 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking While Moving: Deep Reinforcement Learning with Concurrent Control
Apr 25, 2020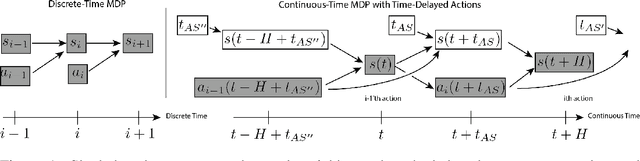
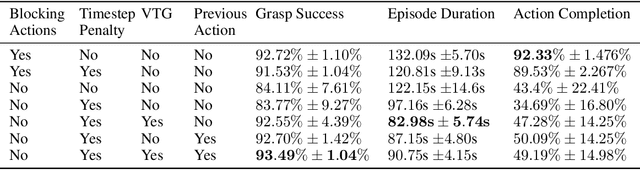
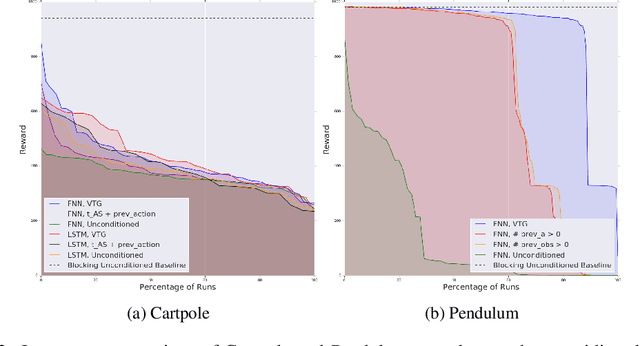

We study reinforcement learning in settings where sampling an action from the policy must be done concurrently with the time evolution of the controlled system, such as when a robot must decide on the next action while still performing the previous action. Much like a person or an animal, the robot must think and move at the same time, deciding on its next action before the previous one has completed. In order to develop an algorithmic framework for such concurrent control problems, we start with a continuous-time formulation of the Bellman equations, and then discretize them in a way that is aware of system delays. We instantiate this new class of approximate dynamic programming methods via a simple architectural extension to existing value-based deep reinforcement learning algorithms. We evaluate our methods on simulated benchmark tasks and a large-scale robotic grasping task where the robot must "think while moving".
Off-Policy Evaluation via Off-Policy Classification
Jun 20, 2019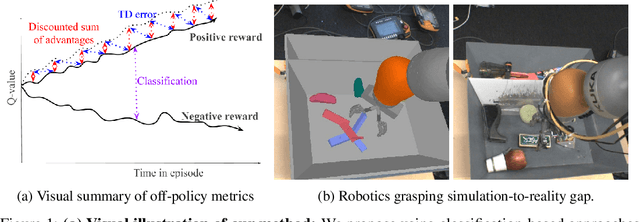

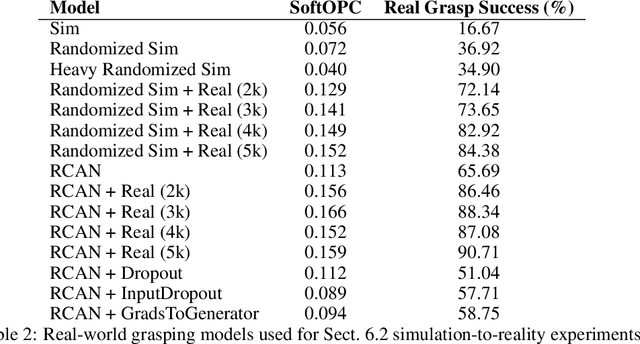

In this work, we consider the problem of model selection for deep reinforcement learning (RL) in real-world environments. Typically, the performance of deep RL algorithms is evaluated via on-policy interactions with the target environment. However, comparing models in a real-world environment for the purposes of early stopping or hyperparameter tuning is costly and often practically infeasible. This leads us to examine off-policy policy evaluation (OPE) in such settings. We focus on OPE for value-based methods, which are of particular interest in deep RL, with applications like robotics, where off-policy algorithms based on Q-function estimation can often attain better sample complexity than direct policy optimization. Existing OPE metrics either rely on a model of the environment, or the use of importance sampling (IS) to correct for the data being off-policy. However, for high-dimensional observations, such as images, models of the environment can be difficult to fit and value-based methods can make IS hard to use or even ill-conditioned, especially when dealing with continuous action spaces. In this paper, we focus on the specific case of MDPs with continuous action spaces and sparse binary rewards, which is representative of many important real-world applications. We propose an alternative metric that relies on neither models nor IS, by framing OPE as a positive-unlabeled (PU) classification problem with the Q-function as the decision function. We experimentally show that this metric outperforms baselines on a number of tasks. Most importantly, it can reliably predict the relative performance of different policies in a number of generalization scenarios, including the transfer to the real-world of policies trained in simulation for an image-based robotic manipulation task.
Sim-to-Real via Sim-to-Sim: Data-efficient Robotic Grasping via Randomized-to-Canonical Adaptation Networks
Mar 25, 2019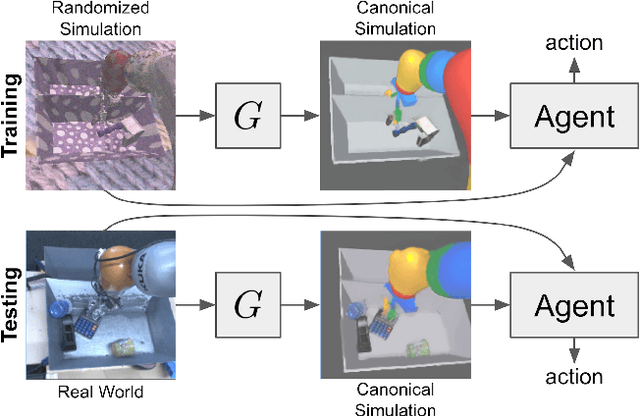
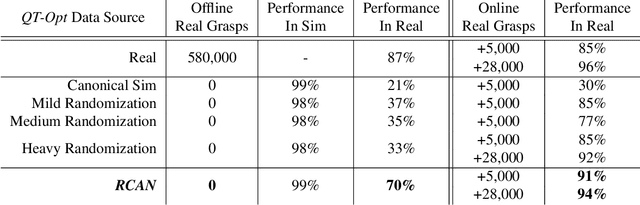


Real world data, especially in the domain of robotics, is notoriously costly to collect. One way to circumvent this can be to leverage the power of simulation to produce large amounts of labelled data. However, training models on simulated images does not readily transfer to real-world ones. Using domain adaptation methods to cross this "reality gap" requires a large amount of unlabelled real-world data, whilst domain randomization alone can waste modeling power. In this paper, we present Randomized-to-Canonical Adaptation Networks (RCANs), a novel approach to crossing the visual reality gap that uses no real-world data. Our method learns to translate randomized rendered images into their equivalent non-randomized, canonical versions. This in turn allows for real images to also be translated into canonical sim images. We demonstrate the effectiveness of this sim-to-real approach by training a vision-based closed-loop grasping reinforcement learning agent in simulation, and then transferring it to the real world to attain 70% zero-shot grasp success on unseen objects, a result that almost doubles the success of learning the same task directly on domain randomization alone. Additionally, by joint finetuning in the real-world with only 5,000 real-world grasps, our method achieves 91%, attaining comparable performance to a state-of-the-art system trained with 580,000 real-world grasps, resulting in a reduction of real-world data by more than 99%.
QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation
Nov 28, 2018


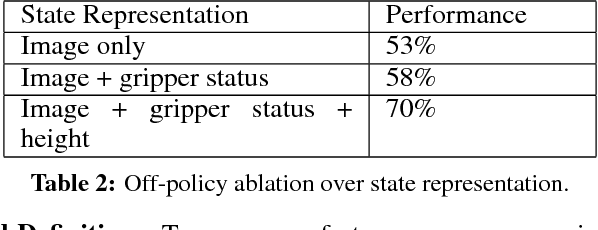
In this paper, we study the problem of learning vision-based dynamic manipulation skills using a scalable reinforcement learning approach. We study this problem in the context of grasping, a longstanding challenge in robotic manipulation. In contrast to static learning behaviors that choose a grasp point and then execute the desired grasp, our method enables closed-loop vision-based control, whereby the robot continuously updates its grasp strategy based on the most recent observations to optimize long-horizon grasp success. To that end, we introduce QT-Opt, a scalable self-supervised vision-based reinforcement learning framework that can leverage over 580k real-world grasp attempts to train a deep neural network Q-function with over 1.2M parameters to perform closed-loop, real-world grasping that generalizes to 96% grasp success on unseen objects. Aside from attaining a very high success rate, our method exhibits behaviors that are quite distinct from more standard grasping systems: using only RGB vision-based perception from an over-the-shoulder camera, our method automatically learns regrasping strategies, probes objects to find the most effective grasps, learns to reposition objects and perform other non-prehensile pre-grasp manipulations, and responds dynamically to disturbances and perturbations.
Diversity is All You Need: Learning Skills without a Reward Function
Oct 09, 2018
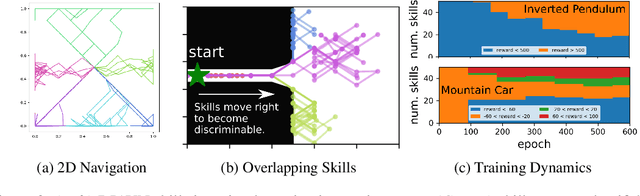
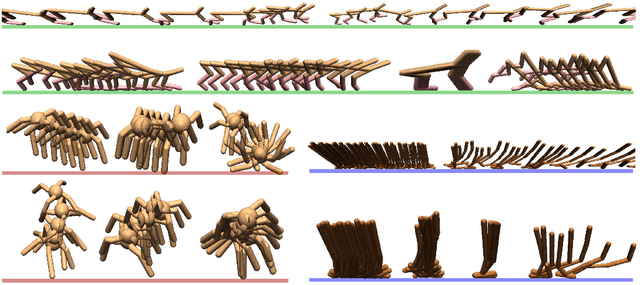
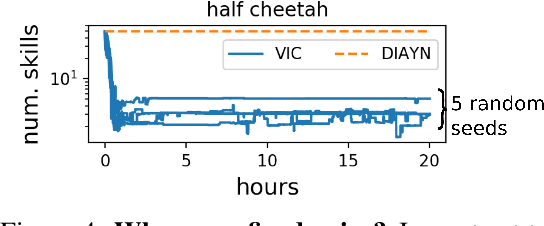
Intelligent creatures can explore their environments and learn useful skills without supervision. In this paper, we propose DIAYN ('Diversity is All You Need'), a method for learning useful skills without a reward function. Our proposed method learns skills by maximizing an information theoretic objective using a maximum entropy policy. On a variety of simulated robotic tasks, we show that this simple objective results in the unsupervised emergence of diverse skills, such as walking and jumping. In a number of reinforcement learning benchmark environments, our method is able to learn a skill that solves the benchmark task despite never receiving the true task reward. We show how pretrained skills can provide a good parameter initialization for downstream tasks, and can be composed hierarchically to solve complex, sparse reward tasks. Our results suggest that unsupervised discovery of skills can serve as an effective pretraining mechanism for overcoming challenges of exploration and data efficiency in reinforcement learning.
Discrete Sequential Prediction of Continuous Actions for Deep RL
Jun 16, 2018
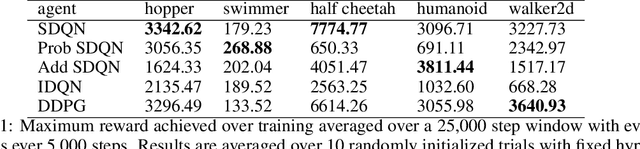
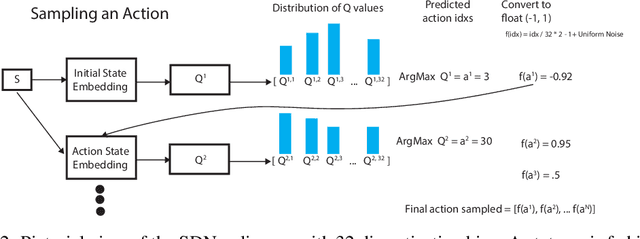
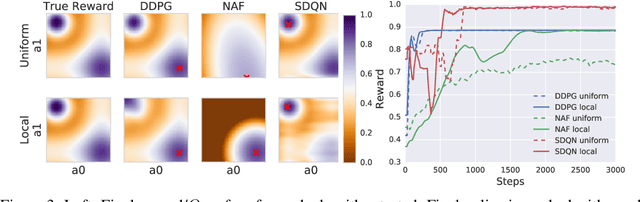
It has long been assumed that high dimensional continuous control problems cannot be solved effectively by discretizing individual dimensions of the action space due to the exponentially large number of bins over which policies would have to be learned. In this paper, we draw inspiration from the recent success of sequence-to-sequence models for structured prediction problems to develop policies over discretized spaces. Central to this method is the realization that complex functions over high dimensional spaces can be modeled by neural networks that predict one dimension at a time. Specifically, we show how Q-values and policies over continuous spaces can be modeled using a next step prediction model over discretized dimensions. With this parameterization, it is possible to both leverage the compositional structure of action spaces during learning, as well as compute maxima over action spaces (approximately). On a simple example task we demonstrate empirically that our method can perform global search, which effectively gets around the local optimization issues that plague DDPG. We apply the technique to off-policy (Q-learning) methods and show that our method can achieve the state-of-the-art for off-policy methods on several continuous control tasks.
Guided Attention for Large Scale Scene Text Verification
Apr 23, 2018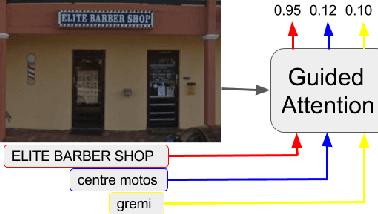
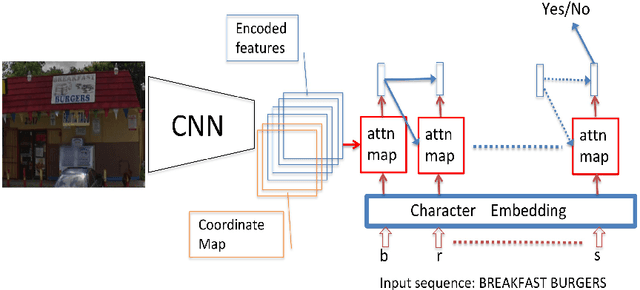
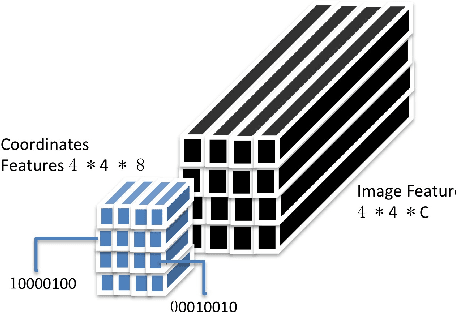

Many tasks are related to determining if a particular text string exists in an image. In this work, we propose a new framework that learns this task in an end-to-end way. The framework takes an image and a text string as input and then outputs the probability of the text string being present in the image. This is the first end-to-end framework that learns such relationships between text and images in scene text area. The framework does not require explicit scene text detection or recognition and thus no bounding box annotations are needed for it. It is also the first work in scene text area that tackles suh a weakly labeled problem. Based on this framework, we developed a model called Guided Attention. Our designed model achieves much better results than several state-of-the-art scene text reading based solutions for a challenging Street View Business Matching task. The task tries to find correct business names for storefront images and the dataset we collected for it is substantially larger, and more challenging than existing scene text dataset. This new real-world task provides a new perspective for studying scene text related problems. We also demonstrate the uniqueness of our task via a comparison between our problem and a typical Visual Question Answering problem.
Deep Reinforcement Learning for Vision-Based Robotic Grasping: A Simulated Comparative Evaluation of Off-Policy Methods
Mar 28, 2018
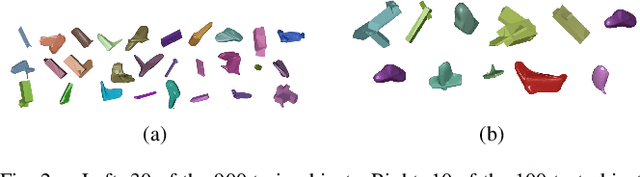
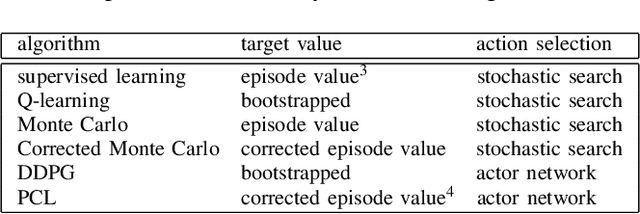
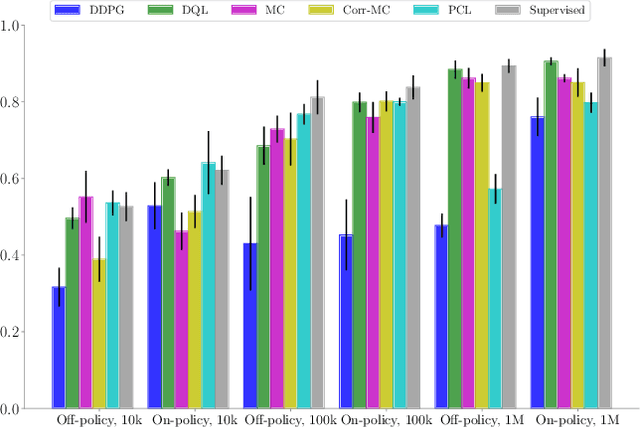
In this paper, we explore deep reinforcement learning algorithms for vision-based robotic grasping. Model-free deep reinforcement learning (RL) has been successfully applied to a range of challenging environments, but the proliferation of algorithms makes it difficult to discern which particular approach would be best suited for a rich, diverse task like grasping. To answer this question, we propose a simulated benchmark for robotic grasping that emphasizes off-policy learning and generalization to unseen objects. Off-policy learning enables utilization of grasping data over a wide variety of objects, and diversity is important to enable the method to generalize to new objects that were not seen during training. We evaluate the benchmark tasks against a variety of Q-function estimation methods, a method previously proposed for robotic grasping with deep neural network models, and a novel approach based on a combination of Monte Carlo return estimation and an off-policy correction. Our results indicate that several simple methods provide a surprisingly strong competitor to popular algorithms such as double Q-learning, and our analysis of stability sheds light on the relative tradeoffs between the algorithms.
Leave no Trace: Learning to Reset for Safe and Autonomous Reinforcement Learning
Nov 18, 2017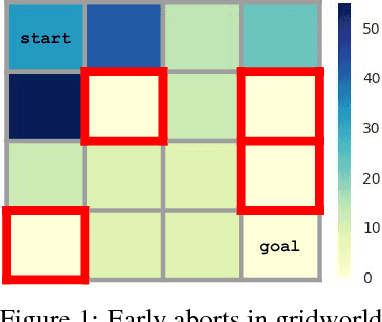
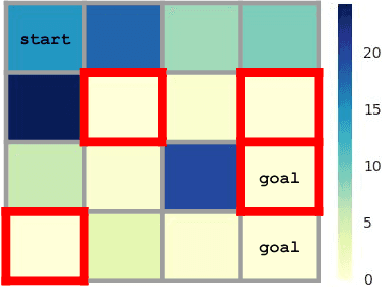
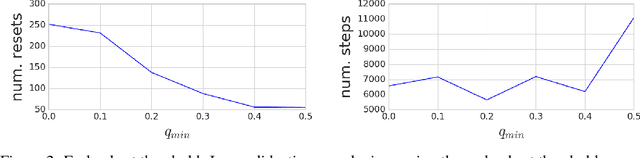
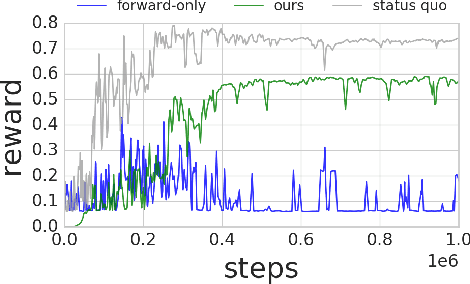
Deep reinforcement learning algorithms can learn complex behavioral skills, but real-world application of these methods requires a large amount of experience to be collected by the agent. In practical settings, such as robotics, this involves repeatedly attempting a task, resetting the environment between each attempt. However, not all tasks are easily or automatically reversible. In practice, this learning process requires extensive human intervention. In this work, we propose an autonomous method for safe and efficient reinforcement learning that simultaneously learns a forward and reset policy, with the reset policy resetting the environment for a subsequent attempt. By learning a value function for the reset policy, we can automatically determine when the forward policy is about to enter a non-reversible state, providing for uncertainty-aware safety aborts. Our experiments illustrate that proper use of the reset policy can greatly reduce the number of manual resets required to learn a task, can reduce the number of unsafe actions that lead to non-reversible states, and can automatically induce a curriculum.
End-to-End Learning of Semantic Grasping
Nov 09, 2017
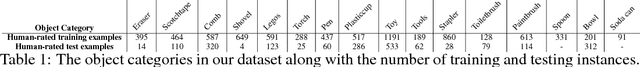
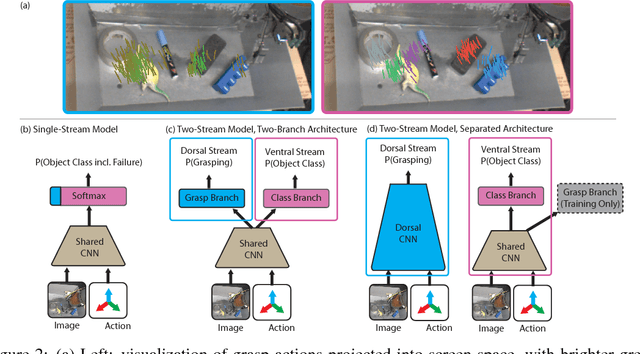
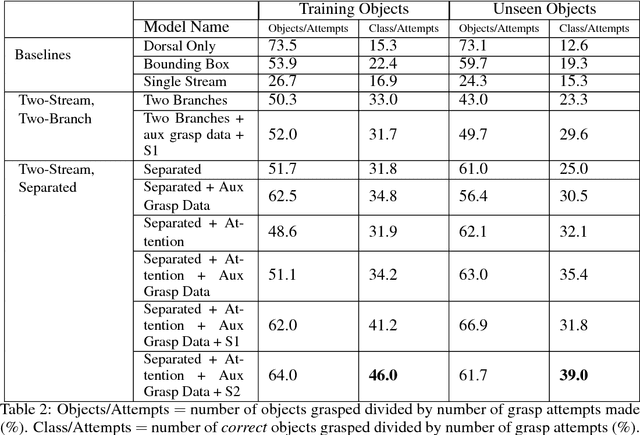
We consider the task of semantic robotic grasping, in which a robot picks up an object of a user-specified class using only monocular images. Inspired by the two-stream hypothesis of visual reasoning, we present a semantic grasping framework that learns object detection, classification, and grasp planning in an end-to-end fashion. A "ventral stream" recognizes object class while a "dorsal stream" simultaneously interprets the geometric relationships necessary to execute successful grasps. We leverage the autonomous data collection capabilities of robots to obtain a large self-supervised dataset for training the dorsal stream, and use semi-supervised label propagation to train the ventral stream with only a modest amount of human supervision. We experimentally show that our approach improves upon grasping systems whose components are not learned end-to-end, including a baseline method that uses bounding box detection. Furthermore, we show that jointly training our model with auxiliary data consisting of non-semantic grasping data, as well as semantically labeled images without grasp actions, has the potential to substantially improve semantic grasping performance.