 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPPER: A Graph-Theoretic Framework for Robust Data Association
Nov 20, 2020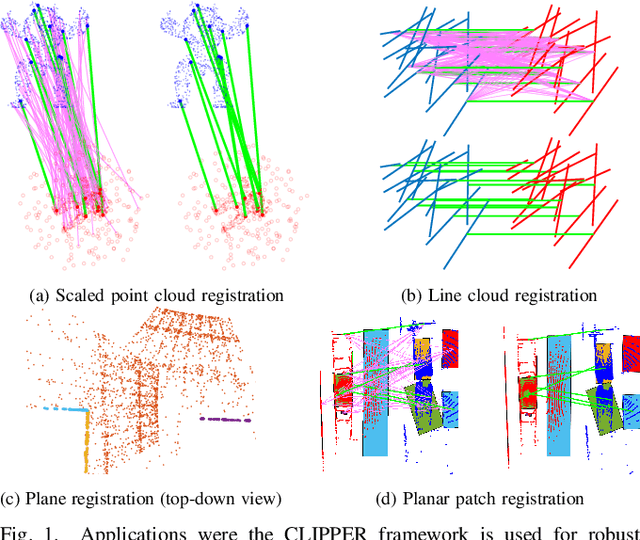

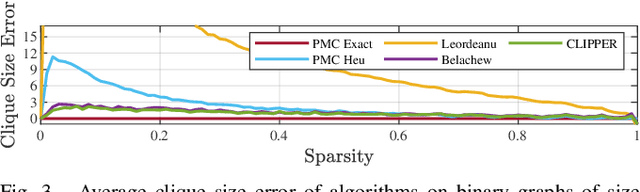
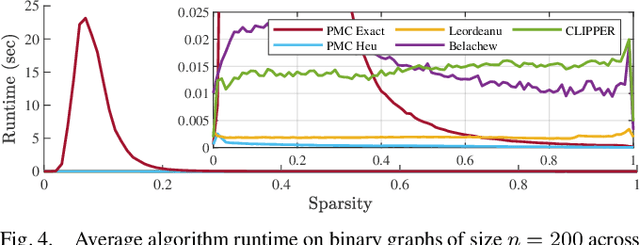
We present CLIPPER (Consistent LInking, Pruning, and Pairwise Error Rectification), a framework for robust data association in the presence of noise and outliers. We formulate the problem in a graph-theoretic framework using the notion of geometric consistency. State-of-the-art techniques that use this framework utilize either combinatorial optimization techniques that do not scale well to large-sized problems, or use heuristic approximations that yield low accuracy in high-noise, high-outlier regimes. In contrast, CLIPPER uses a relaxation of the combinatorial problem and returns solutions that are guaranteed to correspond to the optima of the original problem. Low time complexity is achieved with an efficient projected gradient ascent approach. Experiments indicate that CLIPPER maintains a consistently low runtime of 15 ms where exact methods can require up to 24 s at their peak, even on small-sized problems with 200 associations. When evaluated on noisy point cloud registration problems, CLIPPER achieves 100% precision and 98% recall in 90% outlier regimes while competing algorithms begin degrading by 70% outliers. In an instance of associating noisy points of the Stanford Bunny with 990 outlier associations and only 10 inlier associations, CLIPPER successfully returns 8 inlier associations with 100% precision in 138 ms.
Kimera-Multi: a System for Distributed Multi-Robot Metric-Semantic Simultaneous Localization and Mapping
Nov 08, 2020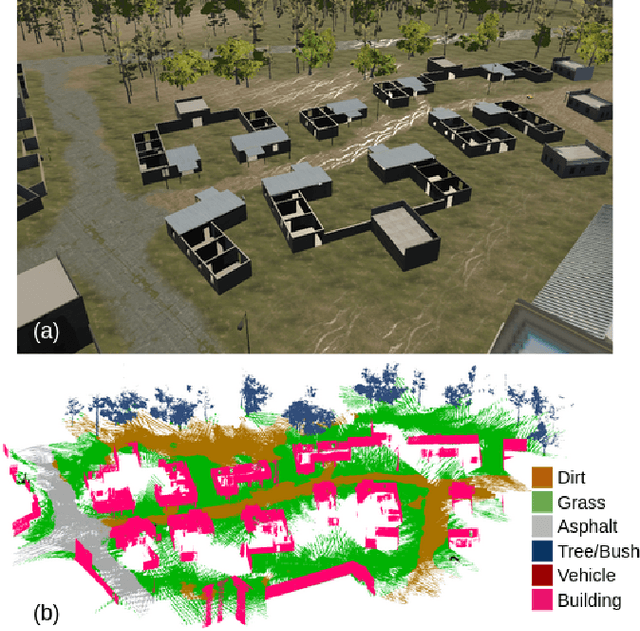
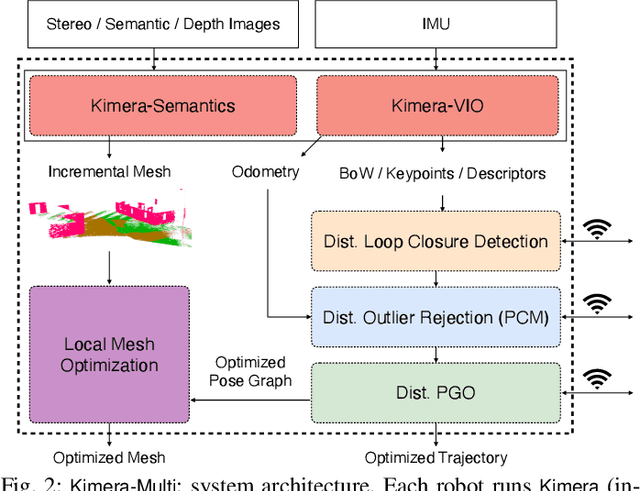
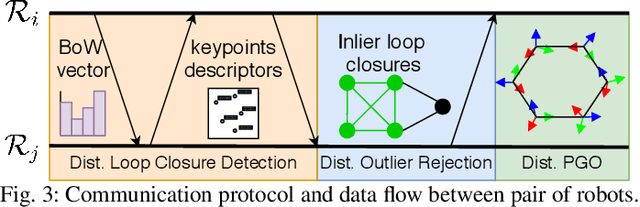
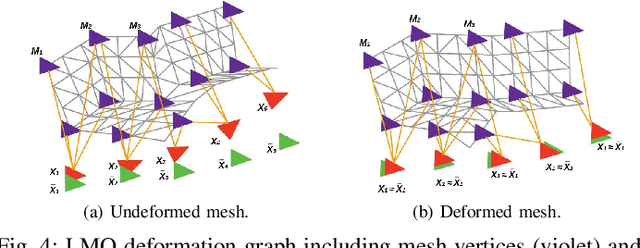
We present the first fully distributed multi-robot system for dense metric-semantic Simultaneous Localization and Mapping (SLAM). Our system, dubbed Kimera-Multi, is implemented by a team of robots equipped with visual-inertial sensors, and builds a 3D mesh model of the environment in real-time, where each face of the mesh is annotated with a semantic label (e.g., building, road, objects). In Kimera-Multi, each robot builds a local trajectory estimate and a local mesh using Kimera. Then, when two robots are within communication range, they initiate a distributed place recognition and robust pose graph optimization protocol with a novel incremental maximum clique outlier rejection; the protocol allows the robots to improve their local trajectory estimates by leveraging inter-robot loop closures. Finally, each robot uses its improved trajectory estimate to correct the local mesh using mesh deformation techniques. We demonstrate Kimera-Multi in photo-realistic simulations and real data. Kimera-Multi (i) is able to build accurate 3D metric-semantic meshes, (ii) is robust to incorrect loop closures while requiring less computation than state-of-the-art distributed SLAM back-ends, and (iii) is efficient, both in terms of computation at each robot as well as communication bandwidth.
A Policy Gradient Algorithm for Learning to Learn in Multiagent Reinforcement Learning
Oct 31, 2020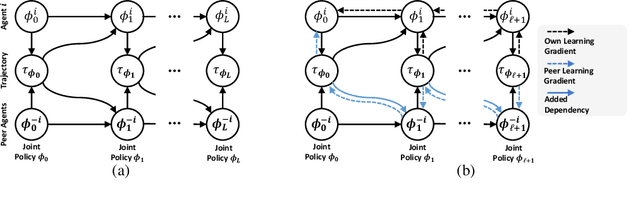
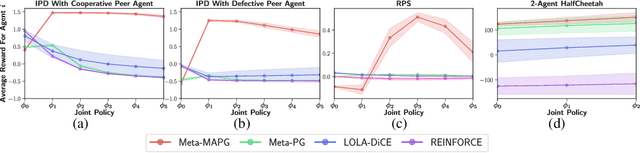

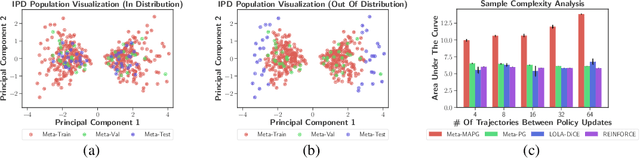
A fundamental challenge in multiagent reinforcement learning is to learn beneficial behaviors in a shared environment with other agents that are also simultaneously learning. In particular, each agent perceives the environment as effectively non-stationary due to the changing policies of other agents. Moreover, each agent is itself constantly learning, leading to natural nonstationarity in the distribution of experiences encountered. In this paper, we propose a novel meta-multiagent policy gradient theorem that directly accommodates for the non-stationary policy dynamics inherent to these multiagent settings. This is achieved by modeling our gradient updates to directly consider both an agent's own non-stationary policy dynamics and the non-stationary policy dynamics of other agents interacting with it in the environment. We find that our theoretically grounded approach provides a general solution to the multiagent learning problem, which inherently combines key aspects of previous state of the art approaches on this topic. We test our method on several multiagent benchmarks and demonstrate a more efficient ability to adapt to new agents as they learn than previous related approaches across the spectrum of mixed incentive, competitive, and cooperative environments.
MADER: Trajectory Planner in Multi-Agent and Dynamic Environments
Oct 21, 2020
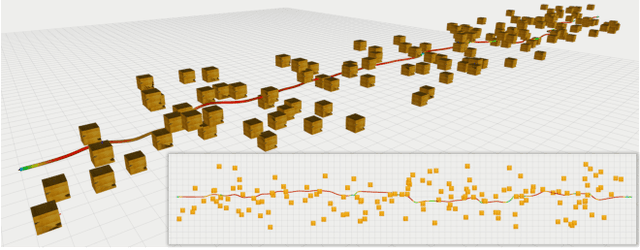
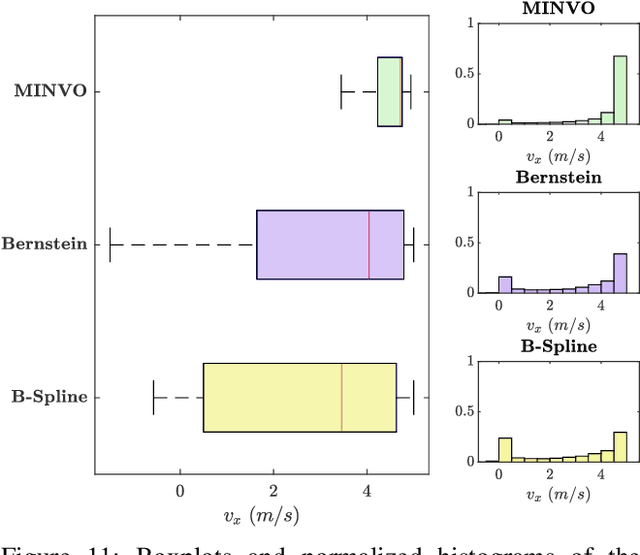
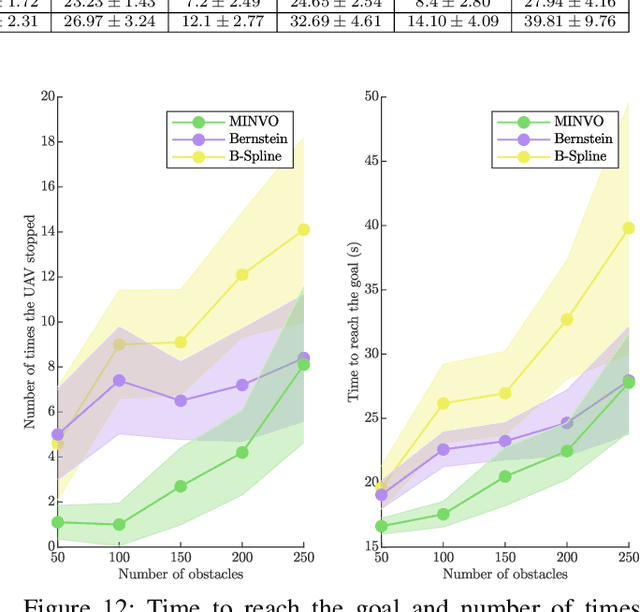
This paper presents MADER, a 3D decentralized and asynchronous trajectory planner for UAVs that generates collision-free trajectories in environments with static obstacles, dynamic obstacles, and other planning agents. Real-time collision avoidance with other dynamic obstacles or agents is done by performing outer polyhedral representations of every interval of the trajectories and then including the plane that separates each pair of polyhedra as a decision variable in the optimization problem. MADER uses our recently developed MINVO basis to obtain outer polyhedral representations with volumes 2.36 and 254.9 times, respectively, smaller than the Bernstein or B-Spline bases used extensively in the planning literature. Our decentralized and asynchronous algorithm guarantees safety with respect to other agents by including their committed trajectories as constraints in the optimization and then executing a collision check-recheck scheme. Finally, extensive simulations in challenging cluttered environments show up to a 33.9% reduction in the flight time, and a 88.8% reduction in the number of stops compared to the Bernstein and B-Spline bases, shorter flight distances than centralized approaches, and shorter total times on average than synchronous decentralized approaches.
MINVO Basis: Finding Simplexes with Minimum Volume Enclosing Polynomial Curves
Oct 21, 2020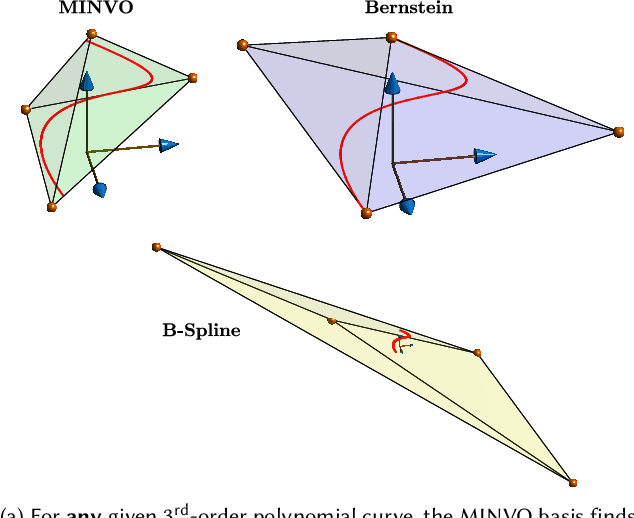
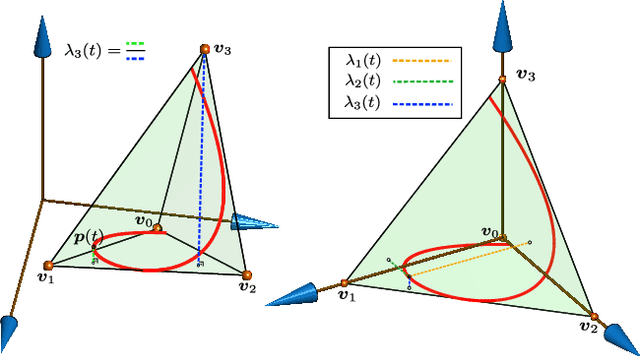
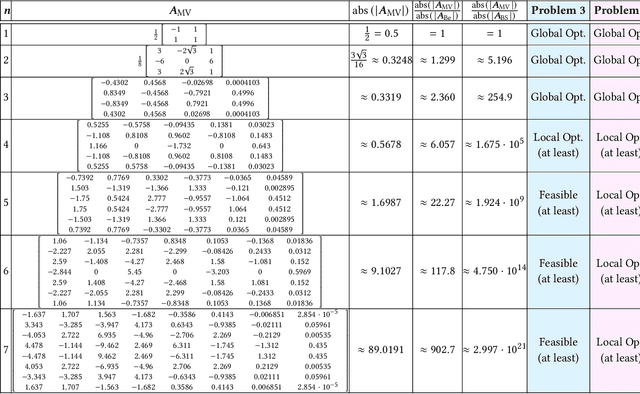
Outer polyhedral representations of a given polynomial curve are extensively exploited in computer graphics rendering, computer gaming, path planning for robots, and finite element simulations. B\'ezier curves (which use the Bernstein basis) or B-Splines are a very common choice for these polyhedral representations because their non-negativity and partition-of-unity properties guarantee that each interval of the curve is contained inside the convex hull of its control points. However, the convex hull provided by these bases is not the one with smallest volume, producing therefore undesirable levels of conservatism in all of the applications mentioned above. This paper presents the MINVO basis, a polynomial basis that generates the smallest $n$-simplex that encloses any given $n^\text{th}$-order polynomial curve. The results obtained for $n=3$ show that, for any given $3^{\text{rd}}$-order polynomial curve, the MINVO basis is able to obtain an enclosing simplex whose volume is $2.36$ and $254.9$ times smaller than the ones obtained by the Bernstein and B-Spline bases, respectively. When $n=7$, these ratios increase to $902.7$ and $2.997\cdot10^{21}$, respectively.
Robustness Analysis of Neural Networks via Efficient Partitioning: Theory and Applications in Control Systems
Oct 01, 2020
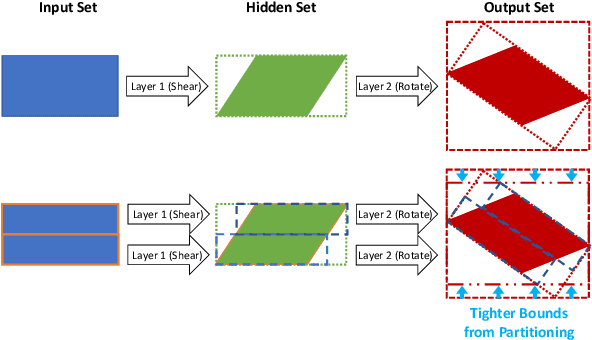
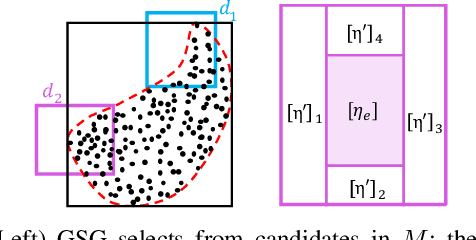
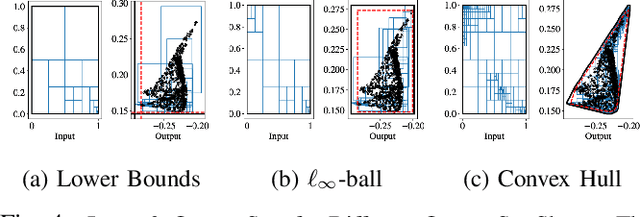
Neural networks (NNs) are now routinely implemented on systems that must operate in uncertain environments, but the tools for formally analyzing how this uncertainty propagates to NN outputs are not yet commonplace. Computing tight bounds on NN output sets (given an input set) provides a measure of confidence associated with the NN decisions and is essential to deploy NNs on safety-critical systems. Recent works approximate the propagation of sets through nonlinear activations or partition the uncertainty set to provide a guaranteed outer bound on the set of possible NN outputs. However, the bound looseness causes excessive conservatism and/or the computation is too slow for online analysis. This paper unifies propagation and partition approaches to provide a family of robustness analysis algorithms that give tighter bounds than existing works for the same amount of computation time (or reduced computational effort for a desired accuracy level). Moreover, we provide new partitioning techniques that are aware of their current bound estimates and desired boundary shape (e.g., lower bounds, weighted $\ell_\infty$-ball, convex hull), leading to further improvements in the computation-tightness tradeoff. The paper demonstrates the tighter bounds and reduced conservatism of the proposed robustness analysis framework with examples from model-free RL and forward kinematics learning.
Lunar Terrain Relative Navigation Using a Convolutional Neural Network for Visual Crater Detection
Jul 15, 2020
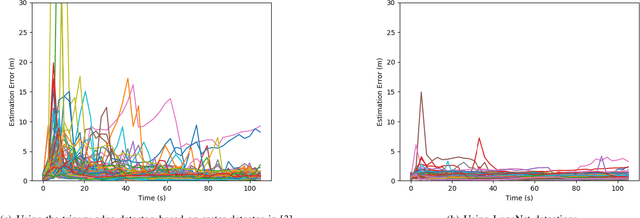
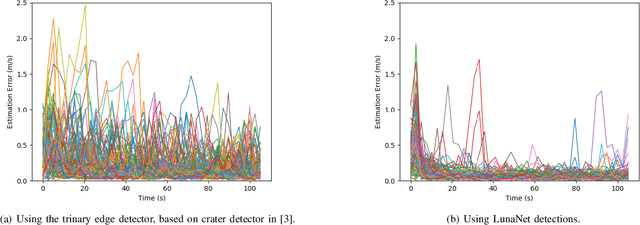
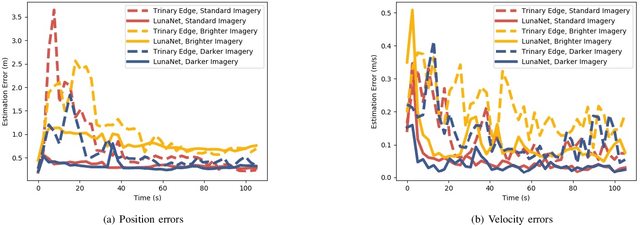
Terrain relative navigation can improve the precision of a spacecraft's position estimate by detecting global features that act as supplementary measurements to correct for drift in the inertial navigation system. This paper presents a system that uses a convolutional neural network (CNN) and image processing methods to track the location of a simulated spacecraft with an extended Kalman filter (EKF). The CNN, called LunaNet, visually detects craters in the simulated camera frame and those detections are matched to known lunar craters in the region of the current estimated spacecraft position. These matched craters are treated as features that are tracked using the EKF. LunaNet enables more reliable position tracking over a simulated trajectory due to its greater robustness to changes in image brightness and more repeatable crater detections from frame to frame throughout a trajectory. LunaNet combined with an EKF produces a decrease of 60% in the average final position estimation error and a decrease of 25% in average final velocity estimation error compared to an EKF using an image processing-based crater detection method when tested on trajectories using images of standard brightness.
Set-Invariant Constrained Reinforcement Learning with a Meta-Optimizer
Jul 09, 2020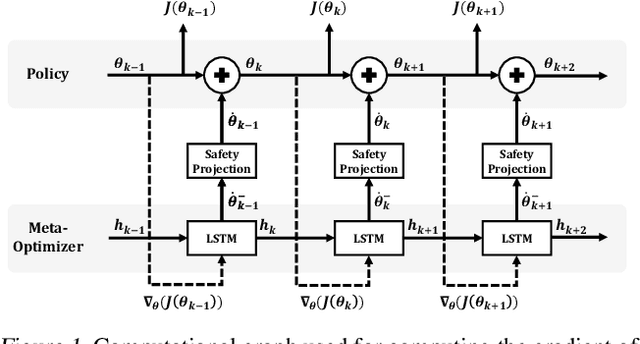
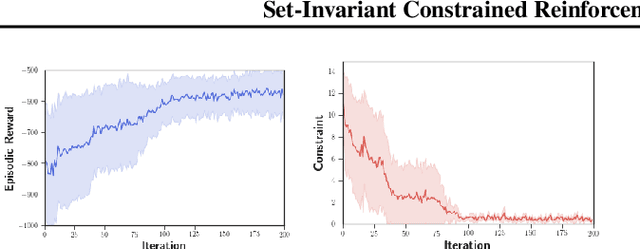
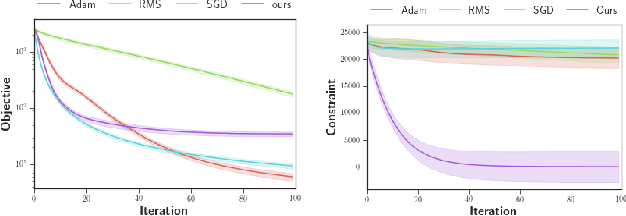
This paper investigates reinforcement learning with constraints, which is indispensable in safety-critical environments. To drive the constraint violation monotonically decrease, the constraints are taken as Lyapunov functions, and new linear constraints are imposed on the updating dynamics of the policy parameters such that the original safety set is forward-invariant in expectation. As the new guaranteed-feasible constraints are imposed on the updating dynamics instead of the original policy parameters, classic optimization algorithms are no longer applicable. To address this, we propose to learn a neural network-based meta-optimizer to optimize the objective while satisfying such linear constraints. The constraint-satisfaction is achieved via projection onto a polytope formulated by multiple linear inequality constraints, which can be solved analytically with our newly designed metric. Ultimately, the meta-optimizer trains the policy network to monotonically decrease the constraint violation and maximize the cumulative reward. Numerical results validate the theoretical findings.
Collision Probabilities for Continuous-Time Systems Without Sampling [with Appendices]
Jun 01, 2020![Figure 1 for Collision Probabilities for Continuous-Time Systems Without Sampling [with Appendices]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ff268865ee371d32400b4654be49f6475852c5d2e%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for Collision Probabilities for Continuous-Time Systems Without Sampling [with Appendices]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ff268865ee371d32400b4654be49f6475852c5d2e%2F5-Figure2-1.png&w=640&q=75)
![Figure 3 for Collision Probabilities for Continuous-Time Systems Without Sampling [with Appendices]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ff268865ee371d32400b4654be49f6475852c5d2e%2F7-Figure3-1.png&w=640&q=75)
![Figure 4 for Collision Probabilities for Continuous-Time Systems Without Sampling [with Appendices]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ff268865ee371d32400b4654be49f6475852c5d2e%2F8-Figure4-1.png&w=640&q=75)
Demand for high-performance, robust, and safe autonomous systems has grown substantially in recent years. Fulfillment of these objectives requires accurate and efficient risk estimation that can be embedded in core decision-making tasks such as motion planning. On one hand, Monte-Carlo (MC) and other sampling-based techniques can provide accurate solutions for a wide variety of motion models but are cumbersome to apply in the context of continuous optimization. On the other hand, "direct" approximations aim to compute (or upper-bound) the failure probability as a smooth function of the decision variables, and thus are widely applicable. However, existing approaches fundamentally assume discrete-time dynamics and can perform unpredictably when applied to continuous-time systems operating in the real world, often manifesting as severe conservatism. State-of-the-art attempts to address this within a conventional discrete-time framework require additional Gaussianity approximations that ultimately produce inconsistency of their own. In this paper we take a fundamentally different approach, deriving a risk approximation framework directly in continuous time and producing a lightweight estimate that actually improves as the discretization is refined. Our approximation is shown to significantly outperform state-of-the-art techniques in replicating the MC estimate while maintaining the functional and computational benefits of a direct method. This enables robust, risk-aware, continuous motion-planning for a broad class of nonlinear, partially-observable systems.
Certified Adversarial Robustness for Deep Reinforcement Learning
Apr 11, 2020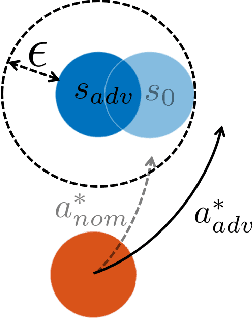
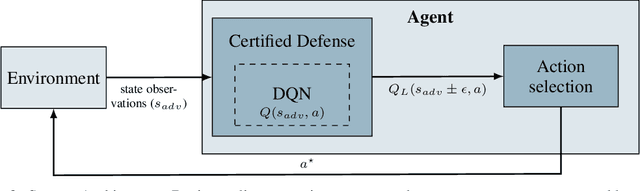
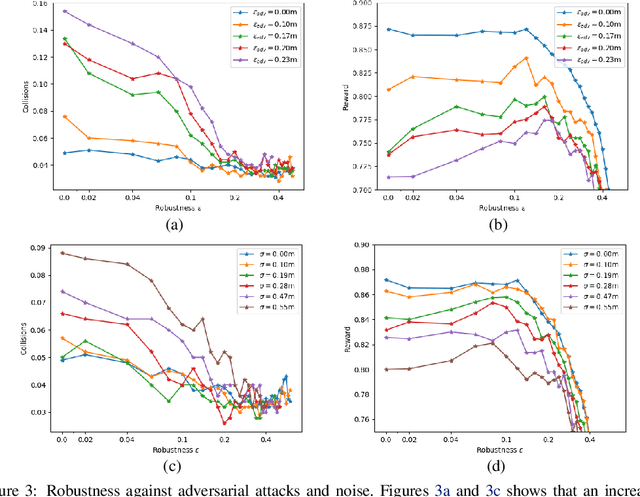
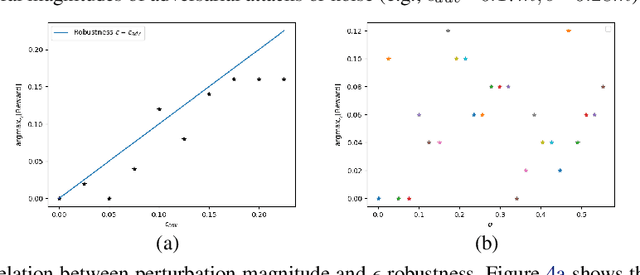
Deep Neural Network-based systems are now the state-of-the-art in many robotics tasks, but their application in safety-critical domains remains dangerous without formal guarantees on network robustness. Small perturbations to sensor inputs (from noise or adversarial examples) are often enough to change network-based decisions, which was recently shown to cause an autonomous vehicle to swerve into another lane. In light of these dangers, numerous algorithms have been developed as defensive mechanisms from these adversarial inputs, some of which provide formal robustness guarantees or certificates. This work leverages research on certified adversarial robustness to develop an online certified defense for deep reinforcement learning algorithms. The proposed defense computes guaranteed lower bounds on state-action values during execution to identify and choose a robust action under a worst-case deviation in input space due to possible adversaries or noise. The approach is demonstrated on a Deep Q-Network policy and is shown to increase robustness to noise and adversaries in pedestrian collision avoidance scenarios and a classic control task. This work extends our previous paper with new performance guarantees, expanded results aggregated across more scenarios, an extension into scenarios with adversarial behavior, comparisons with a more computationally expensive method, and visualizations that provide intuition about the robustness algorithm.