 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPL-NoViD: Context-Aware Prompt-based Learning for Norm Violation Detection in Online Communities
May 18, 2023



Detecting norm violations in online communities is critical to maintaining healthy and safe spaces for online discussions. Existing machine learning approaches often struggle to adapt to the diverse rules and interpretations across different communities due to the inherent challenges of fine-tuning models for such context-specific tasks. In this paper, we introduce Context-aware Prompt-based Learning for Norm Violation Detection (CPL-NoViD), a novel method that employs prompt-based learning to detect norm violations across various types of rules. CPL-NoViD outperforms the baseline by incorporating context through natural language prompts and demonstrates improved performance across different rule types. Significantly, it not only excels in cross-rule-type and cross-community norm violation detection but also exhibits adaptability in few-shot learning scenarios. Most notably, it establishes a new state-of-the-art in norm violation detection, surpassing existing benchmarks. Our work highlights the potential of prompt-based learning for context-sensitive norm violation detection and paves the way for future research on more adaptable, context-aware models to better support online community moderators.
Anger Breeds Controversy: Analyzing Controversy and Emotions on Reddit
Dec 01, 2022Emotions play an important role in interpersonal interactions and social conflict, yet their function in the development of controversy and disagreement in online conversations has not been explored. To address this gap, we study controversy on Reddit, a popular network of online discussion forums. We collect discussions from a wide variety of topical forums and use emotion detection to recognize a range of emotions from text, including anger, fear, joy, admiration, etc. Our study has three main findings. First, controversial comments express more anger and less admiration, joy and optimism than non-controversial comments. Second, controversial comments affect emotions of downstream comments in a discussion, usually resulting in long-term increase in anger and a decrease in positive emotions, although the magnitude and direction of emotional change depends on the forum. Finally, we show that emotions help better predict which comments will become controversial. Understanding emotional dynamics of online discussions can help communities to better manage conversations.
Checks and Strategies for Enabling Code-Switched Machine Translation
Oct 11, 2022
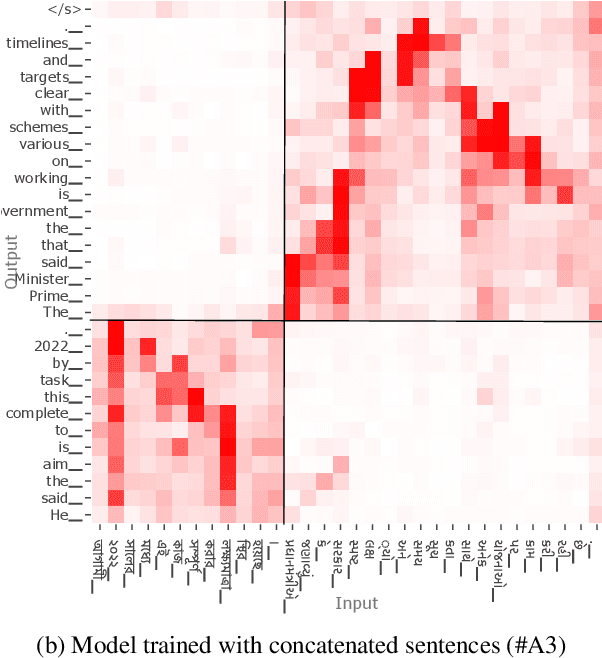
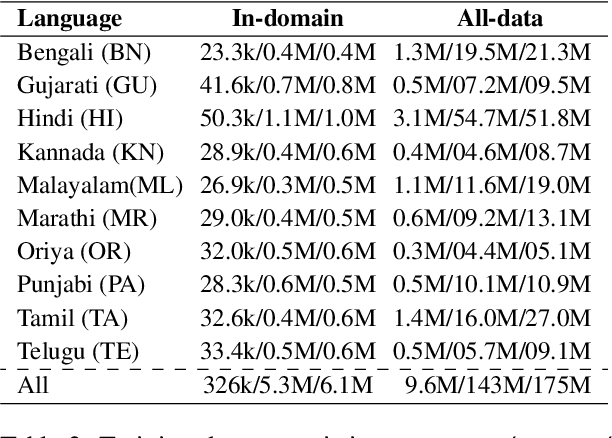
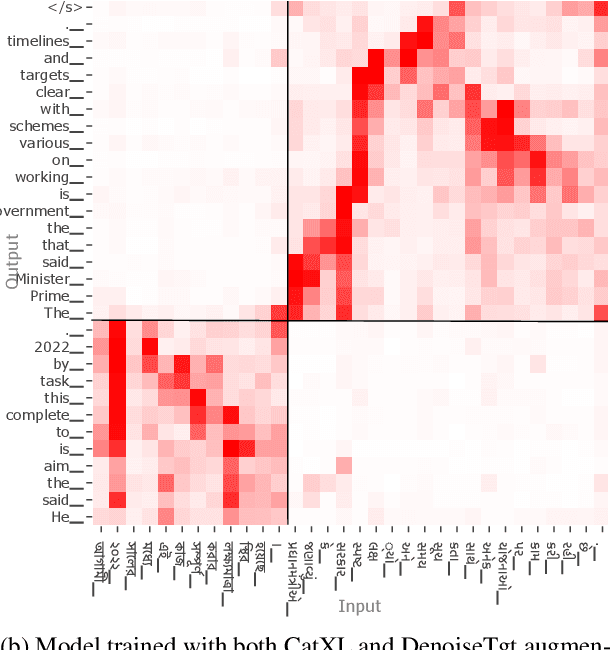
Code-switching is a common phenomenon among multilingual speakers, where alternation between two or more languages occurs within the context of a single conversation. While multilingual humans can seamlessly switch back and forth between languages, multilingual neural machine translation (NMT) models are not robust to such sudden changes in input. This work explores multilingual NMT models' ability to handle code-switched text. First, we propose checks to measure switching capability. Second, we investigate simple and effective data augmentation methods that can enhance an NMT model's ability to support code-switching. Finally, by using a glass-box analysis of attention modules, we demonstrate the effectiveness of these methods in improving robustness.
Mega: Moving Average Equipped Gated Attention
Sep 26, 2022
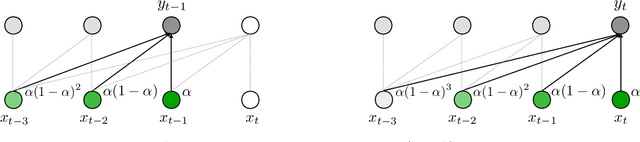
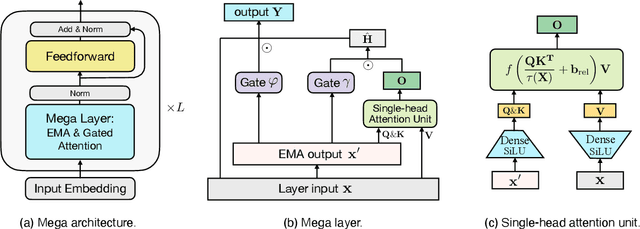
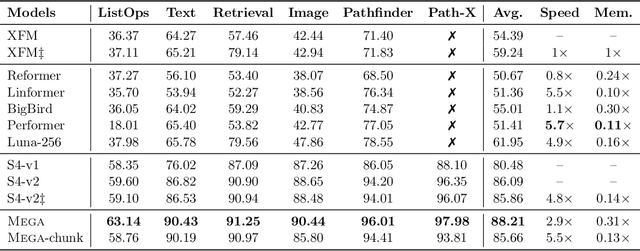
The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. In this paper, we introduce Mega, a simple, theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. We further propose a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length. Extensive experiments on a wide range of sequence modeling benchmarks, including the Long Range Arena, neural machine translation, auto-regressive language modeling, and image and speech classification, show that Mega achieves significant improvements over other sequence models, including variants of Transformers and recent state space models.
Towards WinoQueer: Developing a Benchmark for Anti-Queer Bias in Large Language Models
Jun 23, 2022

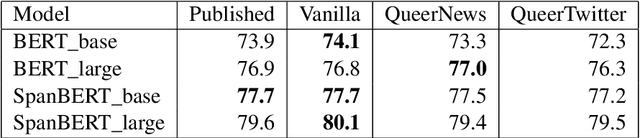
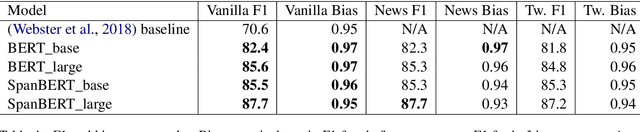
This paper presents exploratory work on whether and to what extent biases against queer and trans people are encoded in large language models (LLMs) such as BERT. We also propose a method for reducing these biases in downstream tasks: finetuning the models on data written by and/or about queer people. To measure anti-queer bias, we introduce a new benchmark dataset, WinoQueer, modeled after other bias-detection benchmarks but addressing homophobic and transphobic biases. We found that BERT shows significant homophobic bias, but this bias can be mostly mitigated by finetuning BERT on a natural language corpus written by members of the LGBTQ+ community.
NewsEdits: A News Article Revision Dataset and a Document-Level Reasoning Challenge
Jun 14, 2022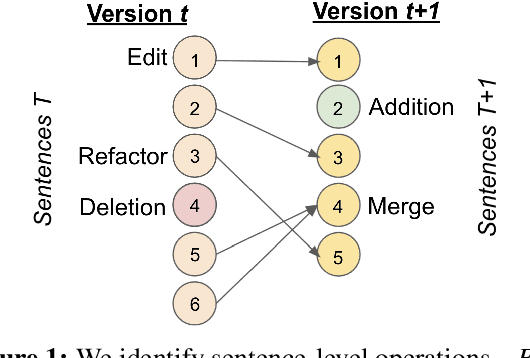
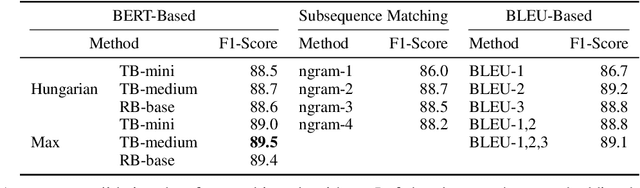
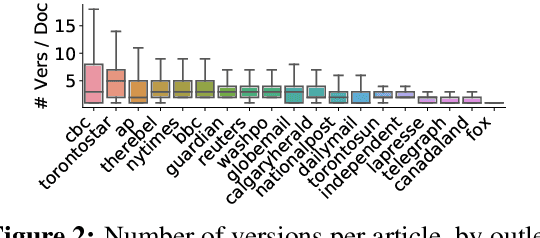
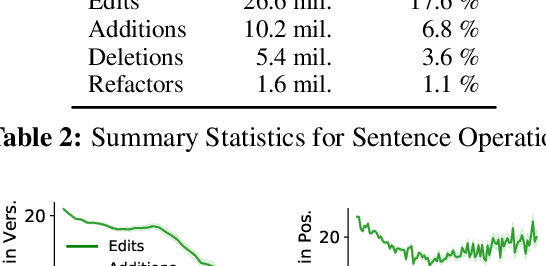
News article revision histories provide clues to narrative and factual evolution in news articles. To facilitate analysis of this evolution, we present the first publicly available dataset of news revision histories, NewsEdits. Our dataset is large-scale and multilingual; it contains 1.2 million articles with 4.6 million versions from over 22 English- and French-language newspaper sources based in three countries, spanning 15 years of coverage (2006-2021). We define article-level edit actions: Addition, Deletion, Edit and Refactor, and develop a high-accuracy extraction algorithm to identify these actions. To underscore the factual nature of many edit actions, we conduct analyses showing that added and deleted sentences are more likely to contain updating events, main content and quotes than unchanged sentences. Finally, to explore whether edit actions are predictable, we introduce three novel tasks aimed at predicting actions performed during version updates. We show that these tasks are possible for expert humans but are challenging for large NLP models. We hope this can spur research in narrative framing and help provide predictive tools for journalists chasing breaking news.
Segmenting Numerical Substitution Ciphers
May 25, 2022



Deciphering historical substitution ciphers is a challenging problem. Example problems that have been previously studied include detecting cipher type, detecting plaintext language, and acquiring the substitution key for segmented ciphers. However, attacking unsegmented, space-free ciphers is still a challenging task. Segmentation (i.e. finding substitution units) is the first step towards cracking those ciphers. In this work, we propose the first automatic methods to segment those ciphers using Byte Pair Encoding (BPE) and unigram language models. Our methods achieve an average segmentation error of 2\% on 100 randomly-generated monoalphabetic ciphers and 27\% on 3 real homophonic ciphers. We also propose a method for solving non-deterministic ciphers with existing keys using a lattice and a pretrained language model. Our method leads to the full solution of the IA cipher; a real historical cipher that has not been fully solved until this work.
Machine Translation Robustness to Natural Asemantic Variation
May 25, 2022
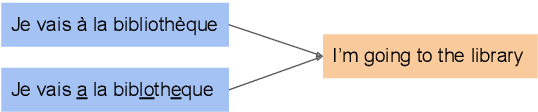

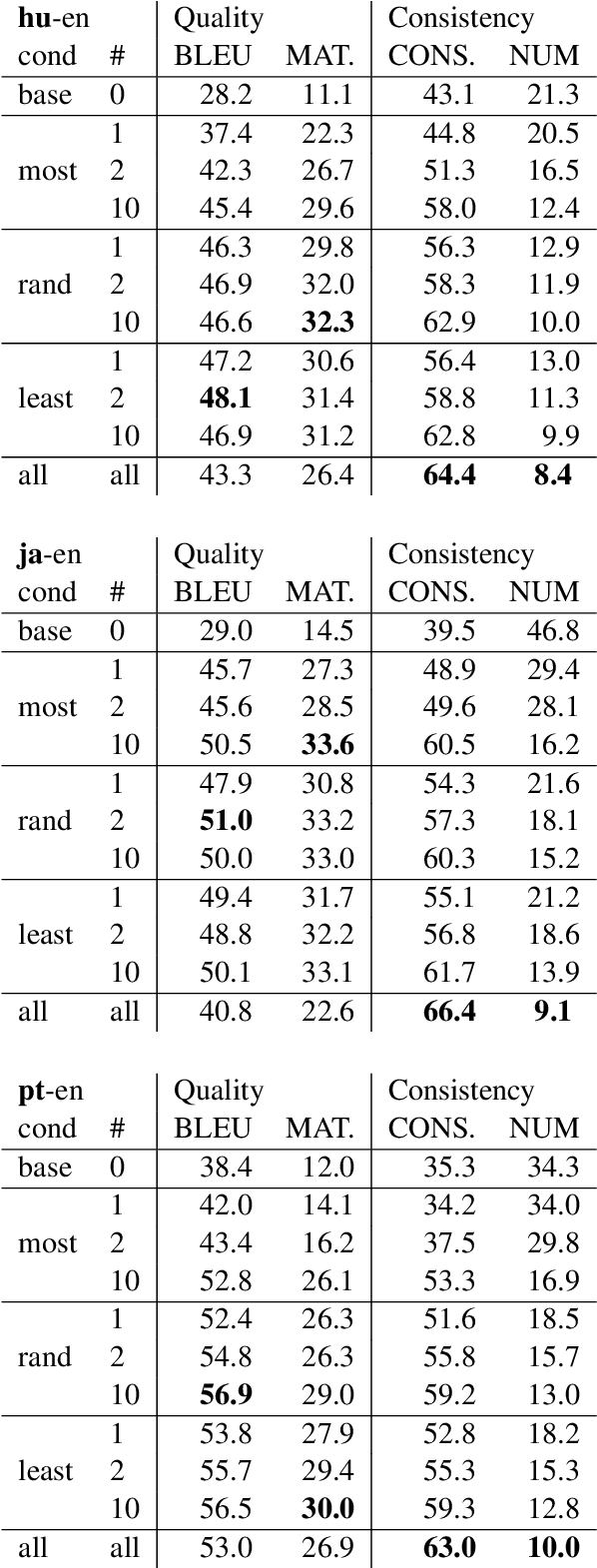
We introduce and formalize an under-studied linguistic phenomenon we call Natural Asemantic Variation (NAV) and investigate it in the context of Machine Translation (MT) robustness. Standard MT models are shown to be less robust to rarer, nuanced language forms, and current robustness techniques do not account for this kind of perturbation despite their prevalence in "real world" data. Experiment results provide more insight into the nature of NAV and we demonstrate strategies to improve performance on NAV. We also show that NAV robustness can be transferred across languages and fine that synthetic perturbations can achieve some but not all of the benefits of human-generated NAV data.
Know Where You're Going: Meta-Learning for Parameter-Efficient Fine-tuning
May 25, 2022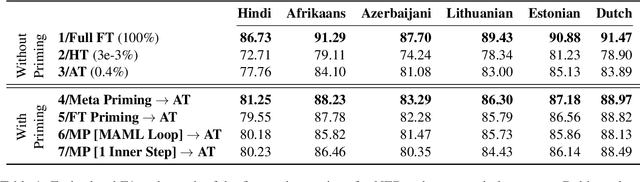
A recent family of techniques, dubbed as lightweight fine-tuning methods, facilitates parameter-efficient transfer learning by updating only a small set of additional parameters while keeping the parameters of the pretrained language model frozen. While proven to be an effective method, there are no existing studies on if and how such knowledge of the downstream fine-tuning approach should affect the pretraining stage. In this work, we show that taking the ultimate choice of fine-tuning method into consideration boosts the performance of parameter-efficient fine-tuning. By relying on optimization-based meta-learning using MAML with certain modifications for our distinct purpose, we prime the pretrained model specifically for parameter-efficient fine-tuning, resulting in gains of up to 1.7 points on cross-lingual NER fine-tuning. Our ablation settings and analyses further reveal that the tweaks we introduce in MAML are crucial for the attained gains.
Cross-lingual Lifelong Learning
May 23, 2022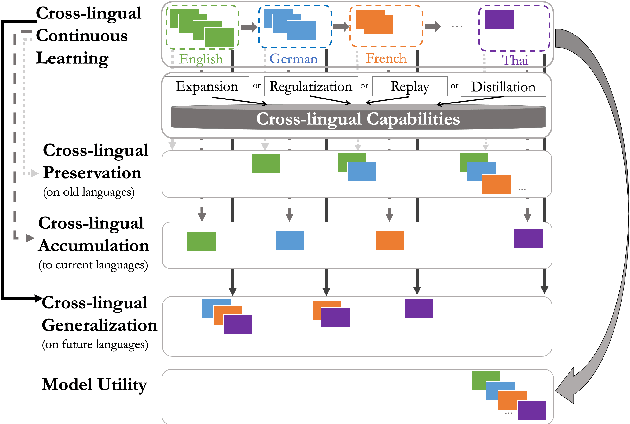
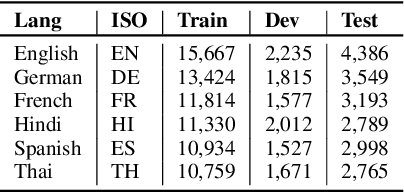
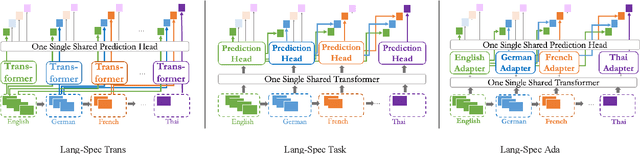

The longstanding goal of multi-lingual learning has been to develop a universal cross-lingual model that can withstand the changes in multi-lingual data distributions. However, most existing models assume full access to the target languages in advance, whereas in realistic scenarios this is not often the case, as new languages can be incorporated later on. In this paper, we present the Cross-lingual Lifelong Learning (CLL) challenge, where a model is continually fine-tuned to adapt to emerging data from different languages. We provide insights into what makes multilingual sequential learning particularly challenging. To surmount such challenges, we benchmark a representative set of cross-lingual continual learning algorithms and analyze their knowledge preservation, accumulation, and generalization capabilities compared to baselines on carefully curated datastreams. The implications of this analysis include a recipe for how to measure and balance between different cross-lingual continual learning desiderata, which goes beyond conventional transfer learning.