 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionBooster: A Unified Image Fusion Boosting Paradigm
May 10, 2023



Numerous ideas have emerged for designing fusion rules in the image fusion field. Essentially, all the existing formulations try to manage the diverse levels of information communicated by the source images to achieve the best fusion result. We argue that there is a scope for improving the performance of existing methods further with the help of FusionBooster, a fusion guidance method proposed in this paper. Our booster is based on the divide and conquer strategy controlled by an information probe. The booster is composed of three building blocks: the probe units, the booster layer, and the assembling module. Given the embedding produced by a backbone method, the probe units assess the source images and divide them according to their information content. This is instrumental in identifying missing information, as a step to its recovery. The recovery of the degraded components along with the fusion guidance are embedded in the booster layer. Lastly, the assembling module is responsible for piecing these advanced components together to deliver the output. We use concise reconstruction loss functions and lightweight models to formulate the network, with marginal computational increase. The experimental results obtained in various fusion tasks, as well as downstream detection tasks, consistently demonstrate that the proposed FusionBooster significantly improves the performance. Our codes will be publicly available on the project homepage.
LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images
Apr 16, 2023Deep learning based fusion methods have been achieving promising performance in image fusion tasks. This is attributed to the network architecture that plays a very important role in the fusion process. However, in general, it is hard to specify a good fusion architecture, and consequently, the design of fusion networks is still a black art, rather than science. To address this problem, we formulate the fusion task mathematically, and establish a connection between its optimal solution and the network architecture that can implement it. This approach leads to a novel method proposed in the paper of constructing a lightweight fusion network. It avoids the time-consuming empirical network design by a trial-and-test strategy. In particular we adopt a learnable representation approach to the fusion task, in which the construction of the fusion network architecture is guided by the optimisation algorithm producing the learnable model. The low-rank representation (LRR) objective is the foundation of our learnable model. The matrix multiplications, which are at the heart of the solution are transformed into convolutional operations, and the iterative process of optimisation is replaced by a special feed-forward network. Based on this novel network architecture, an end-to-end lightweight fusion network is constructed to fuse infrared and visible light images. Its successful training is facilitated by a detail-to-semantic information loss function proposed to preserve the image details and to enhance the salient features of the source images. Our experiments show that the proposed fusion network exhibits better fusion performance than the state-of-the-art fusion methods on public datasets. Interestingly, our network requires a fewer training parameters than other existing methods. The codes are available at https://github.com/hli1221/imagefusion-LRRNet
ASiT: Audio Spectrogram vIsion Transformer for General Audio Representation
Nov 23, 2022Vision transformers, which were originally developed for natural language processing, have recently generated significant interest in the computer vision and audio communities due to their flexibility in learning long-range relationships. Constrained by data hungry nature of transformers and limited labelled data most transformer-based models for audio tasks are finetuned from ImageNet pretrained models, despite the huge gap between the natural images domain and audio domain. This has motivated the research in self-supervised pretraining of audio transformers, which reduces the dependency on large amounts of labeled data and focuses on extracting concise representation of the audio spectrograms. In this paper, we propose ASiT, a novel self-supervised transformer for general audio representations that captures local and global contextual information employing group masked model learning and self-distillation. We evaluate our pretrained models on both audio and speech classification tasks including audio event classification, keyword spotting, and speaker identification. We further conduct comprehensive ablation studies, including evaluations of different pretraining strategies. The proposed ASiT framework significantly boosts the performance on all tasks and sets a new state-of-the-art performance on five audio and speech classification tasks, outperforming recent methods, including the approaches that use additional datasets for pretraining. The code and pretrained weights will be made publicly available for the scientific community.
RGBD1K: A Large-scale Dataset and Benchmark for RGB-D Object Tracking
Aug 21, 2022
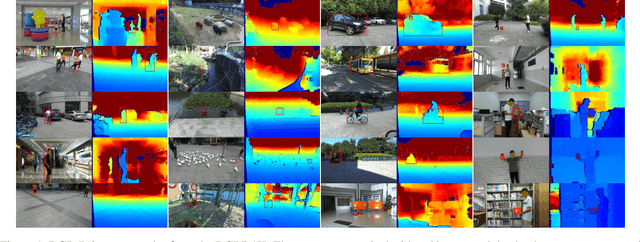
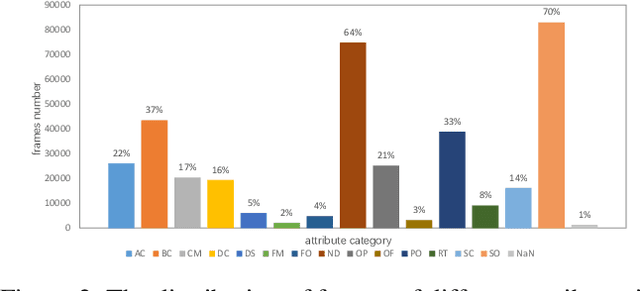

RGB-D object tracking has attracted considerable attention recently, achieving promising performance thanks to the symbiosis between visual and depth channels. However, given a limited amount of annotated RGB-D tracking data, most state-of-the-art RGB-D trackers are simple extensions of high-performance RGB-only trackers, without fully exploiting the underlying potential of the depth channel in the offline training stage. To address the dataset deficiency issue, a new RGB-D dataset named RGBD1K is released in this paper. The RGBD1K contains 1,050 sequences with about 2.5M frames in total. To demonstrate the benefits of training on a larger RGB-D data set in general, and RGBD1K in particular, we develop a transformer-based RGB-D tracker, named SPT, as a baseline for future visual object tracking studies using the new dataset. The results, of extensive experiments using the SPT tracker emonstrate the potential of the RGBD1K dataset to improve the performance of RGB-D tracking, inspiring future developments of effective tracker designs. The dataset and codes will be available on the project homepage: https://will.be.available.at.this.website.
Doubly Reparameterized Importance Weighted Structure Learning for Scene Graph Generation
Jun 22, 2022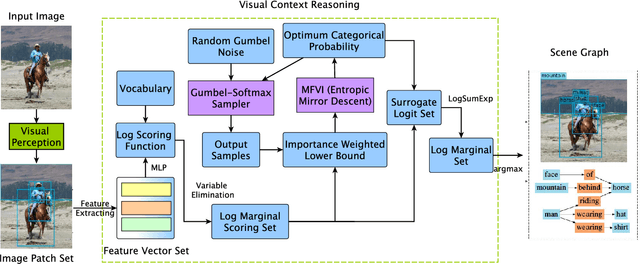
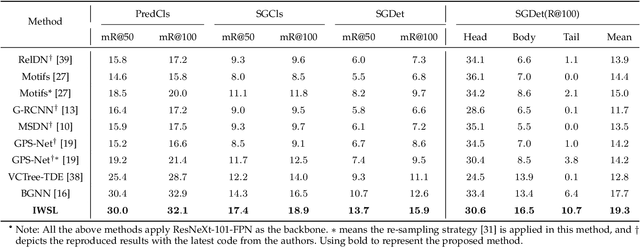
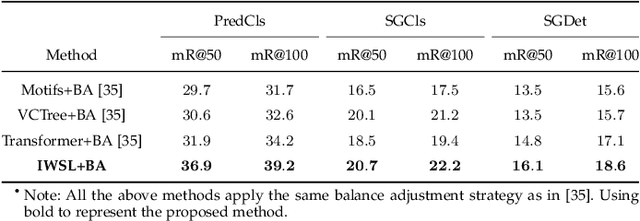
As a structured prediction task, scene graph generation, given an input image, aims to explicitly model objects and their relationships by constructing a visually-grounded scene graph. In the current literature, such task is universally solved via a message passing neural network based mean field variational Bayesian methodology. The classical loose evidence lower bound is generally chosen as the variational inference objective, which could induce oversimplified variational approximation and thus underestimate the underlying complex posterior. In this paper, we propose a novel doubly reparameterized importance weighted structure learning method, which employs a tighter importance weighted lower bound as the variational inference objective. It is computed from multiple samples drawn from a reparameterizable Gumbel-Softmax sampler and the resulting constrained variational inference task is solved by a generic entropic mirror descent algorithm. The resulting doubly reparameterized gradient estimator reduces the variance of the corresponding derivatives with a beneficial impact on learning. The proposed method achieves the state-of-the-art performance on various popular scene graph generation benchmarks.
DreamNet: A Deep Riemannian Network based on SPD Manifold Learning for Visual Classification
Jun 16, 2022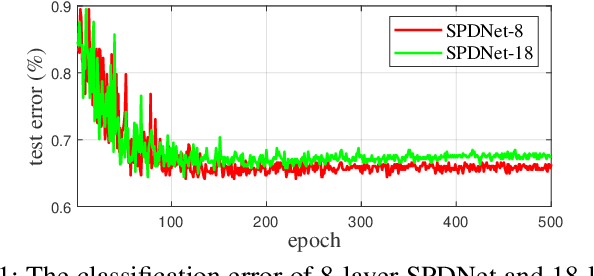
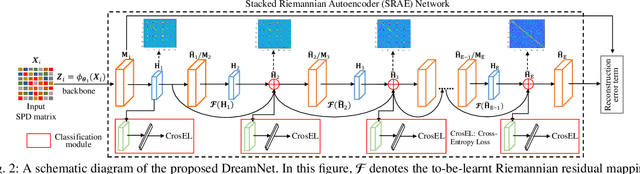
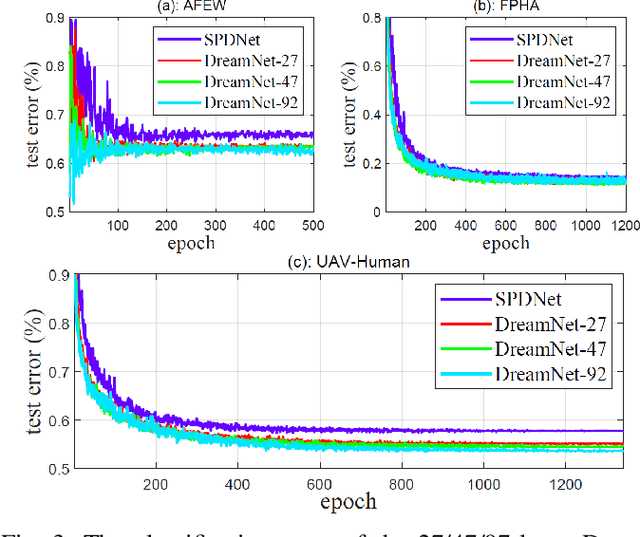
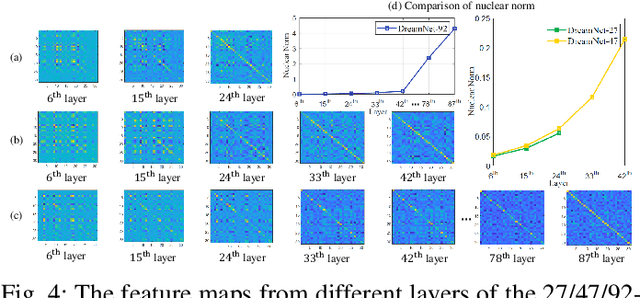
Image set-based visual classification methods have achieved remarkable performance, via characterising the image set in terms of a non-singular covariance matrix on a symmetric positive definite (SPD) manifold. To adapt to complicated visual scenarios better, several Riemannian networks (RiemNets) for SPD matrix nonlinear processing have recently been studied. However, it is pertinent to ask, whether greater accuracy gains can be achieved by simply increasing the depth of RiemNets. The answer appears to be negative, as deeper RiemNets tend to lose generalization ability. To explore a possible solution to this issue, we propose a new architecture for SPD matrix learning. Specifically, to enrich the deep representations, we adopt SPDNet [1] as the backbone, with a stacked Riemannian autoencoder (SRAE) built on the tail. The associated reconstruction error term can make the embedding functions of both SRAE and of each RAE an approximate identity mapping, which helps to prevent the degradation of statistical information. We then insert several residual-like blocks with shortcut connections to augment the representational capacity of SRAE, and to simplify the training of a deeper network. The experimental evidence demonstrates that our DreamNet can achieve improved accuracy with increased depth of the network.
GMML is All you Need
May 30, 2022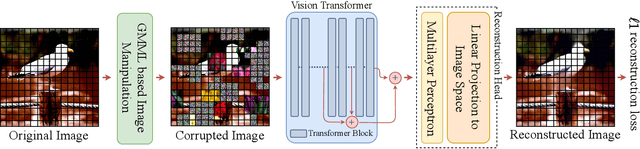
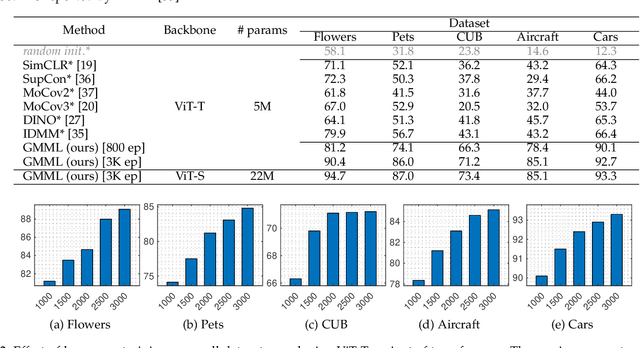
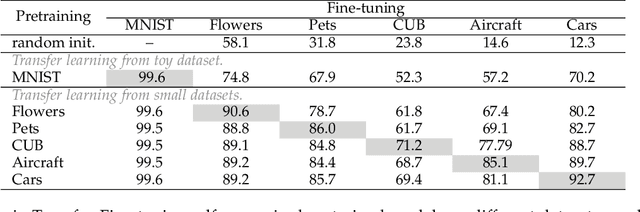
Vision transformers have generated significant interest in the computer vision community because of their flexibility in exploiting contextual information, whether it is sharply confined local, or long range global. However, they are known to be data hungry. This has motivated the research in self-supervised transformer pretraining, which does not need to decode the semantic information conveyed by labels to link it to the image properties, but rather focuses directly on extracting a concise representation of the image data that reflects the notion of similarity, and is invariant to nuisance factors. The key vehicle for the self-learning process used by the majority of self-learning methods is the generation of multiple views of the training data and the creation of pretext tasks which use these views to define the notion of image similarity, and data integrity. However, this approach lacks the natural propensity to extract contextual information. We propose group masked model learning (GMML), a self-supervised learning (SSL) mechanism for pretraining vision transformers with the ability to extract the contextual information present in all the concepts in an image. GMML achieves this by manipulating randomly groups of connected tokens, ensuingly covering a meaningful part of a semantic concept, and then recovering the hidden semantic information from the visible part of the concept. GMML implicitly introduces a novel data augmentation process. Unlike most of the existing SSL approaches, GMML does not require momentum encoder, nor rely on careful implementation details such as large batches and gradient stopping, which are all artefacts of most of the current self-supervised learning techniques. The source code is publicly available for the community to train on bigger corpora: https://github.com/Sara-Ahmed/GMML.
Importance Weighted Structure Learning for Scene Graph Generation
May 14, 2022Scene graph generation is a structured prediction task aiming to explicitly model objects and their relationships via constructing a visually-grounded scene graph for an input image. Currently, the message passing neural network based mean field variational Bayesian methodology is the ubiquitous solution for such a task, in which the variational inference objective is often assumed to be the classical evidence lower bound. However, the variational approximation inferred from such loose objective generally underestimates the underlying posterior, which often leads to inferior generation performance. In this paper, we propose a novel importance weighted structure learning method aiming to approximate the underlying log-partition function with a tighter importance weighted lower bound, which is computed from multiple samples drawn from a reparameterizable Gumbel-Softmax sampler. A generic entropic mirror descent algorithm is applied to solve the resulting constrained variational inference task. The proposed method achieves the state-of-the-art performance on various popular scene graph generation benchmarks.
MSNet: A Deep Multi-scale Submanifold Network for Visual Classification
Jan 29, 2022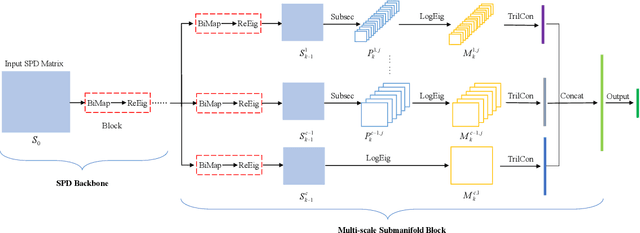
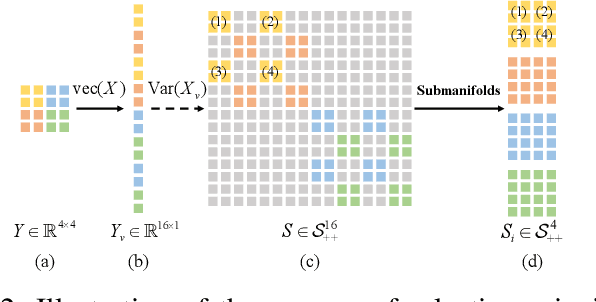


The Symmetric Positive Definite (SPD) matrix has received wide attention as a tool for visual data representation in computer vision. Although there are many different attempts to develop effective deep architectures for data processing on the Riemannian manifold of SPD matrices, a very few solutions explicitly mine the local geometrical information in deep SPD feature representations. While CNNs have demonstrated the potential of hierarchical local pattern extraction even for SPD represented data, we argue that it is of utmost importance to ensure the preservation of local geometric information in the SPD networks. Accordingly, in this work we propose an SPD network designed with this objective in mind. In particular, we propose an architecture, referred to as MSNet, which fuses geometrical multi-scale information. We first analyse the convolution operator commonly used for mapping the local information in Euclidean deep networks from the perspective of a higher level of abstraction afforded by the Category Theory. Based on this analysis, we postulate a submanifold selection principle to guide the design of our MSNet. In particular, we use it to design a submanifold fusion block to take advantage of the rich local geometry encoded in the network layers. The experiments involving multiple visual tasks show that our algorithm outperforms most Riemannian SOTA competitors.
Constrained Structure Learning for Scene Graph Generation
Jan 27, 2022



As a structured prediction task, scene graph generation aims to build a visually-grounded scene graph to explicitly model objects and their relationships in an input image. Currently, the mean field variational Bayesian framework is the de facto methodology used by the existing methods, in which the unconstrained inference step is often implemented by a message passing neural network. However, such formulation fails to explore other inference strategies, and largely ignores the more general constrained optimization models. In this paper, we present a constrained structure learning method, for which an explicit constrained variational inference objective is proposed. Instead of applying the ubiquitous message-passing strategy, a generic constrained optimization method - entropic mirror descent - is utilized to solve the constrained variational inference step. We validate the proposed generic model on various popular scene graph generation benchmarks and show that it outperforms the state-of-the-art methods.