 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Bidding with Multi-Agent Reinforcement Learning in Display Advertising
Sep 11, 2018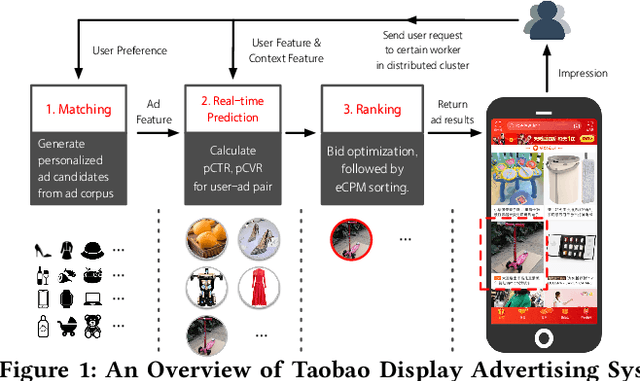
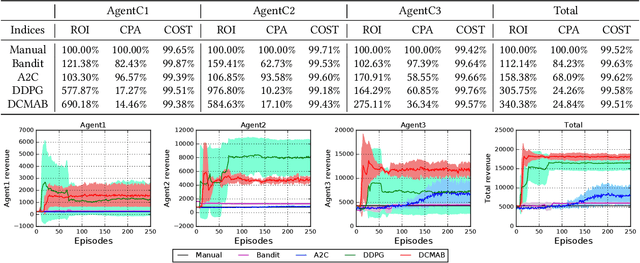
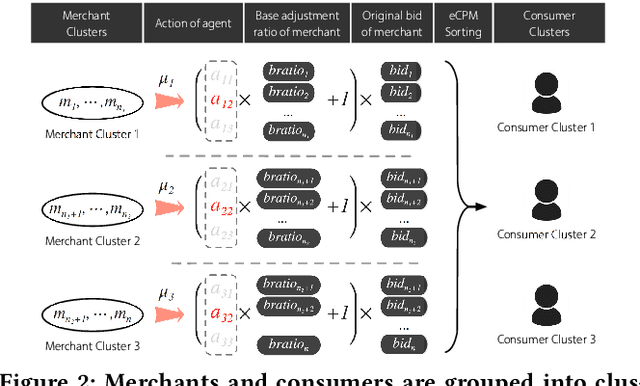
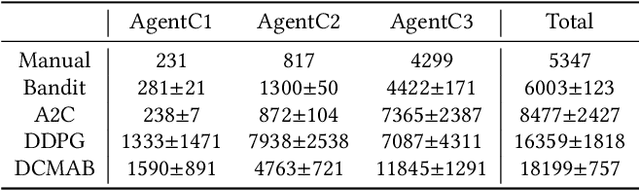
Real-time advertising allows advertisers to bid for each impression for a visiting user. To optimize specific goals such as maximizing revenue and return on investment (ROI) led by ad placements, advertisers not only need to estimate the relevance between the ads and user's interests, but most importantly require a strategic response with respect to other advertisers bidding in the market. In this paper, we formulate bidding optimization with multi-agent reinforcement learning. To deal with a large number of advertisers, we propose a clustering method and assign each cluster with a strategic bidding agent. A practical Distributed Coordinated Multi-Agent Bidding (DCMAB) has been proposed and implemented to balance the tradeoff between the competition and cooperation among advertisers. The empirical study on our industry-scaled real-world data has demonstrated the effectiveness of our methods. Our results show cluster-based bidding would largely outperform single-agent and bandit approaches, and the coordinated bidding achieves better overall objectives than purely self-interested bidding agents.
Learning to Advertise with Adaptive Exposure via Constrained Two-Level Reinforcement Learning
Sep 10, 2018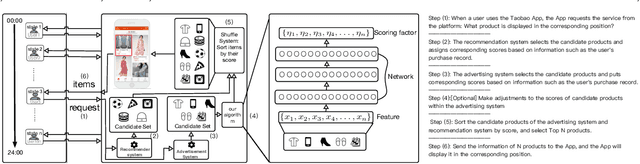
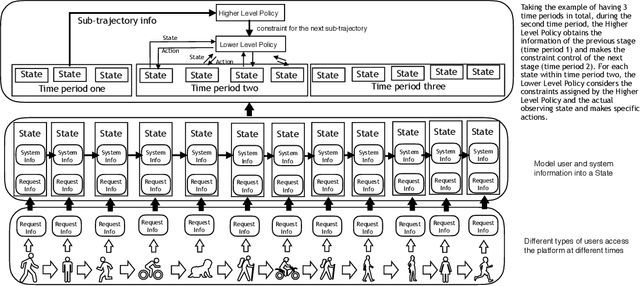

For online advertising in e-commerce, the traditional problem is to assign the right ad to the right user on fixed ad slots. In this paper, we investigate the problem of advertising with adaptive exposure, in which the number of ad slots and their locations can dynamically change over time based on their relative scores with recommendation products. In order to maintain user retention and long-term revenue, there are two types of constraints that need to be met in exposure: query-level and day-level constraints. We model this problem as constrained markov decision process with per-state constraint (psCMDP) and propose a constrained two-level reinforcement learning to decouple the original advertising exposure optimization problem into two relatively independent sub-optimization problems. We also propose a constrained hindsight experience replay mechanism to accelerate the policy training process. Experimental results show that our method can improve the advertising revenue while satisfying different levels of constraints under the real-world datasets. Besides, the proposal of constrained hindsight experience replay mechanism can significantly improve the training speed and the stability of policy performance.
Optimizing Recurrent Neural Networks Architectures under Time Constraints
Feb 21, 2018
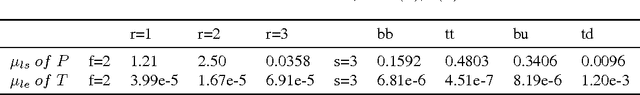
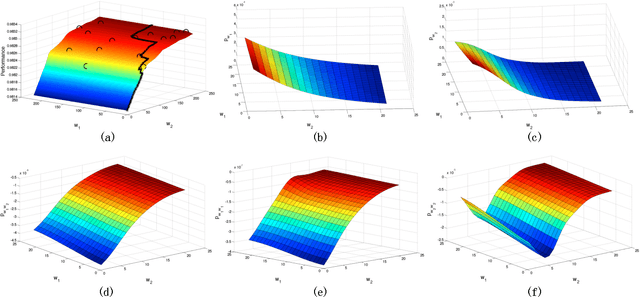
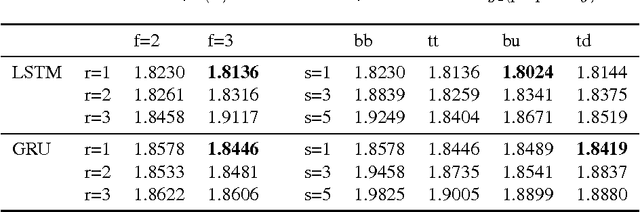
Recurrent neural network (RNN)'s architecture is a key factor influencing its performance. We propose algorithms to optimize hidden sizes under running time constraint. We convert the discrete optimization into a subset selection problem. By novel transformations, the objective function becomes submodular and constraint becomes supermodular. A greedy algorithm with bounds is suggested to solve the transformed problem. And we show how transformations influence the bounds. To speed up optimization, surrogate functions are proposed which balance exploration and exploitation. Experiments show that our algorithms can find more accurate models or faster models than manually tuned state-of-the-art and random search. We also compare popular RNN architectures using our algorithms.
Neural Network Architecture Optimization through Submodularity and Supermodularity
Feb 21, 2018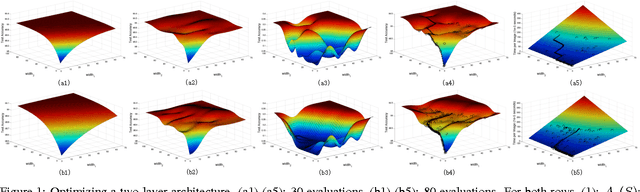
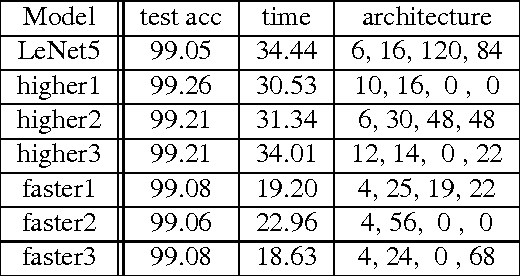
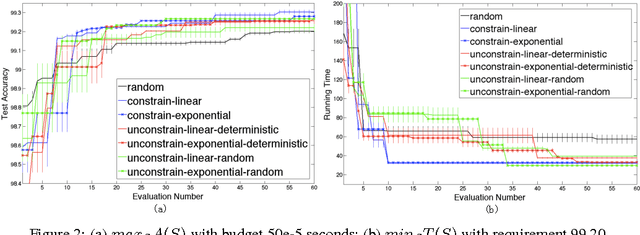
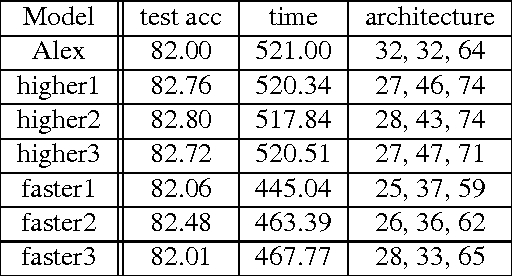
Deep learning models' architectures, including depth and width, are key factors influencing models' performance, such as test accuracy and computation time. This paper solves two problems: given computation time budget, choose an architecture to maximize accuracy, and given accuracy requirement, choose an architecture to minimize computation time. We convert this architecture optimization into a subset selection problem. With accuracy's submodularity and computation time's supermodularity, we propose efficient greedy optimization algorithms. The experiments demonstrate our algorithm's ability to find more accurate models or faster models. By analyzing architecture evolution with growing time budget, we discuss relationships among accuracy, time and architecture, and give suggestions on neural network architecture design.
Aligning where to see and what to tell: image caption with region-based attention and scene factorization
Jun 20, 2015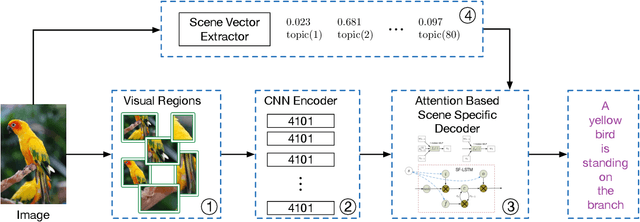
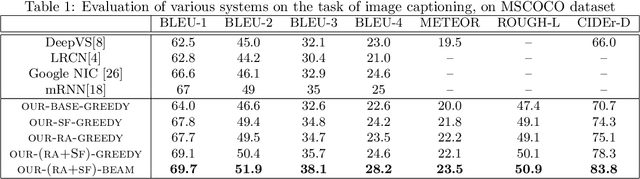
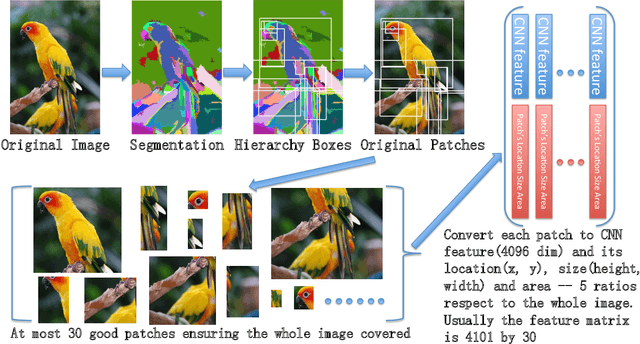
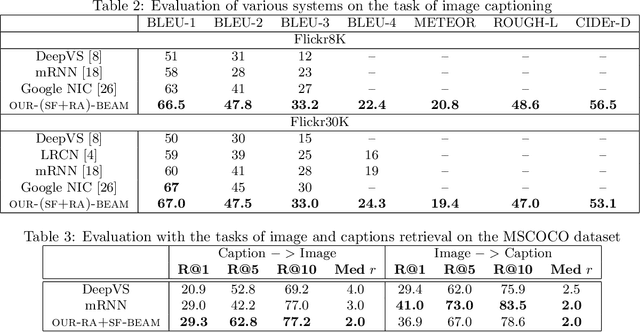
Recent progress on automatic generation of image captions has shown that it is possible to describe the most salient information conveyed by images with accurate and meaningful sentences. In this paper, we propose an image caption system that exploits the parallel structures between images and sentences. In our model, the process of generating the next word, given the previously generated ones, is aligned with the visual perception experience where the attention shifting among the visual regions imposes a thread of visual ordering. This alignment characterizes the flow of "abstract meaning", encoding what is semantically shared by both the visual scene and the text description. Our system also makes another novel modeling contribution by introducing scene-specific contexts that capture higher-level semantic information encoded in an image. The contexts adapt language models for word generation to specific scene types. We benchmark our system and contrast to published results on several popular datasets. We show that using either region-based attention or scene-specific contexts improves systems without those components. Furthermore, combining these two modeling ingredients attains the state-of-the-art performance.