 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Reinforcement Learning in Continuous Control Tasks with Uncertainty Set Regularization
Paper and Code
Jul 05, 2022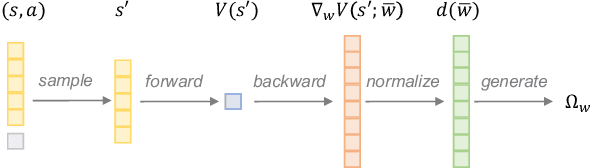
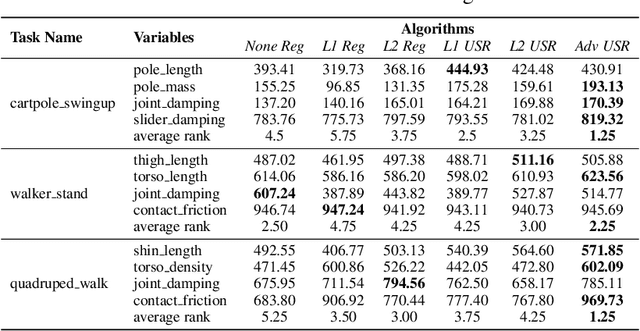

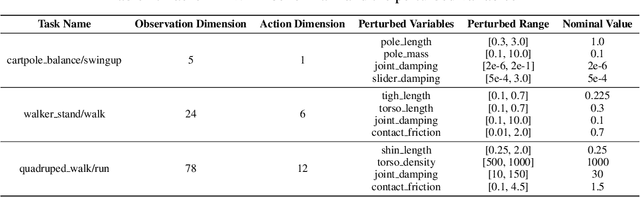
Reinforcement learning (RL) is recognized as lacking generalization and robustness under environmental perturbations, which excessively restricts its application for real-world robotics. Prior work claimed that adding regularization to the value function is equivalent to learning a robust policy with uncertain transitions. Although the regularization-robustness transformation is appealing for its simplicity and efficiency, it is still lacking in continuous control tasks. In this paper, we propose a new regularizer named $\textbf{U}$ncertainty $\textbf{S}$et $\textbf{R}$egularizer (USR), by formulating the uncertainty set on the parameter space of the transition function. In particular, USR is flexible enough to be plugged into any existing RL framework. To deal with unknown uncertainty sets, we further propose a novel adversarial approach to generate them based on the value function. We evaluate USR on the Real-world Reinforcement Learning (RWRL) benchmark, demonstrating improvements in the robust performance for perturbed testing environments.