 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training helps Bayesian optimization too
Jul 07, 2022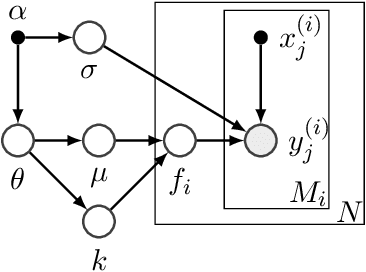
Bayesian optimization (BO) has become a popular strategy for global optimization of many expensive real-world functions. Contrary to a common belief that BO is suited to optimizing black-box functions, it actually requires domain knowledge on characteristics of those functions to deploy BO successfully. Such domain knowledge often manifests in Gaussian process priors that specify initial beliefs on functions. However, even with expert knowledge, it is not an easy task to select a prior. This is especially true for hyperparameter tuning problems on complex machine learning models, where landscapes of tuning objectives are often difficult to comprehend. We seek an alternative practice for setting these functional priors. In particular, we consider the scenario where we have data from similar functions that allow us to pre-train a tighter distribution a priori. To verify our approach in realistic model training setups, we collected a large multi-task hyperparameter tuning dataset by training tens of thousands of configurations of near-state-of-the-art models on popular image and text datasets, as well as a protein sequence dataset. Our results show that on average, our method is able to locate good hyperparameters at least 3 times more efficiently than the best competing methods.
AI system for fetal ultrasound in low-resource settings
Mar 18, 2022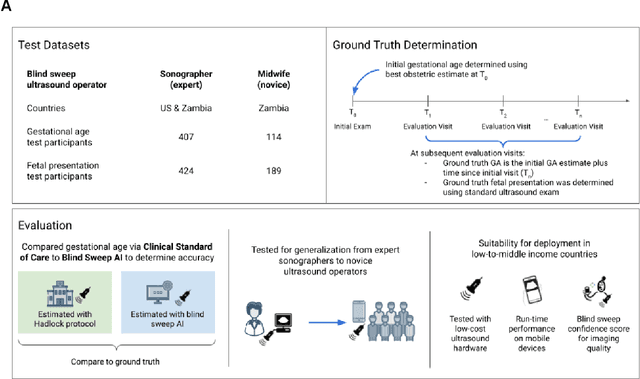
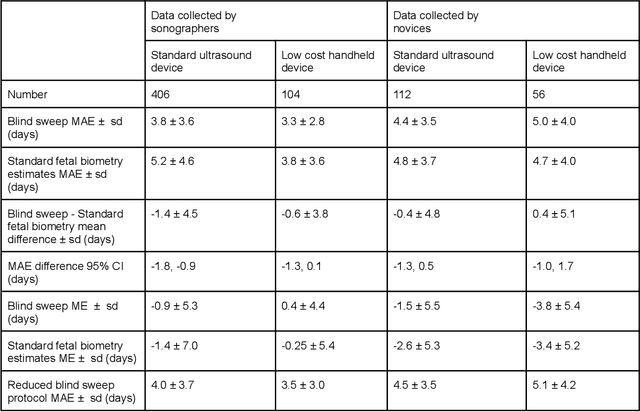
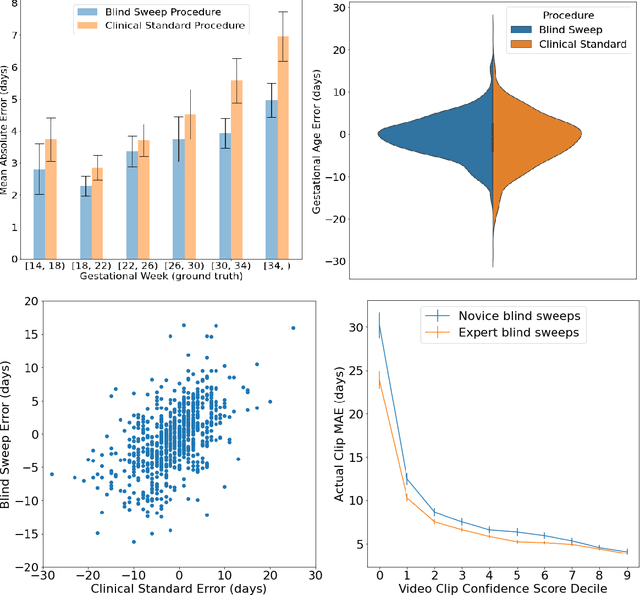
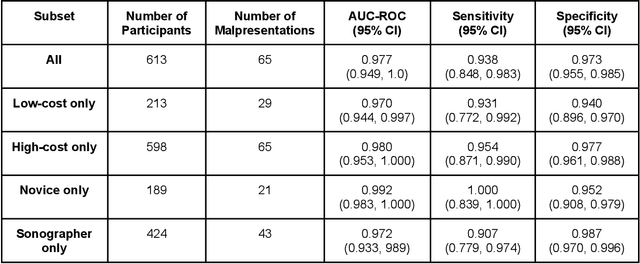
Despite considerable progress in maternal healthcare, maternal and perinatal deaths remain high in low-to-middle income countries. Fetal ultrasound is an important component of antenatal care, but shortage of adequately trained healthcare workers has limited its adoption. We developed and validated an artificial intelligence (AI) system that uses novice-acquired "blind sweep" ultrasound videos to estimate gestational age (GA) and fetal malpresentation. We further addressed obstacles that may be encountered in low-resourced settings. Using a simplified sweep protocol with real-time AI feedback on sweep quality, we have demonstrated the generalization of model performance to minimally trained novice ultrasound operators using low cost ultrasound devices with on-device AI integration. The GA model was non-inferior to standard fetal biometry estimates with as few as two sweeps, and the fetal malpresentation model had high AUC-ROCs across operators and devices. Our AI models have the potential to assist in upleveling the capabilities of lightly trained ultrasound operators in low resource settings.
Predicting the utility of search spaces for black-box optimization: a simple, budget-aware approach
Dec 16, 2021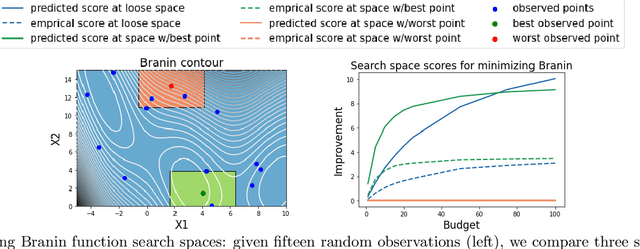

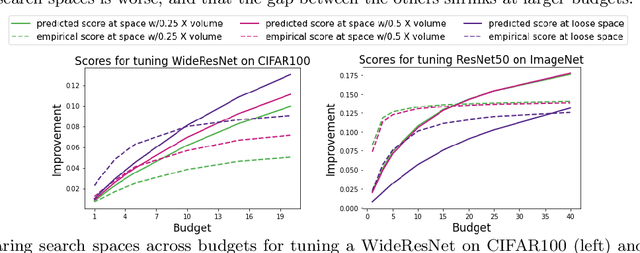

Black box optimization requires specifying a search space to explore for solutions, e.g. a d-dimensional compact space, and this choice is critical for getting the best results at a reasonable budget. Unfortunately, determining a high quality search space can be challenging in many applications. For example, when tuning hyperparameters for machine learning pipelines on a new problem given a limited budget, one must strike a balance between excluding potentially promising regions and keeping the search space small enough to be tractable. The goal of this work is to motivate -- through example applications in tuning deep neural networks -- the problem of predicting the quality of search spaces conditioned on budgets, as well as to provide a simple scoring method based on a utility function applied to a probabilistic response surface model, similar to Bayesian optimization. We show that the method we present can compute meaningful budget-conditional scores in a variety of situations. We also provide experimental evidence that accurate scores can be useful in constructing and pruning search spaces. Ultimately, we believe scoring search spaces should become standard practice in the experimental workflow for deep learning.
A Loss Curvature Perspective on Training Instability in Deep Learning
Oct 08, 2021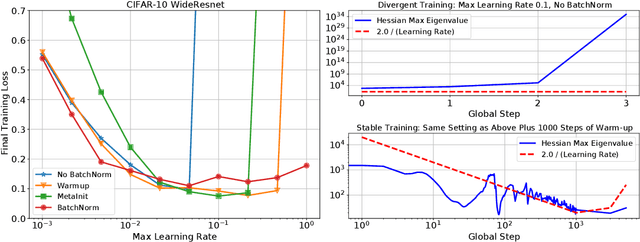

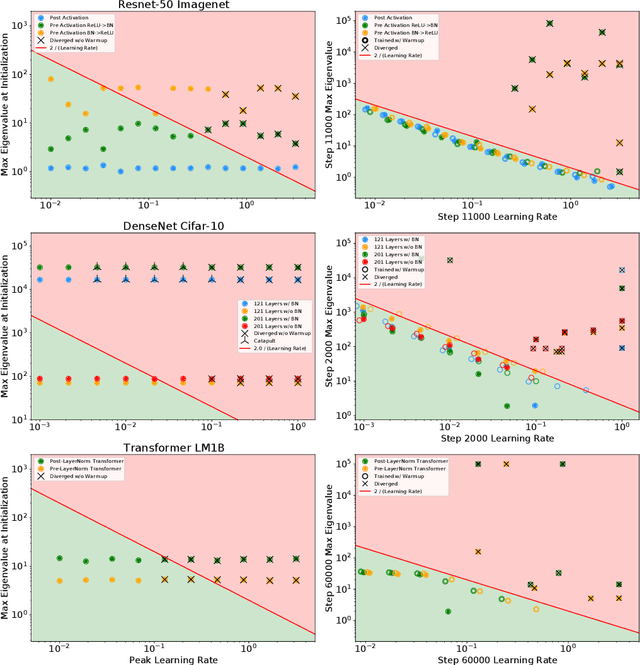

In this work, we study the evolution of the loss Hessian across many classification tasks in order to understand the effect the curvature of the loss has on the training dynamics. Whereas prior work has focused on how different learning rates affect the loss Hessian observed during training, we also analyze the effects of model initialization, architectural choices, and common training heuristics such as gradient clipping and learning rate warmup. Our results demonstrate that successful model and hyperparameter choices allow the early optimization trajectory to either avoid -- or navigate out of -- regions of high curvature and into flatter regions that tolerate a higher learning rate. Our results suggest a unifying perspective on how disparate mitigation strategies for training instability ultimately address the same underlying failure mode of neural network optimization, namely poor conditioning. Inspired by the conditioning perspective, we show that learning rate warmup can improve training stability just as much as batch normalization, layer normalization, MetaInit, GradInit, and Fixup initialization.
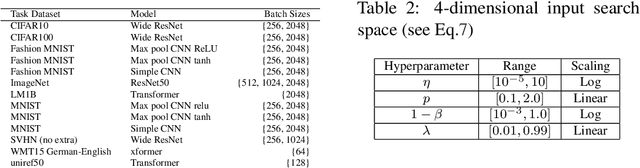
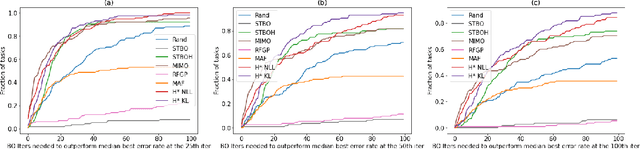
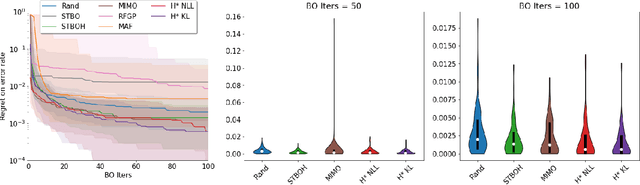
Automatic prior selection for meta Bayesian optimization with a case study on tuning deep neural network optimizers
Sep 16, 2021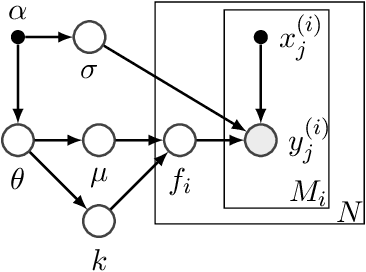
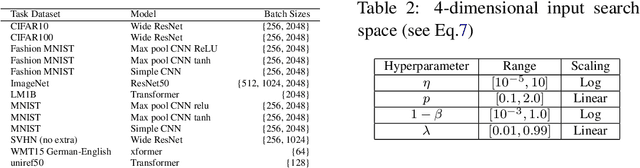
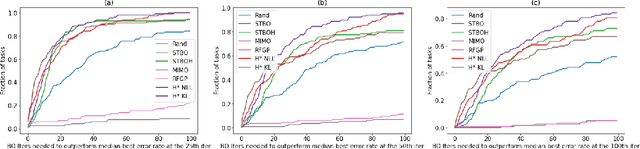
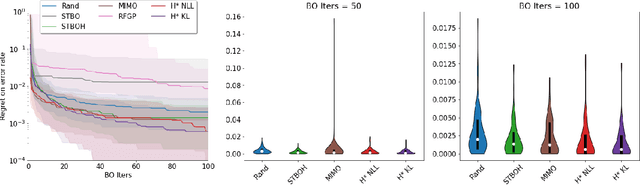
The performance of deep neural networks can be highly sensitive to the choice of a variety of meta-parameters, such as optimizer parameters and model hyperparameters. Tuning these well, however, often requires extensive and costly experimentation. Bayesian optimization (BO) is a principled approach to solve such expensive hyperparameter tuning problems efficiently. Key to the performance of BO is specifying and refining a distribution over functions, which is used to reason about the optima of the underlying function being optimized. In this work, we consider the scenario where we have data from similar functions that allows us to specify a tighter distribution a priori. Specifically, we focus on the common but potentially costly task of tuning optimizer parameters for training neural networks. Building on the meta BO method from Wang et al. (2018), we develop practical improvements that (a) boost its performance by leveraging tuning results on multiple tasks without requiring observations for the same meta-parameter points across all tasks, and (b) retain its regret bound for a special case of our method. As a result, we provide a coherent BO solution for iterative optimization of continuous optimizer parameters. To verify our approach in realistic model training setups, we collected a large multi-task hyperparameter tuning dataset by training tens of thousands of configurations of near-state-of-the-art models on popular image and text datasets, as well as a protein sequence dataset. Our results show that on average, our method is able to locate good hyperparameters at least 3 times more efficiently than the best competing methods.
The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization
Jun 29, 2020
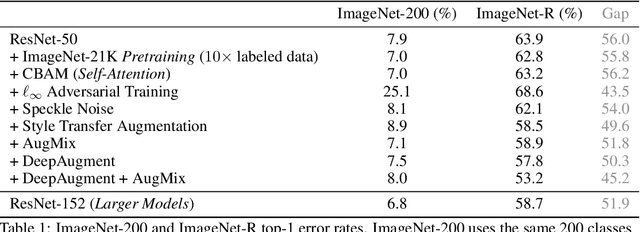

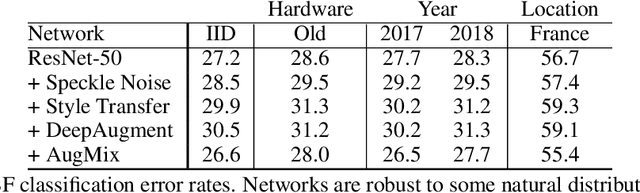
We introduce three new robustness benchmarks consisting of naturally occurring distribution changes in image style, geographic location, camera operation, and more. Using our benchmarks, we take stock of previously proposed hypotheses for out-of-distribution robustness and put them to the test. We find that using larger models and synthetic data augmentation can improve robustness on real-world distribution shifts, contrary to claims in prior work. Motivated by this, we introduce a new data augmentation method which advances the state-of-the-art and outperforms models pretrained with 1000x more labeled data. We find that some methods consistently help with distribution shifts in texture and local image statistics, but these methods do not help with some other distribution shifts like geographic changes. We conclude that future research must study multiple distribution shifts simultaneously.
AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty
Dec 05, 2019
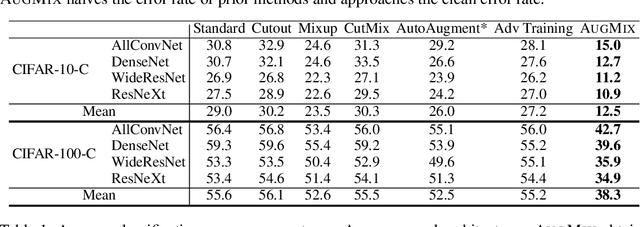

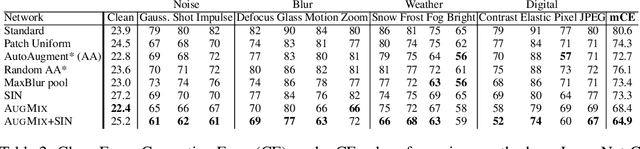
Modern deep neural networks can achieve high accuracy when the training distribution and test distribution are identically distributed, but this assumption is frequently violated in practice. When the train and test distributions are mismatched, accuracy can plummet. Currently there are few techniques that improve robustness to unforeseen data shifts encountered during deployment. In this work, we propose a technique to improve the robustness and uncertainty estimates of image classifiers. We propose AugMix, a data processing technique that is simple to implement, adds limited computational overhead, and helps models withstand unforeseen corruptions. AugMix significantly improves robustness and uncertainty measures on challenging image classification benchmarks, closing the gap between previous methods and the best possible performance in some cases by more than half.
A Fourier Perspective on Model Robustness in Computer Vision
Jun 21, 2019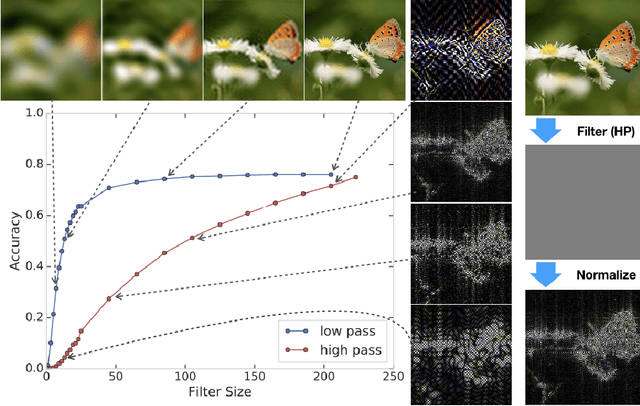

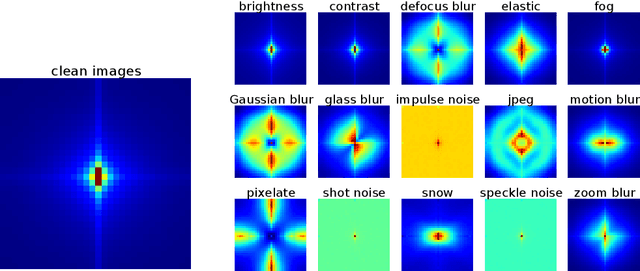
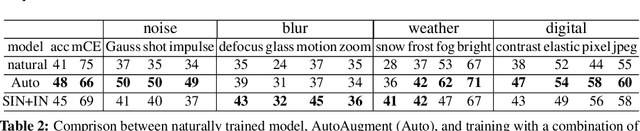
Achieving robustness to distributional shift is a longstanding and challenging goal of computer vision. Data augmentation is a commonly used approach for improving robustness, however robustness gains are typically not uniform across corruption types. Indeed increasing performance in the presence of random noise is often met with reduced performance on other corruptions such as contrast change. Understanding when and why these sorts of trade-offs occur is a crucial step towards mitigating them. Towards this end, we investigate recently observed trade-offs caused by Gaussian data augmentation and adversarial training. We find that both methods improve robustness to corruptions that are concentrated in the high frequency domain while reducing robustness to corruptions that are concentrated in the low frequency domain. This suggests that one way to mitigate these trade-offs via data augmentation is to use a more diverse set of augmentations. Towards this end we observe that AutoAugment, a recently proposed data augmentation policy optimized for clean accuracy, achieves state-of-the-art robustness on the CIFAR-10-C and ImageNet-C benchmarks.
Improving Robustness Without Sacrificing Accuracy with Patch Gaussian Augmentation
Jun 06, 2019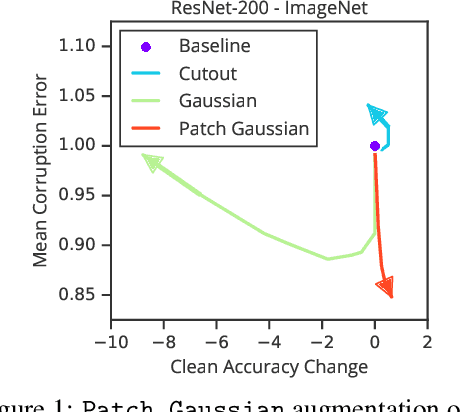
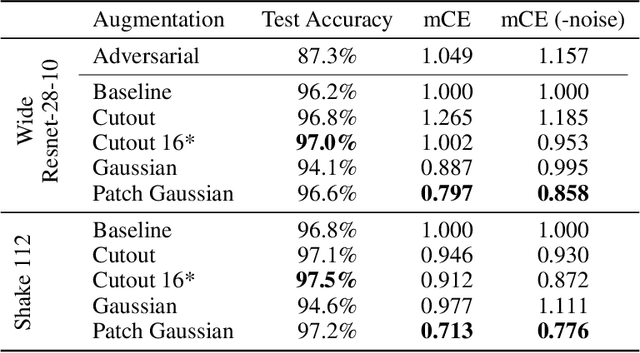
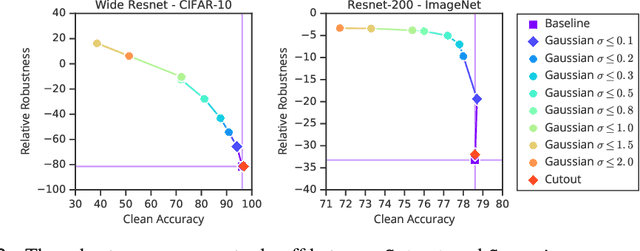
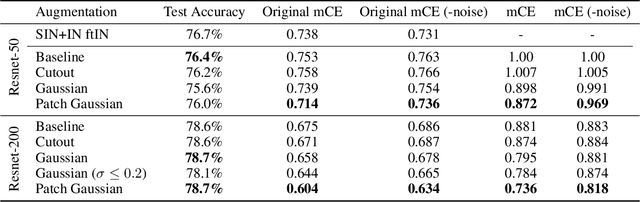
Deploying machine learning systems in the real world requires both high accuracy on clean data and robustness to naturally occurring corruptions. While architectural advances have led to improved accuracy, building robust models remains challenging. Prior work has argued that there is an inherent trade-off between robustness and accuracy, which is exemplified by standard data augment techniques such as Cutout, which improves clean accuracy but not robustness, and additive Gaussian noise, which improves robustness but hurts accuracy. To overcome this trade-off, we introduce Patch Gaussian, a simple augmentation scheme that adds noise to randomly selected patches in an input image. Models trained with Patch Gaussian achieve state of the art on the CIFAR-10 and ImageNetCommon Corruptions benchmarks while also improving accuracy on clean data. We find that this augmentation leads to reduced sensitivity to high frequency noise(similar to Gaussian) while retaining the ability to take advantage of relevant high frequency information in the image (similar to Cutout). Finally, we show that Patch Gaussian can be used in conjunction with other regularization methods and data augmentation policies such as AutoAugment, and improves performance on the COCO object detection benchmark.
MNIST-C: A Robustness Benchmark for Computer Vision
Jun 05, 2019

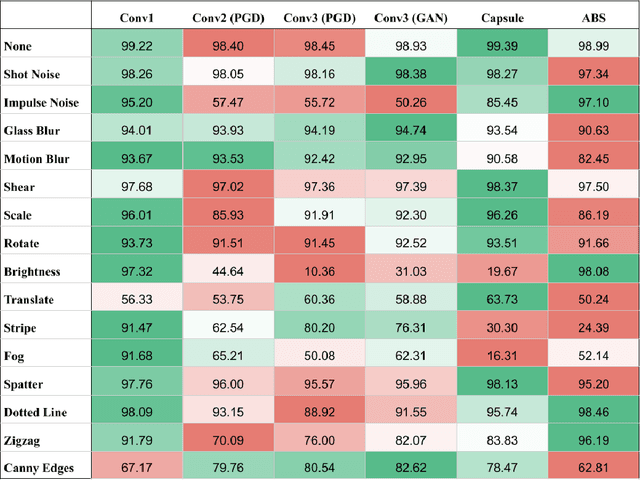
We introduce the MNIST-C dataset, a comprehensive suite of 15 corruptions applied to the MNIST test set, for benchmarking out-of-distribution robustness in computer vision. Through several experiments and visualizations we demonstrate that our corruptions significantly degrade performance of state-of-the-art computer vision models while preserving the semantic content of the test images. In contrast to the popular notion of adversarial robustness, our model-agnostic corruptions do not seek worst-case performance but are instead designed to be broad and diverse, capturing multiple failure modes of modern models. In fact, we find that several previously published adversarial defenses significantly degrade robustness as measured by MNIST-C. We hope that our benchmark serves as a useful tool for future work in designing systems that are able to learn robust feature representations that capture the underlying semantics of the input.