 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Programming Bots in Intuitive Physics Game Play
Apr 05, 2021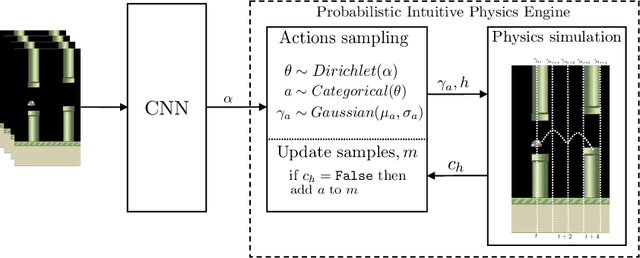
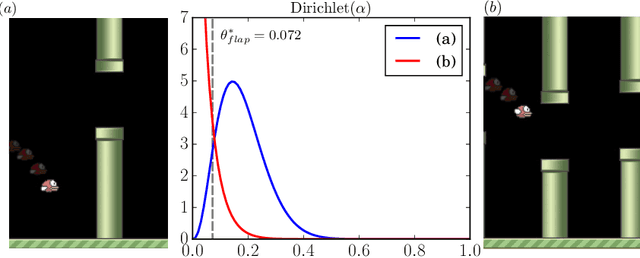
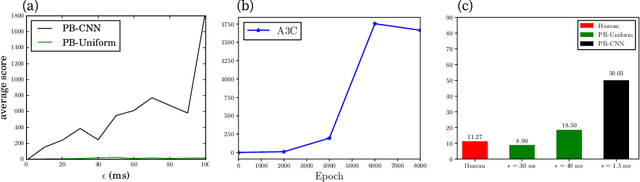
Recent findings suggest that humans deploy cognitive mechanism of physics simulation engines to simulate the physics of objects. We propose a framework for bots to deploy probabilistic programming tools for interacting with intuitive physics environments. The framework employs a physics simulation in a probabilistic way to infer about moves performed by an agent in a setting governed by Newtonian laws of motion. However, methods of probabilistic programs can be slow in such setting due to their need to generate many samples. We complement the model with a model-free approach to aid the sampling procedures in becoming more efficient through learning from experience during game playing. We present an approach where combining model-free approaches (a convolutional neural network in our model) and model-based approaches (probabilistic physics simulation) is able to achieve what neither could alone. This way the model outperforms an all model-free or all model-based approach. We discuss a case study showing empirical results of the performance of the model on the game of Flappy Bird.
Learning Symbolic Operators for Task and Motion Planning
Feb 28, 2021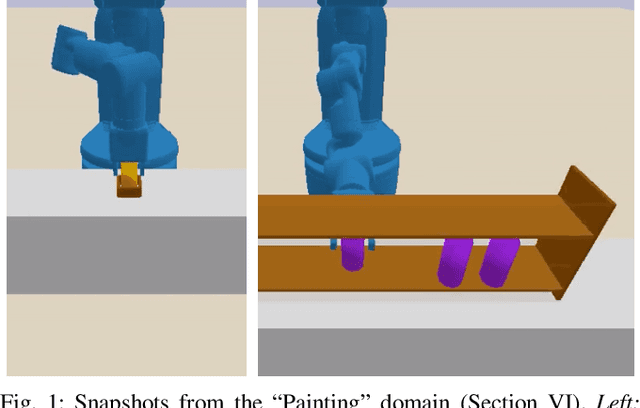



Robotic planning problems in hybrid state and action spaces can be solved by integrated task and motion planners (TAMP) that handle the complex interaction between motion-level decisions and task-level plan feasibility. TAMP approaches rely on domain-specific symbolic operators to guide the task-level search, making planning efficient. In this work, we formalize and study the problem of operator learning for TAMP. Central to this study is the view that operators define a lossy abstraction of the transition model of the underlying domain. We then propose a bottom-up relational learning method for operator learning and show how the learned operators can be used for planning in a TAMP system. Experimentally, we provide results in three domains, including long-horizon robotic planning tasks. We find our approach to substantially outperform several baselines, including three graph neural network-based model-free approaches based on recent work. Video: https://youtu.be/iVfpX9BpBRo
Modular Object-Oriented Games: A Task Framework for Reinforcement Learning, Psychology, and Neuroscience
Feb 25, 2021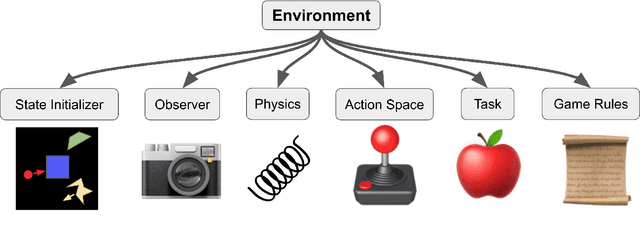
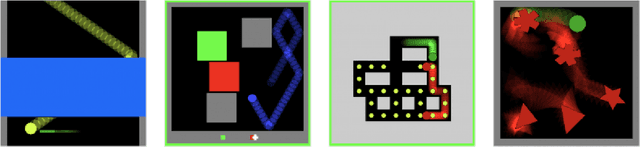
In recent years, trends towards studying simulated games have gained momentum in the fields of artificial intelligence, cognitive science, psychology, and neuroscience. The intersections of these fields have also grown recently, as researchers increasing study such games using both artificial agents and human or animal subjects. However, implementing games can be a time-consuming endeavor and may require a researcher to grapple with complex codebases that are not easily customized. Furthermore, interdisciplinary researchers studying some combination of artificial intelligence, human psychology, and animal neurophysiology face additional challenges, because existing platforms are designed for only one of these domains. Here we introduce Modular Object-Oriented Games, a Python task framework that is lightweight, flexible, customizable, and designed for use by machine learning, psychology, and neurophysiology researchers.
Improved Contrastive Divergence Training of Energy Based Models
Dec 17, 2020

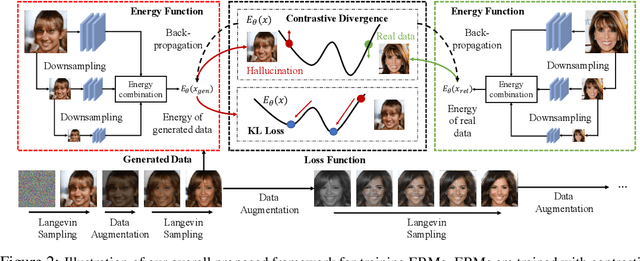

We propose several different techniques to improve contrastive divergence training of energy-based models (EBMs). We first show that a gradient term neglected in the popular contrastive divergence formulation is both tractable to estimate and is important to avoid training instabilities in previous models. We further highlight how data augmentation, multi-scale processing, and reservoir sampling can be used to improve model robustness and generation quality. Thirdly, we empirically evaluate stability of model architectures and show improved performance on a host of benchmarks and use cases, such as image generation, OOD detection, and compositional generation.
Building 3D Morphable Models from a Single Scan
Nov 24, 2020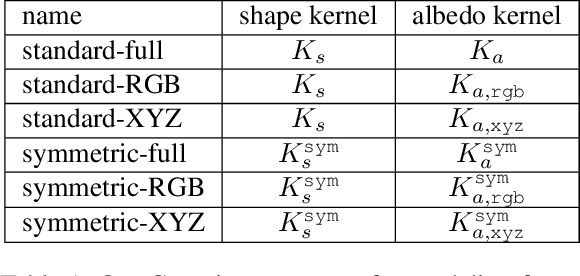

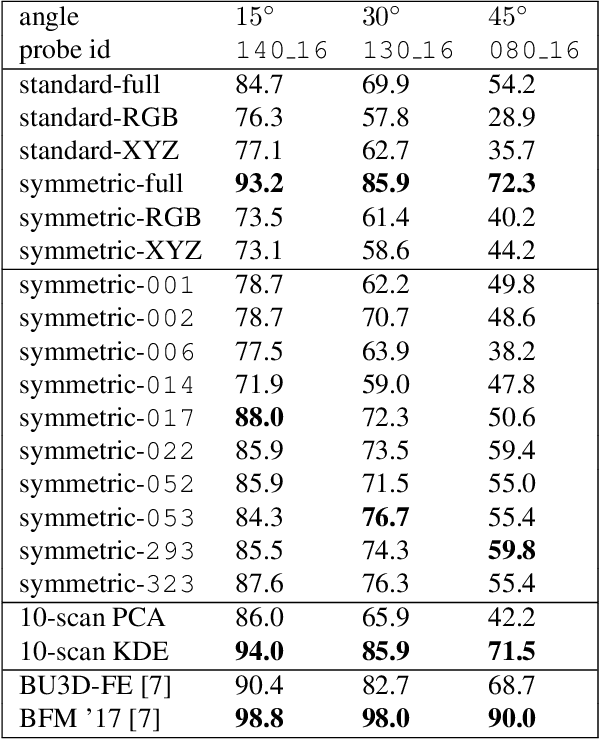
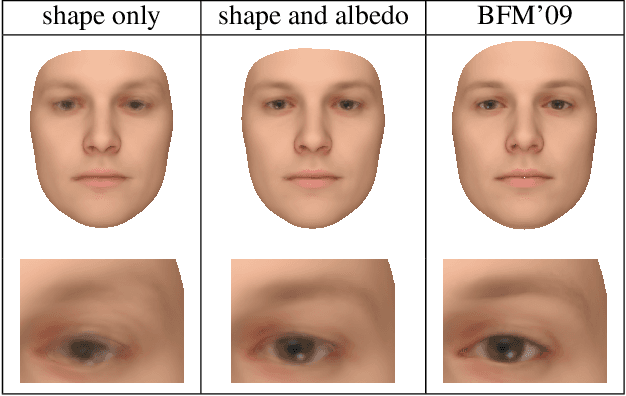
We propose a method for constructing generative models of 3D objects from a single 3D mesh. Our method produces a 3D morphable model that represents shape and albedo in terms of Gaussian processes. We define the shape deformations in physical (3D) space and the albedo deformations as a combination of physical-space and color-space deformations. Whereas previous approaches have typically built 3D morphable models from multiple high-quality 3D scans through principal component analysis, we build 3D morphable models from a single scan or template. We demonstrate the utility of these models in the domain of face modeling through inverse rendering and registration tasks. Specifically, we show that our approach can be used to perform face recognition using only a single 3D scan (one scan total, not one per person), and further demonstrate how multiple scans can be incorporated to improve performance without requiring dense correspondence. Our approach enables the synthesis of 3D morphable models for 3D object categories where dense correspondence between multiple scans is unavailable. We demonstrate this by constructing additional 3D morphable models for fish and birds and use them to perform simple inverse rendering tasks.
A Long Horizon Planning Framework for Manipulating Rigid Pointcloud Objects
Nov 16, 2020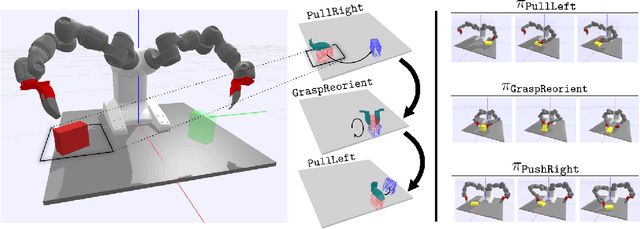

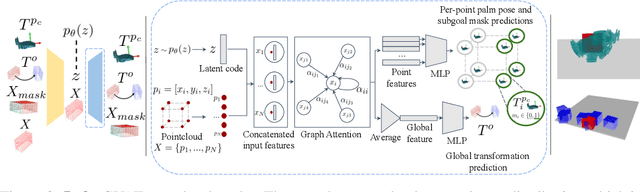
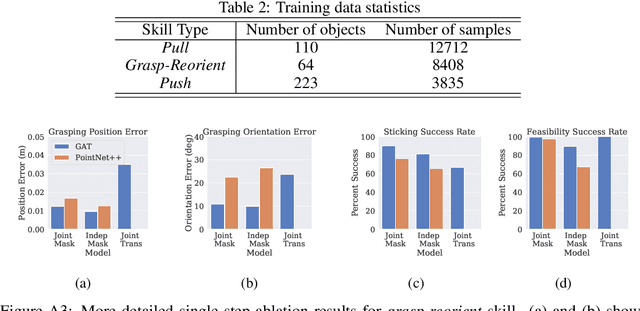
We present a framework for solving long-horizon planning problems involving manipulation of rigid objects that operates directly from a point-cloud observation, i.e. without prior object models. Our method plans in the space of object subgoals and frees the planner from reasoning about robot-object interaction dynamics by relying on a set of generalizable manipulation primitives. We show that for rigid bodies, this abstraction can be realized using low-level manipulation skills that maintain sticking contact with the object and represent subgoals as 3D transformations. To enable generalization to unseen objects and improve planning performance, we propose a novel way of representing subgoals for rigid-body manipulation and a graph-attention based neural network architecture for processing point-cloud inputs. We experimentally validate these choices using simulated and real-world experiments on the YuMi robot. Results demonstrate that our method can successfully manipulate new objects into target configurations requiring long-term planning. Overall, our framework realizes the best of the worlds of task-and-motion planning (TAMP) and learning-based approaches. Project website: https://anthonysimeonov.github.io/rpo-planning-framework/.
Learning Online Data Association
Nov 06, 2020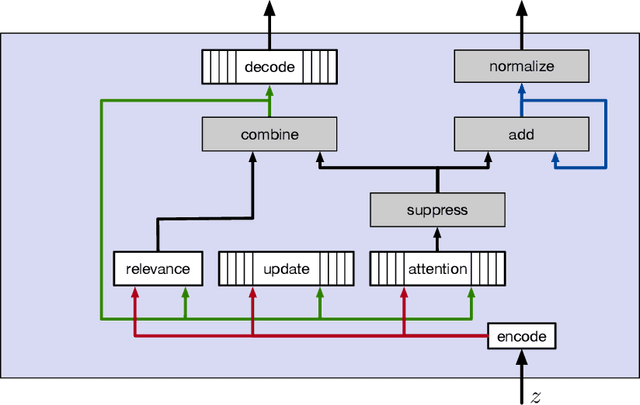
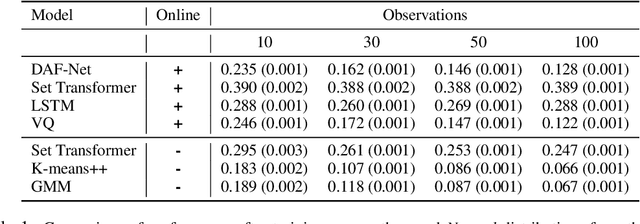
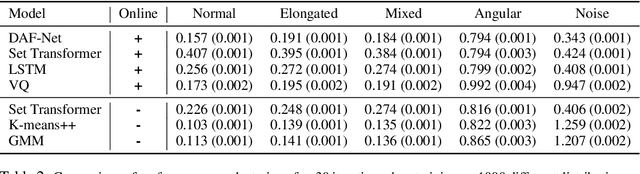

When an agent interacts with a complex environment, it receives a stream of percepts in which it may detect entities, such as objects or people. To build up a coherent, low-variance estimate of the underlying state, it is necessary to fuse information from multiple detections over time. To do this fusion, the agent must decide which detections to associate with one another. We address this data-association problem in the setting of an online filter, in which each observation is processed by aggregating into an existing object hypothesis. Classic methods with strong probabilistic foundations exist, but they are computationally expensive and require models that can be difficult to acquire. In this work, we use the deep-learning tools of sparse attention and representation learning to learn a machine that processes a stream of detections and outputs a set of hypotheses about objects in the world. We evaluate this approach on simple clustering problems, problems with dynamics, and a complex image-based domain. We find that it generalizes well from short to long observation sequences and from a few to many hypotheses, outperforming other learning approaches and classical non-learning methods.
Planning with Learned Object Importance in Large Problem Instances using Graph Neural Networks
Sep 11, 2020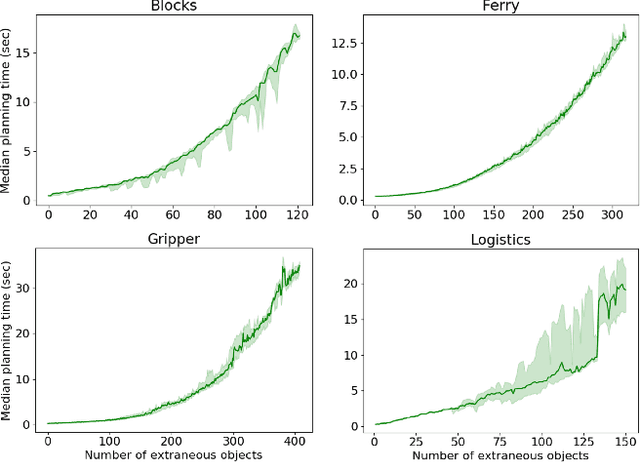
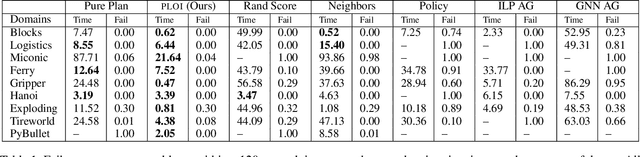
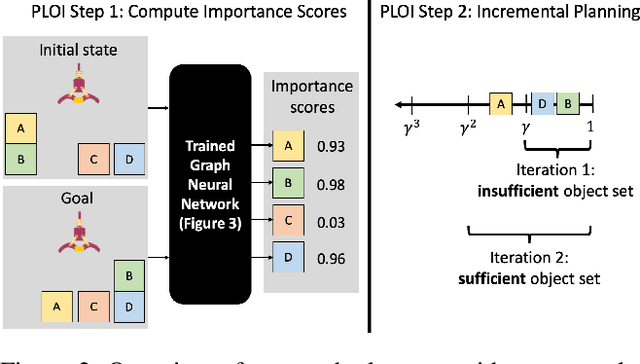

Real-world planning problems often involve hundreds or even thousands of objects, straining the limits of modern planners. In this work, we address this challenge by learning to predict a small set of objects that, taken together, would be sufficient for finding a plan. We propose a graph neural network architecture for predicting object importance in a single pass, thereby incurring little overhead while substantially reducing the number of objects that must be considered by the planner. Our approach treats the planner and transition model as black boxes, and can be used with any off-the-shelf planner. Empirically, across classical planning, probabilistic planning, and robotic task and motion planning, we find that our method results in planning that is significantly faster than several baselines, including other partial grounding strategies and lifted planners. We conclude that learning to predict a sufficient set of objects for a planning problem is a simple, powerful, and general mechanism for planning in large instances. Video: https://youtu.be/FWsVJc2fvCE
Unsupervised Discovery of 3D Physical Objects from Video
Jul 24, 2020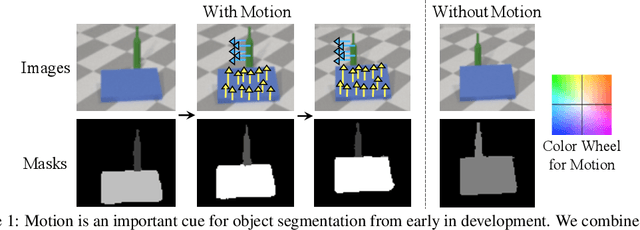
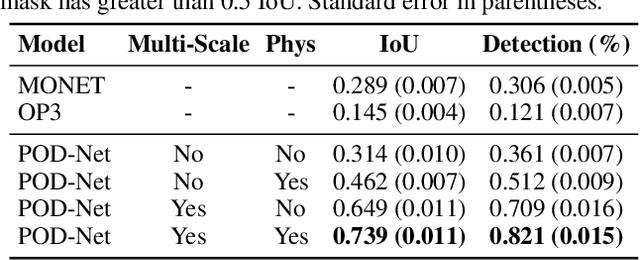
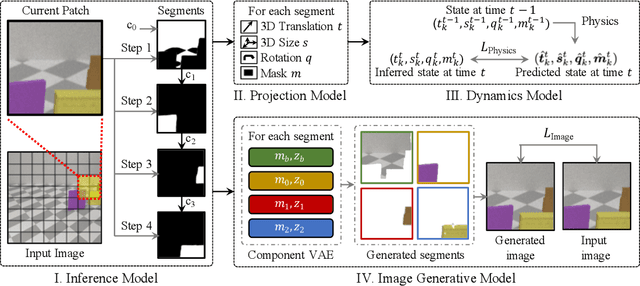
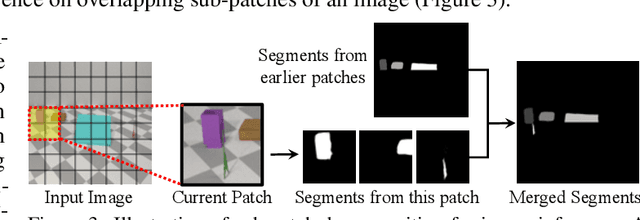
We study the problem of unsupervised physical object discovery. Unlike existing frameworks that aim to learn to decompose scenes into 2D segments purely based on each object's appearance, we explore how physics, especially object interactions, facilitates learning to disentangle and segment instances from raw videos, and to infer the 3D geometry and position of each object, all without supervision. Drawing inspiration from developmental psychology, our Physical Object Discovery Network (POD-Net) uses both multi-scale pixel cues and physical motion cues to accurately segment observable and partially occluded objects of varying sizes, and infer properties of those objects. Our model reliably segments objects on both synthetic and real scenes. The discovered object properties can also be used to reason about physical events.
A Morphable Face Albedo Model
Apr 06, 2020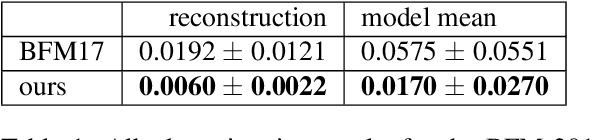



In this paper, we bring together two divergent strands of research: photometric face capture and statistical 3D face appearance modelling. We propose a novel lightstage capture and processing pipeline for acquiring ear-to-ear, truly intrinsic diffuse and specular albedo maps that fully factor out the effects of illumination, camera and geometry. Using this pipeline, we capture a dataset of 50 scans and combine them with the only existing publicly available albedo dataset (3DRFE) of 23 scans. This allows us to build the first morphable face albedo model. We believe this is the first statistical analysis of the variability of facial specular albedo maps. This model can be used as a plug in replacement for the texture model of the Basel Face Model and we make our new albedo model publicly available. We ensure careful spectral calibration such that our model is built in a linear sRGB space, suitable for inverse rendering of images taken by typical cameras. We demonstrate our model in a state of the art analysis-by-synthesis 3DMM fitting pipeline, are the first to integrate specular map estimation and outperform the Basel Face Model in albedo reconstruction.