework for online VIS. Relying on an instance query and proposal propagation mechanism with several specially developed components, this framework can perform accurate instance association implicitly. Specifically, we generate frame-level object instances based on a set of instance query-proposal pairs propagated from previous frames. This instance query-proposal pair is learned to bind with one specific object across frames through conscientiously developed strategies. When using such a pair to predict an object instance on the current frame, not only the generated instance is automatically associated with its precursors on previous frames, but the model gets a good prior for predicting the same object. In this way, we naturally achieve implicit instance association in parallel with segmentation and elegantly take advantage of temporal clues in videos. To show the effectiveness of our method InsPro, we evaluate it on two popular VIS benchmarks, i.e., YouTube-VIS 2019 and YouTube-VIS 2021. Without bells-and-whistles, our InsPro with ResNet-50 backbone achieves 43.2 AP and 37.6 AP on these two benchmarks respectively, outperforming all other online VIS methods.
Learning Disentangled Label Representations for Multi-label Classification
Dec 02, 2022



Although various methods have been proposed for multi-label classification, most approaches still follow the feature learning mechanism of the single-label (multi-class) classification, namely, learning a shared image feature to classify multiple labels. However, we find this One-shared-Feature-for-Multiple-Labels (OFML) mechanism is not conducive to learning discriminative label features and makes the model non-robustness. For the first time, we mathematically prove that the inferiority of the OFML mechanism is that the optimal learned image feature cannot maintain high similarities with multiple classifiers simultaneously in the context of minimizing cross-entropy loss. To address the limitations of the OFML mechanism, we introduce the One-specific-Feature-for-One-Label (OFOL) mechanism and propose a novel disentangled label feature learning (DLFL) framework to learn a disentangled representation for each label. The specificity of the framework lies in a feature disentangle module, which contains learnable semantic queries and a Semantic Spatial Cross-Attention (SSCA) module. Specifically, learnable semantic queries maintain semantic consistency between different images of the same label. The SSCA module localizes the label-related spatial regions and aggregates located region features into the corresponding label feature to achieve feature disentanglement. We achieve state-of-the-art performance on eight datasets of three tasks, \ie, multi-label classification, pedestrian attribute recognition, and continual multi-label learning.
Distributed Deep Reinforcement Learning: A Survey and A Multi-Player Multi-Agent Learning Toolbox
Dec 01, 2022With the breakthrough of AlphaGo, deep reinforcement learning becomes a recognized technique for solving sequential decision-making problems. Despite its reputation, data inefficiency caused by its trial and error learning mechanism makes deep reinforcement learning hard to be practical in a wide range of areas. Plenty of methods have been developed for sample efficient deep reinforcement learning, such as environment modeling, experience transfer, and distributed modifications, amongst which, distributed deep reinforcement learning has shown its potential in various applications, such as human-computer gaming, and intelligent transportation. In this paper, we conclude the state of this exciting field, by comparing the classical distributed deep reinforcement learning methods, and studying important components to achieve efficient distributed learning, covering single player single agent distributed deep reinforcement learning to the most complex multiple players multiple agents distributed deep reinforcement learning. Furthermore, we review recently released toolboxes that help to realize distributed deep reinforcement learning without many modifications of their non-distributed versions. By analyzing their strengths and weaknesses, a multi-player multi-agent distributed deep reinforcement learning toolbox is developed and released, which is further validated on Wargame, a complex environment, showing usability of the proposed toolbox for multiple players and multiple agents distributed deep reinforcement learning under complex games. Finally, we try to point out challenges and future trends, hoping this brief review can provide a guide or a spark for researchers who are interested in distributed deep reinforcement learning.
DiffGAR: Model-Agnostic Restoration from Generative Artifacts Using Image-to-Image Diffusion Models
Oct 16, 2022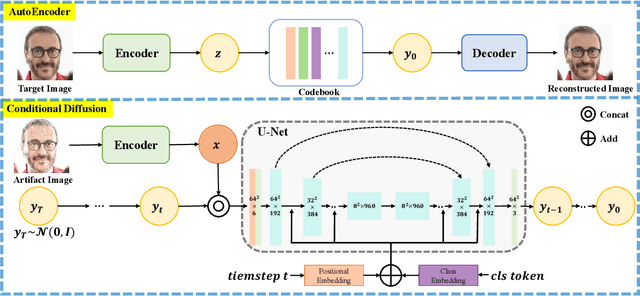

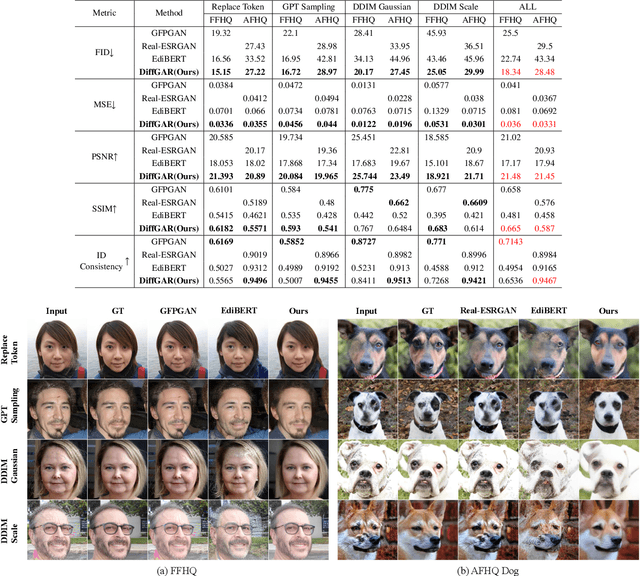
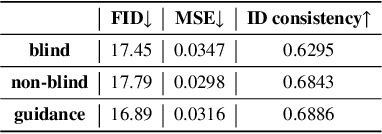
Recent generative models show impressive results in photo-realistic image generation. However, artifacts often inevitably appear in the generated results, leading to downgraded user experience and reduced performance in downstream tasks. This work aims to develop a plugin post-processing module for diverse generative models, which can faithfully restore images from diverse generative artifacts. This is challenging because: (1) Unlike traditional degradation patterns, generative artifacts are non-linear and the transformation function is highly complex. (2) There are no readily available artifact-image pairs. (3) Different from model-specific anti-artifact methods, a model-agnostic framework views the generator as a black-box machine and has no access to the architecture details. In this work, we first design a group of mechanisms to simulate generative artifacts of popular generators (i.e., GANs, autoregressive models, and diffusion models), given real images. Second, we implement the model-agnostic anti-artifact framework as an image-to-image diffusion model, due to its advantage in generation quality and capacity. Finally, we design a conditioning scheme for the diffusion model to enable both blind and non-blind image restoration. A guidance parameter is also introduced to allow for a trade-off between restoration accuracy and image quality. Extensive experiments show that our method significantly outperforms previous approaches on the proposed datasets and real-world artifact images.
QueryProp: Object Query Propagation for High-Performance Video Object Detection
Jul 22, 2022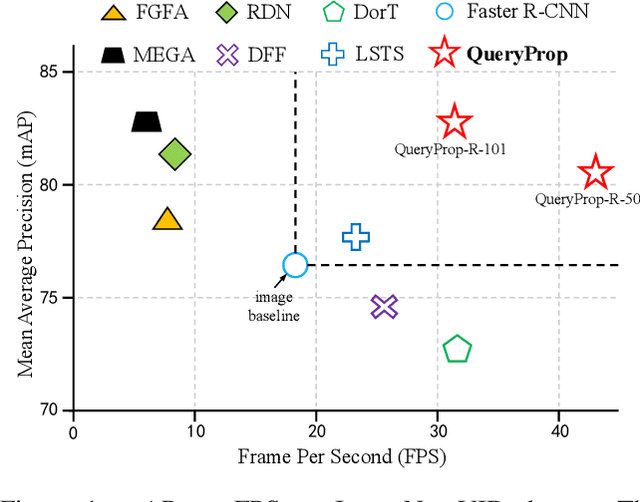
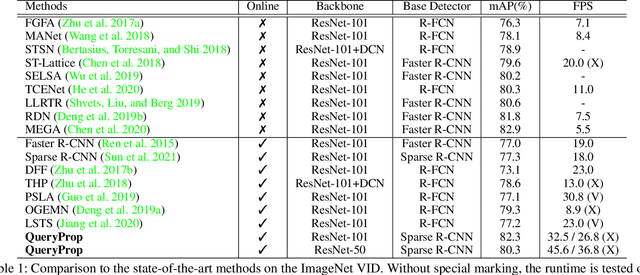
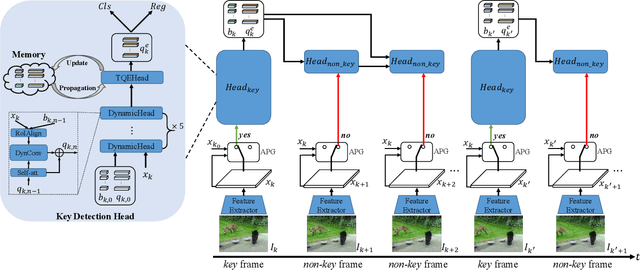
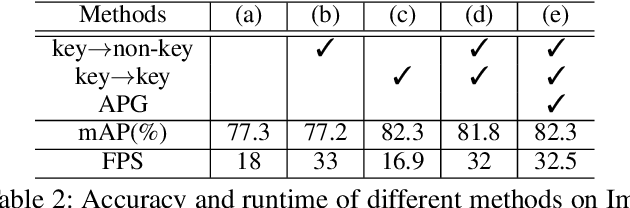
Video object detection has been an important yet challenging topic in computer vision. Traditional methods mainly focus on designing the image-level or box-level feature propagation strategies to exploit temporal information. This paper argues that with a more effective and efficient feature propagation framework, video object detectors can gain improvement in terms of both accuracy and speed. For this purpose, this paper studies object-level feature propagation, and proposes an object query propagation (QueryProp) framework for high-performance video object detection. The proposed QueryProp contains two propagation strategies: 1) query propagation is performed from sparse key frames to dense non-key frames to reduce the redundant computation on non-key frames; 2) query propagation is performed from previous key frames to the current key frame to improve feature representation by temporal context modeling. To further facilitate query propagation, an adaptive propagation gate is designed to achieve flexible key frame selection. We conduct extensive experiments on the ImageNet VID dataset. QueryProp achieves comparable accuracy with state-of-the-art methods and strikes a decent accuracy/speed trade-off. Code is available at https://github.com/hf1995/QueryProp.
RACA: Relation-Aware Credit Assignment for Ad-Hoc Cooperation in Multi-Agent Deep Reinforcement Learning
Jun 02, 2022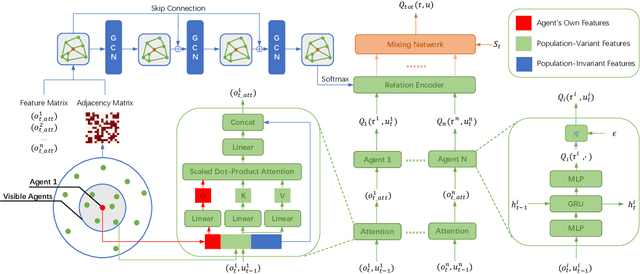
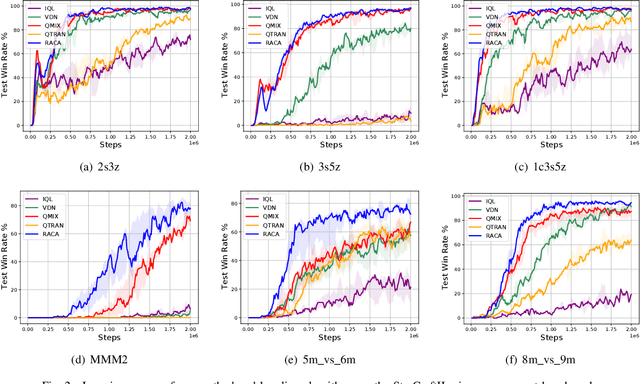
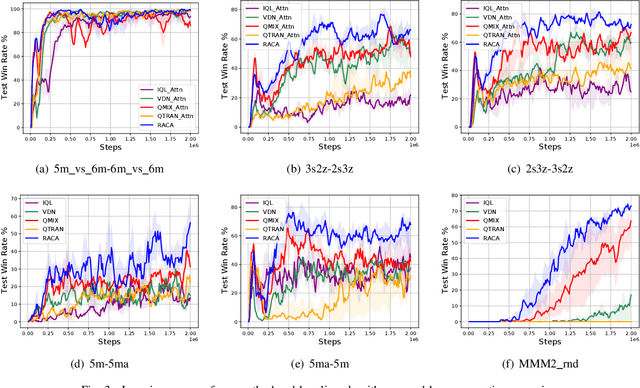
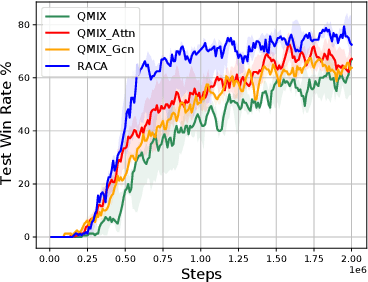
In recent years, reinforcement learning has faced several challenges in the multi-agent domain, such as the credit assignment issue. Value function factorization emerges as a promising way to handle the credit assignment issue under the centralized training with decentralized execution (CTDE) paradigm. However, existing value function factorization methods cannot deal with ad-hoc cooperation, that is, adapting to new configurations of teammates at test time. Specifically, these methods do not explicitly utilize the relationship between agents and cannot adapt to different sizes of inputs. To address these limitations, we propose a novel method, called Relation-Aware Credit Assignment (RACA), which achieves zero-shot generalization in ad-hoc cooperation scenarios. RACA takes advantage of a graph-based relation encoder to encode the topological structure between agents. Furthermore, RACA utilizes an attention-based observation abstraction mechanism that can generalize to an arbitrary number of teammates with a fixed number of parameters. Experiments demonstrate that our method outperforms baseline methods on the StarCraftII micromanagement benchmark and ad-hoc cooperation scenarios.
PanopticDepth: A Unified Framework for Depth-aware Panoptic Segmentation
Jun 01, 2022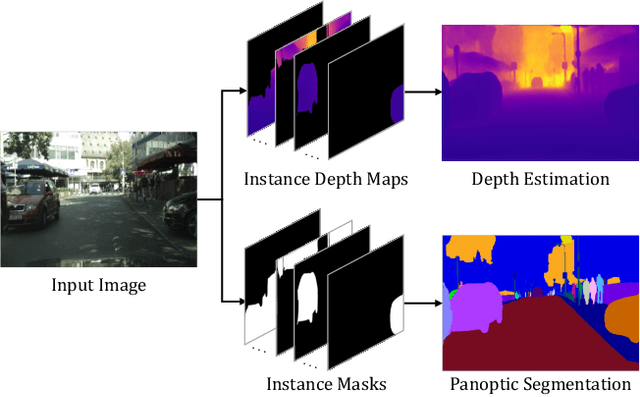
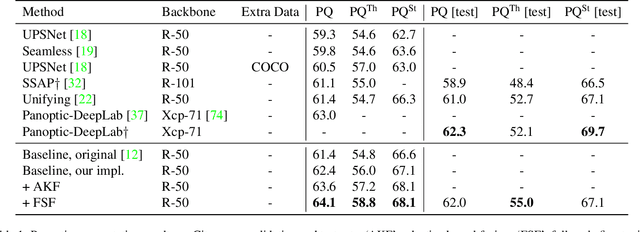
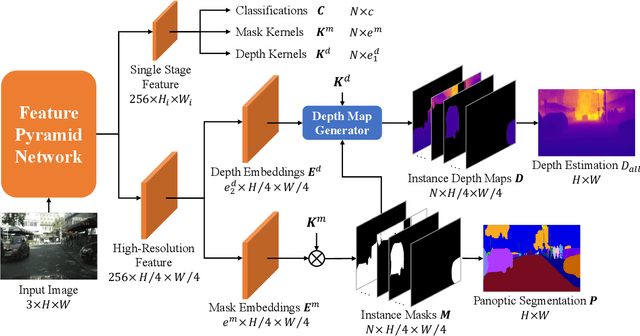

This paper presents a unified framework for depth-aware panoptic segmentation (DPS), which aims to reconstruct 3D scene with instance-level semantics from one single image. Prior works address this problem by simply adding a dense depth regression head to panoptic segmentation (PS) networks, resulting in two independent task branches. This neglects the mutually-beneficial relations between these two tasks, thus failing to exploit handy instance-level semantic cues to boost depth accuracy while also producing sub-optimal depth maps. To overcome these limitations, we propose a unified framework for the DPS task by applying a dynamic convolution technique to both the PS and depth prediction tasks. Specifically, instead of predicting depth for all pixels at a time, we generate instance-specific kernels to predict depth and segmentation masks for each instance. Moreover, leveraging the instance-wise depth estimation scheme, we add additional instance-level depth cues to assist with supervising the depth learning via a new depth loss. Extensive experiments on Cityscapes-DPS and SemKITTI-DPS show the effectiveness and promise of our method. We hope our unified solution to DPS can lead a new paradigm in this area. Code is available at https://github.com/NaiyuGao/PanopticDepth.
Re-parameterizing Your Optimizers rather than Architectures
May 30, 2022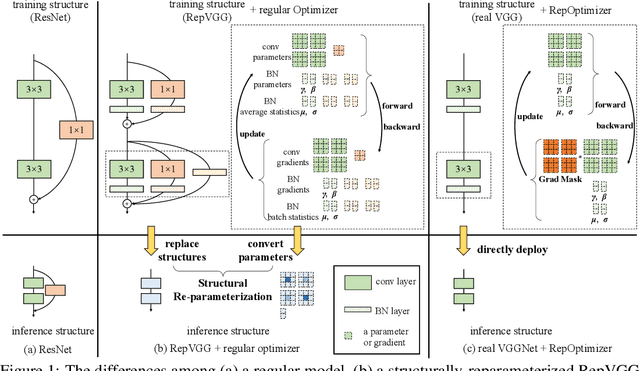

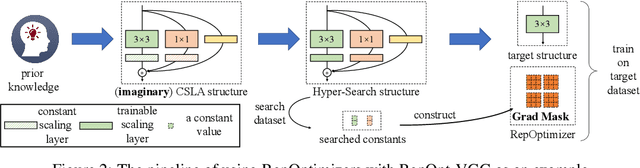
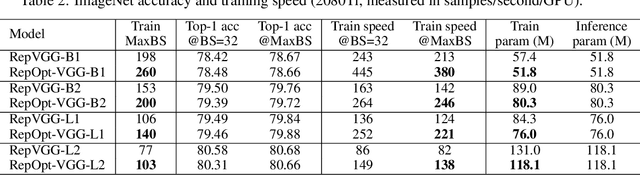
The well-designed structures in neural networks reflect the prior knowledge incorporated into the models. However, though different models have various priors, we are used to training them with model-agnostic optimizers (e.g., SGD). In this paper, we propose a novel paradigm of incorporating model-specific prior knowledge into optimizers and using them to train generic (simple) models. As an implementation, we propose a novel methodology to add prior knowledge by modifying the gradients according to a set of model-specific hyper-parameters, which is referred to as Gradient Re-parameterization, and the optimizers are named RepOptimizers. For the extreme simplicity of model structure, we focus on a VGG-style plain model and showcase that such a simple model trained with a RepOptimizer, which is referred to as RepOpt-VGG, performs on par with the recent well-designed models. From a practical perspective, RepOpt-VGG is a favorable base model because of its simple structure, high inference speed and training efficiency. Compared to Structural Re-parameterization, which adds priors into models via constructing extra training-time structures, RepOptimizers require no extra forward/backward computations and solve the problem of quantization. The code and models are publicly available at https://github.com/DingXiaoH/RepOptimizers.