 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Social Influence with Networked Synthetic Control
May 19, 2025


Measuring social influence is difficult due to the lack of counter-factuals and comparisons. By combining machine learning-based modeling and network science, we present general properties of social value, a recent measure for social influence using synthetic control applicable to political behavior. Social value diverges from centrality measures on in that it relies on an external regressor to predict an output variable of interest, generates a synthetic measure of influence, then distributes individual contribution based on a social network. Through theoretical derivations, we show the properties of SV under linear regression with and without interaction, across lattice networks, power-law networks, and random graphs. A reduction in computation can be achieved for any ensemble model. Through simulation, we find that the generalized friendship paradox holds -- that in certain situations, your friends have on average more influence than you do.
Generative Memesis: AI Mediates Political Memes in the 2024 USA Presidential Election
Nov 01, 2024



Visual content on social media has become increasingly influential in shaping political discourse and civic engagement. Using a dataset of 239,526 Instagram images, deep learning, and LLM-based workflows, we examine the impact of different content types on user engagement during the 2024 US presidential Elections, with a focus on synthetic visuals. Results show while synthetic content may not increase engagement alone, it mediates how political information is created through highly effective, often absurd, political memes. We define the notion of generative memesis, where memes are no longer shared person-to-person but mediated by AI through customized, generated images. We also find partisan divergences: Democrats use AI for in-group support whereas Republicans use it for out-group attacks. Non-traditional, left-leaning outlets are the primary creators of political memes; emphasis on different topics largely follows issue ownership.
LLMs with Personalities in Multi-issue Negotiation Games
May 08, 2024



Powered by large language models (LLMs), AI agents have become capable of many human tasks. Using the most canonical definitions of the Big Five personality, we measure the ability of LLMs to negotiate within a game-theoretical framework, as well as methodological challenges to measuring notions of fairness and risk. Simulations (n=1,500) for both single-issue and multi-issue negotiation reveal increase in domain complexity with asymmetric issue valuations improve agreement rates but decrease surplus from aggressive negotiation. Through gradient-boosted regression and Shapley explainers, we find high openness, conscientiousness, and neuroticism are associated with fair tendencies; low agreeableness and low openness are associated with rational tendencies. Low conscientiousness is associated with high toxicity. These results indicate that LLMs may have built-in guardrails that default to fair behavior, but can be "jail broken" to exploit agreeable opponents. We also offer pragmatic insight in how negotiation bots can be designed, and a framework of assessing negotiation behavior based on game theory and computational social science.
WinoQueer: A Community-in-the-Loop Benchmark for Anti-LGBTQ+ Bias in Large Language Models
Jun 26, 2023



We present WinoQueer: a benchmark specifically designed to measure whether large language models (LLMs) encode biases that are harmful to the LGBTQ+ community. The benchmark is community-sourced, via application of a novel method that generates a bias benchmark from a community survey. We apply our benchmark to several popular LLMs and find that off-the-shelf models generally do exhibit considerable anti-queer bias. Finally, we show that LLM bias against a marginalized community can be somewhat mitigated by finetuning on data written about or by members of that community, and that social media text written by community members is more effective than news text written about the community by non-members. Our method for community-in-the-loop benchmark development provides a blueprint for future researchers to develop community-driven, harms-grounded LLM benchmarks for other marginalized communities.
Towards WinoQueer: Developing a Benchmark for Anti-Queer Bias in Large Language Models
Jun 23, 2022

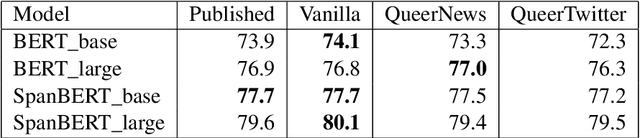
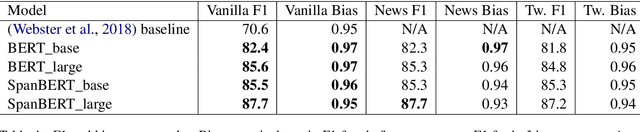
This paper presents exploratory work on whether and to what extent biases against queer and trans people are encoded in large language models (LLMs) such as BERT. We also propose a method for reducing these biases in downstream tasks: finetuning the models on data written by and/or about queer people. To measure anti-queer bias, we introduce a new benchmark dataset, WinoQueer, modeled after other bias-detection benchmarks but addressing homophobic and transphobic biases. We found that BERT shows significant homophobic bias, but this bias can be mostly mitigated by finetuning BERT on a natural language corpus written by members of the LGBTQ+ community.
Tracking e-cigarette warning label compliance on Instagram with deep learning
Feb 08, 2021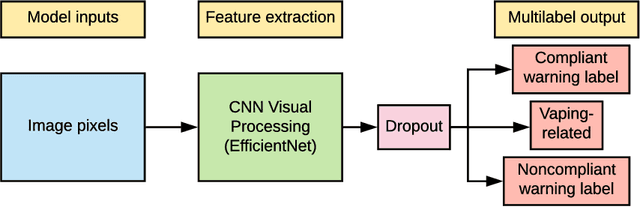

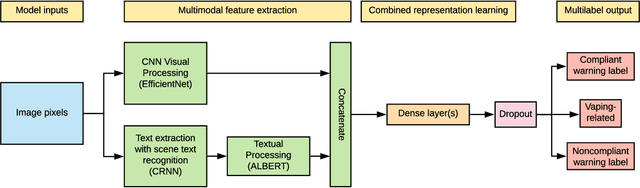
The U.S. Food & Drug Administration (FDA) requires that e-cigarette advertisements include a prominent warning label that reminds consumers that nicotine is addictive. However, the high volume of vaping-related posts on social media makes compliance auditing expensive and time-consuming, suggesting that an automated, scalable method is needed. We sought to develop and evaluate a deep learning system designed to automatically determine if an Instagram post promotes vaping, and if so, if an FDA-compliant warning label was included or if a non-compliant warning label was visible in the image. We compiled and labeled a dataset of 4,363 Instagram images, of which 44% were vaping-related, 3% contained FDA-compliant warning labels, and 4% contained non-compliant labels. Using a 20% test set for evaluation, we tested multiple neural network variations: image processing backbone model (Inceptionv3, ResNet50, EfficientNet), data augmentation, progressive layer unfreezing, output bias initialization designed for class imbalance, and multitask learning. Our final model achieved an area under the curve (AUC) and [accuracy] of 0.97 [92%] on vaping classification, 0.99 [99%] on FDA-compliant warning labels, and 0.94 [97%] on non-compliant warning labels. We conclude that deep learning models can effectively identify vaping posts on Instagram and track compliance with FDA warning label requirements.
Multi-Issue Bargaining With Deep Reinforcement Learning
Feb 18, 2020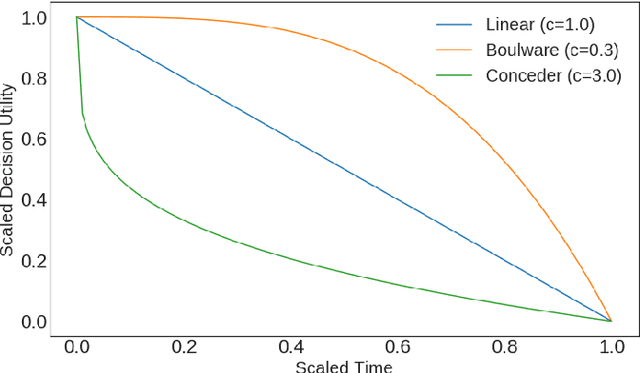
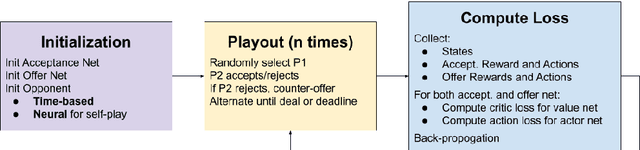

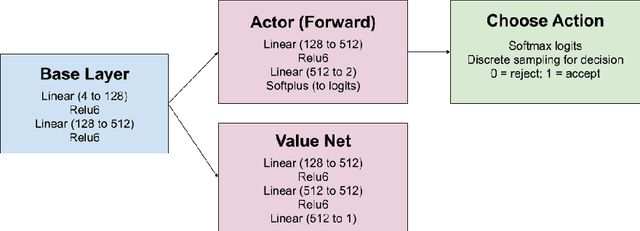
Negotiation is a process where agents aim to work through disputes and maximize their surplus. As the use of deep reinforcement learning in bargaining games is unexplored, this paper evaluates its ability to exploit, adapt, and cooperate to produce fair outcomes. Two actor-critic networks were trained for the bidding and acceptance strategy, against time-based agents, behavior-based agents, and through self-play. Gameplay against these agents reveals three key findings. 1) Neural agents learn to exploit time-based agents, achieving clear transitions in decision preference values. The Cauchy distribution emerges as suitable for sampling offers, due to its peaky center and heavy tails. The kurtosis and variance sensitivity of the probability distributions used for continuous control produce trade-offs in exploration and exploitation. 2) Neural agents demonstrate adaptive behavior against different combinations of concession, discount factors, and behavior-based strategies. 3) Most importantly, neural agents learn to cooperate with other behavior-based agents, in certain cases utilizing non-credible threats to force fairer results. This bears similarities with reputation-based strategies in the evolutionary dynamics, and departs from equilibria in classical game theory.