 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation
Apr 19, 2022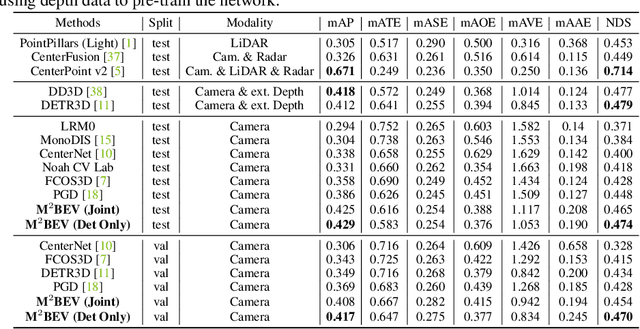
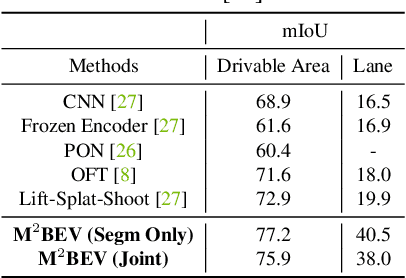
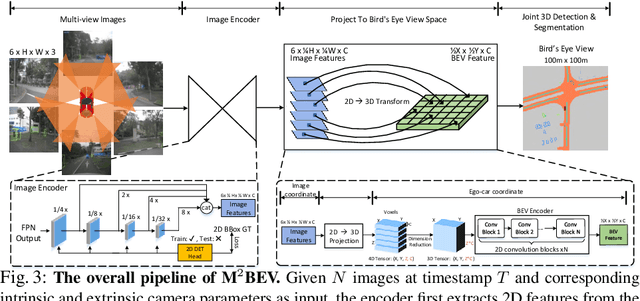
In this paper, we propose M$^2$BEV, a unified framework that jointly performs 3D object detection and map segmentation in the Birds Eye View~(BEV) space with multi-camera image inputs. Unlike the majority of previous works which separately process detection and segmentation, M$^2$BEV infers both tasks with a unified model and improves efficiency. M$^2$BEV efficiently transforms multi-view 2D image features into the 3D BEV feature in ego-car coordinates. Such BEV representation is important as it enables different tasks to share a single encoder. Our framework further contains four important designs that benefit both accuracy and efficiency: (1) An efficient BEV encoder design that reduces the spatial dimension of a voxel feature map. (2) A dynamic box assignment strategy that uses learning-to-match to assign ground-truth 3D boxes with anchors. (3) A BEV centerness re-weighting that reinforces with larger weights for more distant predictions, and (4) Large-scale 2D detection pre-training and auxiliary supervision. We show that these designs significantly benefit the ill-posed camera-based 3D perception tasks where depth information is missing. M$^2$BEV is memory efficient, allowing significantly higher resolution images as input, with faster inference speed. Experiments on nuScenes show that M$^2$BEV achieves state-of-the-art results in both 3D object detection and BEV segmentation, with the best single model achieving 42.5 mAP and 57.0 mIoU in these two tasks, respectively.
FreeSOLO: Learning to Segment Objects without Annotations
Feb 24, 2022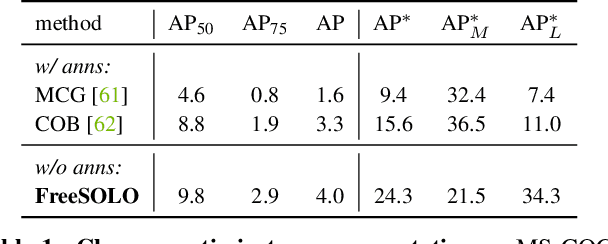

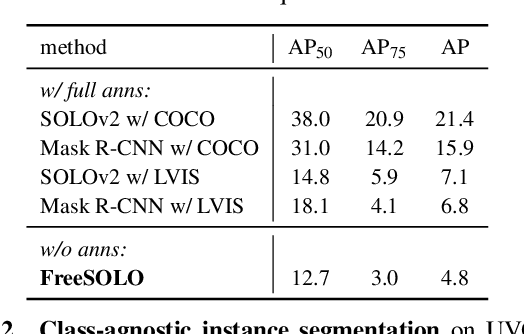
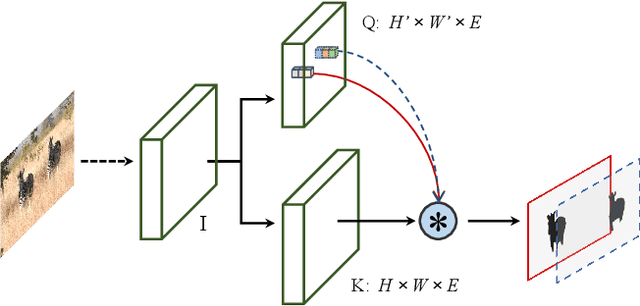
Instance segmentation is a fundamental vision task that aims to recognize and segment each object in an image. However, it requires costly annotations such as bounding boxes and segmentation masks for learning. In this work, we propose a fully unsupervised learning method that learns class-agnostic instance segmentation without any annotations. We present FreeSOLO, a self-supervised instance segmentation framework built on top of the simple instance segmentation method SOLO. Our method also presents a novel localization-aware pre-training framework, where objects can be discovered from complicated scenes in an unsupervised manner. FreeSOLO achieves 9.8% AP_{50} on the challenging COCO dataset, which even outperforms several segmentation proposal methods that use manual annotations. For the first time, we demonstrate unsupervised class-agnostic instance segmentation successfully. FreeSOLO's box localization significantly outperforms state-of-the-art unsupervised object detection/discovery methods, with about 100% relative improvements in COCO AP. FreeSOLO further demonstrates superiority as a strong pre-training method, outperforming state-of-the-art self-supervised pre-training methods by +9.8% AP when fine-tuning instance segmentation with only 5% COCO masks.
Fairness implications of encoding protected categorical attributes
Jan 27, 2022

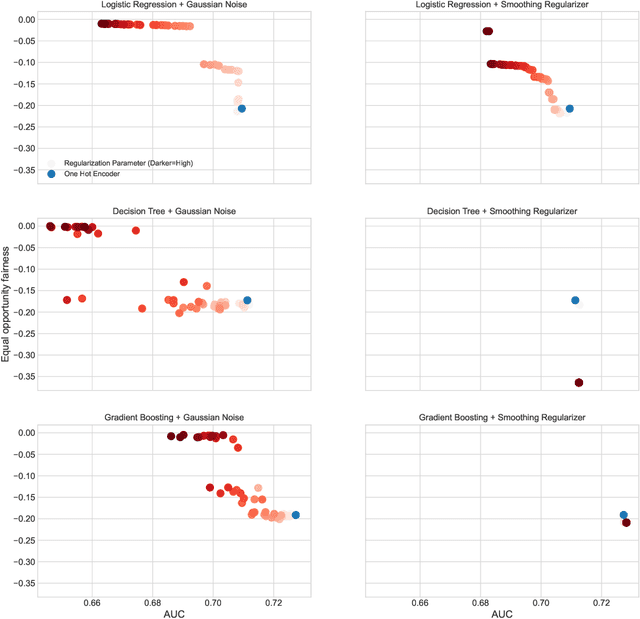
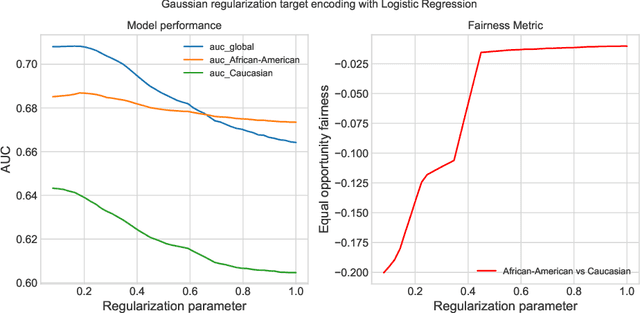
Protected attributes are often presented as categorical features that need to be encoded before feeding them into a machine learning algorithm. Encoding these attributes is paramount as they determine the way the algorithm will learn from the data. Categorical feature encoding has a direct impact on the model performance and fairness. In this work, we compare the accuracy and fairness implications of the two most well-known encoders: one-hot encoding and target encoding. We distinguish between two types of induced bias that can arise while using these encodings and can lead to unfair models. The first type, irreducible bias, is due to direct group category discrimination and a second type, reducible bias, is due to large variance in less statistically represented groups. We take a deeper look into how regularization methods for target encoding can improve the induced bias while encoding categorical features. Furthermore, we tackle the problem of intersectional fairness that arises when mixing two protected categorical features leading to higher cardinality. This practice is a powerful feature engineering technique used for boosting model performance. We study its implications on fairness as it can increase both types of induced bias
Boosting Supervised Learning Performance with Co-training
Nov 18, 2021
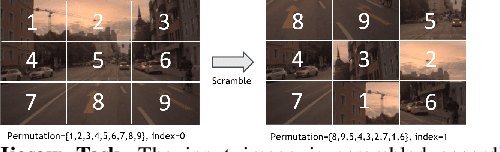


Deep learning perception models require a massive amount of labeled training data to achieve good performance. While unlabeled data is easy to acquire, the cost of labeling is prohibitive and could create a tremendous burden on companies or individuals. Recently, self-supervision has emerged as an alternative to leveraging unlabeled data. In this paper, we propose a new light-weight self-supervised learning framework that could boost supervised learning performance with minimum additional computation cost. Here, we introduce a simple and flexible multi-task co-training framework that integrates a self-supervised task into any supervised task. Our approach exploits pretext tasks to incur minimum compute and parameter overheads and minimal disruption to existing training pipelines. We demonstrate the effectiveness of our framework by using two self-supervised tasks, object detection and panoptic segmentation, on different perception models. Our results show that both self-supervised tasks can improve the accuracy of the supervised task and, at the same time, demonstrates strong domain adaption capability when used with additional unlabeled data.
When to Prune? A Policy towards Early Structural Pruning
Oct 22, 2021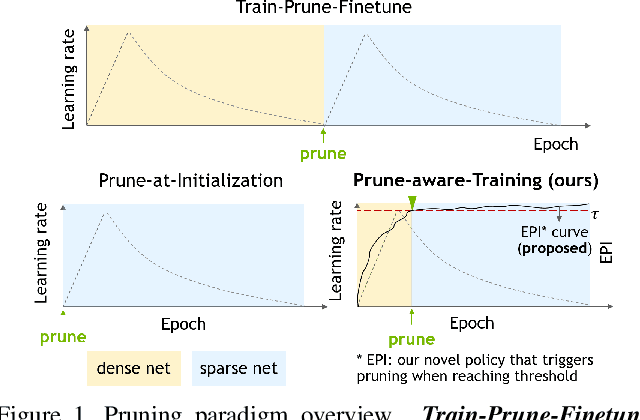
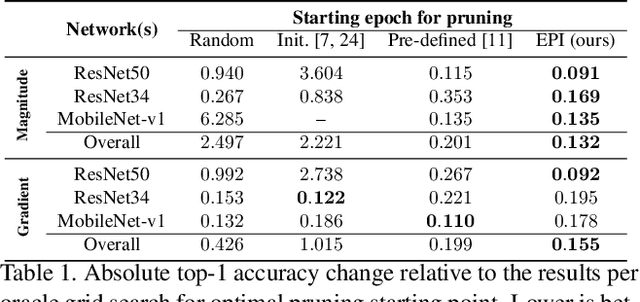
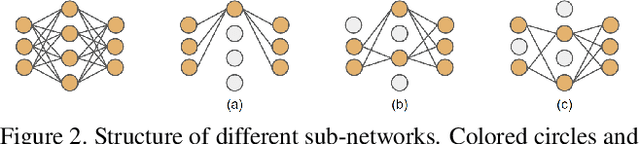
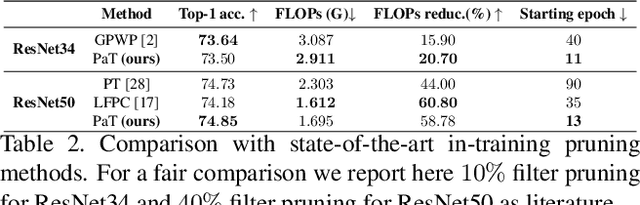
Pruning enables appealing reductions in network memory footprint and time complexity. Conventional post-training pruning techniques lean towards efficient inference while overlooking the heavy computation for training. Recent exploration of pre-training pruning at initialization hints on training cost reduction via pruning, but suffers noticeable performance degradation. We attempt to combine the benefits of both directions and propose a policy that prunes as early as possible during training without hurting performance. Instead of pruning at initialization, our method exploits initial dense training for few epochs to quickly guide the architecture, while constantly evaluating dominant sub-networks via neuron importance ranking. This unveils dominant sub-networks whose structures turn stable, allowing conventional pruning to be pushed earlier into the training. To do this early, we further introduce an Early Pruning Indicator (EPI) that relies on sub-network architectural similarity and quickly triggers pruning when the sub-network's architecture stabilizes. Through extensive experiments on ImageNet, we show that EPI empowers a quick tracking of early training epochs suitable for pruning, offering same efficacy as an otherwise ``oracle'' grid-search that scans through epochs and requires orders of magnitude more compute. Our method yields $1.4\%$ top-1 accuracy boost over state-of-the-art pruning counterparts, cuts down training cost on GPU by $2.4\times$, hence offers a new efficiency-accuracy boundary for network pruning during training.
HALP: Hardware-Aware Latency Pruning
Oct 20, 2021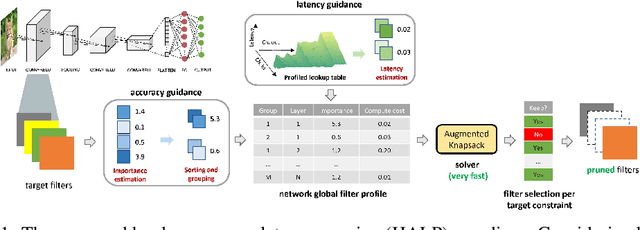
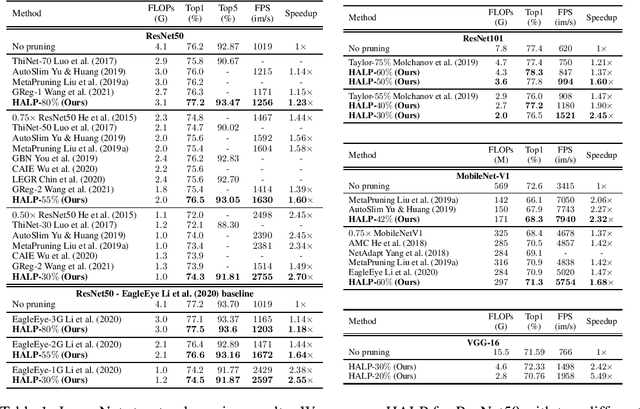
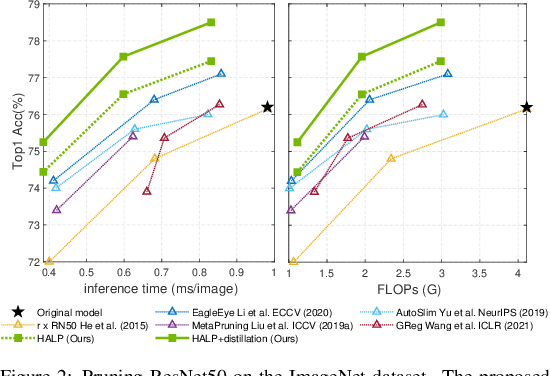
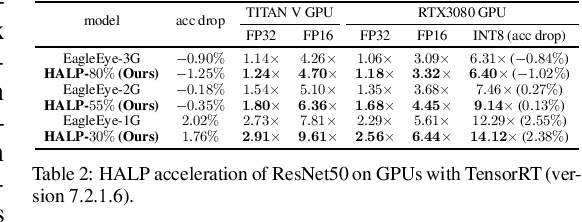
Structural pruning can simplify network architecture and improve inference speed. We propose Hardware-Aware Latency Pruning (HALP) that formulates structural pruning as a global resource allocation optimization problem, aiming at maximizing the accuracy while constraining latency under a predefined budget. For filter importance ranking, HALP leverages latency lookup table to track latency reduction potential and global saliency score to gauge accuracy drop. Both metrics can be evaluated very efficiently during pruning, allowing us to reformulate global structural pruning under a reward maximization problem given target constraint. This makes the problem solvable via our augmented knapsack solver, enabling HALP to surpass prior work in pruning efficacy and accuracy-efficiency trade-off. We examine HALP on both classification and detection tasks, over varying networks, on ImageNet and VOC datasets. In particular, for ResNet-50/-101 pruning on ImageNet, HALP improves network throughput by $1.60\times$/$1.90\times$ with $+0.3\%$/$-0.2\%$ top-1 accuracy changes, respectively. For SSD pruning on VOC, HALP improves throughput by $1.94\times$ with only a $0.56$ mAP drop. HALP consistently outperforms prior art, sometimes by large margins.
Panoptic SegFormer
Sep 11, 2021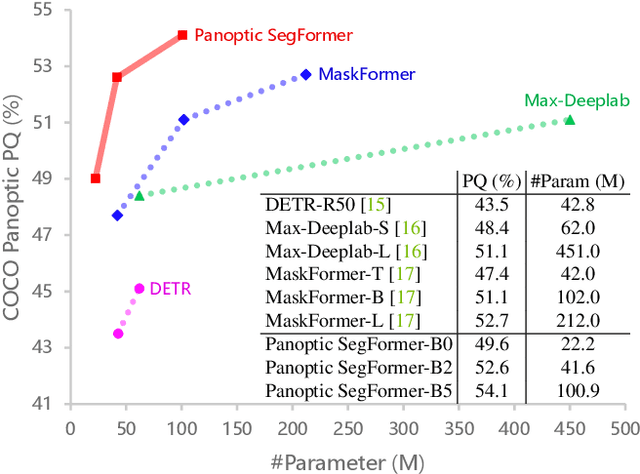
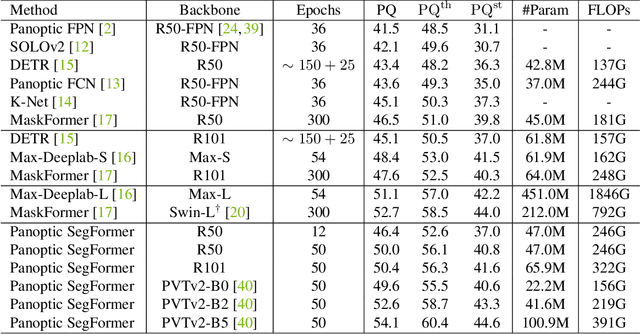
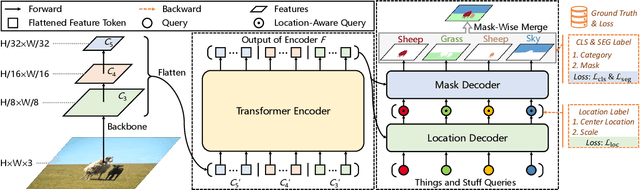
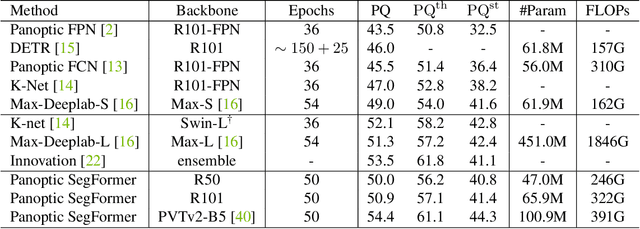
We present Panoptic SegFormer, a general framework for end-to-end panoptic segmentation with Transformers. The proposed method extends Deformable DETR with a unified mask prediction workflow for both things and stuff, making the panoptic segmentation pipeline concise and effective. With a ResNet-50 backbone, our method achieves 50.0\% PQ on the COCO test-dev split, surpassing previous state-of-the-art methods by significant margins without bells and whistles. Using a more powerful PVTv2-B5 backbone, Panoptic-SegFormer achieves a new record of 54.1\%PQ and 54.4\% PQ on the COCO val and test-dev splits with single scale input.
Deep Neural Networks are Surprisingly Reversible: A Baseline for Zero-Shot Inversion
Jul 13, 2021



Understanding the behavior and vulnerability of pre-trained deep neural networks (DNNs) can help to improve them. Analysis can be performed via reversing the network's flow to generate inputs from internal representations. Most existing work relies on priors or data-intensive optimization to invert a model, yet struggles to scale to deep architectures and complex datasets. This paper presents a zero-shot direct model inversion framework that recovers the input to the trained model given only the internal representation. The crux of our method is to inverse the DNN in a divide-and-conquer manner while re-syncing the inverted layers via cycle-consistency guidance with the help of synthesized data. As a result, we obtain a single feed-forward model capable of inversion with a single forward pass without seeing any real data of the original task. With the proposed approach, we scale zero-shot direct inversion to deep architectures and complex datasets. We empirically show that modern classification models on ImageNet can, surprisingly, be inverted, allowing an approximate recovery of the original 224x224px images from a representation after more than 20 layers. Moreover, inversion of generators in GANs unveils latent code of a given synthesized face image at 128x128px, which can even, in turn, improve defective synthesized images from GANs.
Towards Reducing Labeling Cost in Deep Object Detection
Jun 22, 2021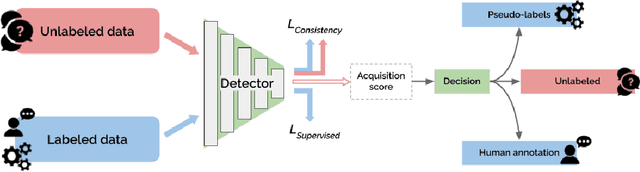

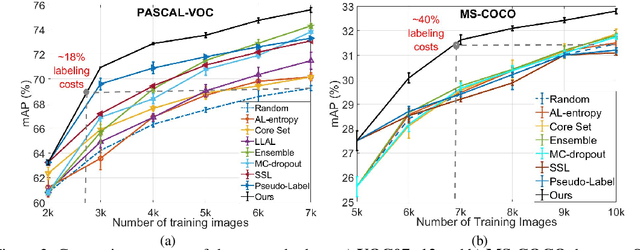

Deep neural networks have reached very high accuracy on object detection but their success hinges on large amounts of labeled data. To reduce the dependency on labels, various active-learning strategies have been proposed, typically based on the confidence of the detector. However, these methods are biased towards best-performing classes and can lead to acquired datasets that are not good representatives of the data in the testing set. In this work, we propose a unified framework for active learning, that considers both the uncertainty and the robustness of the detector, ensuring that the network performs accurately in all classes. Furthermore, our method is able to pseudo-label the very confident predictions, suppressing a potential distribution drift while further boosting the performance of the model. Experiments show that our method comprehensively outperforms a wide range of active-learning methods on PASCAL VOC07+12 and MS-COCO, having up to a 7.7% relative improvement, or up to 82% reduction in labeling cost.
Distilling Image Classifiers in Object Detectors
Jun 09, 2021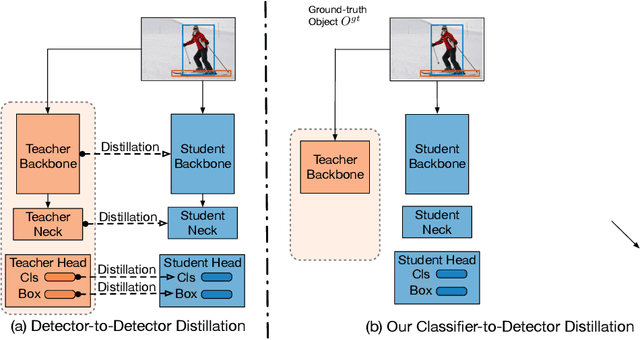
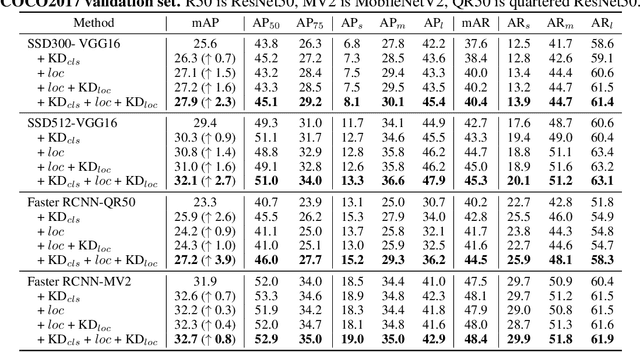
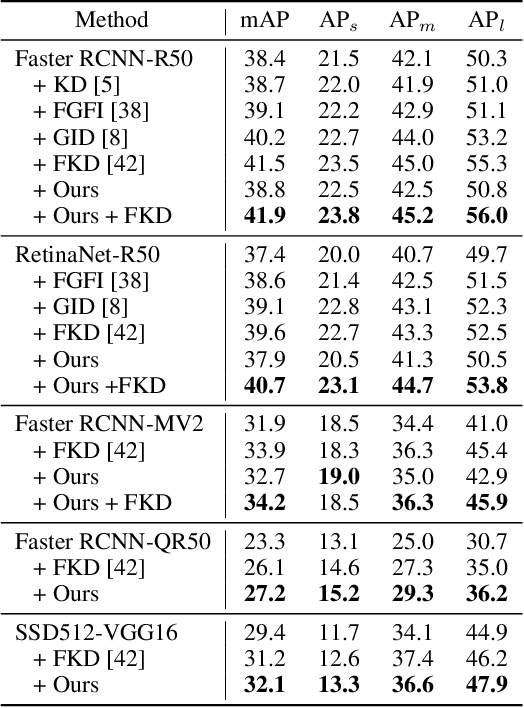

Knowledge distillation constitutes a simple yet effective way to improve the performance of a compact student network by exploiting the knowledge of a more powerful teacher. Nevertheless, the knowledge distillation literature remains limited to the scenario where the student and the teacher tackle the same task. Here, we investigate the problem of transferring knowledge not only across architectures but also across tasks. To this end, we study the case of object detection and, instead of following the standard detector-to-detector distillation approach, introduce a classifier-to-detector knowledge transfer framework. In particular, we propose strategies to exploit the classification teacher to improve both the detector's recognition accuracy and localization performance. Our experiments on several detectors with different backbones demonstrate the effectiveness of our approach, allowing us to outperform the state-of-the-art detector-to-detector distillation methods.