 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Socio-economic Impacts of Secure Texting and Anti-Jamming Technologies in Non-Cooperative Networks
Apr 10, 2023Operating securely over 5G (and legacy) infrastructure is a challenge. In non-cooperative networks, malicious actors may try to decipher, block encrypted messages, or specifically jam wireless radio systems. Such activities can disrupt operations, from causing minor inconvenience, through to fully paralyzing the functionality of critical infrastructure. While technological mitigation measures do exist, there are very few methods capable of assessing the socio-economic impacts from different mitigation strategies. This leads to a lack of robust evidence to inform cost-benefit analysis, and thus support decision makers in industry and government. Consequently, this paper presents two open-source simulation models for assessing the socio-economic impacts of operating in untrusted non-cooperative networks. The first focuses on using multiple non-cooperative networks to transmit a message. The second model simulates a case where a message is converted into alternative plain language to avoid detection, separated into different portions and then transmitted over multiple non-cooperative networks. A probabilistic simulation of the two models is performed for a 15 km by 15 km spatial grid with 5 untrusted non-cooperative networks and intercepting agents. The results are used to estimate economic losses for private, commercial, government and military sectors. The highest probabilistic total losses for military applications include US$300, US$150, and US$75, incurred for a 1, 3 and 5 site multi-transmission approach, respectively, for non-cooperative networks when considering 1,000 texts being sent. These results form a framework for deterministic socio-economic impact analysis of using non-cooperative networks and secure texting as protection against radio network attacks. The simulation data and the open-source codebase is provided for reproducibility.
Distributed Swarm Learning for Internet of Things at the Edge: Where Artificial Intelligence Meets Biological Intelligence
Oct 29, 2022With the proliferation of versatile Internet of Things (IoT) services, smart IoT devices are increasingly deployed at the edge of wireless networks to perform collaborative machine learning tasks using locally collected data, giving rise to the edge learning paradigm. Due to device restrictions and resource constraints, edge learning among massive IoT devices faces major technical challenges caused by the communication bottleneck, data and device heterogeneity, non-convex optimization, privacy and security concerns, and dynamic environments. To overcome these challenges, this article studies a new framework of distributed swarm learning (DSL) through a holistic integration of artificial intelligence and biological swarm intelligence. Leveraging efficient and robust signal processing and communication techniques, DSL contributes to novel tools for learning and optimization tailored for real-time operations of large-scale IoT in edge wireless environments, which will benefit a wide range of edge IoT applications.
Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation
Sep 15, 2021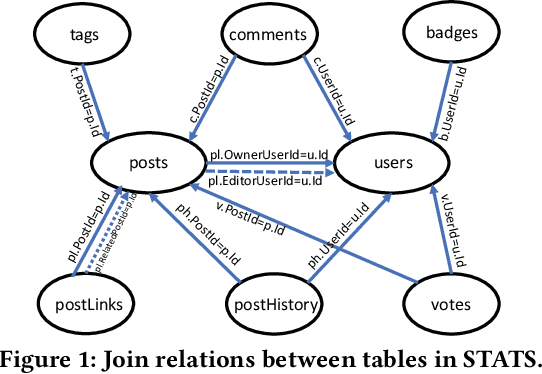
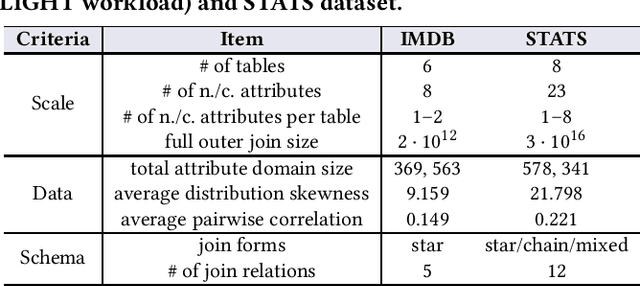
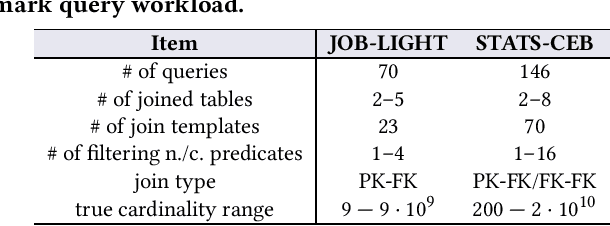
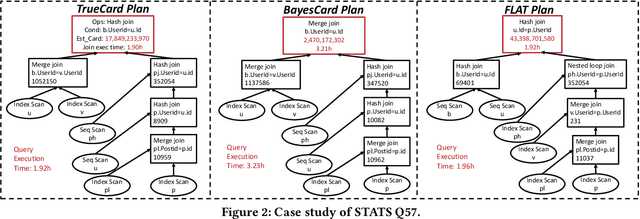
Cardinality estimation (CardEst) plays a significant role in generating high-quality query plans for a query optimizer in DBMS. In the last decade, an increasing number of advanced CardEst methods (especially ML-based) have been proposed with outstanding estimation accuracy and inference latency. However, there exists no study that systematically evaluates the quality of these methods and answer the fundamental problem: to what extent can these methods improve the performance of query optimizer in real-world settings, which is the ultimate goal of a CardEst method. In this paper, we comprehensively and systematically compare the effectiveness of CardEst methods in a real DBMS. We establish a new benchmark for CardEst, which contains a new complex real-world dataset STATS and a diverse query workload STATS-CEB. We integrate multiple most representative CardEst methods into an open-source database system PostgreSQL, and comprehensively evaluate their true effectiveness in improving query plan quality, and other important aspects affecting their applicability, ranging from inference latency, model size, and training time, to update efficiency and accuracy. We obtain a number of key findings for the CardEst methods, under different data and query settings. Furthermore, we find that the widely used estimation accuracy metric(Q-Error) cannot distinguish the importance of different sub-plan queries during query optimization and thus cannot truly reflect the query plan quality generated by CardEst methods. Therefore, we propose a new metric P-Error to evaluate the performance of CardEst methods, which overcomes the limitation of Q-Error and is able to reflect the overall end-to-end performance of CardEst methods. We have made all of the benchmark data and evaluation code publicly available at https://github.com/Nathaniel-Han/End-to-End-CardEst-Benchmark.
A Unified Transferable Model for ML-Enhanced DBMS
May 06, 2021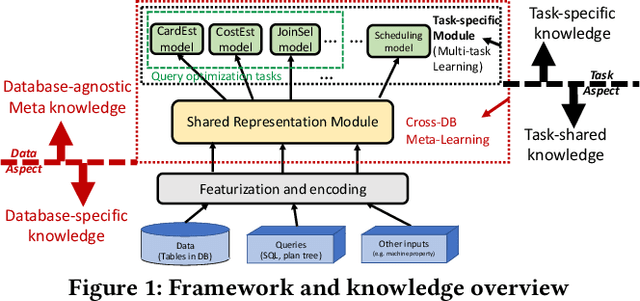
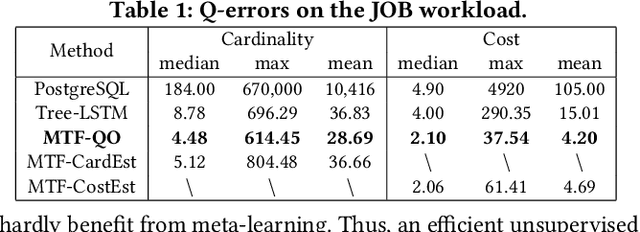
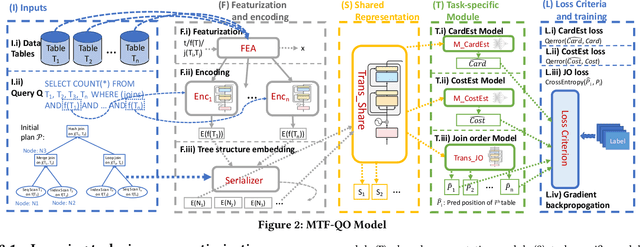
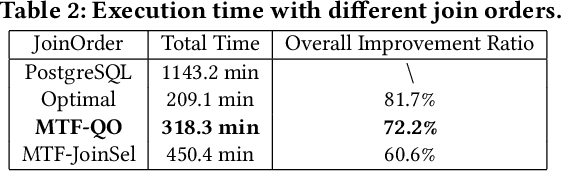
Recently, the database management system (DBMS) community has witnessed the power of machine learning (ML) solutions for DBMS tasks. Despite their promising performance, these existing solutions can hardly be considered satisfactory. First, these ML-based methods in DBMS are not effective enough because they are optimized on each specific task, and cannot explore or understand the intrinsic connections between tasks. Second, the training process has serious limitations that hinder their practicality, because they need to retrain the entire model from scratch for a new DB. Moreover, for each retraining, they require an excessive amount of training data, which is very expensive to acquire and unavailable for a new DB. We propose to explore the transferabilities of the ML methods both across tasks and across DBs to tackle these fundamental drawbacks. In this paper, we propose a unified model MTMLF that uses a multi-task training procedure to capture the transferable knowledge across tasks and a pretrain finetune procedure to distill the transferable meta knowledge across DBs. We believe this paradigm is more suitable for cloud DB service, and has the potential to revolutionize the way how ML is used in DBMS. Furthermore, to demonstrate the predicting power and viability of MTMLF, we provide a concrete and very promising case study on query optimization tasks. Last but not least, we discuss several concrete research opportunities along this line of work.
BayesCard: Revitilizing Bayesian Frameworks for Cardinality Estimation
Feb 02, 2021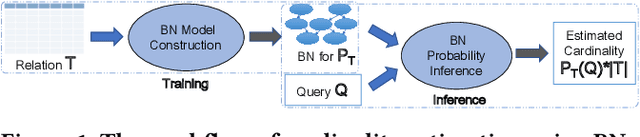
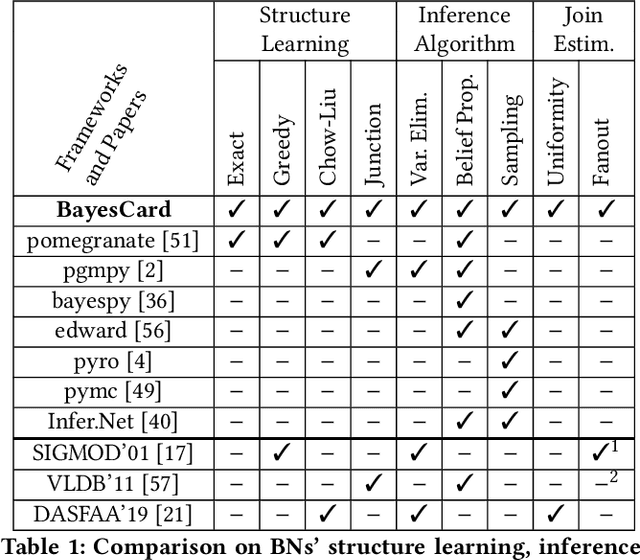
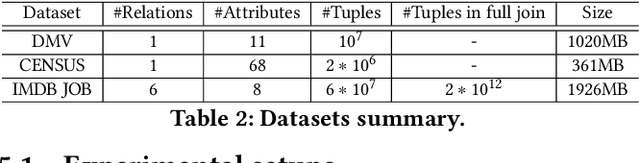
Cardinality estimation (CardEst) is an essential component in query optimizers and a fundamental problem in DBMS. A desired CardEst method should attain good algorithm performance, be stable to varied data settings, and be friendly to system deployment. However, no existing CardEst method can fulfill the three criteria at the same time. Traditional methods often have significant algorithm drawbacks such as large estimation errors. Recently proposed deep learning based methods largely improve the estimation accuracy but their performance can be greatly affected by data and often difficult for system deployment. In this paper, we revitalize the Bayesian networks (BN) for CardEst by incorporating the techniques of probabilistic programming languages. We present BayesCard, the first framework that inherits the advantages of BNs, i.e., high estimation accuracy and interpretability, while overcomes their drawbacks, i.e. low structure learning and inference efficiency. This makes BayesCard a perfect candidate for commercial DBMS deployment. Our experimental results on several single-table and multi-table benchmarks indicate BayesCard's superiority over existing state-of-the-art CardEst methods: BayesCard achieves comparable or better accuracy, 1-2 orders of magnitude faster inference time, 1-3 orders faster training time, 1-3 orders smaller model size, and 1-2 orders faster updates. Meanwhile, BayesCard keeps stable performance when varying data with different settings. We also deploy BayesCard into PostgreSQL. On the IMDB benchmark workload, it improves the end-to-end query time by 13.3%, which is very close to the optimal result of 14.2% using an oracle of true cardinality.
A Pluggable Learned Index Method via Sampling and Gap Insertion
Jan 04, 2021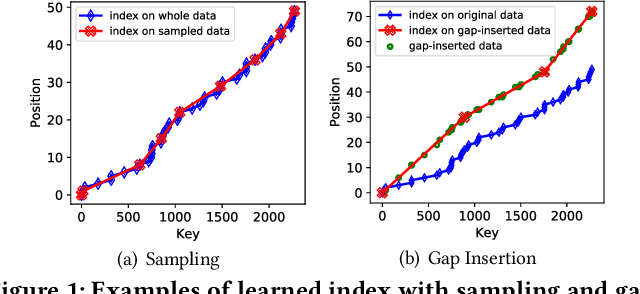
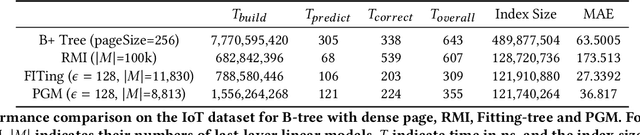
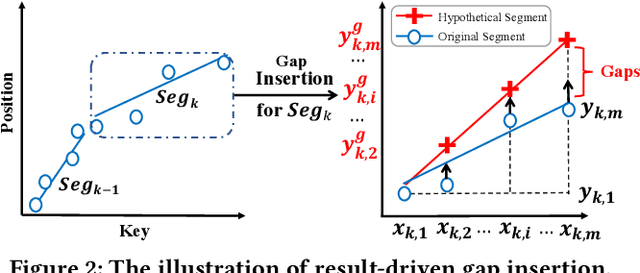
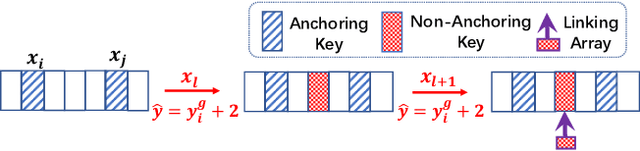
Database indexes facilitate data retrieval and benefit broad applications in real-world systems. Recently, a new family of index, named learned index, is proposed to learn hidden yet useful data distribution and incorporate such information into the learning of indexes, which leads to promising performance improvements. However, the "learning" process of learned indexes is still under-explored. In this paper, we propose a formal machine learning based framework to quantify the index learning objective, and study two general and pluggable techniques to enhance the learning efficiency and learning effectiveness for learned indexes. With the guidance of the formal learning objective, we can efficiently learn index by incorporating the proposed sampling technique, and learn precise index with enhanced generalization ability brought by the proposed result-driven gap insertion technique. We conduct extensive experiments on real-world datasets and compare several indexing methods from the perspective of the index learning objective. The results show the ability of the proposed framework to help to design suitable indexes for different scenarios. Further, we demonstrate the effectiveness of the proposed sampling technique, which achieves up to 78x construction speedup while maintaining non-degraded indexing performance. Finally, we show the gap insertion technique can enhance both the static and dynamic indexing performances of existing learned index methods with up to 1.59x query speedup. We will release our codes and processed data for further study, which can enable more exploration of learned indexes from both the perspectives of machine learning and database.
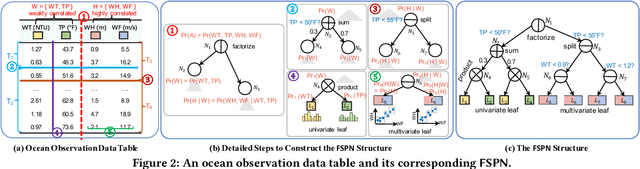
FSPN: A New Class of Probabilistic Graphical Model
Nov 20, 2020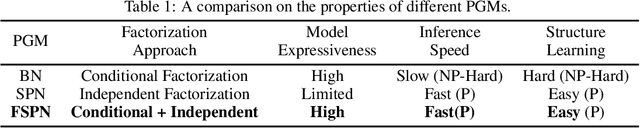
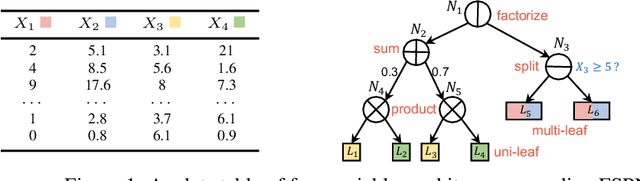
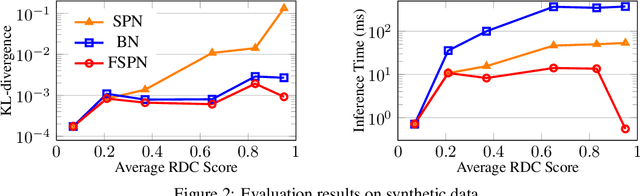
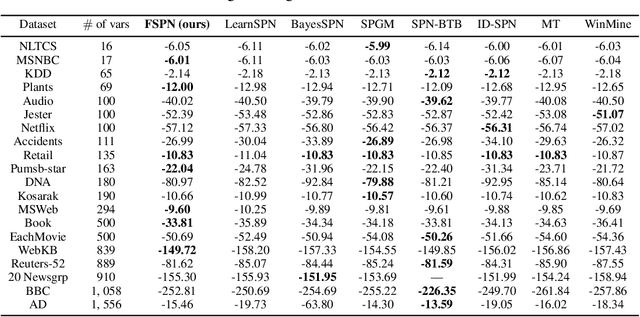
We introduce factorize sum split product networks (FSPNs), a new class of probabilistic graphical models (PGMs). FSPNs are designed to overcome the drawbacks of existing PGMs in terms of estimation accuracy and inference efficiency. Specifically, Bayesian networks (BNs) have low inference speed and performance of tree structured sum product networks(SPNs) significantly degrades in presence of highly correlated variables. FSPNs absorb their advantages by adaptively modeling the joint distribution of variables according to their dependence degree, so that one can simultaneously attain the two desirable goals: high estimation accuracy and fast inference speed. We present efficient probability inference and structure learning algorithms for FSPNs, along with a theoretical analysis and extensive evaluation evidence. Our experimental results on synthetic and benchmark datasets indicate the superiority of FSPN over other PGMs.
FLAT: Fast, Lightweight and Accurate Method for Cardinality Estimation
Nov 18, 2020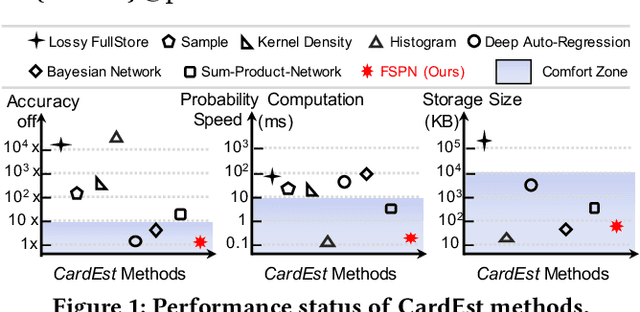
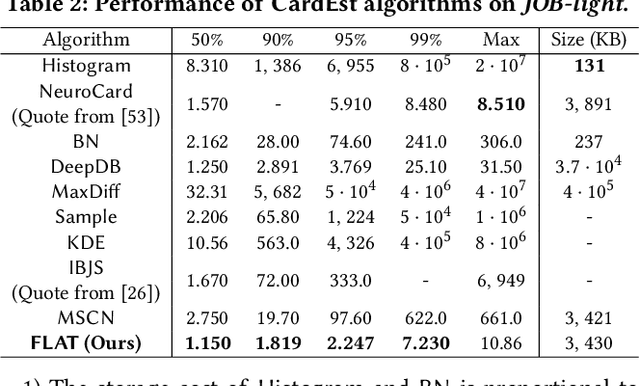

Query optimizers rely on accurate cardinality estimation (CardEst) to produce good execution plans. The core problem of CardEst is how to model the rich joint distribution of attributes in an accurate and compact manner. Despite decades of research, existing methods either over simplify the models only using independent factorization which leads to inaccurate estimates and sub optimal query plans, or over-complicate them by lossless conditional factorization without any independent assumption which results in slow probability computation. In this paper, we propose FLAT, a CardEst method that is simultaneously fast in probability computation, lightweight in model size and accurate in estimation quality. The key idea of FLAT is a novel unsupervised graphical model, called FSPN. It utilizes both independent and conditional factorization to adaptively model different levels of attributes correlations, and thus subsumes all existing CardEst models and dovetails their advantages. FLAT supports efficient online probability computation in near liner time on the underlying FSPN model, and provides effective offline model construction. It can estimate cardinality for both single table queries and multi-table join queries. Extensive experimental study demonstrates the superiority of FLAT over existing CardEst methods on well-known benchmarks: FLAT achieves 1 to 5 orders of magnitude better accuracy, 1 to 3 orders of magnitude faster probability computation speed (around 0.2ms) and 1 to 2 orders of magnitude lower storage cost (only tens of KB).
MicroRec: Accelerating Deep Recommendation Systems to Microseconds by Hardware and Data Structure Solutions
Oct 12, 2020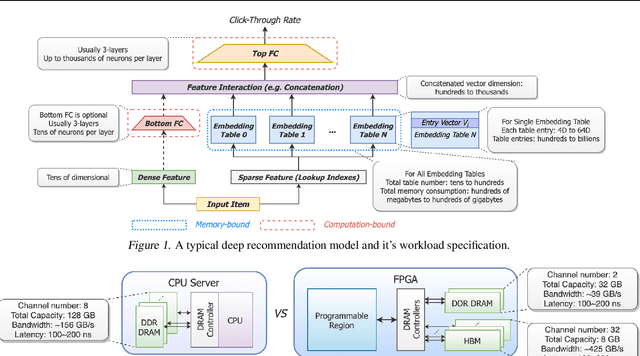
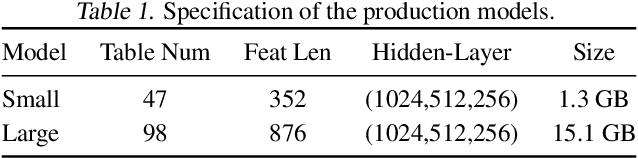
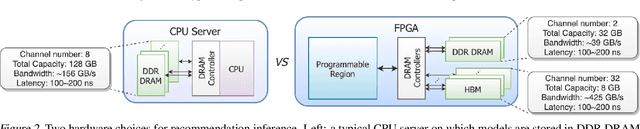
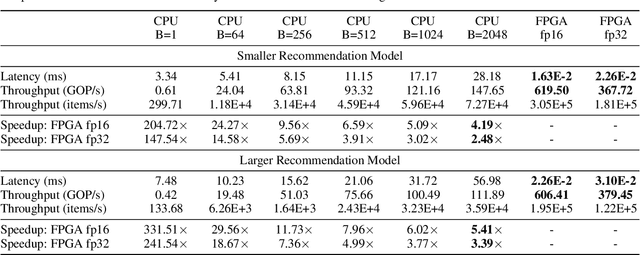
Deep neural networks are widely used in personalized recommendation systems. Unlike regular DNN inference workloads, recommendation inference is memory-bound due to the many random memory accesses needed to lookup the embedding tables. The inference is also heavily constrained in terms of latency because producing a recommendation for a user must be done in about tens of milliseconds. In this paper, we propose MicroRec, a high-performance inference engine for recommendation systems. MicroRec accelerates recommendation inference by (1) redesigning the data structures involved in the embeddings to reduce the number of lookups needed and (2) taking advantage of the availability of High-Bandwidth Memory (HBM) in FPGA accelerators to tackle the latency by enabling parallel lookups. We have implemented the resulting design on an FPGA board including the embedding lookup step as well as the complete inference process. Compared to the optimized CPU baseline (16 vCPU, AVX2-enabled), MicroRec achieves 13.8~14.7x speedup on embedding lookup alone and 2.5$~5.4x speedup for the entire recommendation inference in terms of throughput. As for latency, CPU-based engines needs milliseconds for inferring a recommendation while MicroRec only takes microseconds, a significant advantage in real-time recommendation systems.
Intelligent Policing Strategy for Traffic Violation Prevention
Sep 20, 2019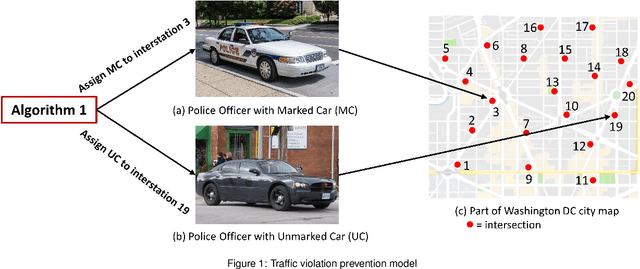

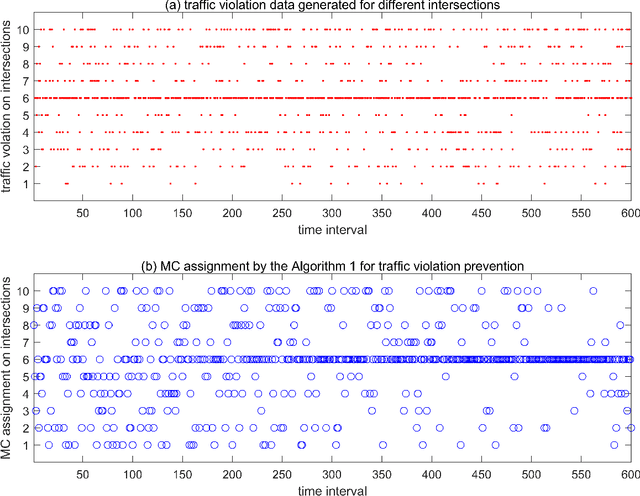
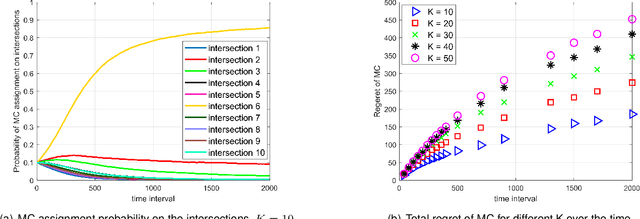
Police officer presence at an intersection discourages a potential traffic violator from violating the law. It also alerts the motorists' consciousness to take precaution and follow the rules. However, due to the abundant intersections and shortage of human resources, it is not possible to assign a police officer to every intersection. In this paper, we propose an intelligent and optimal policing strategy for traffic violation prevention. Our model consists of a specific number of targeted intersections and two police officers with no prior knowledge on the number of the traffic violations in the designated intersections. At each time interval, the proposed strategy, assigns the two police officers to different intersections such that at the end of the time horizon, maximum traffic violation prevention is achieved. Our proposed methodology adapts the PROLA (Play and Random Observe Learning Algorithm) algorithm [1] to achieve an optimal traffic violation prevention strategy. Finally, we conduct a case study to evaluate and demonstrate the performance of the proposed method.