 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT is Not an Annotator: The Necessity of Human Annotation in Fairness Benchmark Construction
May 24, 2024



Social biases in LLMs are usually measured via bias benchmark datasets. Current benchmarks have limitations in scope, grounding, quality, and human effort required. Previous work has shown success with a community-sourced, rather than crowd-sourced, approach to benchmark development. However, this work still required considerable effort from annotators with relevant lived experience. This paper explores whether an LLM (specifically, GPT-3.5-Turbo) can assist with the task of developing a bias benchmark dataset from responses to an open-ended community survey. We also extend the previous work to a new community and set of biases: the Jewish community and antisemitism. Our analysis shows that GPT-3.5-Turbo has poor performance on this annotation task and produces unacceptable quality issues in its output. Thus, we conclude that GPT-3.5-Turbo is not an appropriate substitute for human annotation in sensitive tasks related to social biases, and that its use actually negates many of the benefits of community-sourcing bias benchmarks.
WinoQueer: A Community-in-the-Loop Benchmark for Anti-LGBTQ+ Bias in Large Language Models
Jun 26, 2023



We present WinoQueer: a benchmark specifically designed to measure whether large language models (LLMs) encode biases that are harmful to the LGBTQ+ community. The benchmark is community-sourced, via application of a novel method that generates a bias benchmark from a community survey. We apply our benchmark to several popular LLMs and find that off-the-shelf models generally do exhibit considerable anti-queer bias. Finally, we show that LLM bias against a marginalized community can be somewhat mitigated by finetuning on data written about or by members of that community, and that social media text written by community members is more effective than news text written about the community by non-members. Our method for community-in-the-loop benchmark development provides a blueprint for future researchers to develop community-driven, harms-grounded LLM benchmarks for other marginalized communities.
Towards WinoQueer: Developing a Benchmark for Anti-Queer Bias in Large Language Models
Jun 23, 2022

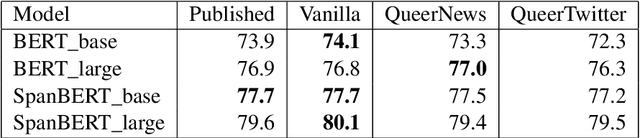
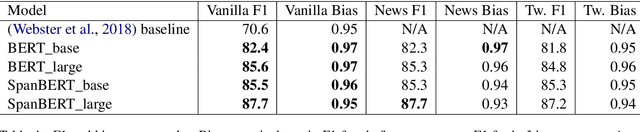
This paper presents exploratory work on whether and to what extent biases against queer and trans people are encoded in large language models (LLMs) such as BERT. We also propose a method for reducing these biases in downstream tasks: finetuning the models on data written by and/or about queer people. To measure anti-queer bias, we introduce a new benchmark dataset, WinoQueer, modeled after other bias-detection benchmarks but addressing homophobic and transphobic biases. We found that BERT shows significant homophobic bias, but this bias can be mostly mitigated by finetuning BERT on a natural language corpus written by members of the LGBTQ+ community.