 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceTalk: Audio-Driven Motion Diffusion for Neural Parametric Head Models
Dec 13, 2023



We introduce FaceTalk, a novel generative approach designed for synthesizing high-fidelity 3D motion sequences of talking human heads from input audio signal. To capture the expressive, detailed nature of human heads, including hair, ears, and finer-scale eye movements, we propose to couple speech signal with the latent space of neural parametric head models to create high-fidelity, temporally coherent motion sequences. We propose a new latent diffusion model for this task, operating in the expression space of neural parametric head models, to synthesize audio-driven realistic head sequences. In the absence of a dataset with corresponding NPHM expressions to audio, we optimize for these correspondences to produce a dataset of temporally-optimized NPHM expressions fit to audio-video recordings of people talking. To the best of our knowledge, this is the first work to propose a generative approach for realistic and high-quality motion synthesis of volumetric human heads, representing a significant advancement in the field of audio-driven 3D animation. Notably, our approach stands out in its ability to generate plausible motion sequences that can produce high-fidelity head animation coupled with the NPHM shape space. Our experimental results substantiate the effectiveness of FaceTalk, consistently achieving superior and visually natural motion, encompassing diverse facial expressions and styles, outperforming existing methods by 75% in perceptual user study evaluation.
360° Volumetric Portrait Avatar
Dec 08, 2023



We propose 360{\deg} Volumetric Portrait (3VP) Avatar, a novel method for reconstructing 360{\deg} photo-realistic portrait avatars of human subjects solely based on monocular video inputs. State-of-the-art monocular avatar reconstruction methods rely on stable facial performance capturing. However, the common usage of 3DMM-based facial tracking has its limits; side-views can hardly be captured and it fails, especially, for back-views, as required inputs like facial landmarks or human parsing masks are missing. This results in incomplete avatar reconstructions that only cover the frontal hemisphere. In contrast to this, we propose a template-based tracking of the torso, head and facial expressions which allows us to cover the appearance of a human subject from all sides. Thus, given a sequence of a subject that is rotating in front of a single camera, we train a neural volumetric representation based on neural radiance fields. A key challenge to construct this representation is the modeling of appearance changes, especially, in the mouth region (i.e., lips and teeth). We, therefore, propose a deformation-field-based blend basis which allows us to interpolate between different appearance states. We evaluate our approach on captured real-world data and compare against state-of-the-art monocular reconstruction methods. In contrast to those, our method is the first monocular technique that reconstructs an entire 360{\deg} avatar.
DPHMs: Diffusion Parametric Head Models for Depth-based Tracking
Dec 02, 2023



We introduce Diffusion Parametric Head Models (DPHMs), a generative model that enables robust volumetric head reconstruction and tracking from monocular depth sequences. While recent volumetric head models, such as NPHMs, can now excel in representing high-fidelity head geometries, tracking and reconstruction heads from real-world single-view depth sequences remains very challenging, as the fitting to partial and noisy observations is underconstrained. To tackle these challenges, we propose a latent diffusion-based prior to regularize volumetric head reconstruction and tracking. This prior-based regularizer effectively constrains the identity and expression codes to lie on the underlying latent manifold which represents plausible head shapes. To evaluate the effectiveness of the diffusion-based prior, we collect a dataset of monocular Kinect sequences consisting of various complex facial expression motions and rapid transitions. We compare our method to state-of-the-art tracking methods, and demonstrate improved head identity reconstruction as well as robust expression tracking.
3DiFACE: Diffusion-based Speech-driven 3D Facial Animation and Editing
Dec 01, 2023



We present 3DiFACE, a novel method for personalized speech-driven 3D facial animation and editing. While existing methods deterministically predict facial animations from speech, they overlook the inherent one-to-many relationship between speech and facial expressions, i.e., there are multiple reasonable facial expression animations matching an audio input. It is especially important in content creation to be able to modify generated motion or to specify keyframes. To enable stochasticity as well as motion editing, we propose a lightweight audio-conditioned diffusion model for 3D facial motion. This diffusion model can be trained on a small 3D motion dataset, maintaining expressive lip motion output. In addition, it can be finetuned for specific subjects, requiring only a short video of the person. Through quantitative and qualitative evaluations, we show that our method outperforms existing state-of-the-art techniques and yields speech-driven animations with greater fidelity and diversity.
GAN-Avatar: Controllable Personalized GAN-based Human Head Avatar
Nov 22, 2023



Digital humans and, especially, 3D facial avatars have raised a lot of attention in the past years, as they are the backbone of several applications like immersive telepresence in AR or VR. Despite the progress, facial avatars reconstructed from commodity hardware are incomplete and miss out on parts of the side and back of the head, severely limiting the usability of the avatar. This limitation in prior work stems from their requirement of face tracking, which fails for profile and back views. To address this issue, we propose to learn person-specific animatable avatars from images without assuming to have access to precise facial expression tracking. At the core of our method, we leverage a 3D-aware generative model that is trained to reproduce the distribution of facial expressions from the training data. To train this appearance model, we only assume to have a collection of 2D images with the corresponding camera parameters. For controlling the model, we learn a mapping from 3DMM facial expression parameters to the latent space of the generative model. This mapping can be learned by sampling the latent space of the appearance model and reconstructing the facial parameters from a normalized frontal view, where facial expression estimation performs well. With this scheme, we decouple 3D appearance reconstruction and animation control to achieve high fidelity in image synthesis. In a series of experiments, we compare our proposed technique to state-of-the-art monocular methods and show superior quality while not requiring expression tracking of the training data.
Drivable 3D Gaussian Avatars
Nov 14, 2023We present Drivable 3D Gaussian Avatars (D3GA), the first 3D controllable model for human bodies rendered with Gaussian splats. Current photorealistic drivable avatars require either accurate 3D registrations during training, dense input images during testing, or both. The ones based on neural radiance fields also tend to be prohibitively slow for telepresence applications. This work uses the recently presented 3D Gaussian Splatting (3DGS) technique to render realistic humans at real-time framerates, using dense calibrated multi-view videos as input. To deform those primitives, we depart from the commonly used point deformation method of linear blend skinning (LBS) and use a classic volumetric deformation method: cage deformations. Given their smaller size, we drive these deformations with joint angles and keypoints, which are more suitable for communication applications. Our experiments on nine subjects with varied body shapes, clothes, and motions obtain higher-quality results than state-of-the-art methods when using the same training and test data.
Text-Guided Generation and Editing of Compositional 3D Avatars
Sep 13, 2023



Our goal is to create a realistic 3D facial avatar with hair and accessories using only a text description. While this challenge has attracted significant recent interest, existing methods either lack realism, produce unrealistic shapes, or do not support editing, such as modifications to the hairstyle. We argue that existing methods are limited because they employ a monolithic modeling approach, using a single representation for the head, face, hair, and accessories. Our observation is that the hair and face, for example, have very different structural qualities that benefit from different representations. Building on this insight, we generate avatars with a compositional model, in which the head, face, and upper body are represented with traditional 3D meshes, and the hair, clothing, and accessories with neural radiance fields (NeRF). The model-based mesh representation provides a strong geometric prior for the face region, improving realism while enabling editing of the person's appearance. By using NeRFs to represent the remaining components, our method is able to model and synthesize parts with complex geometry and appearance, such as curly hair and fluffy scarves. Our novel system synthesizes these high-quality compositional avatars from text descriptions. The experimental results demonstrate that our method, Text-guided generation and Editing of Compositional Avatars (TECA), produces avatars that are more realistic than those of recent methods while being editable because of their compositional nature. For example, our TECA enables the seamless transfer of compositional features like hairstyles, scarves, and other accessories between avatars. This capability supports applications such as virtual try-on.
SCULPT: Shape-Conditioned Unpaired Learning of Pose-dependent Clothed and Textured Human Meshes
Aug 21, 2023



We present SCULPT, a novel 3D generative model for clothed and textured 3D meshes of humans. Specifically, we devise a deep neural network that learns to represent the geometry and appearance distribution of clothed human bodies. Training such a model is challenging, as datasets of textured 3D meshes for humans are limited in size and accessibility. Our key observation is that there exist medium-sized 3D scan datasets like CAPE, as well as large-scale 2D image datasets of clothed humans and multiple appearances can be mapped to a single geometry. To effectively learn from the two data modalities, we propose an unpaired learning procedure for pose-dependent clothed and textured human meshes. Specifically, we learn a pose-dependent geometry space from 3D scan data. We represent this as per vertex displacements w.r.t. the SMPL model. Next, we train a geometry conditioned texture generator in an unsupervised way using the 2D image data. We use intermediate activations of the learned geometry model to condition our texture generator. To alleviate entanglement between pose and clothing type, and pose and clothing appearance, we condition both the texture and geometry generators with attribute labels such as clothing types for the geometry, and clothing colors for the texture generator. We automatically generated these conditioning labels for the 2D images based on the visual question answering model BLIP and CLIP. We validate our method on the SCULPT dataset, and compare to state-of-the-art 3D generative models for clothed human bodies. We will release the codebase for research purposes.
TADA! Text to Animatable Digital Avatars
Aug 21, 2023

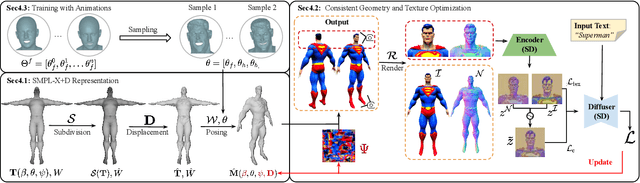

We introduce TADA, a simple-yet-effective approach that takes textual descriptions and produces expressive 3D avatars with high-quality geometry and lifelike textures, that can be animated and rendered with traditional graphics pipelines. Existing text-based character generation methods are limited in terms of geometry and texture quality, and cannot be realistically animated due to inconsistent alignment between the geometry and the texture, particularly in the face region. To overcome these limitations, TADA leverages the synergy of a 2D diffusion model and an animatable parametric body model. Specifically, we derive an optimizable high-resolution body model from SMPL-X with 3D displacements and a texture map, and use hierarchical rendering with score distillation sampling (SDS) to create high-quality, detailed, holistic 3D avatars from text. To ensure alignment between the geometry and texture, we render normals and RGB images of the generated character and exploit their latent embeddings in the SDS training process. We further introduce various expression parameters to deform the generated character during training, ensuring that the semantics of our generated character remain consistent with the original SMPL-X model, resulting in an animatable character. Comprehensive evaluations demonstrate that TADA significantly surpasses existing approaches on both qualitative and quantitative measures. TADA enables creation of large-scale digital character assets that are ready for animation and rendering, while also being easily editable through natural language. The code will be public for research purposes.
TeCH: Text-guided Reconstruction of Lifelike Clothed Humans
Aug 19, 2023Despite recent research advancements in reconstructing clothed humans from a single image, accurately restoring the "unseen regions" with high-level details remains an unsolved challenge that lacks attention. Existing methods often generate overly smooth back-side surfaces with a blurry texture. But how to effectively capture all visual attributes of an individual from a single image, which are sufficient to reconstruct unseen areas (e.g., the back view)? Motivated by the power of foundation models, TeCH reconstructs the 3D human by leveraging 1) descriptive text prompts (e.g., garments, colors, hairstyles) which are automatically generated via a garment parsing model and Visual Question Answering (VQA), 2) a personalized fine-tuned Text-to-Image diffusion model (T2I) which learns the "indescribable" appearance. To represent high-resolution 3D clothed humans at an affordable cost, we propose a hybrid 3D representation based on DMTet, which consists of an explicit body shape grid and an implicit distance field. Guided by the descriptive prompts + personalized T2I diffusion model, the geometry and texture of the 3D humans are optimized through multi-view Score Distillation Sampling (SDS) and reconstruction losses based on the original observation. TeCH produces high-fidelity 3D clothed humans with consistent & delicate texture, and detailed full-body geometry. Quantitative and qualitative experiments demonstrate that TeCH outperforms the state-of-the-art methods in terms of reconstruction accuracy and rendering quality. The code will be publicly available for research purposes at https://huangyangyi.github.io/TeCH