 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Regularity with Robot Intrinsic Symmetry in Reinforcement Learning
Jun 28, 2023



Geometric regularity, which leverages data symmetry, has been successfully incorporated into deep learning architectures such as CNNs, RNNs, GNNs, and Transformers. While this concept has been widely applied in robotics to address the curse of dimensionality when learning from high-dimensional data, the inherent reflectional and rotational symmetry of robot structures has not been adequately explored. Drawing inspiration from cooperative multi-agent reinforcement learning, we introduce novel network structures for deep learning algorithms that explicitly capture this geometric regularity. Moreover, we investigate the relationship between the geometric prior and the concept of Parameter Sharing in multi-agent reinforcement learning. Through experiments conducted on various challenging continuous control tasks, we demonstrate the significant potential of the proposed geometric regularity in enhancing robot learning capabilities.
The Treachery of Images: Bayesian Scene Keypoints for Deep Policy Learning in Robotic Manipulation
May 08, 2023In policy learning for robotic manipulation, sample efficiency is of paramount importance. Thus, learning and extracting more compact representations from camera observations is a promising avenue. However, current methods often assume full observability of the scene and struggle with scale invariance. In many tasks and settings, this assumption does not hold as objects in the scene are often occluded or lie outside the field of view of the camera, rendering the camera observation ambiguous with regard to their location. To tackle this problem, we present BASK, a Bayesian approach to tracking scale-invariant keypoints over time. Our approach successfully resolves inherent ambiguities in images, enabling keypoint tracking on symmetrical objects and occluded and out-of-view objects. We employ our method to learn challenging multi-object robot manipulation tasks from wrist camera observations and demonstrate superior utility for policy learning compared to other representation learning techniques. Furthermore, we show outstanding robustness towards disturbances such as clutter, occlusions, and noisy depth measurements, as well as generalization to unseen objects both in simulation and real-world robotic experiments.
Survey on LiDAR Perception in Adverse Weather Conditions
Apr 13, 2023

Autonomous vehicles rely on a variety of sensors to gather information about their surrounding. The vehicle's behavior is planned based on the environment perception, making its reliability crucial for safety reasons. The active LiDAR sensor is able to create an accurate 3D representation of a scene, making it a valuable addition for environment perception for autonomous vehicles. Due to light scattering and occlusion, the LiDAR's performance change under adverse weather conditions like fog, snow or rain. This limitation recently fostered a large body of research on approaches to alleviate the decrease in perception performance. In this survey, we gathered, analyzed, and discussed different aspects on dealing with adverse weather conditions in LiDAR-based environment perception. We address topics such as the availability of appropriate data, raw point cloud processing and denoising, robust perception algorithms and sensor fusion to mitigate adverse weather induced shortcomings. We furthermore identify the most pressing gaps in the current literature and pinpoint promising research directions.
Imitation Learning from Nonlinear MPC via the Exact Q-Loss and its Gauss-Newton Approximation
Apr 03, 2023This work presents a novel loss function for learning nonlinear Model Predictive Control policies via Imitation Learning. Standard approaches to Imitation Learning neglect information about the expert and generally adopt a loss function based on the distance between expert and learned controls. In this work, we present a loss based on the Q-function directly embedding the performance objectives and constraint satisfaction of the associated Optimal Control Problem (OCP). However, training a Neural Network with the Q-loss requires solving the associated OCP for each new sample. To alleviate the computational burden, we derive a second Q-loss based on the Gauss-Newton approximation of the OCP resulting in a faster training time. We validate our losses against Behavioral Cloning, the standard approach to Imitation Learning, on the control of a nonlinear system with constraints. The final results show that the Q-function-based losses significantly reduce the amount of constraint violations while achieving comparable or better closed-loop costs.
Robust Tumor Detection from Coarse Annotations via Multi-Magnification Ensembles
Mar 29, 2023Cancer detection and classification from gigapixel whole slide images of stained tissue specimens has recently experienced enormous progress in computational histopathology. The limitation of available pixel-wise annotated scans shifted the focus from tumor localization to global slide-level classification on the basis of (weakly-supervised) multiple-instance learning despite the clinical importance of local cancer detection. However, the worse performance of these techniques in comparison to fully supervised methods has limited their usage until now for diagnostic interventions in domains of life-threatening diseases such as cancer. In this work, we put the focus back on tumor localization in form of a patch-level classification task and take up the setting of so-called coarse annotations, which provide greater training supervision while remaining feasible from a clinical standpoint. To this end, we present a novel ensemble method that not only significantly improves the detection accuracy of metastasis on the open CAMELYON16 data set of sentinel lymph nodes of breast cancer patients, but also considerably increases its robustness against noise while training on coarse annotations. Our experiments show that better results can be achieved with our technique making it clinically feasible to use for cancer diagnosis and opening a new avenue for translational and clinical research.
Incorporating Recurrent Reinforcement Learning into Model Predictive Control for Adaptive Control in Autonomous Driving
Jan 30, 2023
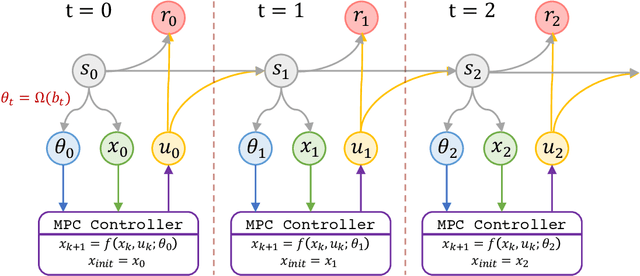
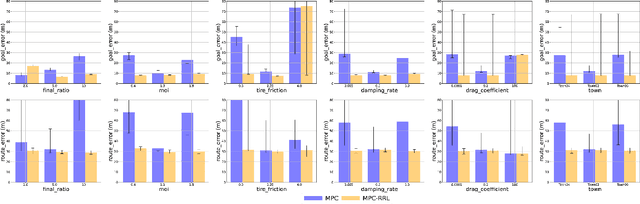

Model Predictive Control (MPC) is attracting tremendous attention in the autonomous driving task as a powerful control technique. The success of an MPC controller strongly depends on an accurate internal dynamics model. However, the static parameters, usually learned by system identification, often fail to adapt to both internal and external perturbations in real-world scenarios. In this paper, we firstly (1) reformulate the problem as a Partially Observed Markov Decision Process (POMDP) that absorbs the uncertainties into observations and maintains Markov property into hidden states; and (2) learn a recurrent policy continually adapting the parameters of the dynamics model via Recurrent Reinforcement Learning (RRL) for optimal and adaptive control; and (3) finally evaluate the proposed algorithm (referred as $\textit{MPC-RRL}$) in CARLA simulator and leading to robust behaviours under a wide range of perturbations.
A Hierarchical Approach for Strategic Motion Planning in Autonomous Racing
Dec 03, 2022We present an approach for safe trajectory planning, where a strategic task related to autonomous racing is learned sample-efficient within a simulation environment. A high-level policy, represented as a neural network, outputs a reward specification that is used within the cost function of a parametric nonlinear model predictive controller (NMPC). By including constraints and vehicle kinematics in the NLP, we are able to guarantee safe and feasible trajectories related to the used model. Compared to classical reinforcement learning (RL), our approach restricts the exploration to safe trajectories, starts with a good prior performance and yields full trajectories that can be passed to a tracking lowest-level controller. We do not address the lowest-level controller in this work and assume perfect tracking of feasible trajectories. We show the superior performance of our algorithm on simulated racing tasks that include high-level decision making. The vehicle learns to efficiently overtake slower vehicles and to avoid getting overtaken by blocking faster vehicles.
On the calibration of underrepresented classes in LiDAR-based semantic segmentation
Oct 13, 2022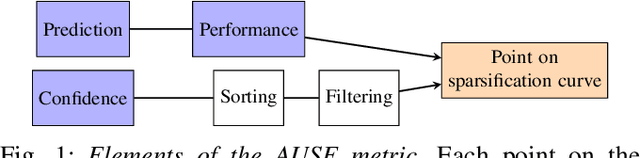
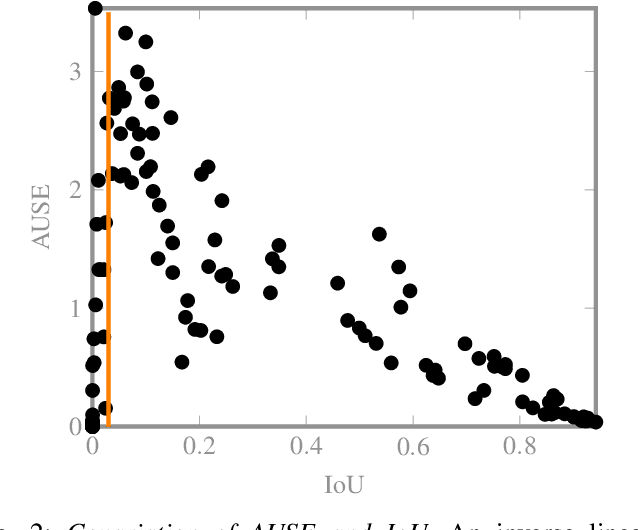
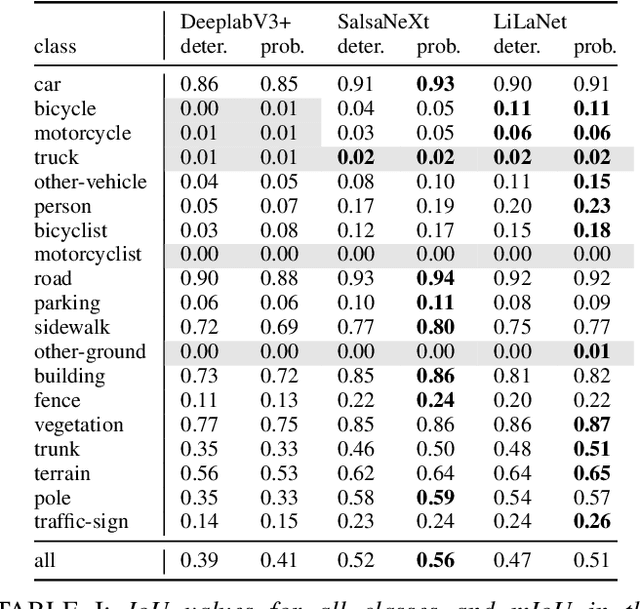
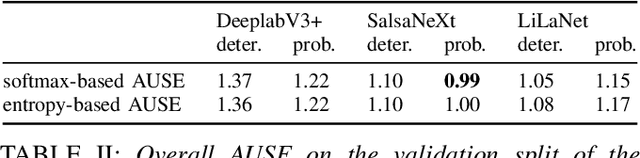
The calibration of deep learning-based perception models plays a crucial role in their reliability. Our work focuses on a class-wise evaluation of several model's confidence performance for LiDAR-based semantic segmentation with the aim of providing insights into the calibration of underrepresented classes. Those classes often include VRUs and are thus of particular interest for safety reasons. With the help of a metric based on sparsification curves we compare the calibration abilities of three semantic segmentation models with different architectural concepts, each in a in deterministic and a probabilistic version. By identifying and describing the dependency between the predictive performance of a class and the respective calibration quality we aim to facilitate the model selection and refinement for safety-critical applications.
Latent Plans for Task-Agnostic Offline Reinforcement Learning
Sep 19, 2022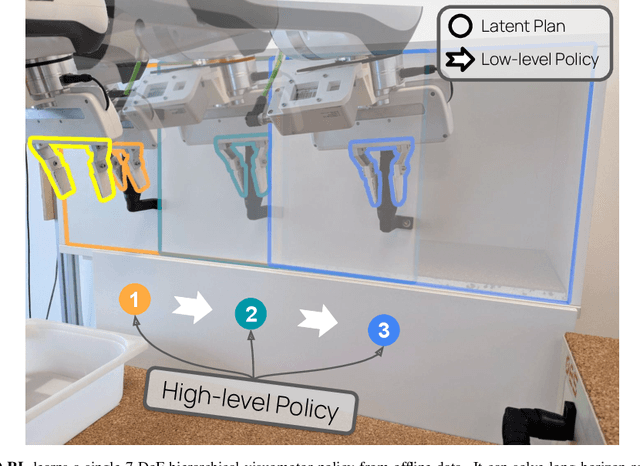
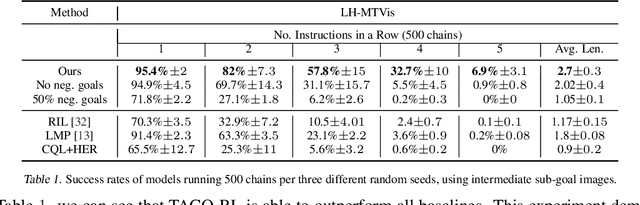
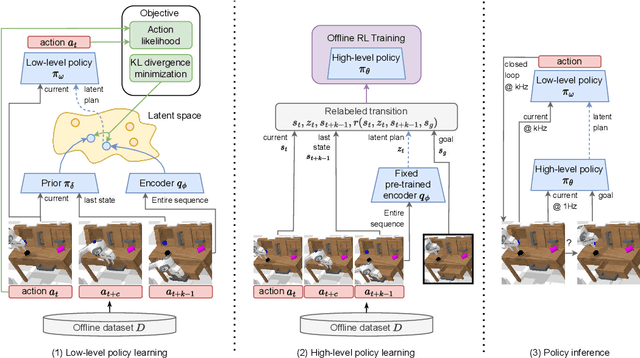
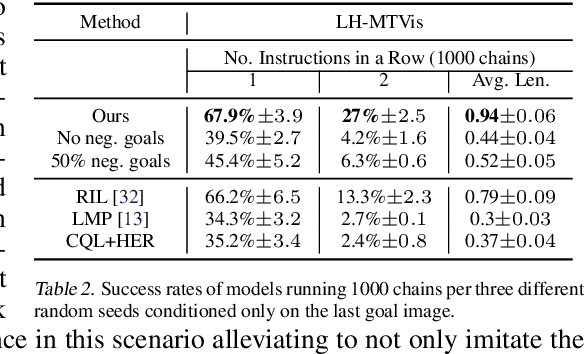
Everyday tasks of long-horizon and comprising a sequence of multiple implicit subtasks still impose a major challenge in offline robot control. While a number of prior methods aimed to address this setting with variants of imitation and offline reinforcement learning, the learned behavior is typically narrow and often struggles to reach configurable long-horizon goals. As both paradigms have complementary strengths and weaknesses, we propose a novel hierarchical approach that combines the strengths of both methods to learn task-agnostic long-horizon policies from high-dimensional camera observations. Concretely, we combine a low-level policy that learns latent skills via imitation learning and a high-level policy learned from offline reinforcement learning for skill-chaining the latent behavior priors. Experiments in various simulated and real robot control tasks show that our formulation enables producing previously unseen combinations of skills to reach temporally extended goals by "stitching" together latent skills through goal chaining with an order-of-magnitude improvement in performance upon state-of-the-art baselines. We even learn one multi-task visuomotor policy for 25 distinct manipulation tasks in the real world which outperforms both imitation learning and offline reinforcement learning techniques.
Robust Reinforcement Learning in Continuous Control Tasks with Uncertainty Set Regularization
Jul 05, 2022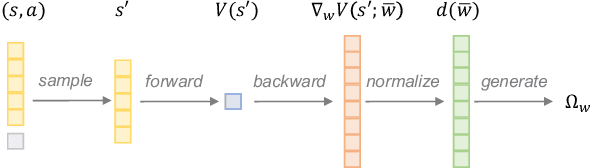
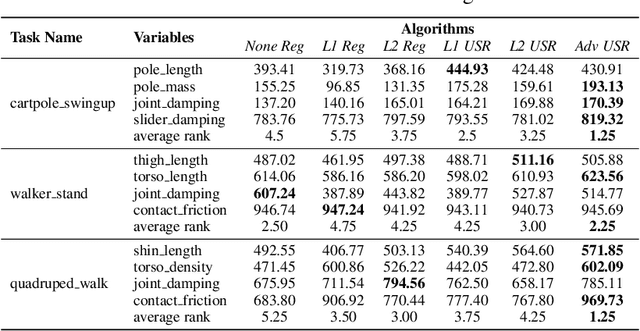

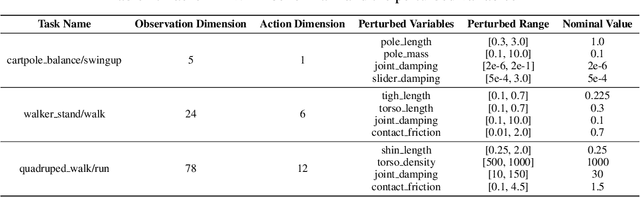
Reinforcement learning (RL) is recognized as lacking generalization and robustness under environmental perturbations, which excessively restricts its application for real-world robotics. Prior work claimed that adding regularization to the value function is equivalent to learning a robust policy with uncertain transitions. Although the regularization-robustness transformation is appealing for its simplicity and efficiency, it is still lacking in continuous control tasks. In this paper, we propose a new regularizer named $\textbf{U}$ncertainty $\textbf{S}$et $\textbf{R}$egularizer (USR), by formulating the uncertainty set on the parameter space of the transition function. In particular, USR is flexible enough to be plugged into any existing RL framework. To deal with unknown uncertainty sets, we further propose a novel adversarial approach to generate them based on the value function. We evaluate USR on the Real-world Reinforcement Learning (RWRL) benchmark, demonstrating improvements in the robust performance for perturbed testing environments.