 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixColor: Pixel Recursive Colorization
Jun 05, 2017
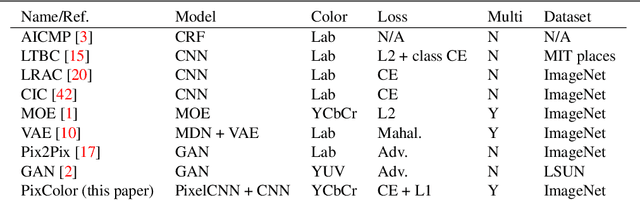


We propose a novel approach to automatically produce multiple colorized versions of a grayscale image. Our method results from the observation that the task of automated colorization is relatively easy given a low-resolution version of the color image. We first train a conditional PixelCNN to generate a low resolution color for a given grayscale image. Then, given the generated low-resolution color image and the original grayscale image as inputs, we train a second CNN to generate a high-resolution colorization of an image. We demonstrate that our approach produces more diverse and plausible colorizations than existing methods, as judged by human raters in a "Visual Turing Test".
YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video
Mar 24, 2017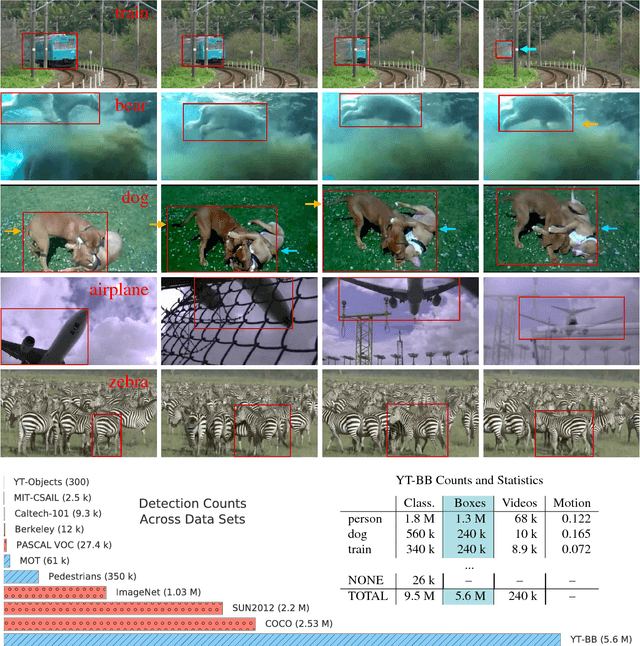
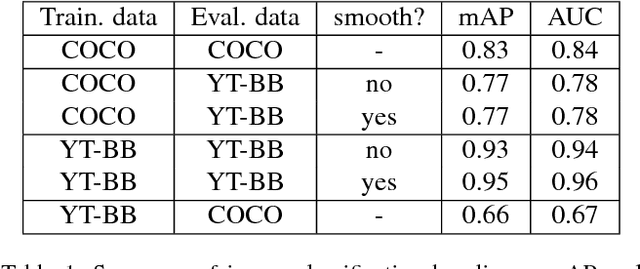
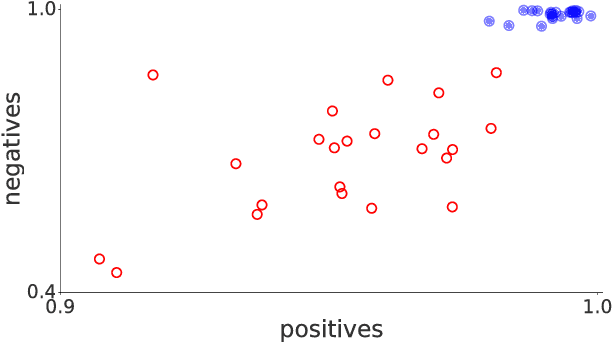

We introduce a new large-scale data set of video URLs with densely-sampled object bounding box annotations called YouTube-BoundingBoxes (YT-BB). The data set consists of approximately 380,000 video segments about 19s long, automatically selected to feature objects in natural settings without editing or post-processing, with a recording quality often akin to that of a hand-held cell phone camera. The objects represent a subset of the MS COCO label set. All video segments were human-annotated with high-precision classification labels and bounding boxes at 1 frame per second. The use of a cascade of increasingly precise human annotations ensures a label accuracy above 95% for every class and tight bounding boxes. Finally, we train and evaluate well-known deep network architectures and report baseline figures for per-frame classification and localization to provide a point of comparison for future work. We also demonstrate how the temporal contiguity of video can potentially be used to improve such inferences. Please see the PDF file to find the URL to download the data. We hope the availability of such large curated corpus will spur new advances in video object detection and tracking.
Pixel Recursive Super Resolution
Mar 22, 2017
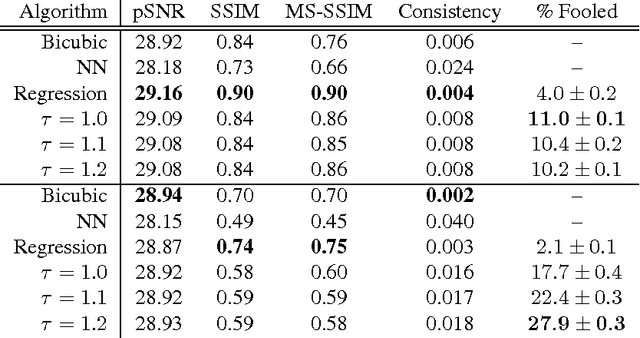
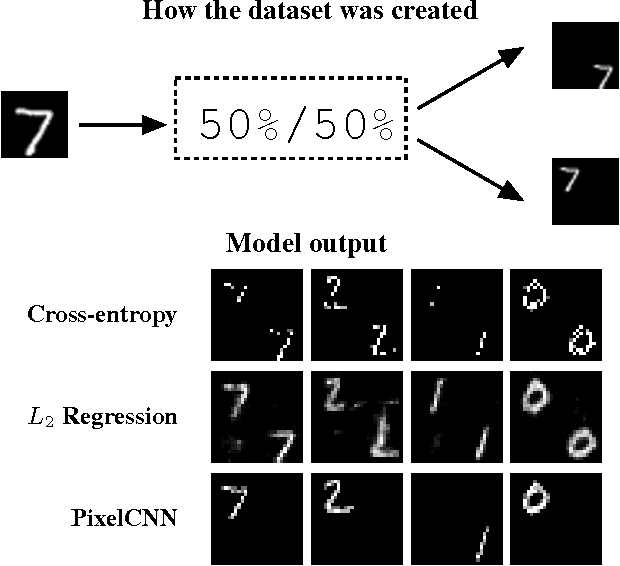
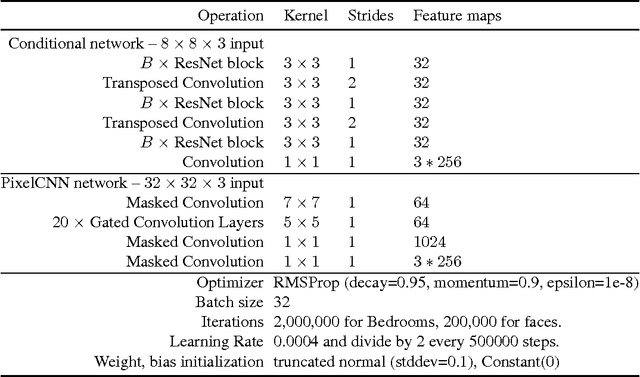
We present a pixel recursive super resolution model that synthesizes realistic details into images while enhancing their resolution. A low resolution image may correspond to multiple plausible high resolution images, thus modeling the super resolution process with a pixel independent conditional model often results in averaging different details--hence blurry edges. By contrast, our model is able to represent a multimodal conditional distribution by properly modeling the statistical dependencies among the high resolution image pixels, conditioned on a low resolution input. We employ a PixelCNN architecture to define a strong prior over natural images and jointly optimize this prior with a deep conditioning convolutional network. Human evaluations indicate that samples from our proposed model look more photo realistic than a strong L2 regression baseline.
A Learned Representation For Artistic Style
Feb 09, 2017
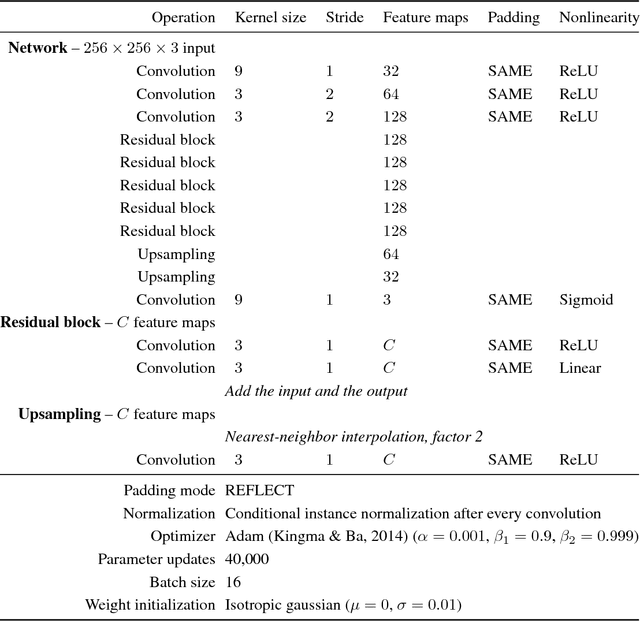
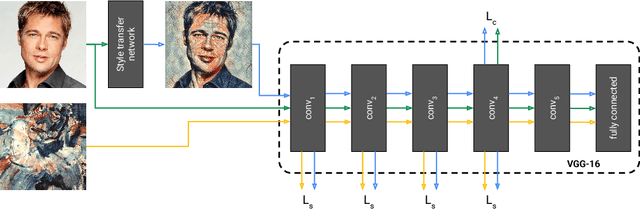
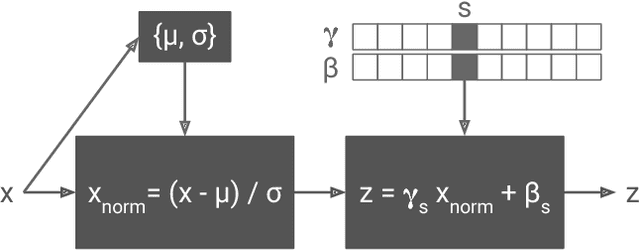
The diversity of painting styles represents a rich visual vocabulary for the construction of an image. The degree to which one may learn and parsimoniously capture this visual vocabulary measures our understanding of the higher level features of paintings, if not images in general. In this work we investigate the construction of a single, scalable deep network that can parsimoniously capture the artistic style of a diversity of paintings. We demonstrate that such a network generalizes across a diversity of artistic styles by reducing a painting to a point in an embedding space. Importantly, this model permits a user to explore new painting styles by arbitrarily combining the styles learned from individual paintings. We hope that this work provides a useful step towards building rich models of paintings and offers a window on to the structure of the learned representation of artistic style.
Adversarial Autoencoders
May 25, 2016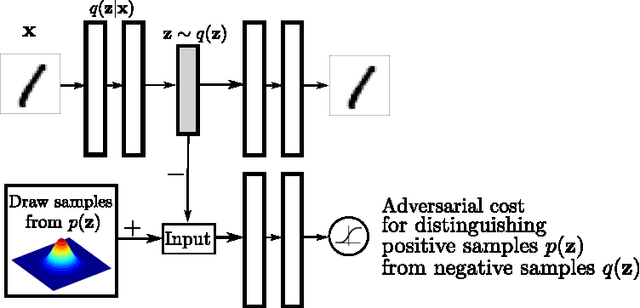
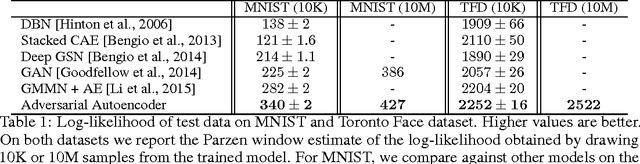
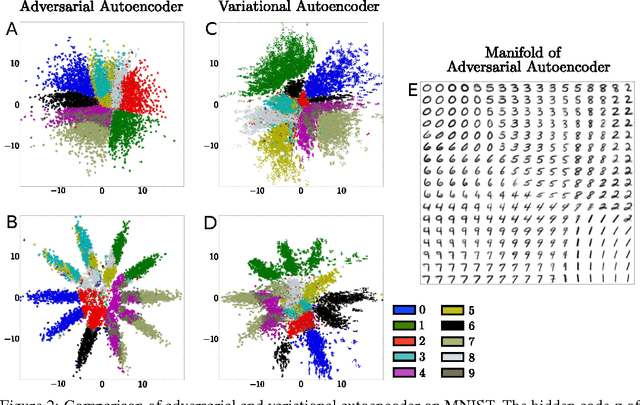
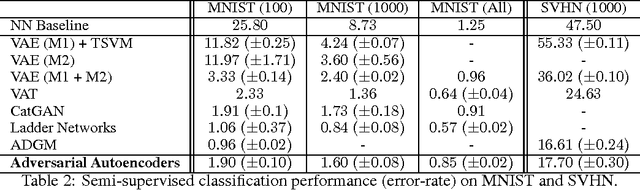
In this paper, we propose the "adversarial autoencoder" (AAE), which is a probabilistic autoencoder that uses the recently proposed generative adversarial networks (GAN) to perform variational inference by matching the aggregated posterior of the hidden code vector of the autoencoder with an arbitrary prior distribution. Matching the aggregated posterior to the prior ensures that generating from any part of prior space results in meaningful samples. As a result, the decoder of the adversarial autoencoder learns a deep generative model that maps the imposed prior to the data distribution. We show how the adversarial autoencoder can be used in applications such as semi-supervised classification, disentangling style and content of images, unsupervised clustering, dimensionality reduction and data visualization. We performed experiments on MNIST, Street View House Numbers and Toronto Face datasets and show that adversarial autoencoders achieve competitive results in generative modeling and semi-supervised classification tasks.
Net2Net: Accelerating Learning via Knowledge Transfer
Apr 23, 2016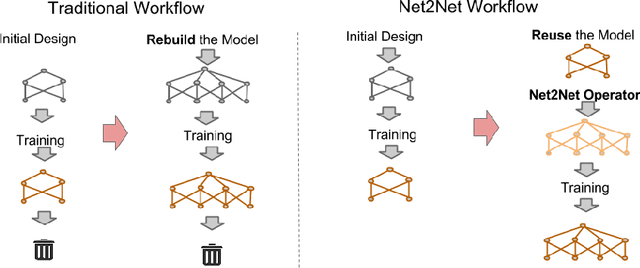
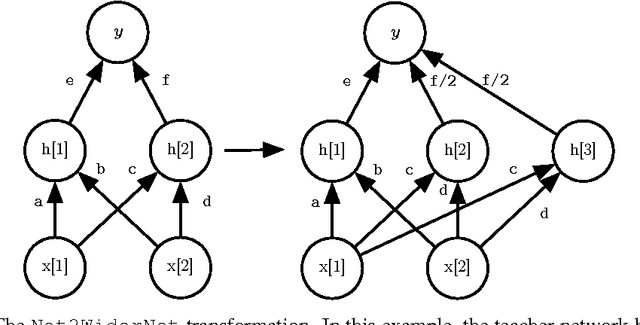
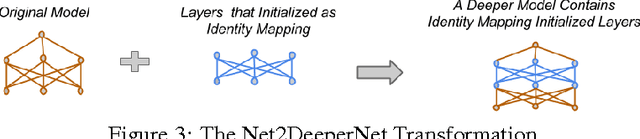
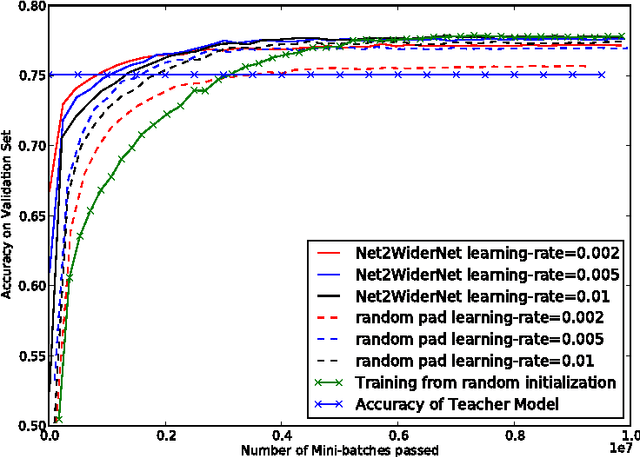
We introduce techniques for rapidly transferring the information stored in one neural net into another neural net. The main purpose is to accelerate the training of a significantly larger neural net. During real-world workflows, one often trains very many different neural networks during the experimentation and design process. This is a wasteful process in which each new model is trained from scratch. Our Net2Net technique accelerates the experimentation process by instantaneously transferring the knowledge from a previous network to each new deeper or wider network. Our techniques are based on the concept of function-preserving transformations between neural network specifications. This differs from previous approaches to pre-training that altered the function represented by a neural net when adding layers to it. Using our knowledge transfer mechanism to add depth to Inception modules, we demonstrate a new state of the art accuracy rating on the ImageNet dataset.
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Mar 16, 2016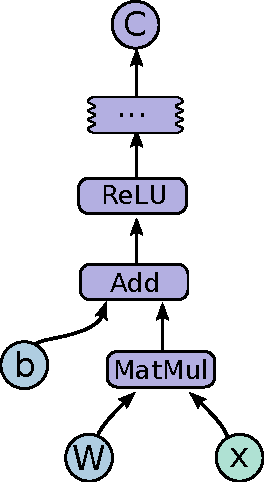

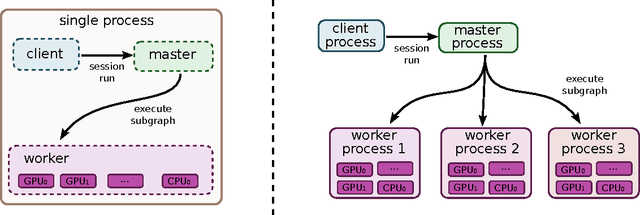
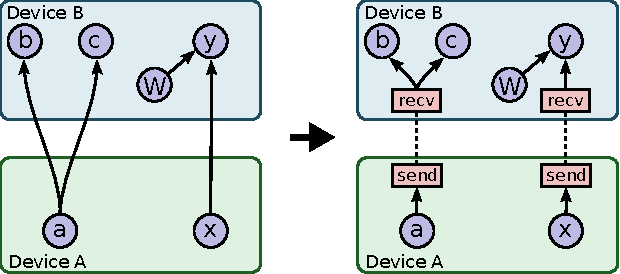
TensorFlow is an interface for expressing machine learning algorithms, and an implementation for executing such algorithms. A computation expressed using TensorFlow can be executed with little or no change on a wide variety of heterogeneous systems, ranging from mobile devices such as phones and tablets up to large-scale distributed systems of hundreds of machines and thousands of computational devices such as GPU cards. The system is flexible and can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models, and it has been used for conducting research and for deploying machine learning systems into production across more than a dozen areas of computer science and other fields, including speech recognition, computer vision, robotics, information retrieval, natural language processing, geographic information extraction, and computational drug discovery. This paper describes the TensorFlow interface and an implementation of that interface that we have built at Google. The TensorFlow API and a reference implementation were released as an open-source package under the Apache 2.0 license in November, 2015 and are available at www.tensorflow.org.
Rethinking the Inception Architecture for Computer Vision
Dec 11, 2015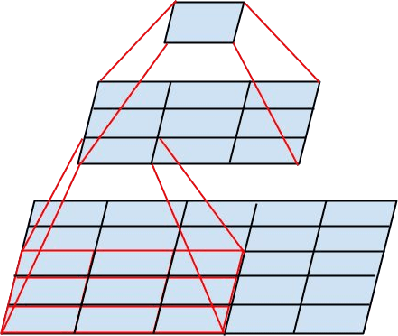
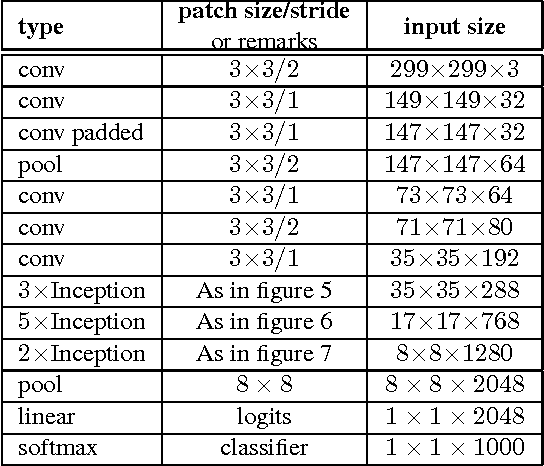
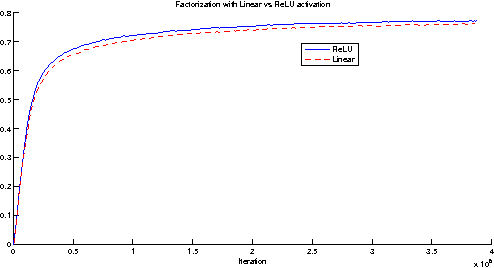
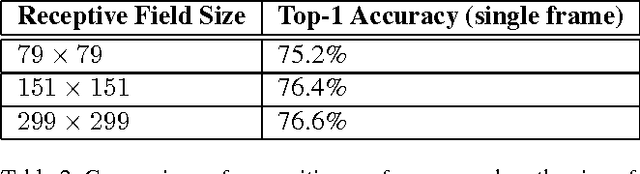
Convolutional networks are at the core of most state-of-the-art computer vision solutions for a wide variety of tasks. Since 2014 very deep convolutional networks started to become mainstream, yielding substantial gains in various benchmarks. Although increased model size and computational cost tend to translate to immediate quality gains for most tasks (as long as enough labeled data is provided for training), computational efficiency and low parameter count are still enabling factors for various use cases such as mobile vision and big-data scenarios. Here we explore ways to scale up networks in ways that aim at utilizing the added computation as efficiently as possible by suitably factorized convolutions and aggressive regularization. We benchmark our methods on the ILSVRC 2012 classification challenge validation set demonstrate substantial gains over the state of the art: 21.2% top-1 and 5.6% top-5 error for single frame evaluation using a network with a computational cost of 5 billion multiply-adds per inference and with using less than 25 million parameters. With an ensemble of 4 models and multi-crop evaluation, we report 3.5% top-5 error on the validation set (3.6% error on the test set) and 17.3% top-1 error on the validation set.
Deep Networks With Large Output Spaces
Apr 10, 2015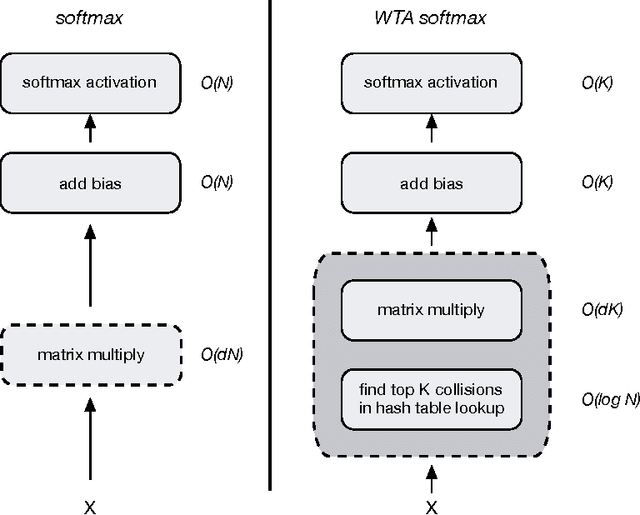
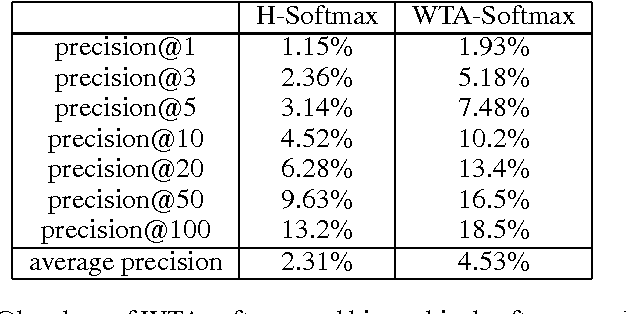
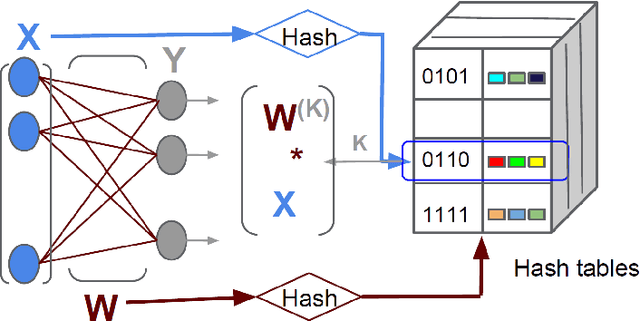
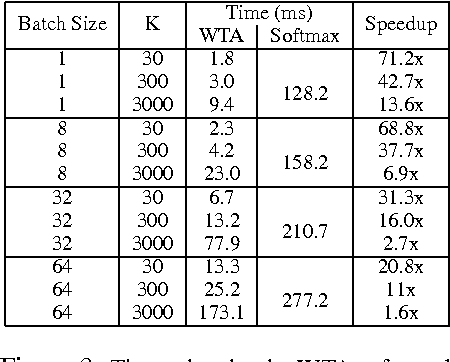
Deep neural networks have been extremely successful at various image, speech, video recognition tasks because of their ability to model deep structures within the data. However, they are still prohibitively expensive to train and apply for problems containing millions of classes in the output layer. Based on the observation that the key computation common to most neural network layers is a vector/matrix product, we propose a fast locality-sensitive hashing technique to approximate the actual dot product enabling us to scale up the training and inference to millions of output classes. We evaluate our technique on three diverse large-scale recognition tasks and show that our approach can train large-scale models at a faster rate (in terms of steps/total time) compared to baseline methods.
Explaining and Harnessing Adversarial Examples
Mar 20, 2015

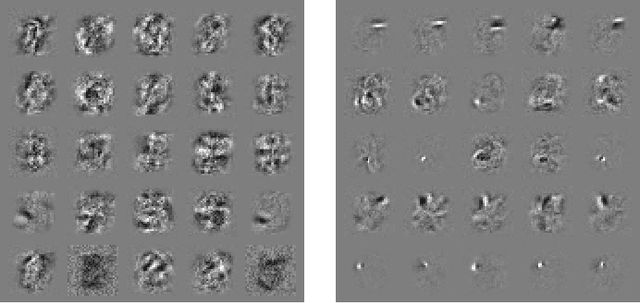
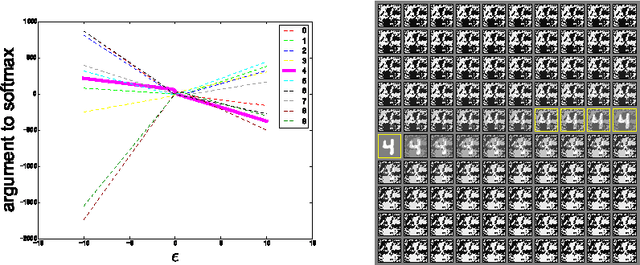
Several machine learning models, including neural networks, consistently misclassify adversarial examples---inputs formed by applying small but intentionally worst-case perturbations to examples from the dataset, such that the perturbed input results in the model outputting an incorrect answer with high confidence. Early attempts at explaining this phenomenon focused on nonlinearity and overfitting. We argue instead that the primary cause of neural networks' vulnerability to adversarial perturbation is their linear nature. This explanation is supported by new quantitative results while giving the first explanation of the most intriguing fact about them: their generalization across architectures and training sets. Moreover, this view yields a simple and fast method of generating adversarial examples. Using this approach to provide examples for adversarial training, we reduce the test set error of a maxout network on the MNIST dataset.