 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity Map Distillation for Incremental Object Counting
Apr 11, 2023We investigate the problem of incremental learning for object counting, where a method must learn to count a variety of object classes from a sequence of datasets. A na\"ive approach to incremental object counting would suffer from catastrophic forgetting, where it would suffer from a dramatic performance drop on previous tasks. In this paper, we propose a new exemplar-free functional regularization method, called Density Map Distillation (DMD). During training, we introduce a new counter head for each task and introduce a distillation loss to prevent forgetting of previous tasks. Additionally, we introduce a cross-task adaptor that projects the features of the current backbone to the previous backbone. This projector allows for the learning of new features while the backbone retains the relevant features for previous tasks. Finally, we set up experiments of incremental learning for counting new objects. Results confirm that our method greatly reduces catastrophic forgetting and outperforms existing methods.
StyleDiffusion: Prompt-Embedding Inversion for Text-Based Editing
Mar 28, 2023



A significant research effort is focused on exploiting the amazing capacities of pretrained diffusion models for the editing of images. They either finetune the model, or invert the image in the latent space of the pretrained model. However, they suffer from two problems: (1) Unsatisfying results for selected regions, and unexpected changes in nonselected regions. (2) They require careful text prompt editing where the prompt should include all visual objects in the input image. To address this, we propose two improvements: (1) Only optimizing the input of the value linear network in the cross-attention layers, is sufficiently powerful to reconstruct a real image. (2) We propose attention regularization to preserve the object-like attention maps after editing, enabling us to obtain accurate style editing without invoking significant structural changes. We further improve the editing technique which is used for the unconditional branch of classifier-free guidance, as well as the conditional one as used by P2P. Extensive experimental prompt-editing results on a variety of images, demonstrate qualitatively and quantitatively that our method has superior editing capabilities than existing and concurrent works.
Projected Latent Distillation for Data-Agnostic Consolidation in Distributed Continual Learning
Mar 28, 2023



Distributed learning on the edge often comprises self-centered devices (SCD) which learn local tasks independently and are unwilling to contribute to the performance of other SDCs. How do we achieve forward transfer at zero cost for the single SCDs? We formalize this problem as a Distributed Continual Learning scenario, where SCD adapt to local tasks and a CL model consolidates the knowledge from the resulting stream of models without looking at the SCD's private data. Unfortunately, current CL methods are not directly applicable to this scenario. We propose Data-Agnostic Consolidation (DAC), a novel double knowledge distillation method that consolidates the stream of SC models without using the original data. DAC performs distillation in the latent space via a novel Projected Latent Distillation loss. Experimental results show that DAC enables forward transfer between SCDs and reaches state-of-the-art accuracy on Split CIFAR100, CORe50 and Split TinyImageNet, both in reharsal-free and distributed CL scenarios. Somewhat surprisingly, even a single out-of-distribution image is sufficient as the only source of data during consolidation.
3D-Aware Multi-Class Image-to-Image Translation with NeRFs
Mar 27, 2023Recent advances in 3D-aware generative models (3D-aware GANs) combined with Neural Radiance Fields (NeRF) have achieved impressive results. However no prior works investigate 3D-aware GANs for 3D consistent multi-class image-to-image (3D-aware I2I) translation. Naively using 2D-I2I translation methods suffers from unrealistic shape/identity change. To perform 3D-aware multi-class I2I translation, we decouple this learning process into a multi-class 3D-aware GAN step and a 3D-aware I2I translation step. In the first step, we propose two novel techniques: a new conditional architecture and an effective training strategy. In the second step, based on the well-trained multi-class 3D-aware GAN architecture, that preserves view-consistency, we construct a 3D-aware I2I translation system. To further reduce the view-consistency problems, we propose several new techniques, including a U-net-like adaptor network design, a hierarchical representation constrain and a relative regularization loss. In extensive experiments on two datasets, quantitative and qualitative results demonstrate that we successfully perform 3D-aware I2I translation with multi-view consistency.
ICICLE: Interpretable Class Incremental Continual Learning
Mar 14, 2023Continual learning enables incremental learning of new tasks without forgetting those previously learned, resulting in positive knowledge transfer that can enhance performance on both new and old tasks. However, continual learning poses new challenges for interpretability, as the rationale behind model predictions may change over time, leading to interpretability concept drift. We address this problem by proposing Interpretable Class-InCremental LEarning (ICICLE), an exemplar-free approach that adopts a prototypical part-based approach. It consists of three crucial novelties: interpretability regularization that distills previously learned concepts while preserving user-friendly positive reasoning; proximity-based prototype initialization strategy dedicated to the fine-grained setting; and task-recency bias compensation devoted to prototypical parts. Our experimental results demonstrate that ICICLE reduces the interpretability concept drift and outperforms the existing exemplar-free methods of common class-incremental learning when applied to concept-based models. We make the code available.
Towards Label-Efficient Incremental Learning: A Survey
Feb 11, 2023The current dominant paradigm when building a machine learning model is to iterate over a dataset over and over until convergence. Such an approach is non-incremental, as it assumes access to all images of all categories at once. However, for many applications, non-incremental learning is unrealistic. To that end, researchers study incremental learning, where a learner is required to adapt to an incoming stream of data with a varying distribution while preventing forgetting of past knowledge. Significant progress has been made, however, the vast majority of works focus on the fully supervised setting, making these algorithms label-hungry thus limiting their real-life deployment. To that end, in this paper, we make the first attempt to survey recently growing interest in label-efficient incremental learning. We identify three subdivisions, namely semi-, few-shot- and self-supervised learning to reduce labeling efforts. Finally, we identify novel directions that can further enhance label-efficiency and improve incremental learning scalability. Project website: https://github.com/kilickaya/label-efficient-il.
Gated Class-Attention with Cascaded Feature Drift Compensation for Exemplar-free Continual Learning of Vision Transformers
Nov 22, 2022In this paper we propose a new method for exemplar-free class incremental training of ViTs. The main challenge of exemplar-free continual learning is maintaining plasticity of the learner without causing catastrophic forgetting of previously learned tasks. This is often achieved via exemplar replay which can help recalibrate previous task classifiers to the feature drift which occurs when learning new tasks. Exemplar replay, however, comes at the cost of retaining samples from previous tasks which for some applications may not be possible. To address the problem of continual ViT training, we first propose gated class-attention to minimize the drift in the final ViT transformer block. This mask-based gating is applied to class-attention mechanism of the last transformer block and strongly regulates the weights crucial for previous tasks. Secondly, we propose a new method of feature drift compensation that accommodates feature drift in the backbone when learning new tasks. The combination of gated class-attention and cascaded feature drift compensation allows for plasticity towards new tasks while limiting forgetting of previous ones. Extensive experiments performed on CIFAR-100, Tiny-ImageNet and ImageNet100 demonstrate that our method outperforms existing exemplar-free state-of-the-art methods without the need to store any representative exemplars of past tasks.
Attribution-aware Weight Transfer: A Warm-Start Initialization for Class-Incremental Semantic Segmentation
Oct 13, 2022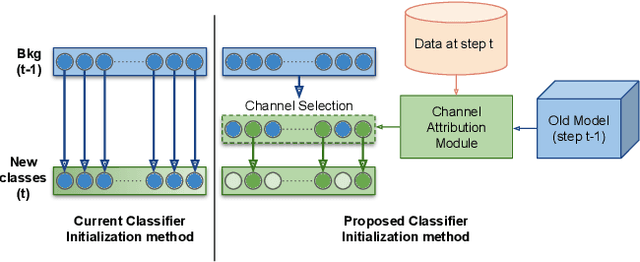
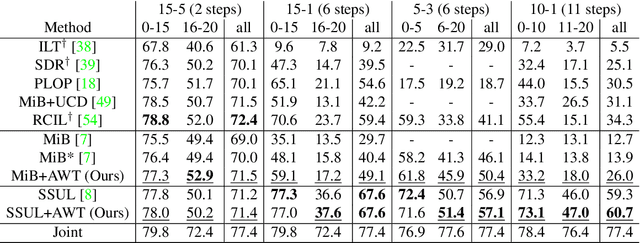

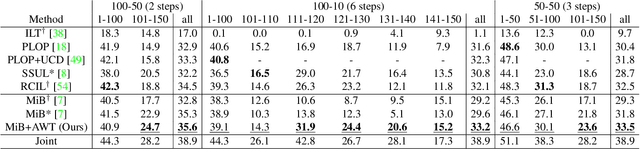
In class-incremental semantic segmentation (CISS), deep learning architectures suffer from the critical problems of catastrophic forgetting and semantic background shift. Although recent works focused on these issues, existing classifier initialization methods do not address the background shift problem and assign the same initialization weights to both background and new foreground class classifiers. We propose to address the background shift with a novel classifier initialization method which employs gradient-based attribution to identify the most relevant weights for new classes from the classifier's weights for the previous background and transfers these weights to the new classifier. This warm-start weight initialization provides a general solution applicable to several CISS methods. Furthermore, it accelerates learning of new classes while mitigating forgetting. Our experiments demonstrate significant improvement in mIoU compared to the state-of-the-art CISS methods on the Pascal-VOC 2012, ADE20K and Cityscapes datasets.
Positive Pair Distillation Considered Harmful: Continual Meta Metric Learning for Lifelong Object Re-Identification
Oct 04, 2022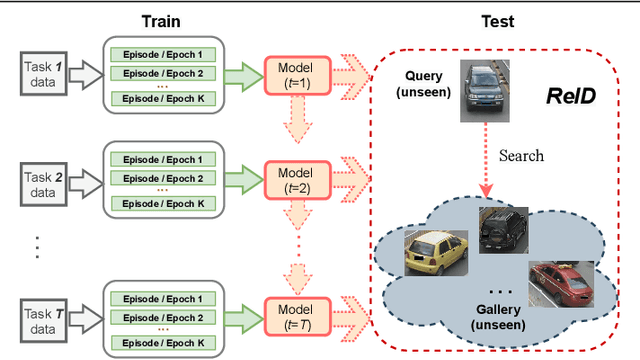

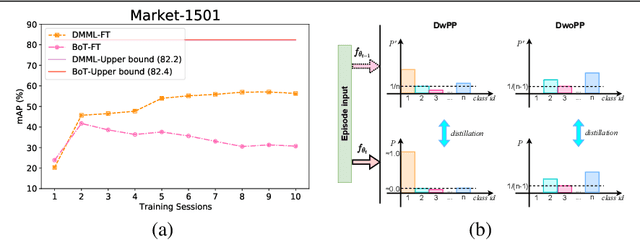

Lifelong object re-identification incrementally learns from a stream of re-identification tasks. The objective is to learn a representation that can be applied to all tasks and that generalizes to previously unseen re-identification tasks. The main challenge is that at inference time the representation must generalize to previously unseen identities. To address this problem, we apply continual meta metric learning to lifelong object re-identification. To prevent forgetting of previous tasks, we use knowledge distillation and explore the roles of positive and negative pairs. Based on our observation that the distillation and metric losses are antagonistic, we propose to remove positive pairs from distillation to robustify model updates. Our method, called Distillation without Positive Pairs (DwoPP), is evaluated on extensive intra-domain experiments on person and vehicle re-identification datasets, as well as inter-domain experiments on the LReID benchmark. Our experiments demonstrate that DwoPP significantly outperforms the state-of-the-art. The code is here: https://github.com/wangkai930418/DwoPP_code
Attention Distillation: self-supervised vision transformer students need more guidance
Oct 03, 2022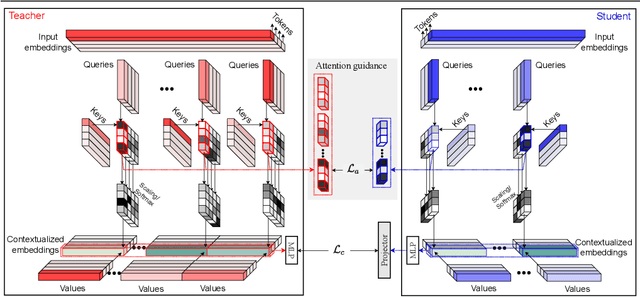
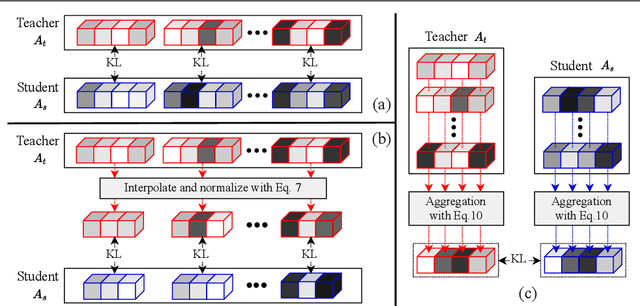
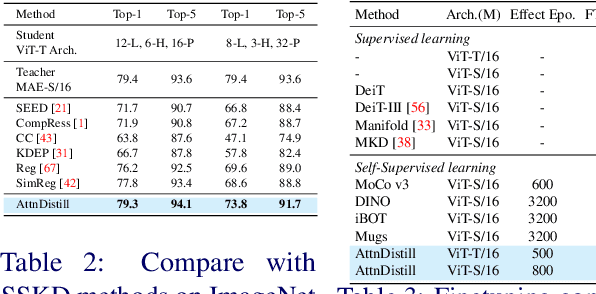
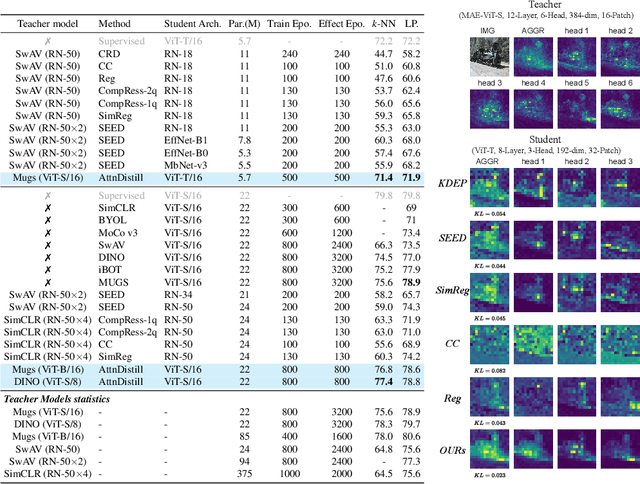
Self-supervised learning has been widely applied to train high-quality vision transformers. Unleashing their excellent performance on memory and compute constraint devices is therefore an important research topic. However, how to distill knowledge from one self-supervised ViT to another has not yet been explored. Moreover, the existing self-supervised knowledge distillation (SSKD) methods focus on ConvNet based architectures are suboptimal for ViT knowledge distillation. In this paper, we study knowledge distillation of self-supervised vision transformers (ViT-SSKD). We show that directly distilling information from the crucial attention mechanism from teacher to student can significantly narrow the performance gap between both. In experiments on ImageNet-Subset and ImageNet-1K, we show that our method AttnDistill outperforms existing self-supervised knowledge distillation (SSKD) methods and achieves state-of-the-art k-NN accuracy compared with self-supervised learning (SSL) methods learning from scratch (with the ViT-S model). We are also the first to apply the tiny ViT-T model on self-supervised learning. Moreover, AttnDistill is independent of self-supervised learning algorithms, it can be adapted to ViT based SSL methods to improve the performance in future research. The code is here: https://github.com/wangkai930418/attndistill